 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Simple and Asymmetric Graph Contrastive Learning without Augmentations
Oct 29, 2023
Graph Contrastive Learning (GCL) has shown superior performance in representation learning in graph-structured data. Despite their success, most existing GCL methods rely on prefabricated graph augmentation and homophily assumptions. Thus, they fail to generalize well to heterophilic graphs where connected nodes may have different class labels and dissimilar features. In this paper, we study the problem of conducting contrastive learning on homophilic and heterophilic graphs. We find that we can achieve promising performance simply by considering an asymmetric view of the neighboring nodes. The resulting simple algorithm, Asymmetric Contrastive Learning for Graphs (GraphACL), is easy to implement and does not rely on graph augmentations and homophily assumptions. We provide theoretical and empirical evidence that GraphACL can capture one-hop local neighborhood information and two-hop monophily similarity, which are both important for modeling heterophilic graphs. Experimental results show that the simple GraphACL significantly outperforms state-of-the-art graph contrastive learning and self-supervised learning methods on homophilic and heterophilic graphs. The code of GraphACL is available at https://github.com/tengxiao1/GraphACL.
Transport-of-Intensity Model for Single-Mask X-ray Differential Phase Contrast Imaging
Oct 29, 2023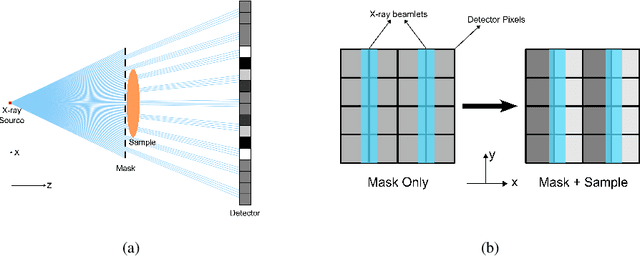
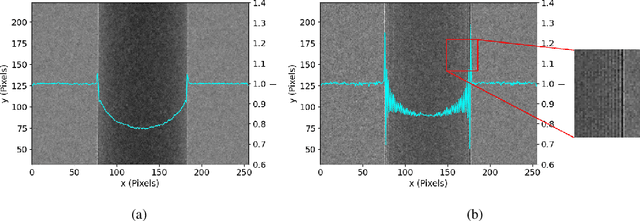
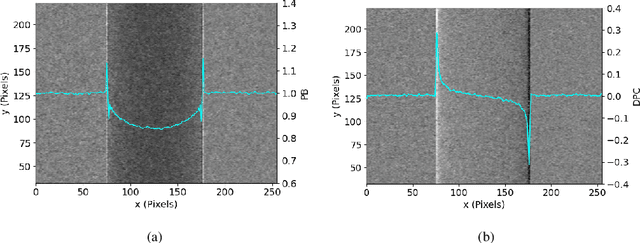

X-ray phase contrast imaging has emerged as a promising technique for enhancing contrast and visibility of light-element materials, including soft tissues and tumors. In this paper, we propose a novel model for a single-mask phase imaging system based on the transport-of-intensity equation. Our model offers an intuitive understanding of signal and contrast formation in single-mask phase imaging systems. We also demonstrate efficient retrieval of attenuation and differential phase contrast with just one intensity image without requiring spectral information or mask/detector movement. The model validity as well as the proposed retrieval method is demonstrated via both experimental results on a system developed in-house as well as with Monte Carlo simulations. Our proposed model overcomes the limitations of existing models by providing an intuitive visualization of the image formation process. It also allows optimizing differential phase imaging geometries for practical applications, further enhancing broader applicability. Furthermore, the general methodology described herein offers insight on deriving transport-of-intensity models for novel X-ray imaging systems with periodic structures in the beam path.
