 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
Run-time Introspection of 2D Object Detection in Automated Driving Systems Using Learning Representations
Mar 02, 2024
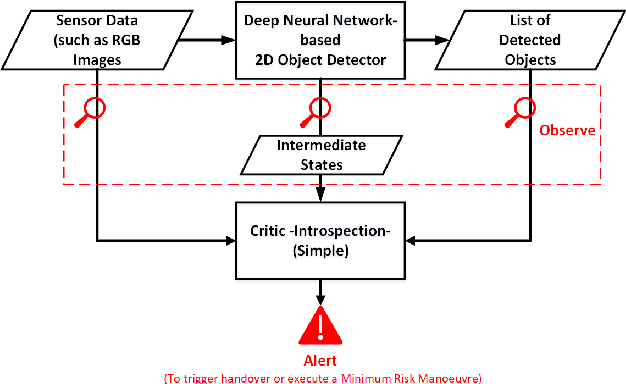
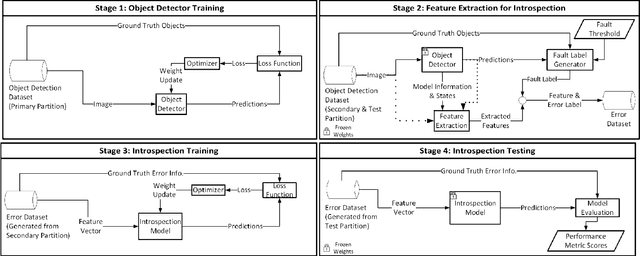
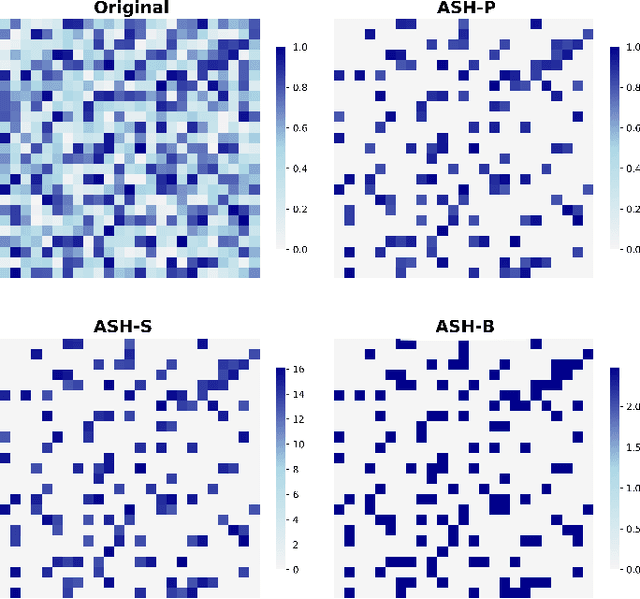
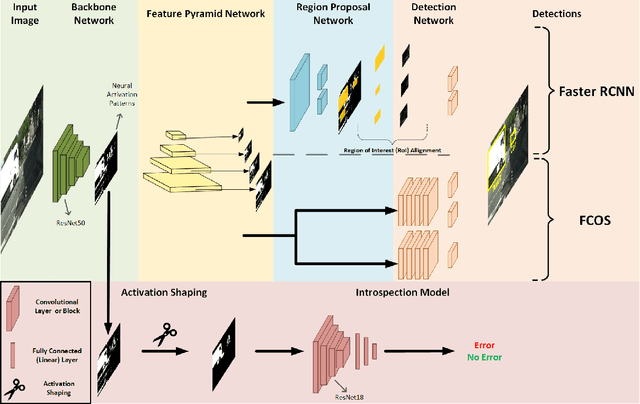
Reliable detection of various objects and road users in the surrounding environment is crucial for the safe operation of automated driving systems (ADS). Despite recent progresses in developing highly accurate object detectors based on Deep Neural Networks (DNNs), they still remain prone to detection errors, which can lead to fatal consequences in safety-critical applications such as ADS. An effective remedy to this problem is to equip the system with run-time monitoring, named as introspection in the context of autonomous systems. Motivated by this, we introduce a novel introspection solution, which operates at the frame level for DNN-based 2D object detection and leverages neural network activation patterns. The proposed approach pre-processes the neural activation patterns of the object detector's backbone using several different modes. To provide extensive comparative analysis and fair comparison, we also adapt and implement several state-of-the-art (SOTA) introspection mechanisms for error detection in 2D object detection, using one-stage and two-stage object detectors evaluated on KITTI and BDD datasets. We compare the performance of the proposed solution in terms of error detection, adaptability to dataset shift, and, computational and memory resource requirements. Our performance evaluation shows that the proposed introspection solution outperforms SOTA methods, achieving an absolute reduction in the missed error ratio of 9% to 17% in the BDD dataset.
