 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adaptive Policy with Wait-$k$ Model for Simultaneous Translation
Oct 23, 2023
Simultaneous machine translation (SiMT) requires a robust read/write policy in conjunction with a high-quality translation model. Traditional methods rely on either a fixed wait-$k$ policy coupled with a standalone wait-$k$ translation model, or an adaptive policy jointly trained with the translation model. In this study, we propose a more flexible approach by decoupling the adaptive policy model from the translation model. Our motivation stems from the observation that a standalone multi-path wait-$k$ model performs competitively with adaptive policies utilized in state-of-the-art SiMT approaches. Specifically, we introduce DaP, a divergence-based adaptive policy, that makes read/write decisions for any translation model based on the potential divergence in translation distributions resulting from future information. DaP extends a frozen wait-$k$ model with lightweight parameters, and is both memory and computation efficient. Experimental results across various benchmarks demonstrate that our approach offers an improved trade-off between translation accuracy and latency, outperforming strong baselines.
Pre-Trained Language Models Augmented with Synthetic Scanpaths for Natural Language Understanding
Oct 23, 2023Human gaze data offer cognitive information that reflects natural language comprehension. Indeed, augmenting language models with human scanpaths has proven beneficial for a range of NLP tasks, including language understanding. However, the applicability of this approach is hampered because the abundance of text corpora is contrasted by a scarcity of gaze data. Although models for the generation of human-like scanpaths during reading have been developed, the potential of synthetic gaze data across NLP tasks remains largely unexplored. We develop a model that integrates synthetic scanpath generation with a scanpath-augmented language model, eliminating the need for human gaze data. Since the model's error gradient can be propagated throughout all parts of the model, the scanpath generator can be fine-tuned to downstream tasks. We find that the proposed model not only outperforms the underlying language model, but achieves a performance that is comparable to a language model augmented with real human gaze data. Our code is publicly available.
CrisisMatch: Semi-Supervised Few-Shot Learning for Fine-Grained Disaster Tweet Classification
Oct 23, 2023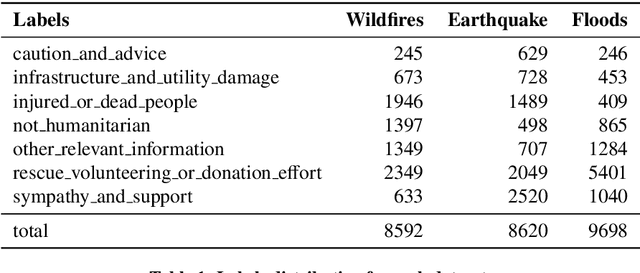
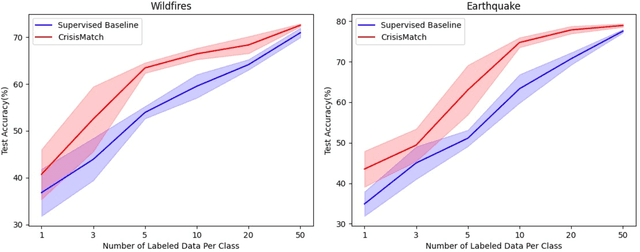
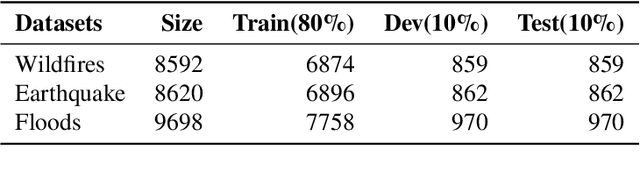
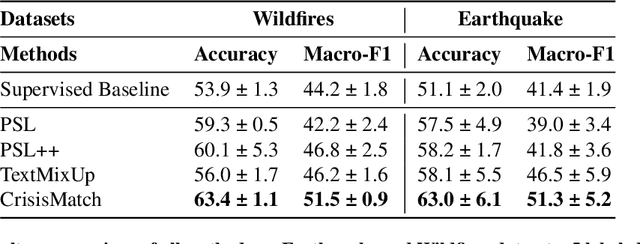
The shared real-time information about natural disasters on social media platforms like Twitter and Facebook plays a critical role in informing volunteers, emergency managers, and response organizations. However, supervised learning models for monitoring disaster events require large amounts of annotated data, making them unrealistic for real-time use in disaster events. To address this challenge, we present a fine-grained disaster tweet classification model under the semi-supervised, few-shot learning setting where only a small number of annotated data is required. Our model, CrisisMatch, effectively classifies tweets into fine-grained classes of interest using few labeled data and large amounts of unlabeled data, mimicking the early stage of a disaster. Through integrating effective semi-supervised learning ideas and incorporating TextMixUp, CrisisMatch achieves performance improvement on two disaster datasets of 11.2\% on average. Further analyses are also provided for the influence of the number of labeled data and out-of-domain results.
