 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Comprehensive Representations with Richer Self for Text-to-Image Person Re-Identification
Oct 17, 2023
Text-to-image person re-identification (TIReID) retrieves pedestrian images of the same identity based on a query text. However, existing methods for TIReID typically treat it as a one-to-one image-text matching problem, only focusing on the relationship between image-text pairs within a view. The many-to-many matching between image-text pairs across views under the same identity is not taken into account, which is one of the main reasons for the poor performance of existing methods. To this end, we propose a simple yet effective framework, called LCR$^2$S, for modeling many-to-many correspondences of the same identity by learning comprehensive representations for both modalities from a novel perspective. We construct a support set for each image (text) by using other images (texts) under the same identity and design a multi-head attentional fusion module to fuse the image (text) and its support set. The resulting enriched image and text features fuse information from multiple views, which are aligned to train a "richer" TIReID model with many-to-many correspondences. Since the support set is unavailable during inference, we propose to distill the knowledge learned by the "richer" model into a lightweight model for inference with a single image/text as input. The lightweight model focuses on semantic association and reasoning of multi-view information, which can generate a comprehensive representation containing multi-view information with only a single-view input to perform accurate text-to-image retrieval during inference. In particular, we use the intra-modal features and inter-modal semantic relations of the "richer" model to supervise the lightweight model to inherit its powerful capability. Extensive experiments demonstrate the effectiveness of LCR$^2$S, and it also achieves new state-of-the-art performance on three popular TIReID datasets.
Minimally Informed Linear Discriminant Analysis: training an LDA model with unlabelled data
Oct 17, 2023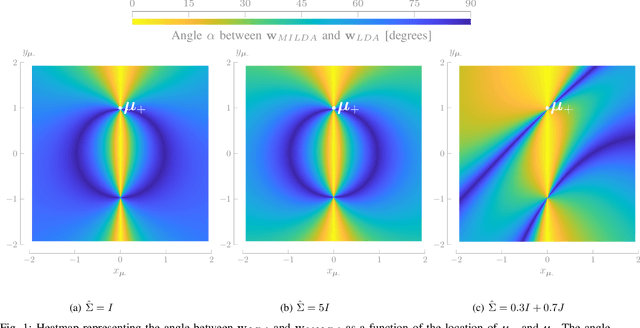
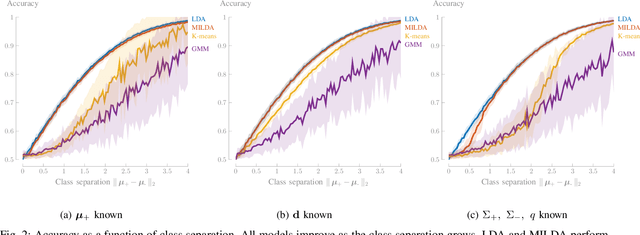
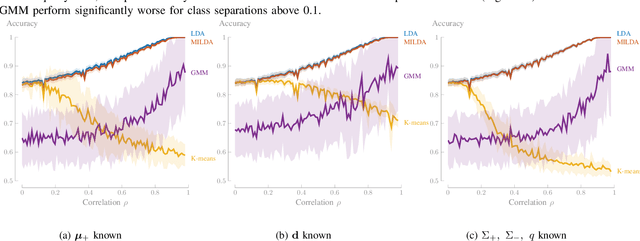
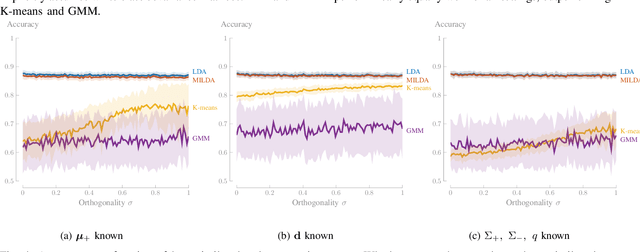
Linear Discriminant Analysis (LDA) is one of the oldest and most popular linear methods for supervised classification problems. In this paper, we demonstrate that it is possible to compute the exact projection vector from LDA models based on unlabelled data, if some minimal prior information is available. More precisely, we show that only one of the following three pieces of information is actually sufficient to compute the LDA projection vector if only unlabelled data are available: (1) the class average of one of the two classes, (2) the difference between both class averages (up to a scaling), or (3) the class covariance matrices (up to a scaling). These theoretical results are validated in numerical experiments, demonstrating that this minimally informed Linear Discriminant Analysis (MILDA) model closely matches the performance of a supervised LDA model. Furthermore, we show that the MILDA projection vector can be computed in a closed form with a computational cost comparable to LDA and is able to quickly adapt to non-stationary data, making it well-suited to use as an adaptive classifier.