Prompt Learning for Oriented Power Transmission Tower Detection in High-Resolution SAR Images
Apr 01, 2024Detecting transmission towers from synthetic aperture radar (SAR) images remains a challenging task due to the comparatively small size and side-looking geometry, with background clutter interference frequently hindering tower identification. A large number of interfering signals superimposes the return signal from the tower. We found that localizing or prompting positions of power transmission towers is beneficial to address this obstacle. Based on this revelation, this paper introduces prompt learning into the oriented object detector (P2Det) for multimodal information learning. P2Det contains the sparse prompt coding and cross-attention between the multimodal data. Specifically, the sparse prompt encoder (SPE) is proposed to represent point locations, converting prompts into sparse embeddings. The image embeddings are generated through the Transformer layers. Then a two-way fusion module (TWFM) is proposed to calculate the cross-attention of the two different embeddings. The interaction of image-level and prompt-level features is utilized to address the clutter interference. A shape-adaptive refinement module (SARM) is proposed to reduce the effect of aspect ratio. Extensive experiments demonstrated the effectiveness of the proposed model on high-resolution SAR images. P2Det provides a novel insight for multimodal object detection due to its competitive performance.
Instance-Aware Group Quantization for Vision Transformers
Apr 01, 2024Post-training quantization (PTQ) is an efficient model compression technique that quantizes a pretrained full-precision model using only a small calibration set of unlabeled samples without retraining. PTQ methods for convolutional neural networks (CNNs) provide quantization results comparable to full-precision counterparts. Directly applying them to vision transformers (ViTs), however, incurs severe performance degradation, mainly due to the differences in architectures between CNNs and ViTs. In particular, the distribution of activations for each channel vary drastically according to input instances, making PTQ methods for CNNs inappropriate for ViTs. To address this, we introduce instance-aware group quantization for ViTs (IGQ-ViT). To this end, we propose to split the channels of activation maps into multiple groups dynamically for each input instance, such that activations within each group share similar statistical properties. We also extend our scheme to quantize softmax attentions across tokens. In addition, the number of groups for each layer is adjusted to minimize the discrepancies between predictions from quantized and full-precision models, under a bit-operation (BOP) constraint. We show extensive experimental results on image classification, object detection, and instance segmentation, with various transformer architectures, demonstrating the effectiveness of our approach.
GOOD: Towards Domain Generalized Orientated Object Detection
Feb 20, 2024Oriented object detection has been rapidly developed in the past few years, but most of these methods assume the training and testing images are under the same statistical distribution, which is far from reality. In this paper, we propose the task of domain generalized oriented object detection, which intends to explore the generalization of oriented object detectors on arbitrary unseen target domains. Learning domain generalized oriented object detectors is particularly challenging, as the cross-domain style variation not only negatively impacts the content representation, but also leads to unreliable orientation predictions. To address these challenges, we propose a generalized oriented object detector (GOOD). After style hallucination by the emerging contrastive language-image pre-training (CLIP), it consists of two key components, namely, rotation-aware content consistency learning (RAC) and style consistency learning (SEC). The proposed RAC allows the oriented object detector to learn stable orientation representation from style-diversified samples. The proposed SEC further stabilizes the generalization ability of content representation from different image styles. Extensive experiments on multiple cross-domain settings show the state-of-the-art performance of GOOD. Source code will be publicly available.
