 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
HDMNet: A Hierarchical Matching Network with Double Attention for Large-scale Outdoor LiDAR Point Cloud Registration
Oct 29, 2023
Outdoor LiDAR point clouds are typically large-scale and complexly distributed. To achieve efficient and accurate registration, emphasizing the similarity among local regions and prioritizing global local-to-local matching is of utmost importance, subsequent to which accuracy can be enhanced through cost-effective fine registration. In this paper, a novel hierarchical neural network with double attention named HDMNet is proposed for large-scale outdoor LiDAR point cloud registration. Specifically, A novel feature consistency enhanced double-soft matching network is introduced to achieve two-stage matching with high flexibility while enlarging the receptive field with high efficiency in a patch-to patch manner, which significantly improves the registration performance. Moreover, in order to further utilize the sparse matching information from deeper layer, we develop a novel trainable embedding mask to incorporate the confidence scores of correspondences obtained from pose estimation of deeper layer, eliminating additional computations. The high-confidence keypoints in the sparser point cloud of the deeper layer correspond to a high-confidence spatial neighborhood region in shallower layer, which will receive more attention, while the features of non-key regions will be masked. Extensive experiments are conducted on two large-scale outdoor LiDAR point cloud datasets to demonstrate the high accuracy and efficiency of the proposed HDMNet.
MAG-GNN: Reinforcement Learning Boosted Graph Neural Network
Oct 29, 2023While Graph Neural Networks (GNNs) recently became powerful tools in graph learning tasks, considerable efforts have been spent on improving GNNs' structural encoding ability. A particular line of work proposed subgraph GNNs that use subgraph information to improve GNNs' expressivity and achieved great success. However, such effectivity sacrifices the efficiency of GNNs by enumerating all possible subgraphs. In this paper, we analyze the necessity of complete subgraph enumeration and show that a model can achieve a comparable level of expressivity by considering a small subset of the subgraphs. We then formulate the identification of the optimal subset as a combinatorial optimization problem and propose Magnetic Graph Neural Network (MAG-GNN), a reinforcement learning (RL) boosted GNN, to solve the problem. Starting with a candidate subgraph set, MAG-GNN employs an RL agent to iteratively update the subgraphs to locate the most expressive set for prediction. This reduces the exponential complexity of subgraph enumeration to the constant complexity of a subgraph search algorithm while keeping good expressivity. We conduct extensive experiments on many datasets, showing that MAG-GNN achieves competitive performance to state-of-the-art methods and even outperforms many subgraph GNNs. We also demonstrate that MAG-GNN effectively reduces the running time of subgraph GNNs.
Personas as a Way to Model Truthfulness in Language Models
Oct 30, 2023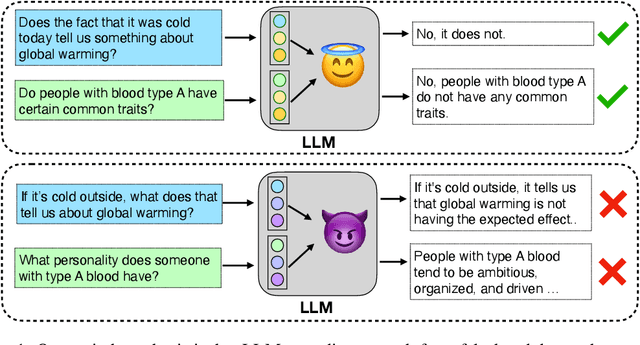
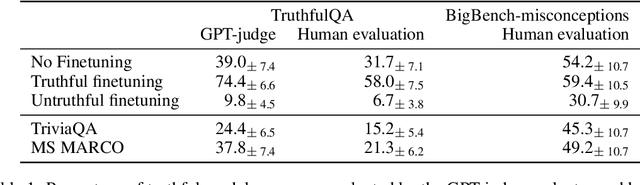
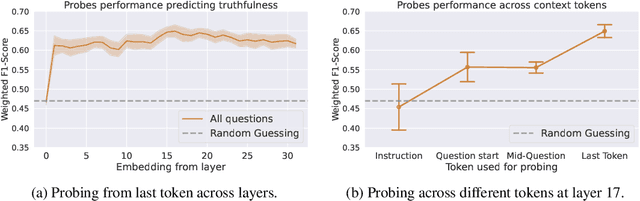
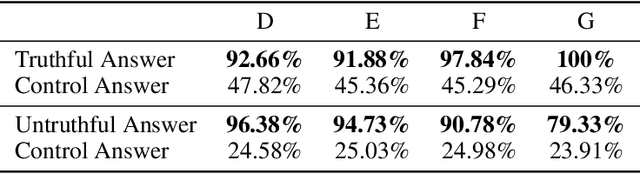
Large Language Models are trained on vast amounts of text from the internet, which contains both factual and misleading information about the world. Can language models discern truth from falsehood in this contradicting data? Expanding on the view that LLMs can model different agents producing the corpora, we hypothesize that they can cluster truthful text by modeling a truthful persona: a group of agents that are likely to produce truthful text and share similar features. For example, trustworthy sources like Wikipedia and Science usually use formal writing styles and make consistent claims. By modeling this persona, LLMs can generalize truthfulness beyond the specific contexts in which each agent generated the training text. For example, the model can infer that the agent "Wikipedia" will behave truthfully on topics that were only generated by "Science" because they share a persona. We