Channel Autocorrelation Estimation for IRS-Aided Wireless Communications Based on Power Measurements
Oct 17, 2023Intelligent reflecting surface (IRS) can bring significant performance enhancement for wireless communication systems by reconfiguring wireless channels via passive signal reflection. However, such performance improvement generally relies on the knowledge of channel state information (CSI) for IRS-associated links. Prior IRS channel estimation strategies mainly estimate IRS-cascaded channels based on the excessive pilot signals received at the users/base station (BS) with time-varying IRS reflections, which, however, are not compatible with the existing channel training/estimation protocol for cellular networks. To address this issue, we propose in this paper a new channel estimation scheme for IRS-assisted communication systems based on the received signal power measured at the user, which is practically attainable without the need of changing the current protocol. Specifically, due to the lack of signal phase information in power measurements, the autocorrelation matrix of the BS-IRS-user cascaded channel is estimated by solving equivalent matrix-rank-minimization problems. Simulation results are provided to verify the effectiveness of the proposed channel estimation algorithm as well as the IRS passive reflection design based on the estimated channel autocorrelation matrix.
DialogueLLM: Context and Emotion Knowledge-Tuned LLaMA Models for Emotion Recognition in Conversations
Oct 17, 2023

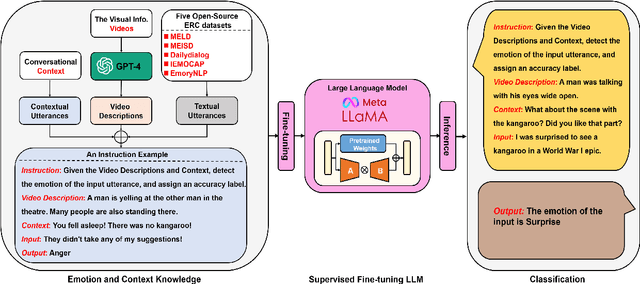

Large language models (LLMs) and their variants have shown extraordinary efficacy across numerous downstream natural language processing (NLP) tasks, which has presented a new vision for the development of NLP. Despite their remarkable performance in natural language generating (NLG), LLMs lack a distinct focus on the emotion understanding domain. As a result, using LLMs for emotion recognition may lead to suboptimal and inadequate precision. Another limitation of LLMs is that they are typical trained without leveraging multi-modal information. To overcome these limitations, we propose DialogueLLM, a context and emotion knowledge tuned LLM that is obtained by fine-tuning LLaMA models with 13,638 multi-modal (i.e., texts and videos) emotional dialogues. The visual information is considered as the supplementary knowledge to construct high-quality instructions. We offer a comprehensive evaluation of our proposed model on three benchmarking emotion recognition in conversations (ERC) datasets and compare the results against the SOTA baselines and other SOTA LLMs. Additionally, DialogueLLM-7B can be easily trained using LoRA on a 40GB A100 GPU in 5 hours, facilitating reproducibility for other researchers.
LLM4DyG: Can Large Language Models Solve Problems on Dynamic Graphs?