BM2CP: Efficient Collaborative Perception with LiDAR-Camera Modalities
Oct 23, 2023Collaborative perception enables agents to share complementary perceptual information with nearby agents. This would improve the perception performance and alleviate the issues of single-view perception, such as occlusion and sparsity. Most existing approaches mainly focus on single modality (especially LiDAR), and not fully exploit the superiority of multi-modal perception. We propose a collaborative perception paradigm, BM2CP, which employs LiDAR and camera to achieve efficient multi-modal perception. It utilizes LiDAR-guided modal fusion, cooperative depth generation and modality-guided intermediate fusion to acquire deep interactions among modalities of different agents, Moreover, it is capable to cope with the special case where one of the sensors, same or different type, of any agent is missing. Extensive experiments validate that our approach outperforms the state-of-the-art methods with 50X lower communication volumes in both simulated and real-world autonomous driving scenarios. Our code is available at https://github.com/byzhaoAI/BM2CP.
A Hybrid GNN approach for predicting node data for 3D meshes
Oct 23, 2023Metal forging is used to manufacture dies. We require the best set of input parameters for the process to be efficient. Currently, we predict the best parameters using the finite element method by generating simulations for the different initial conditions, which is a time-consuming process. In this paper, introduce a hybrid approach that helps in processing and generating new data simulations using a surrogate graph neural network model based on graph convolutions, having a cheaper time cost. We also introduce a hybrid approach that helps in processing and generating new data simulations using the model. Given a dataset representing meshes, our focus is on the conversion of the available information into a graph or point cloud structure. This new representation enables deep learning. The predicted result is similar, with a low error when compared to that produced using the finite element method. The new models have outperformed existing PointNet and simple graph neural network models when applied to produce the simulations.
Why LLMs Hallucinate, and How to Get (Evidential) Closure: Perceptual, Intensional, and Extensional Learning for Faithful Natural Language Generation
Oct 23, 2023We show that LLMs hallucinate because their output is not constrained to be synonymous with claims for which they have evidence: a condition that we call evidential closure. Information about the truth or falsity of sentences is not statistically identified in the standard neural probabilistic language model setup, and so cannot be conditioned on to generate new strings. We then show how to constrain LLMs to produce output that does satisfy evidential closure. A multimodal LLM must learn about the external world (perceptual learning); it must learn a mapping from strings to states of the world (extensional learning); and, to achieve fluency when generalizing beyond a body of evidence, it must learn mappings from strings to their synonyms (intensional learning). The output of a unimodal LLM must be synonymous with strings in a validated evidence set. Finally, we present a heuristic procedure, Learn-Babble-Prune, that yields faithful output from an LLM by rejecting output that is not synonymous with claims for which the LLM has evidence.
PRCA: Fitting Black-Box Large Language Models for Retrieval Question Answering via Pluggable Reward-Driven Contextual Adapter
Oct 23, 2023The Retrieval Question Answering (ReQA) task employs the retrieval-augmented framework, composed of a retriever and generator. The generator formulates the answer based on the documents retrieved by the retriever. Incorporating Large Language Models (LLMs) as generators is beneficial due to their advanced QA capabilities, but they are typically too large to be fine-tuned with budget constraints while some of them are only accessible via APIs. To tackle this issue and further improve ReQA performance, we propose a trainable Pluggable Reward-Driven Contextual Adapter (PRCA), keeping the generator as a black box. Positioned between the retriever and generator in a Pluggable manner, PRCA refines the retrieved information by operating in a token-autoregressive strategy via maximizing rewards of the reinforcement learning phase. Our experiments validate PRCA's effectiveness in enhancing ReQA performance on three datasets by up to 20% improvement to fit black-box LLMs into existing frameworks, demonstrating its considerable potential in the LLMs era.
