 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Key Point-based Orientation Estimation of Strawberries for Robotic Fruit Picking
Oct 17, 2023
Selective robotic harvesting is a promising technological solution to address labour shortages which are affecting modern agriculture in many parts of the world. For an accurate and efficient picking process, a robotic harvester requires the precise location and orientation of the fruit to effectively plan the trajectory of the end effector. The current methods for estimating fruit orientation employ either complete 3D information which typically requires registration from multiple views or rely on fully-supervised learning techniques, which require difficult-to-obtain manual annotation of the reference orientation. In this paper, we introduce a novel key-point-based fruit orientation estimation method allowing for the prediction of 3D orientation from 2D images directly. The proposed technique can work without full 3D orientation annotations but can also exploit such information for improved accuracy. We evaluate our work on two separate datasets of strawberry images obtained from real-world data collection scenarios. Our proposed method achieves state-of-the-art performance with an average error as low as $8^{\circ}$, improving predictions by $\sim30\%$ compared to previous work presented in~\cite{wagner2021efficient}. Furthermore, our method is suited for real-time robotic applications with fast inference times of $\sim30$ms.
Specify Robust Causal Representation from Mixed Observations
Oct 21, 2023Learning representations purely from observations concerns the problem of learning a low-dimensional, compact representation which is beneficial to prediction models. Under the hypothesis that the intrinsic latent factors follow some casual generative models, we argue that by learning a causal representation, which is the minimal sufficient causes of the whole system, we can improve the robustness and generalization performance of machine learning models. In this paper, we develop a learning method to learn such representation from observational data by regularizing the learning procedure with mutual information measures, according to the hypothetical factored causal graph. We theoretically and empirically show that the models trained with the learned causal representations are more robust under adversarial attacks and distribution shifts compared with baselines. The supplementary materials are available at https://github.com/ymy $4323460 / \mathrm{CaRI} /$.
Prevalence and prevention of large language model use in crowd work
Oct 24, 2023We show that the use of large language models (LLMs) is prevalent among crowd workers, and that targeted mitigation strategies can significantly reduce, but not eliminate, LLM use. On a text summarization task where workers were not directed in any way regarding their LLM use, the estimated prevalence of LLM use was around 30%, but was reduced by about half by asking workers to not use LLMs and by raising the cost of using them, e.g., by disabling copy-pasting. Secondary analyses give further insight into LLM use and its prevention: LLM use yields high-quality but homogeneous responses, which may harm research concerned with human (rather than model) behavior and degrade future models trained with crowdsourced data. At the same time, preventing LLM use may be at odds with obtaining high-quality responses; e.g., when requesting workers not to use LLMs, summaries contained fewer keywords carrying essential information. Our estimates will likely change as LLMs increase in popularity or capabilities, and as norms around their usage change. Yet, understanding the co-evolution of LLM-based tools and users is key to maintaining the validity of research done using crowdsourcing, and we provide a critical baseline before widespread adoption ensues.