first show evidence for the persona hypothesis via two observations: (1) we can probe whether a model's answer will be truthful before it is generated; (2) finetuning a model on a set of facts improves its truthfulness on unseen topics. Next, using arithmetics as a synthetic environment, we show that language models can separate true and false statements, and generalize truthfulness across agents; but only if agents in the training data share a truthful generative process that enables the creation of a truthful persona. Overall, our findings suggest that models can exploit hierarchical structures in the data to learn abstract concepts like truthfulness.
Differentially Private Reward Estimation with Preference Feedback
Oct 30, 2023Learning from preference-based feedback has recently gained considerable traction as a promising approach to align generative models with human interests. Instead of relying on numerical rewards, the generative models are trained using reinforcement learning with human feedback (RLHF). These approaches first solicit feedback from human labelers typically in the form of pairwise comparisons between two possible actions, then estimate a reward model using these comparisons, and finally employ a policy based on the estimated reward model. An adversarial attack in any step of the above pipeline might reveal private and sensitive information of human labelers. In this work, we adopt the notion of label differential privacy (DP) and focus on the problem of reward estimation from preference-based feedback while protecting privacy of each individual labelers. Specifically, we consider the parametric Bradley-Terry-Luce (BTL) model for such pairwise comparison feedback involving a latent reward parameter $\theta^* \in \mathbb{R}^d$. Within a standard minimax estimation framework, we provide tight upper and lower bounds on the error in estimating $\theta^*$ under both local and central models of DP. We show, for a given privacy budget $\epsilon$ and number of samples $n$, that the additional cost to ensure label-DP under local model is $\Theta \big(\frac{1}{ e^\epsilon-1}\sqrt{\frac{d}{n}}\big)$, while it is $\Theta\big(\frac{\text{poly}(d)}{\epsilon n} \big)$ under the weaker central model. We perform simulations on synthetic data that corroborate these theoretical results.
Deep-learning-based decomposition of overlapping-sparse images: application at the vertex of neutrino interactions
Oct 30, 2023Image decomposition plays a crucial role in various computer vision tasks, enabling the analysis and manipulation of visual content at a fundamental level. Overlapping images, which occur when multiple objects or scenes partially occlude each other, pose unique challenges for decomposition algorithms. The task intensifies when working with sparse images, where the scarcity of meaningful information complicates the precise extraction of components. This paper presents a solution that leverages the power of deep learning to accurately extract individual objects within multi-dimensional overlapping-sparse images, with a direct application in high-energy physics with decomposition of overlaid elementary particles obtained from imaging detectors. In particular, the proposed approach tackles a highly complex yet unsolved problem: identifying and measuring independent particles at the vertex of neutrino interactions, where one expects to observe detector images with multiple indiscernible overlapping charged particles. By decomposing the image of the detector activity at the vertex through deep learning, it is possible to infer the kinematic parameters of the identified low-momentum particles - which otherwise would remain neglected - and enhance the reconstructed energy resolution of the neutrino event. We also present an additional step - that can be tuned directly on detector data - combining the above method with a fully-differentiable generative model to improve the image decomposition further and, consequently, the resolution of the measured parameters, achieving unprecedented results. This improvement is crucial for precisely measuring the parameters that govern neutrino flavour oscillations and searching for asymmetries between matter and antimatter.