Fully Onboard Low-Power Localization with Semantic Sensor Fusion on a Nano-UAV using Floor Plans
Oct 19, 2023Nano-sized unmanned aerial vehicles (UAVs) are well-fit for indoor applications and for close proximity to humans. To enable autonomy, the nano-UAV must be able to self-localize in its operating environment. This is a particularly-challenging task due to the limited sensing and compute resources on board. This work presents an online and onboard approach for localization in floor plans annotated with semantic information. Unlike sensor-based maps, floor plans are readily-available, and do not increase the cost and time of deployment. To overcome the difficulty of localizing in sparse maps, the proposed approach fuses geometric information from miniaturized time-of-flight sensors and semantic cues. The semantic information is extracted from images by deploying a state-of-the-art object detection model on a high-performance multi-core microcontroller onboard the drone, consuming only 2.5mJ per frame and executing in 38ms. In our evaluation, we globally localize in a real-world office environment, achieving 90% success rate. We also release an open-source implementation of our work.
Enhancing Cross-Dataset Performance of Distracted Driving Detection With Score-Softmax Classifier
Oct 20, 2023Deep neural networks enable real-time monitoring of in-vehicle driver, facilitating the timely prediction of distractions, fatigue, and potential hazards. This technology is now integral to intelligent transportation systems. Recent research has exposed unreliable cross-dataset end-to-end driver behavior recognition due to overfitting, often referred to as ``shortcut learning", resulting from limited data samples. In this paper, we introduce the Score-Softmax classifier, which addresses this issue by enhancing inter-class independence and Intra-class uncertainty. Motivated by human rating patterns, we designed a two-dimensional supervisory matrix based on marginal Gaussian distributions to train the classifier. Gaussian distributions help amplify intra-class uncertainty while ensuring the Score-Softmax classifier learns accurate knowledge. Furthermore, leveraging the summation of independent Gaussian distributed random variables, we introduced a multi-channel information fusion method. This strategy effectively resolves the multi-information fusion challenge for the Score-Softmax classifier. Concurrently, we substantiate the necessity of transfer learning and multi-dataset combination. We conducted cross-dataset experiments using the SFD, AUCDD-V1, and 100-Driver datasets, demonstrating that Score-Softmax improves cross-dataset performance without modifying the model architecture. This provides a new approach for enhancing neural network generalization. Additionally, our information fusion approach outperforms traditional methods.
Enhancing Document-level Event Argument Extraction with Contextual Clues and Role Relevance
Oct 20, 2023Document-level event argument extraction poses new challenges of long input and cross-sentence inference compared to its sentence-level counterpart. However, most prior works focus on capturing the relations between candidate arguments and the event trigger in each event, ignoring two crucial points: a) non-argument contextual clue information; b) the relevance among argument roles. In this paper, we propose a SCPRG (Span-trigger-based Contextual Pooling and latent Role Guidance) model, which contains two novel and effective modules for the above problem. The Span-Trigger-based Contextual Pooling(STCP) adaptively selects and aggregates the information of non-argument clue words based on the context attention weights of specific argument-trigger pairs from pre-trained model. The Role-based Latent Information Guidance (RLIG) module constructs latent role representations, makes them interact through role-interactive encoding to capture semantic relevance, and merges them into candidate arguments. Both STCP and RLIG introduce no more than 1% new parameters compared with the base model and can be easily applied to other event extraction models, which are compact and transplantable. Experiments on two public datasets show that our SCPRG outperforms previous state-of-the-art methods, with 1.13 F1 and 2.64 F1 improvements on RAMS and WikiEvents respectively. Further analyses illustrate the interpretability of our model.