A Mass-Conserving-Perceptron for Machine Learning-Based Modeling of Geoscientific Systems
Oct 24, 2023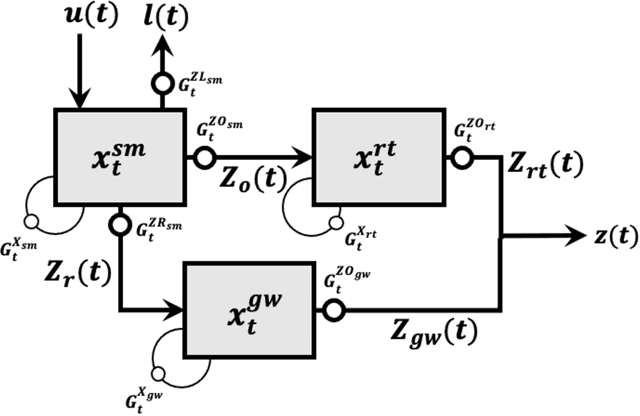
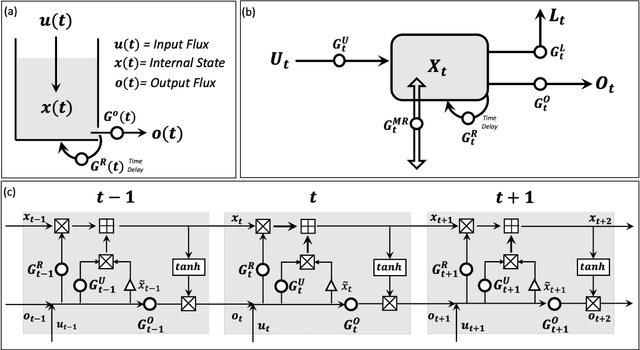
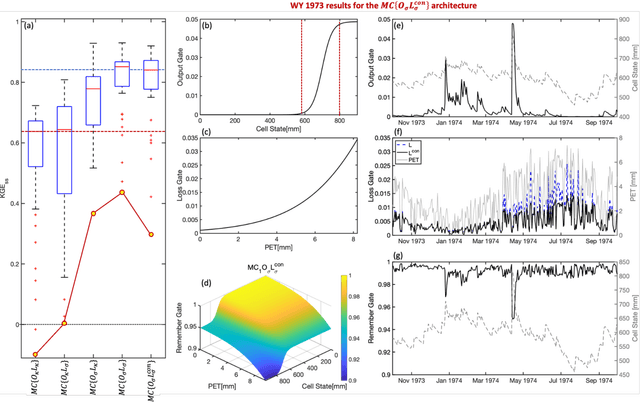
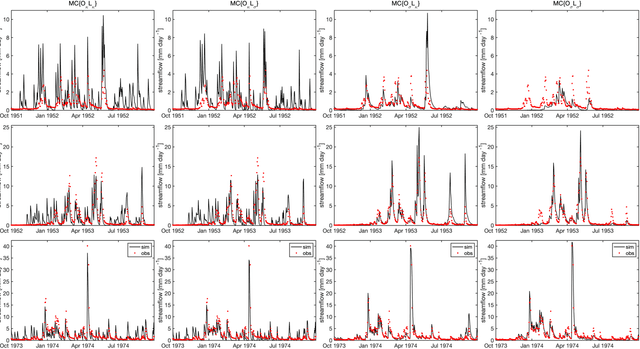
Although decades of effort have been devoted to building Physical-Conceptual (PC) models for predicting the time-series evolution of geoscientific systems, recent work shows that Machine Learning (ML) based Gated Recurrent Neural Network technology can be used to develop models that are much more accurate. However, the difficulty of extracting physical understanding from ML-based models complicates their utility for enhancing scientific knowledge regarding system structure and function. Here, we propose a physically-interpretable Mass Conserving Perceptron (MCP) as a way to bridge the gap between PC-based and ML-based modeling approaches. The MCP exploits the inherent isomorphism between the directed graph structures underlying both PC models and GRNNs to explicitly represent the mass-conserving nature of physical processes while enabling the functional nature of such processes to be directly learned (in an interpretable manner) from available data using off-the-shelf ML technology. As a proof of concept, we investigate the functional expressivity (capacity) of the MCP, explore its ability to parsimoniously represent the rainfall-runoff (RR) dynamics of the Leaf River Basin, and demonstrate its utility for scientific hypothesis testing. To conclude, we discuss extensions of the concept to enable ML-based physical-conceptual representation of the coupled nature of mass-energy-information flows through geoscientific systems.