Oct 26, 2023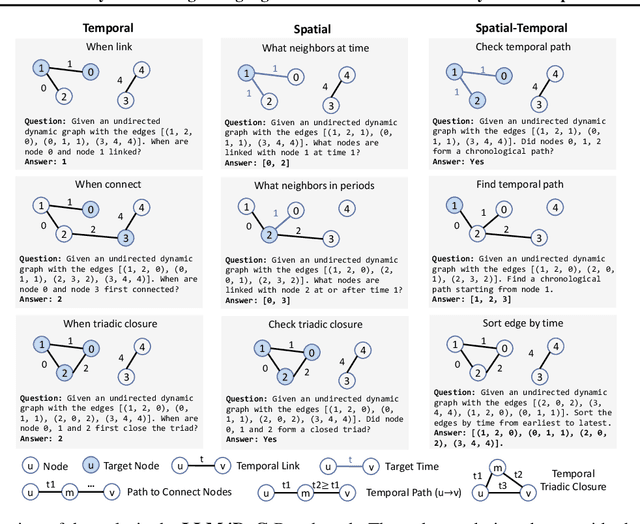
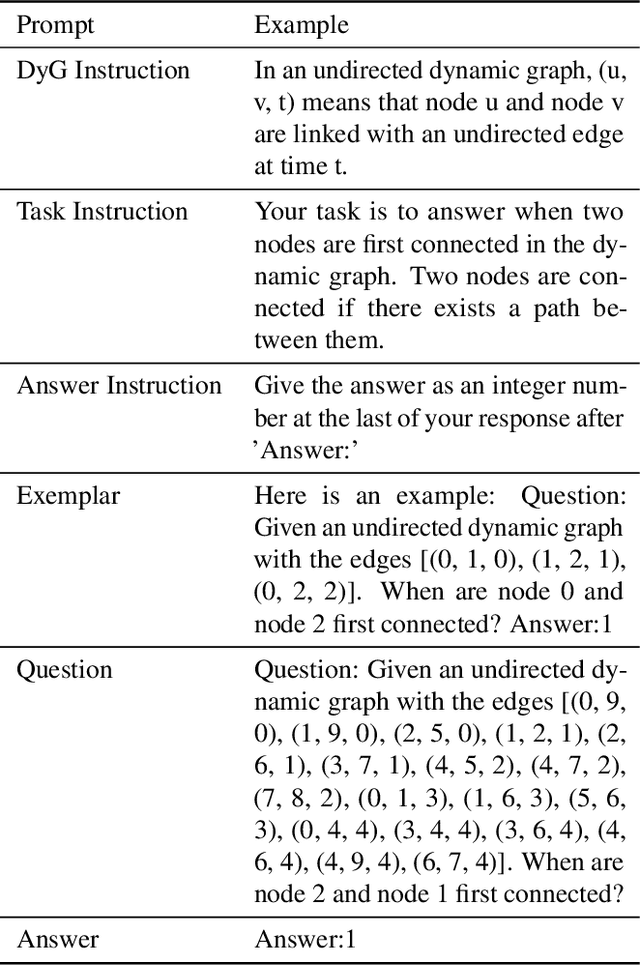

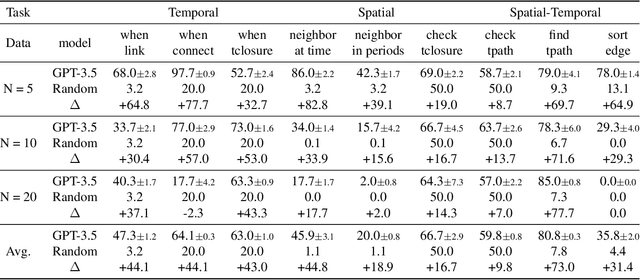
In an era marked by the increasing adoption of Large Language Models (LLMs) for various tasks, there is a growing focus on exploring LLMs' capabilities in handling web data, particularly graph data. Dynamic graphs, which capture temporal network evolution patterns, are ubiquitous in real-world web data. Evaluating LLMs' competence in understanding spatial-temporal information on dynamic graphs is essential for their adoption in web applications, which remains unexplored in the literature. In this paper, we bridge the gap via proposing to evaluate LLMs' spatial-temporal understanding abilities on dynamic graphs, to the best of our knowledge, for the first time. Specifically, we propose the LLM4DyG benchmark, which includes nine specially designed tasks considering the capability evaluation of LLMs from both temporal and spatial dimensions. Then, we conduct extensive experiments to analyze the impacts of different data generators, data statistics, prompting techniques, and LLMs on the model performance. Finally, we propose Disentangled Spatial-Temporal Thoughts (DST2) for LLMs on dynamic graphs to enhance LLMs' spatial-temporal understanding abilities. Our main observations are: 1) LLMs have preliminary spatial-temporal understanding abilities on dynamic graphs, 2) Dynamic graph tasks show increasing difficulties for LLMs as the graph size and density increase, while not sensitive to the time span and data generation mechanism, 3) the proposed DST2 prompting method can help to improve LLMs' spatial-temporal understanding abilities on dynamic graphs for most tasks. The data and codes will be open-sourced at publication time.