Augment with Care: Enhancing Graph Contrastive Learning with Selective Spectrum Perturbation
Oct 20, 2023In recent years, Graph Contrastive Learning (GCL) has shown remarkable effectiveness in learning representations on graphs. As a component of GCL, good augmentation views are supposed to be invariant to the important information while discarding the unimportant part. Existing augmentation views with perturbed graph structures are usually based on random topology corruption in the spatial domain; however, from perspectives of the spectral domain, this approach may be ineffective as it fails to pose tailored impacts on the information of different frequencies, thus weakening the agreement between the augmentation views. By a preliminary experiment, we show that the impacts caused by spatial random perturbation are approximately evenly distributed among frequency bands, which may harm the invariance of augmentations required by contrastive learning frameworks. To address this issue, we argue that the perturbation should be selectively posed on the information concerning different frequencies. In this paper, we propose GASSER which poses tailored perturbation on the specific frequencies of graph structures in spectral domain, and the edge perturbation is selectively guided by the spectral hints. As shown by extensive experiments and theoretical analysis, the augmentation views are adaptive and controllable, as well as heuristically fitting the homophily ratios and spectrum of graph structures.
Thoroughly Modeling Multi-domain Pre-trained Recommendation as Language
Oct 20, 2023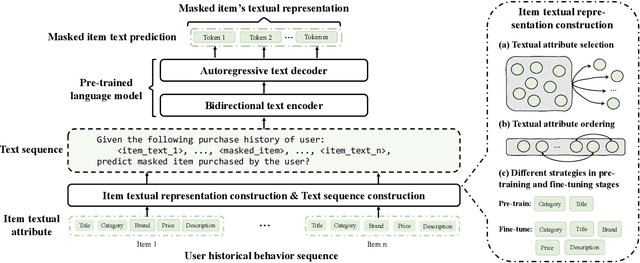

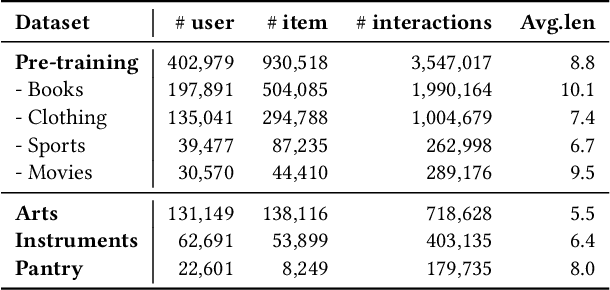
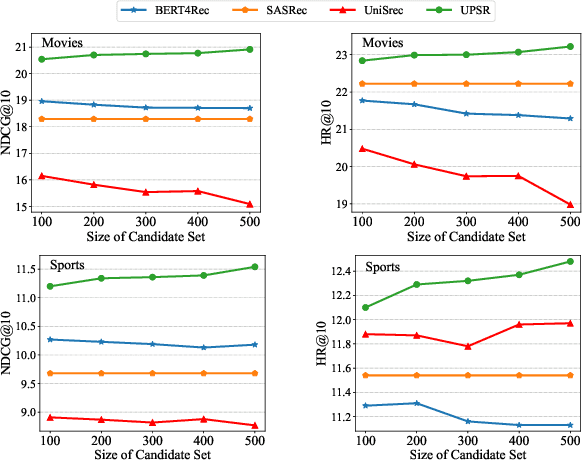
With the thriving of pre-trained language model (PLM) widely verified in various of NLP tasks, pioneer efforts attempt to explore the possible cooperation of the general textual information in PLM with the personalized behavioral information in user historical behavior sequences to enhance sequential recommendation (SR). However, despite the commonalities of input format and task goal, there are huge gaps between the behavioral and textual information, which obstruct thoroughly modeling SR as language modeling via PLM. To bridge the gap, we propose a novel Unified pre-trained language model enhanced sequential recommendation (UPSR), aiming to build a unified pre-trained recommendation model for multi-domain recommendation tasks. We formally design five key indicators, namely naturalness, domain consistency, informativeness, noise & ambiguity, and text length, to guide the text->item adaptation and behavior sequence->text sequence adaptation differently for pre-training and fine-tuning stages, which are essential but under-explored by previous works. In experiments, we conduct extensive evaluations on seven datasets with both tuning and zero-shot settings and achieve the overall best performance. Comprehensive model analyses also provide valuable insights for behavior modeling via PLM, shedding light on large pre-trained recommendation models. The source codes will be released in the future.