GROVE: A Retrieval-augmented Complex Story Generation Framework with A Forest of Evidence
Oct 24, 2023Conditional story generation is significant in human-machine interaction, particularly in producing stories with complex plots. While Large language models (LLMs) perform well on multiple NLP tasks, including story generation, it is challenging to generate stories with both complex and creative plots. Existing methods often rely on detailed prompts to guide LLMs to meet target conditions, which inadvertently restrict the creative potential of the generated stories. We argue that leveraging information from exemplary human-written stories facilitates generating more diverse plotlines. Delving deeper into story details helps build complex and credible plots. In this paper, we propose a retrieval-au\textbf{G}mented sto\textbf{R}y generation framework with a f\textbf{O}rest of e\textbf{V}id\textbf{E}nce (GROVE) to enhance stories' complexity. We build a retrieval repository for target conditions to produce few-shot examples to prompt LLMs. Additionally, we design an ``asking-why'' prompting scheme that extracts a forest of evidence, providing compensation for the ambiguities that may occur in the generated story. This iterative process uncovers underlying story backgrounds. Finally, we select the most fitting chains of evidence from the evidence forest and integrate them into the generated story, thereby enhancing the narrative's complexity and credibility. Experimental results and numerous examples verify the effectiveness of our method.
Uncertainty in Automated Ontology Matching: Lessons Learned from an Empirical Experimentation
Oct 18, 2023Data integration is considered a classic research field and a pressing need within the information science community. Ontologies play a critical role in such a process by providing well-consolidated support to link and semantically integrate datasets via interoperability. This paper approaches data integration from an application perspective, looking at techniques based on ontology matching. An ontology-based process may only be considered adequate by assuming manual matching of different sources of information. However, since the approach becomes unrealistic once the system scales up, automation of the matching process becomes a compelling need. Therefore, we have conducted