Model-Based Runtime Monitoring with Interactive Imitation Learning
Oct 26, 2023
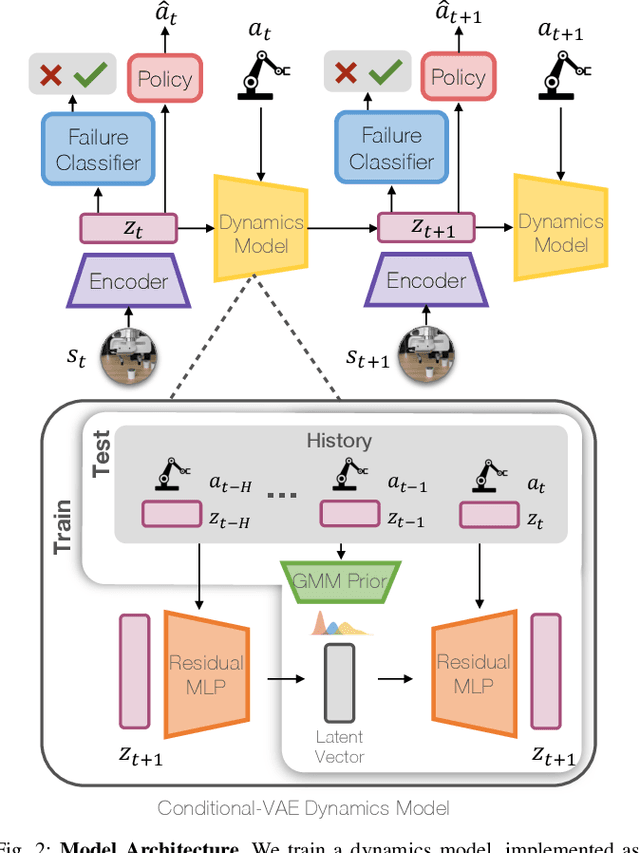
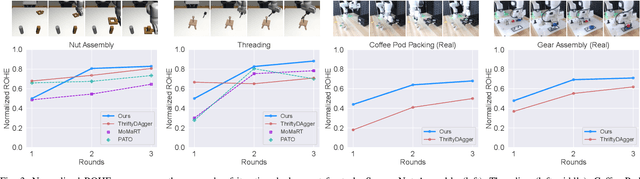
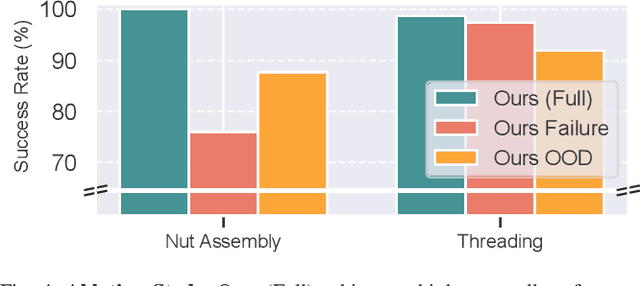
Robot learning methods have recently made great strides, but generalization and robustness challenges still hinder their widespread deployment. Failing to detect and address potential failures renders state-of-the-art learning systems not combat-ready for high-stakes tasks. Recent advances in interactive imitation learning have presented a promising framework for human-robot teaming, enabling the robots to operate safely and continually improve their performances over long-term deployments. Nonetheless, existing methods typically require constant human supervision and preemptive feedback, limiting their practicality in realistic domains. This work aims to endow a robot with the ability to monitor and detect errors during task execution. We introduce a model-based runtime monitoring algorithm that learns from deployment data to detect system anomalies and anticipate failures. Unlike prior work that cannot foresee future failures or requires failure experiences for training, our method learns a latent-space dynamics model and a failure classifier, enabling our method to simulate future action outcomes and detect out-of-distribution and high-risk states preemptively. We train our method within an interactive imitation learning framework, where it continually updates the model from the experiences of the human-robot team collected using trustworthy deployments. Consequently, our method reduces the human workload needed over time while ensuring reliable task execution. Our method outperforms the baselines across system-level and unit-test metrics, with 23% and 40% higher success rates in simulation and on physical hardware, respectively. More information at https://ut-austin-rpl.github.io/sirius-runtime-monitor/