Self-supervised co-salient object detection via feature correspondence at multiple scales
Mar 27, 2024

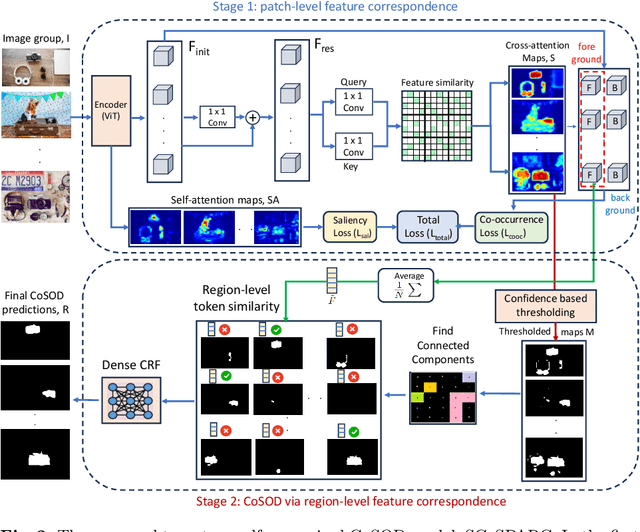
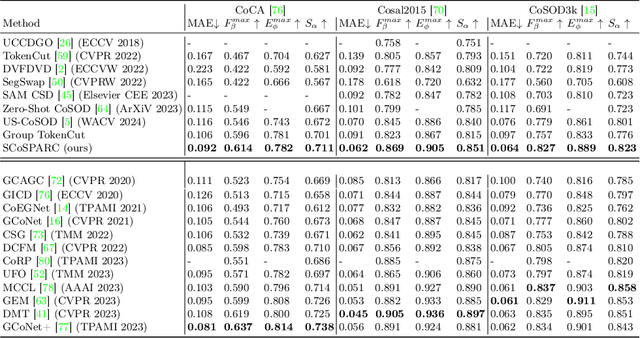
Our paper introduces a novel two-stage self-supervised approach for detecting co-occurring salient objects (CoSOD) in image groups without requiring segmentation annotations. Unlike existing unsupervised methods that rely solely on patch-level information (e.g. clustering patch descriptors) or on computation heavy off-the-shelf components for CoSOD, our lightweight model leverages feature correspondences at both patch and region levels, significantly improving prediction performance. In the first stage, we train a self-supervised network that detects co-salient regions by computing local patch-level feature correspondences across images. We obtain the segmentation predictions using confidence-based adaptive thresholding. In the next stage, we refine these intermediate segmentations by eliminating the detected regions (within each image) whose averaged feature representations are dissimilar to the foreground feature representation averaged across all the cross-attention maps (from the previous stage). Extensive experiments on three CoSOD benchmark datasets show that our self-supervised model outperforms the corresponding state-of-the-art models by a huge margin (e.g. on the CoCA dataset, our model has a 13.7% F-measure gain over the SOTA unsupervised CoSOD model). Notably, our self-supervised model also outperforms several recent fully supervised CoSOD models on the three test datasets (e.g., on the CoCA dataset, our model has a 4.6% F-measure gain over a recent supervised CoSOD model).