experiments on actual data with the support of existing tools for automatic ontology matching from the scientific community. Even considering a relatively simple case study (i.e., the spatio-temporal alignment of global indicators), outcomes clearly show significant uncertainty resulting from errors and inaccuracies along the automated matching process. More concretely, this paper aims to test on real-world data a bottom-up knowledge-building approach, discuss the lessons learned from the experimental results of the case study, and draw conclusions about uncertainty and uncertainty management in an automated ontology matching process. While the most common evaluation metrics clearly demonstrate the unreliability of fully automated matching solutions, properly designed semi-supervised approaches seem to be mature for a more generalized application.
Getting aligned on representational alignment
Oct 18, 2023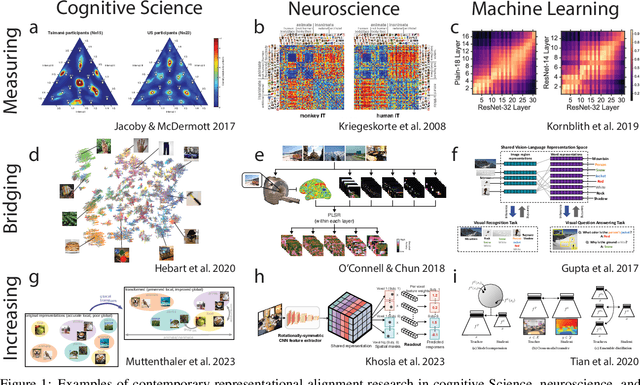
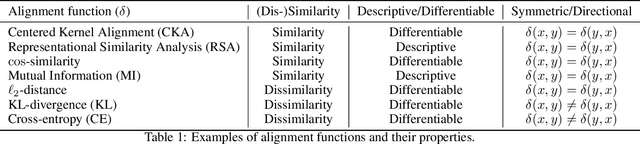
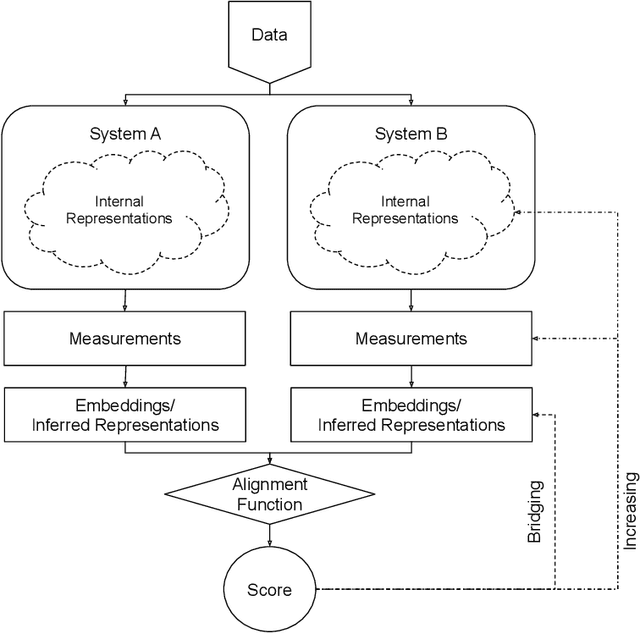
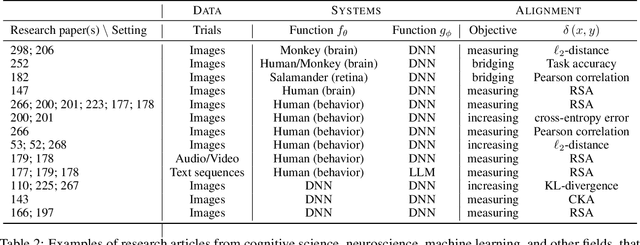
Biological and artificial information processing systems form representations of the world that they can use to categorize, reason, plan, navigate, and make decisions. To what extent do the representations formed by these diverse systems agree? Can diverging representations still lead to the same behaviors? And how can systems modify their representations to better match those of another system? These questions pertaining to the study of \textbf{\emph{representational alignment}} are at the heart of some of the most active research areas in contemporary cognitive science, neuroscience, and machine learning. Unfortunately, there is limited knowledge-transfer between research communities interested in representational alignment, and much of the progress in one field ends up being rediscovered independently in another, when greater cross-field communication would be advantageous. To improve communication between fields, we propose a unifying framework that can serve as a common language between researchers studying representational alignment. We survey the literature from the fields of cognitive science, neuroscience, and machine learning, and demonstrate how prior work fits into this framework. Finally, we lay out open problems in representational alignment where progress can benefit all three fields. We hope that our work can catalyze cross-disciplinary collaboration and accelerate progress for all communities studying and developing information processing systems. We note that this is a working paper and encourage readers to reach out with their suggestions for future revisions.