Towards Unifying Diffusion Models for Probabilistic Spatio-Temporal Graph Learning
Oct 26, 2023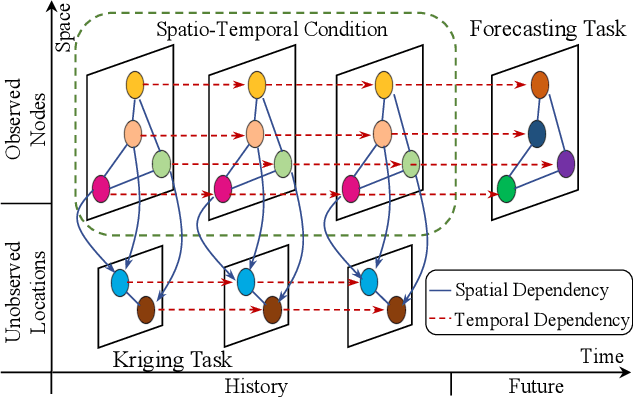

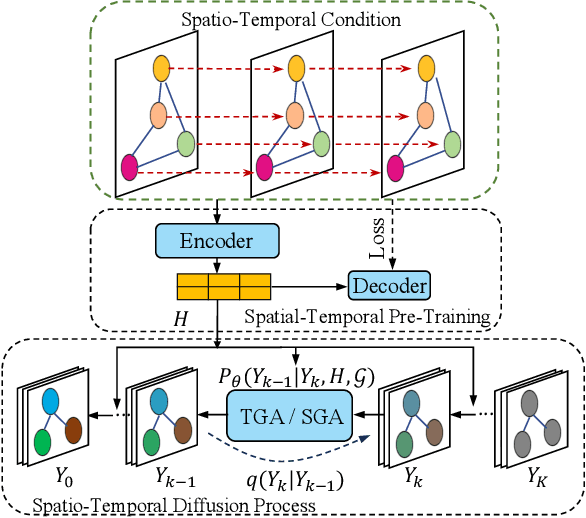
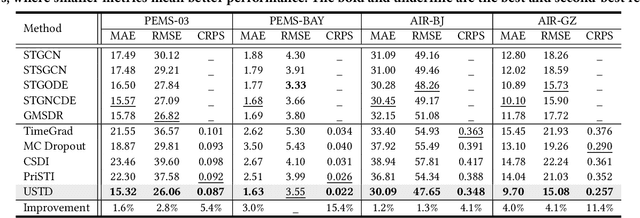
Spatio-temporal graph learning is a fundamental problem in the Web of Things era, which enables a plethora of Web applications such as smart cities, human mobility and climate analysis. Existing approaches tackle different learning tasks independently, tailoring their models to unique task characteristics. These methods, however, fall short of modeling intrinsic uncertainties in the spatio-temporal data. Meanwhile, their specialized designs limit their universality as general spatio-temporal learning solutions. In this paper, we propose to model the learning tasks in a unified perspective, viewing them as predictions based on conditional information with shared spatio-temporal patterns. Based on this proposal, we introduce Unified Spatio-Temporal Diffusion Models (USTD) to address the tasks uniformly within the uncertainty-aware diffusion framework. USTD is holistically designed, comprising a shared spatio-temporal encoder and attention-based denoising networks that are task-specific. The shared encoder, optimized by a pre-training strategy, effectively captures conditional spatio-temporal patterns. The denoising networks, utilizing both cross- and self-attention, integrate conditional dependencies and generate predictions. Opting for forecasting and kriging as downstream tasks, we design Gated Attention (SGA) and Temporal Gated Attention (TGA) for each task, with different emphases on the spatial and temporal dimensions, respectively. By combining the advantages of deterministic encoders and probabilistic diffusion models, USTD achieves state-of-the-art performances compared to deterministic and probabilistic baselines in both tasks, while also providing valuable uncertainty estimates.