VLM-PL: Advanced Pseudo Labeling approach Class Incremental Object Detection with Vision-Language Model
Mar 08, 2024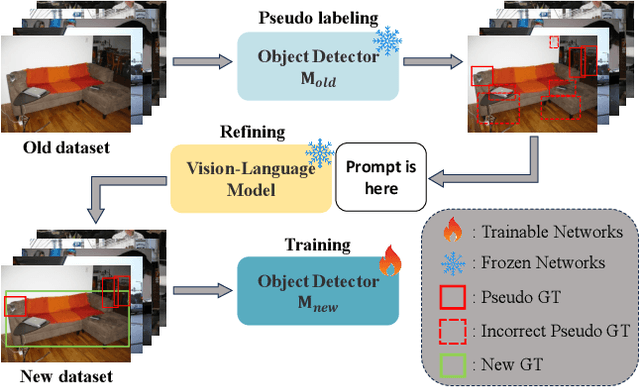
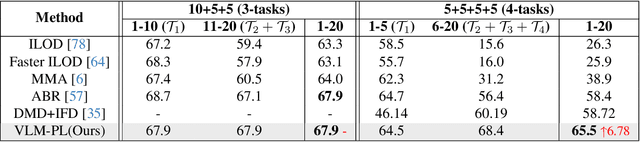
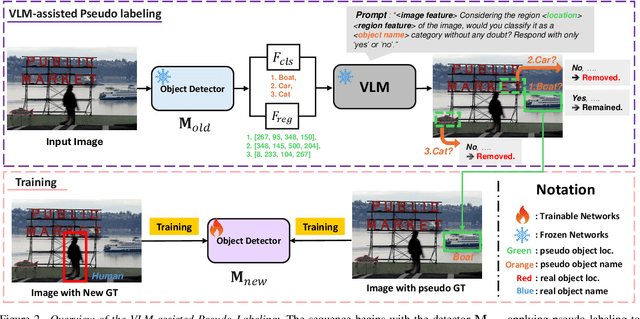
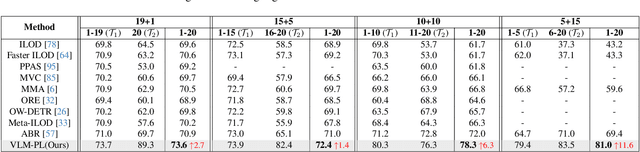
In the field of Class Incremental Object Detection (CIOD), creating models that can continuously learn like humans is a major challenge. Pseudo-labeling methods, although initially powerful, struggle with multi-scenario incremental learning due to their tendency to forget past knowledge. To overcome this, we introduce a new approach called Vision-Language Model assisted Pseudo-Labeling (VLM-PL). This technique uses Vision-Language Model (VLM) to verify the correctness of pseudo ground-truths (GTs) without requiring additional model training. VLM-PL starts by deriving pseudo GTs from a pre-trained detector. Then, we generate custom queries for each pseudo GT using carefully designed prompt templates that combine image and text features. This allows the VLM to classify the correctness through its responses. Furthermore, VLM-PL integrates refined pseudo and real GTs from upcoming training, effectively combining new and old knowledge. Extensive experiments conducted on the Pascal VOC and MS COCO datasets not only highlight VLM-PL's exceptional performance in multi-scenario but also illuminate its effectiveness in dual-scenario by achieving state-of-the-art results in both.
AIDE: An Automatic Data Engine for Object Detection in Autonomous Driving
Mar 26, 2024Autonomous vehicle (AV) systems rely on robust perception models as a cornerstone of safety assurance. However, objects encountered on the road exhibit a long-tailed distribution, with rare or unseen categories posing challenges to a deployed perception model. This necessitates an expensive process of continuously curating and annotating data with significant human effort. We propose to leverage recent advances in vision-language and large language models to design an Automatic Data Engine (AIDE) that automatically identifies issues, efficiently curates data, improves the model through auto-labeling, and verifies the model through generation of diverse scenarios. This process operates iteratively, allowing for continuous self-improvement of the model. We further establish a benchmark for open-world detection on AV datasets to comprehensively evaluate various learning paradigms, demonstrating our method's superior performance at a reduced cost.