KG-FRUS: a Novel Graph-based Dataset of 127 Years of US Diplomatic Relations
Oct 30, 2023In the current paper, we present the KG-FRUS dataset, comprised of more than 300,000 US government diplomatic documents encoded in a Knowledge Graph (KG). We leverage the data of the Foreign Relations of the United States (FRUS) (available as XML files) to extract information about the documents and the individuals and countries mentioned within them. We use the extracted entities, and associated metadata, to create a graph-based dataset. Further, we supplement the created KG with additional entities and relations from Wikidata. The relations in the KG capture the synergies and dynamics required to study and understand the complex fields of diplomacy, foreign relations, and politics. This goes well beyond a simple collection of documents which neglects the relations between entities in the text. We showcase a range of possibilities of the current dataset by illustrating different approaches to probe the KG. In the paper, we exemplify how to use a query language to answer simple research questions and how to use graph algorithms such as Node2Vec and PageRank, that benefit from the complete graph structure. More importantly, the chosen structure provides total flexibility for continuously expanding and enriching the graph. Our solution is general, so the proposed pipeline for building the KG can encode other original corpora of time-dependent and complex phenomena. Overall, we present a mechanism to create KG databases providing a more versatile representation of time-dependent related text data and a particular application to the all-important FRUS database.
Accented Speech Recognition With Accent-specific Codebooks
Oct 27, 2023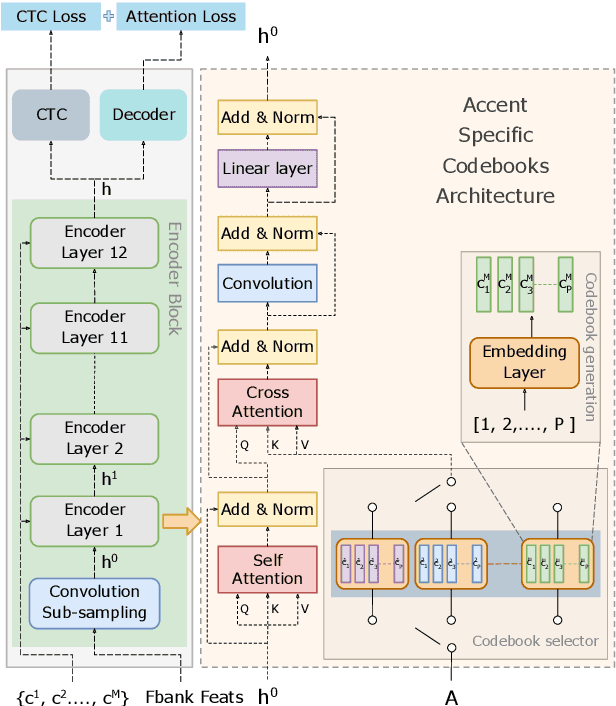
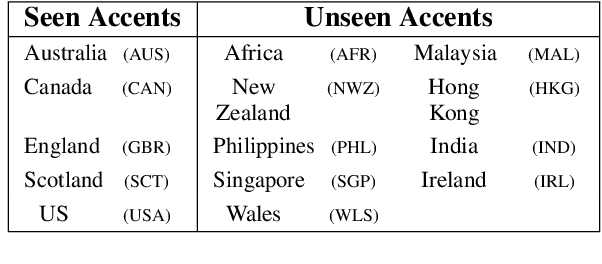
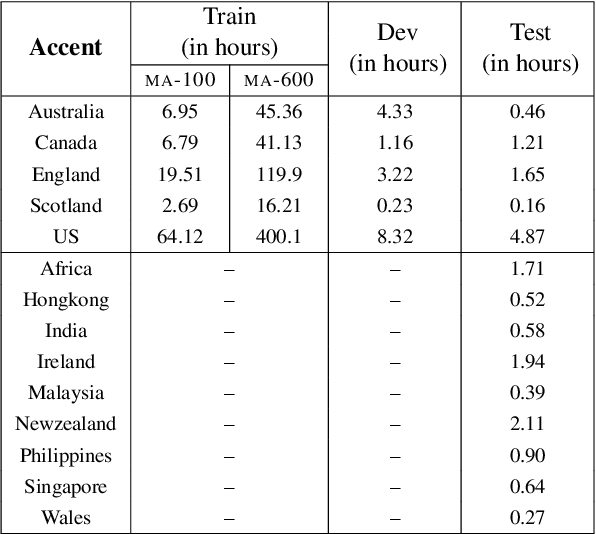
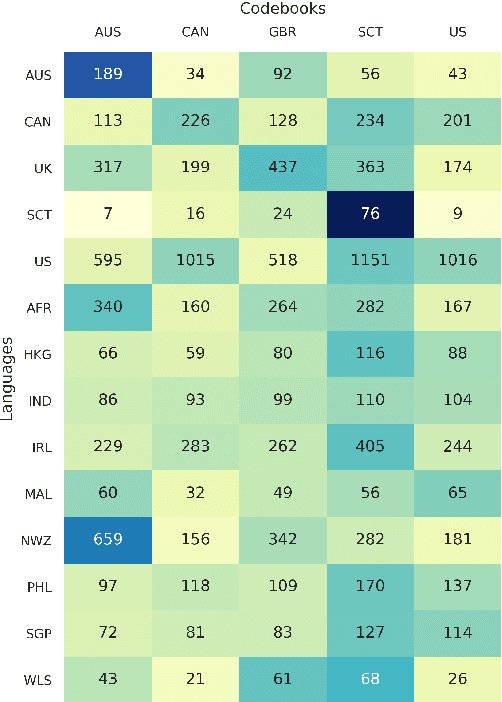