Dual Defense: Adversarial, Traceable, and Invisible Robust Watermarking against Face Swapping
Oct 25, 2023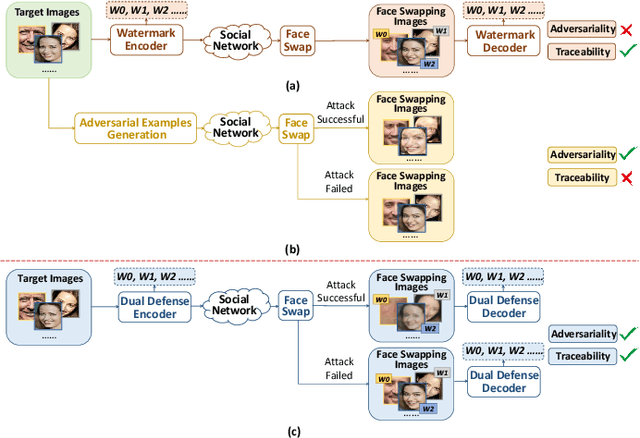
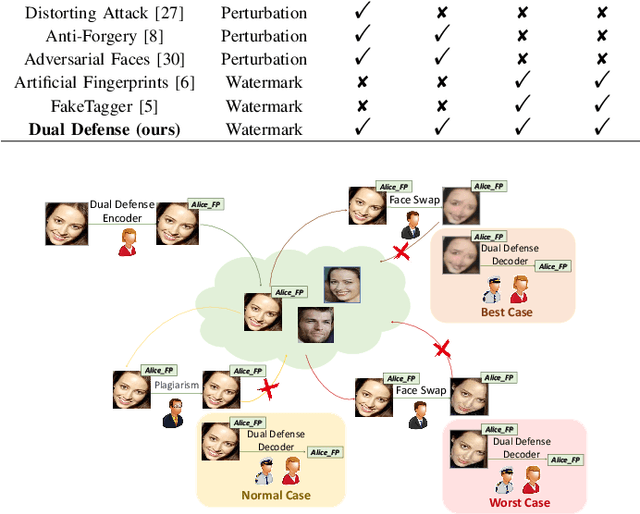
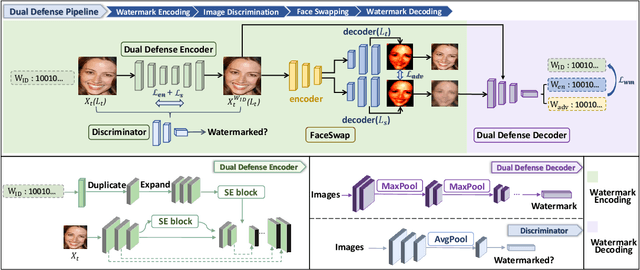
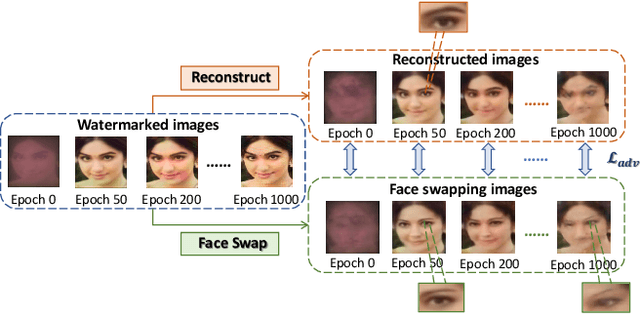
The malicious applications of deep forgery, represented by face swapping, have introduced security threats such as misinformation dissemination and identity fraud. While some research has proposed the use of robust watermarking methods to trace the copyright of facial images for post-event traceability, these methods cannot effectively prevent the generation of forgeries at the source and curb their dissemination. To address this problem, we propose a novel comprehensive active defense mechanism that combines traceability and adversariality, called Dual Defense. Dual Defense invisibly embeds a single robust watermark within the target face to actively respond to sudden cases of malicious face swapping. It disrupts the output of the face swapping model while maintaining the integrity of watermark information throughout the entire dissemination process. This allows for watermark extraction at any stage of image tracking for traceability. Specifically, we introduce a watermark embedding network based on original-domain feature impersonation attack. This network learns robust adversarial features of target facial images and embeds watermarks, seeking a well-balanced trade-off between watermark invisibility, adversariality, and traceability through perceptual adversarial encoding strategies. Extensive experiments demonstrate that Dual Defense achieves optimal overall defense success rates and exhibits promising universality in anti-face swapping tasks and dataset generalization ability. It maintains impressive adversariality and traceability in both original and robust settings, surpassing current forgery defense methods that possess only one of these capabilities, including CMUA-Watermark, Anti-Forgery, FakeTagger, or PGD methods.