CMDA: Cross-Modal and Domain Adversarial Adaptation for LiDAR-Based 3D Object Detection
Mar 07, 2024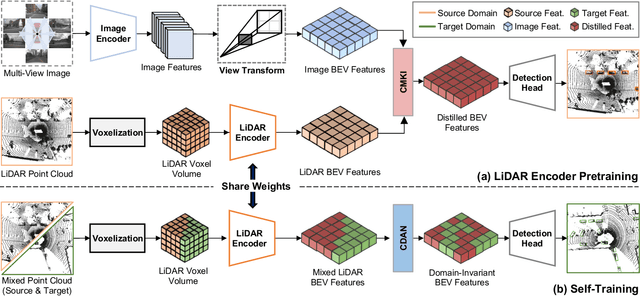
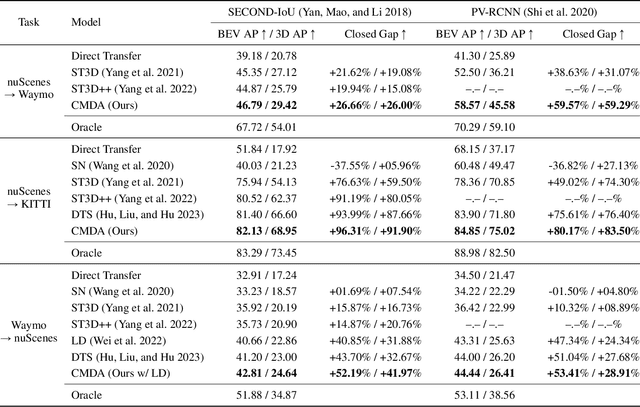
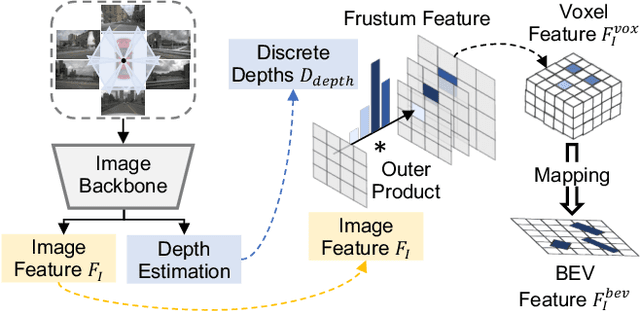
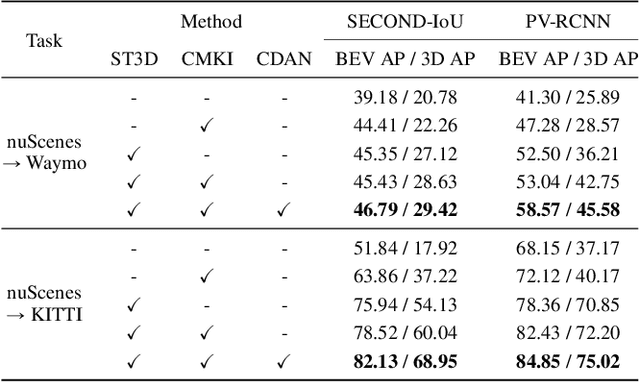
Recent LiDAR-based 3D Object Detection (3DOD) methods show promising results, but they often do not generalize well to target domains outside the source (or training) data distribution. To reduce such domain gaps and thus to make 3DOD models more generalizable, we introduce a novel unsupervised domain adaptation (UDA) method, called CMDA, which (i) leverages visual semantic cues from an image modality (i.e., camera images) as an effective semantic bridge to close the domain gap in the cross-modal Bird's Eye View (BEV) representations. Further, (ii) we also introduce a self-training-based learning strategy, wherein a model is adversarially trained to generate domain-invariant features, which disrupt the discrimination of whether a feature instance comes from a source or an unseen target domain. Overall, our CMDA framework guides the 3DOD model to generate highly informative and domain-adaptive features for novel data distributions. In our extensive experiments with large-scale benchmarks, such as nuScenes, Waymo, and KITTI, those mentioned above provide significant performance gains for UDA tasks, achieving state-of-the-art performance.