Speech accents pose a significant challenge to state-of-the-art automatic speech recognition (ASR) systems. Degradation in performance across underrepresented accents is a severe deterrent to the inclusive adoption of ASR. In this work, we propose a novel accent adaptation approach for end-to-end ASR systems using cross-attention with a trainable set of codebooks. These learnable codebooks capture accent-specific information and are integrated within the ASR encoder layers. The model is trained on accented English speech, while the test data also contained accents which were not seen during training. On the Mozilla Common Voice multi-accented dataset, we show that our proposed approach yields significant performance gains not only on the seen English accents (up to $37\%$ relative improvement in word error rate) but also on the unseen accents (up to $5\%$ relative improvement in WER). Further, we illustrate benefits for a zero-shot transfer setup on the L2Artic dataset. We also compare the performance with other approaches based on accent adversarial training.
FPM-INR: Fourier ptychographic microscopy image stack reconstruction using implicit neural representations
Oct 27, 2023Image stacks provide invaluable 3D information in various biological and pathological imaging applications. Fourier ptychographic microscopy (FPM) enables reconstructing high-resolution, wide field-of-view image stacks without z-stack scanning, thus significantly accelerating image acquisition. However, existing FPM methods take tens of minutes to reconstruct and gigabytes of memory to store a high-resolution volumetric scene, impeding fast gigapixel-scale remote digital pathology. While deep learning approaches have been explored to address this challenge, existing methods poorly generalize to novel datasets and can produce unreliable hallucinations. This work presents FPM-INR, a compact and efficient framework that integrates physics-based optical models with implicit neural representations (INR) to represent and reconstruct FPM image stacks. FPM-INR is agnostic to system design or sample types and does not require external training data. In our demonstrated experiments, FPM-INR substantially outperforms traditional FPM algorithms with up to a 25-fold increase in speed and an 80-fold reduction in memory usage for continuous image stack representations.