Does Graph Distillation See Like Vision Dataset Counterpart?
Oct 13, 2023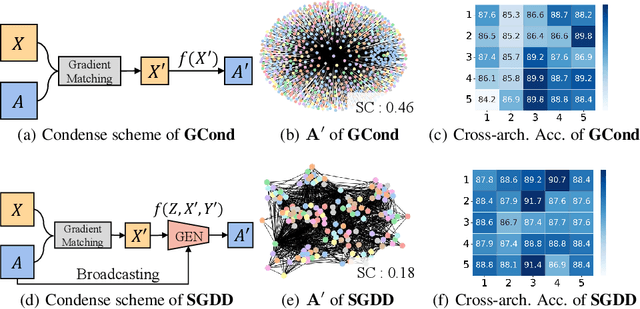
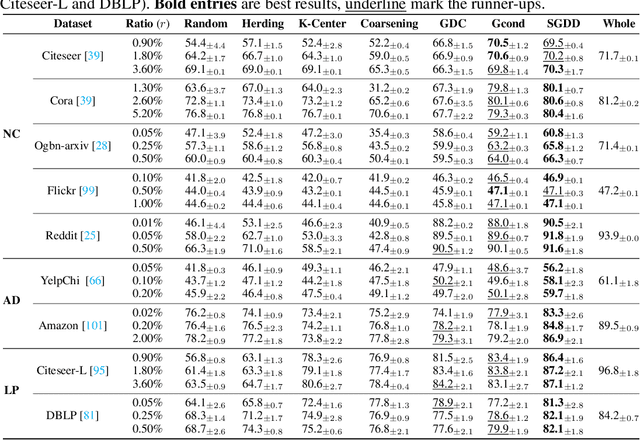
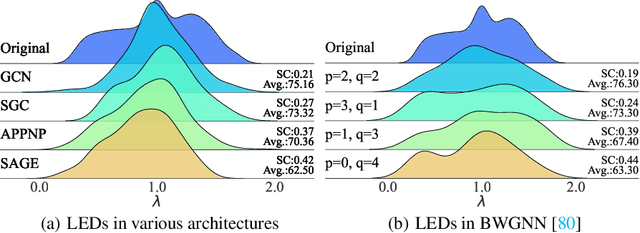
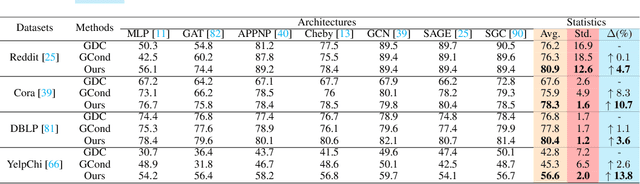
Training on large-scale graphs has achieved remarkable results in graph representation learning, but its cost and storage have attracted increasing concerns. Existing graph condensation methods primarily focus on optimizing the feature matrices of condensed graphs while overlooking the impact of the structure information from the original graphs. To investigate the impact of the structure information, we conduct analysis from the spectral domain and empirically identify substantial Laplacian Energy Distribution (LED) shifts in previous works. Such shifts lead to poor performance in cross-architecture generalization and specific tasks, including anomaly detection and link prediction. In this paper, we propose a novel Structure-broadcasting Graph Dataset Distillation (SGDD) scheme for broadcasting the original structure information to the generation of the synthetic one, which explicitly prevents overlooking the original structure information. Theoretically, the synthetic graphs by SGDD are expected to have smaller LED shifts than previous works, leading to superior performance in both cross-architecture settings and specific tasks. We validate the proposed SGDD across 9 datasets and achieve state-of-the-art results on all of them: for example, on the YelpChi dataset, our approach maintains 98.6% test accuracy of training on the original graph dataset with 1,000 times saving on the scale of the graph. Moreover, we empirically evaluate there exist 17.6% ~ 31.4% reductions in LED shift crossing 9 datasets. Extensive experiments and analysis verify the effectiveness and necessity of the proposed designs. The code is available in the GitHub repository: https://github.com/RingBDStack/SGDD.