Leveraging Anchor-based LiDAR 3D Object Detection via Point Assisted Sample Selection
Mar 04, 2024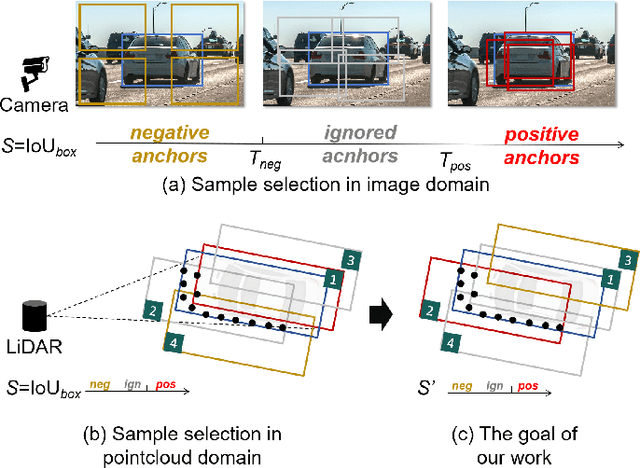
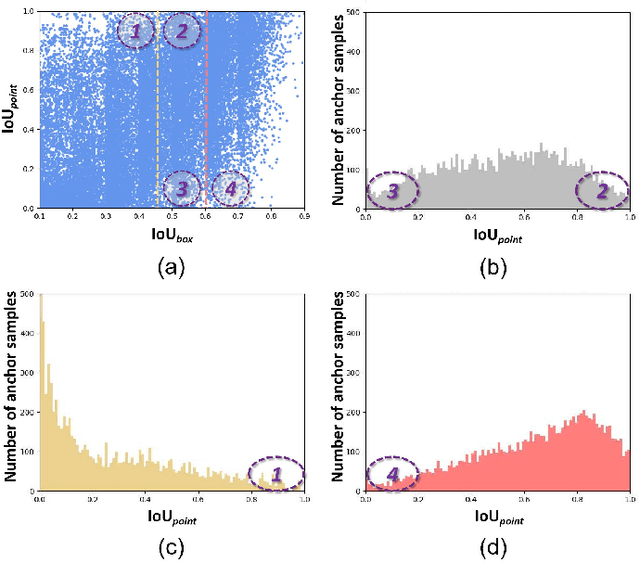
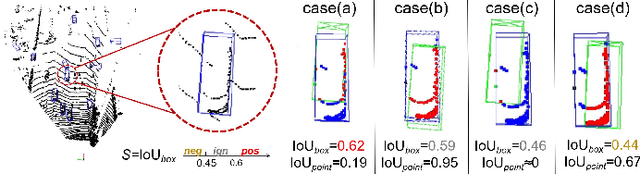
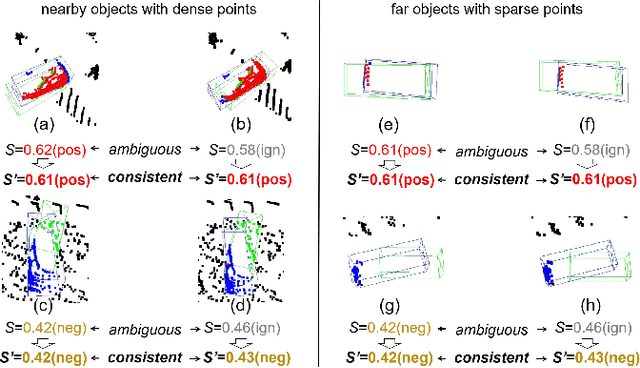
3D object detection based on LiDAR point cloud and prior anchor boxes is a critical technology for autonomous driving environment perception and understanding. Nevertheless, an overlooked practical issue in existing methods is the ambiguity in training sample allocation based on box Intersection over Union (IoU_box). This problem impedes further enhancements in the performance of anchor-based LiDAR 3D object detectors. To tackle this challenge, this paper introduces a new training sample selection method that utilizes point cloud distribution for anchor sample quality measurement, named Point Assisted Sample Selection (PASS). This method has undergone rigorous evaluation on two widely utilized datasets. Experimental results demonstrate that the application of PASS elevates the average precision of anchor-based LiDAR 3D object detectors to a novel state-of-the-art, thereby proving the effectiveness of the proposed approach. The codes will be made available at https://github.com/XJTU-Haolin/Point_Assisted_Sample_Selection.
ProtoP-OD: Explainable Object Detection with Prototypical Parts
Feb 29, 2024Interpretation and visualization of the behavior of detection transformers tends to highlight the locations in the image that the model attends to, but it provides limited insight into the \emph{semantics} that the model is focusing on. This paper introduces an extension to detection transformers that constructs prototypical local features and uses them in object detection. These custom features, which we call prototypical parts, are designed to be mutually exclusive and align with the classifications of the model. The proposed extension consists of a bottleneck module, the prototype neck, that computes a discretized representation of prototype activations and a new loss term that matches prototypes to object classes. This setup leads to interpretable representations in the prototype neck, allowing visual inspection of the image content perceived by the model and a better understanding of the model's reliability. We show experimentally that our method incurs only a limited performance penalty, and we provide examples that demonstrate the quality of the explanations provided by our method, which we argue outweighs the performance penalty.