Flow-Attention-based Spatio-Temporal Aggregation Network for 3D Mask Detection
Oct 25, 2023Anti-spoofing detection has become a necessity for face recognition systems due to the security threat posed by spoofing attacks. Despite great success in traditional attacks, most deep-learning-based methods perform poorly in 3D masks, which can highly simulate real faces in appearance and structure, suffering generalizability insufficiency while focusing only on the spatial domain with single frame input. This has been mitigated by the recent introduction of a biomedical technology called rPPG (remote photoplethysmography). However, rPPG-based methods are sensitive to noisy interference and require at least one second (> 25 frames) of observation time, which induces high computational overhead. To address these challenges, we propose a novel 3D mask detection framework, called FASTEN (Flow-Attention-based Spatio-Temporal aggrEgation Network). We tailor the network for focusing more on fine-grained details in large movements, which can eliminate redundant spatio-temporal feature interference and quickly capture splicing traces of 3D masks in fewer frames. Our proposed network contains three key modules: 1) a facial optical flow network to obtain non-RGB inter-frame flow information; 2) flow attention to assign different significance to each frame; 3) spatio-temporal aggregation to aggregate high-level spatial features and temporal transition features. Through extensive experiments, FASTEN only requires five frames of input and outperforms eight competitors for both intra-dataset and cross-dataset evaluations in terms of multiple detection metrics. Moreover, FASTEN has been deployed in real-world mobile devices for practical 3D mask detection.
Distance Weighted Trans Network for Image Completion
Oct 25, 2023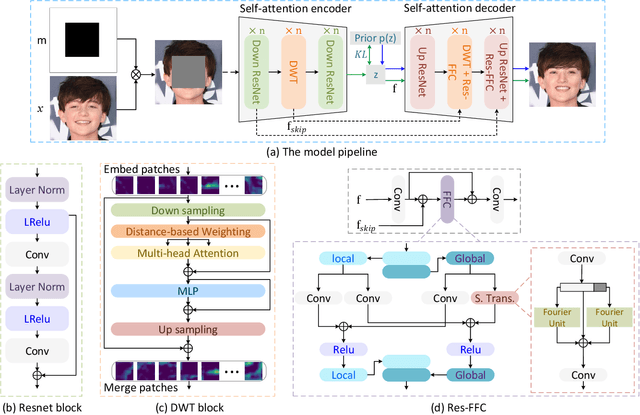
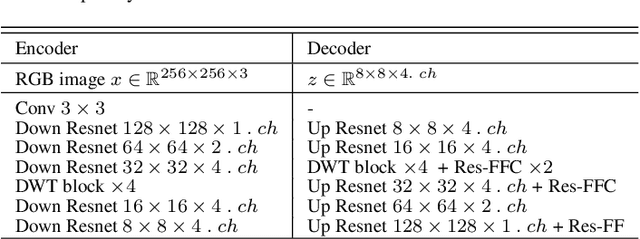

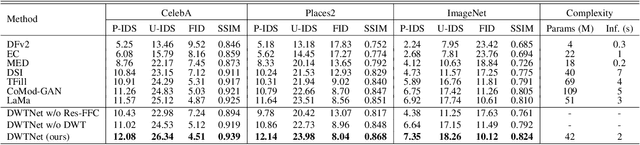
The challenge of image generation has been effectively modeled as a problem of structure priors or transformation. However, existing models have unsatisfactory performance in understanding the global input image structures because of particular inherent features (for example, local inductive prior). Recent studies have shown that self-attention is an efficient modeling technique for image completion problems. In this paper, we propose a new architecture that relies on Distance-based Weighted Transformer (DWT) to better understand the relationships between an image's components. In our model, we leverage the strengths of both Convolutional Neural Networks (CNNs) and DWT blocks to enhance the image completion process. Specifically, CNNs are used to augment the local texture information of coarse priors and DWT blocks are used to recover certain coarse textures and coherent visual structures. Unlike current approaches that generally use CNNs to create feature maps, we use the DWT to encode global dependencies and compute distance-based weighted feature maps, which substantially minimizes the problem of visual ambiguities. Meanwhile, to better produce repeated textures, we introduce Residual Fast Fourier Convolution (Res-FFC) blocks to combine the encoder's skip features with the coarse features provided by our generator. Furthermore, a simple yet effective technique is proposed to normalize the non-zero values of convolutions, and fine-tune the network layers for regularization of the gradient norms to provide an efficient training stabiliser. Extensive quantitative and qualitative experiments on three challenging datasets demonstrate the superiority of our proposed model compared to existing approaches.