Learning Real-World Image De-Weathering with Imperfect Supervision
Oct 23, 2023Real-world image de-weathering aims at removing various undesirable weather-related artifacts. Owing to the impossibility of capturing image pairs concurrently, existing real-world de-weathering datasets often exhibit inconsistent illumination, position, and textures between the ground-truth images and the input degraded images, resulting in imperfect supervision. Such non-ideal supervision negatively affects the training process of learning-based de-weathering methods. In this work, we attempt to address the problem with a unified solution for various inconsistencies. Specifically, inspired by information bottleneck theory, we first develop a Consistent Label Constructor (CLC) to generate a pseudo-label as consistent as possible with the input degraded image while removing most weather-related degradations. In particular, multiple adjacent frames of the current input are also fed into CLC to enhance the pseudo-label. Then we combine the original imperfect labels and pseudo-labels to jointly supervise the de-weathering model by the proposed Information Allocation Strategy (IAS). During testing, only the de-weathering model is used for inference. Experiments on two real-world de-weathering datasets show that our method helps existing de-weathering models achieve better performance. Codes are available at https://github.com/1180300419/imperfect-deweathering.
Novel-View Acoustic Synthesis from 3D Reconstructed Rooms
Oct 23, 2023We investigate the benefit of combining blind audio recordings with 3D scene information for novel-view acoustic synthesis. Given audio recordings from 2-4 microphones and the 3D geometry and material of a scene containing multiple unknown sound sources, we estimate the sound anywhere in the scene. We identify the main challenges of novel-view acoustic synthesis as sound source localization, separation, and dereverberation. While naively training an end-to-end network fails to produce high-quality results, we show that incorporating room impulse responses (RIRs) derived from 3D reconstructed rooms enables the same network to jointly tackle these tasks. Our method outperforms existing methods designed for the individual tasks, demonstrating its effectiveness at utilizing 3D visual information. In a simulated study on the Matterport3D-NVAS dataset, our model achieves near-perfect accuracy on source localization, a PSNR of 26.44 dB and a SDR of 14.23 dB for source separation and dereverberation, resulting in a PSNR of 25.55 dB and a SDR of 14.20 dB on novel-view acoustic synthesis. Code, pretrained model, and video results are available on the project webpage (https://github.com/apple/ml-nvas3d).
Reliable Academic Conference Question Answering: A Study Based on Large Language Model
Oct 19, 2023The rapid growth of computer science has led to a proliferation of research presented at academic conferences, fostering global scholarly communication. Researchers consistently seek accurate, current information about these events at all stages. This data surge necessitates an intelligent question-answering system to efficiently address researchers' queries and ensure awareness of the latest advancements. The information of conferences is usually published on their official website, organized in a semi-structured way with a lot of text. To address this need, we have developed the ConferenceQA dataset for 7 diverse academic conferences with human annotations. Firstly, we employ a combination of manual and automated methods to organize academic conference data in a semi-structured JSON format. Subsequently, we annotate nearly 100 question-answer pairs for each conference. Each pair is classified into four different dimensions. To ensure the reliability of the data, we manually annotate the source of each answer. In light of recent advancements, Large Language Models (LLMs) have demonstrated impressive performance in various NLP tasks. They have demonstrated impressive capabilities in information-seeking question answering after instruction fine-tuning, and as such, we present our conference QA study based on LLM. Due to hallucination and outdated knowledge of LLMs, we adopt retrieval based methods to enhance LLMs' question-answering abilities. We have proposed a structure-aware retrieval method, specifically designed to leverage inherent structural information during the retrieval process. Empirical validation on the ConferenceQA dataset has demonstrated the effectiveness of this method. The dataset and code are readily accessible on https://github.com/zjukg/ConferenceQA.