ClusVPR: Efficient Visual Place Recognition with Clustering-based Weighted Transformer
Oct 12, 2023

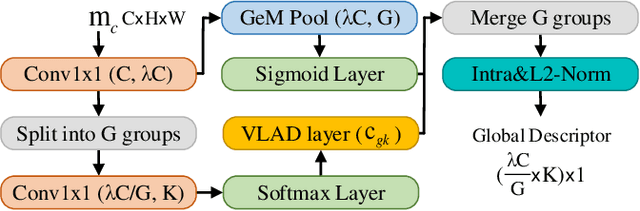
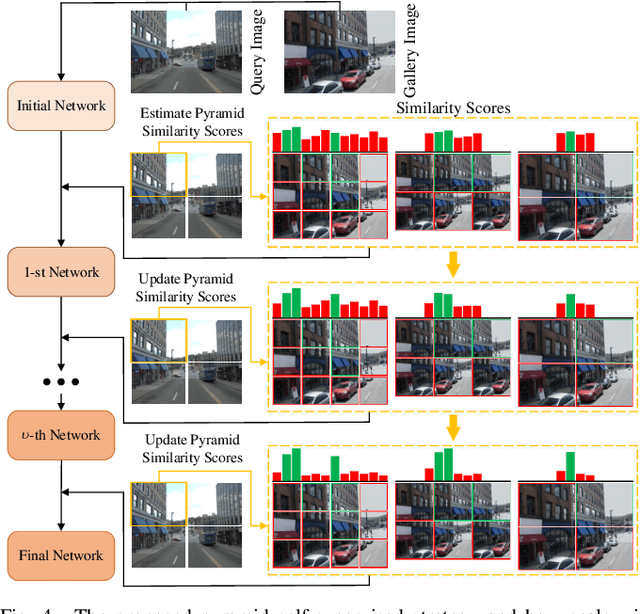
Visual place recognition (VPR) is a highly challenging task that has a wide range of applications, including robot navigation and self-driving vehicles. VPR is particularly difficult due to the presence of duplicate regions and the lack of attention to small objects in complex scenes, resulting in recognition deviations. In this paper, we present ClusVPR, a novel approach that tackles the specific issues of redundant information in duplicate regions and representations of small objects. Different from existing methods that rely on Convolutional Neural Networks (CNNs) for feature map generation, ClusVPR introduces a unique paradigm called Clustering-based Weighted Transformer Network (CWTNet). CWTNet leverages the power of clustering-based weighted feature maps and integrates global dependencies to effectively address visual deviations encountered in large-scale VPR problems. We also introduce the optimized-VLAD (OptLAD) layer that significantly reduces the number of parameters and enhances model efficiency. This layer is specifically designed to aggregate the information obtained from scale-wise image patches. Additionally, our pyramid self-supervised strategy focuses on extracting representative and diverse information from scale-wise image patches instead of entire images, which is crucial for capturing representative and diverse information in VPR. Extensive experiments on four VPR datasets show our model's superior performance compared to existing models while being less complex.
Generative Intrinsic Optimization: Intrisic Control with Model Learning
Oct 12, 2023Future sequence represents the outcome after executing the action into the environment. When driven by the information-theoretic concept of mutual information, it seeks maximally informative consequences. Explicit outcomes may vary across state, return, or trajectory serving different purposes such as credit assignment or imitation learning. However, the inherent nature of incorporating intrinsic motivation with reward maximization is often neglected. In this work, we propose a variational approach to jointly learn the necessary quantity for estimating the mutual information and the dynamics model, providing a general framework for incorporating different forms of outcomes of interest. Integrated into a policy iteration scheme, our approach guarantees convergence to the optimal policy. While we mainly focus on theoretical analysis, our approach opens the possibilities of leveraging intrinsic control with model learning to enhance sample efficiency and incorporate uncertainty of the environment into decision-making.