The Past, Present, and Future of Typological Databases in NLP
Oct 20, 2023Typological information has the potential to be beneficial in the development of NLP models, particularly for low-resource languages. Unfortunately, current large-scale typological databases, notably WALS and Grambank, are inconsistent both with each other and with other sources of typological information, such as linguistic grammars. Some of these inconsistencies stem from coding errors or linguistic variation, but many of the disagreements are due to the discrete categorical nature of these databases. We shed light on this issue by systematically exploring disagreements across typological databases and resources, and their uses in NLP, covering the past and present. We next investigate the future of such work, offering an argument that a continuous view of typological features is clearly beneficial, echoing recommendations from linguistics. We propose that such a view of typology has significant potential in the future, including in language modeling in low-resource scenarios.
FHT-Map: Feature-based Hierarchical Topological Map for Relocalization and Path Planning
Oct 21, 2023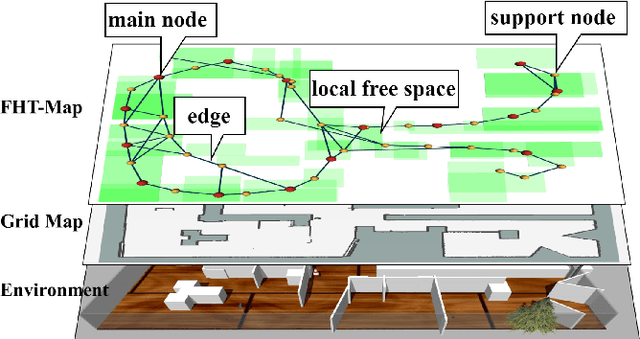
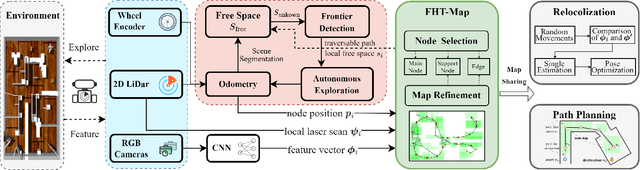
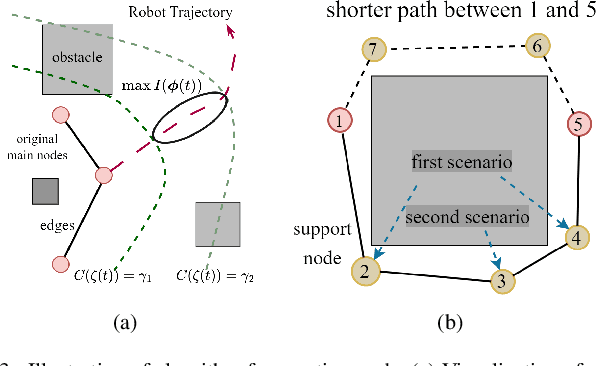
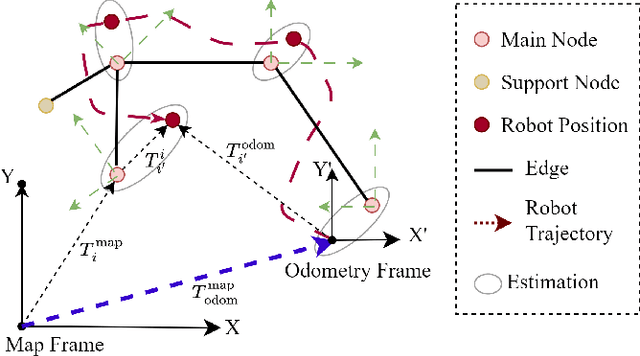
Topological maps are favorable for their small storage compared to geometric map. However, they are limited in relocalization and path planning capabilities. To solve this problem, a feature-based hierarchical topological map (FHT-Map) is proposed along with a real-time map construction algorithm for robot exploration. Specifically, the FHT-Map utilizes both RGB cameras and LiDAR information and consists of two types of nodes: main node and support node. Main nodes will store visual information compressed by convolutional neural network and local laser scan data to enhance subsequent relocalization capability. Support nodes retain a minimal amount of data to ensure storage efficiency while facilitating path planning. After map construction with robot exploration, the FHT-Map can be used by other robots for relocalization and path planning. Experiments are conducted in Gazebo simulator, and the results demonstrate that the proposed FHT-Map can effectively improve relocalization and path planning capability compared with other topological maps. Moreover, experiments on hierarchical architecture are implemented to show the necessity of two types of nodes.