Learning to Correct Noisy Labels for Fine-Grained Entity Typing via Co-Prediction Prompt Tuning
Oct 23, 2023Fine-grained entity typing (FET) is an essential task in natural language processing that aims to assign semantic types to entities in text. However, FET poses a major challenge known as the noise labeling problem, whereby current methods rely on estimating noise distribution to identify noisy labels but are confused by diverse noise distribution deviation. To address this limitation, we introduce Co-Prediction Prompt Tuning for noise correction in FET, which leverages multiple prediction results to identify and correct noisy labels. Specifically, we integrate prediction results to recall labeled labels and utilize a differentiated margin to identify inaccurate labels. Moreover, we design an optimization objective concerning divergent co-predictions during fine-tuning, ensuring that the model captures sufficient information and maintains robustness in noise identification. Experimental results on three widely-used FET datasets demonstrate that our noise correction approach significantly enhances the quality of various types of training samples, including those annotated using distant supervision, ChatGPT, and crowdsourcing.
Efficient Active Learning Halfspaces with Tsybakov Noise: A Non-convex Optimization Approach
Oct 23, 2023We study the problem of computationally and label efficient PAC active learning $d$-dimensional halfspaces with Tsybakov Noise~\citep{tsybakov2004optimal} under structured unlabeled data distributions. Inspired by~\cite{diakonikolas2020learning}, we prove that any approximate first-order stationary point of a smooth nonconvex loss function yields a halfspace with a low excess error guarantee. In light of the above structural result, we design a nonconvex optimization-based algorithm with a label complexity of $\tilde{O}(d (\frac{1}{\epsilon})^{\frac{8-6\alpha}{3\alpha-1}})$\footnote{In the main body of this work, we use $\tilde{O}(\cdot), \tilde{\Theta}(\cdot)$ to hide factors of the form $\polylog(d, \frac{1}{\epsilon}, \frac{1}{\delta})$}, under the assumption that the Tsybakov noise parameter $\alpha \in (\frac13, 1]$, which narrows down the gap between the label complexities of the previously known efficient passive or active algorithms~\citep{diakonikolas2020polynomial,zhang2021improved} and the information-theoretic lower bound in this setting.
EpiK-Eval: Evaluation for Language Models as Epistemic Models
Oct 23, 2023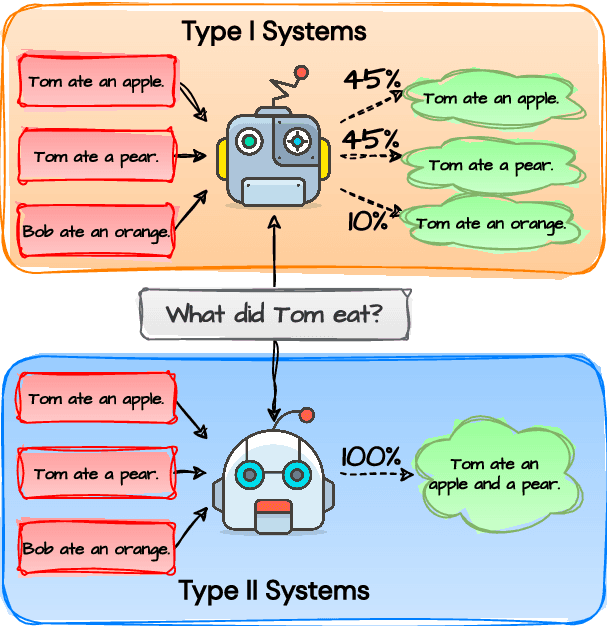

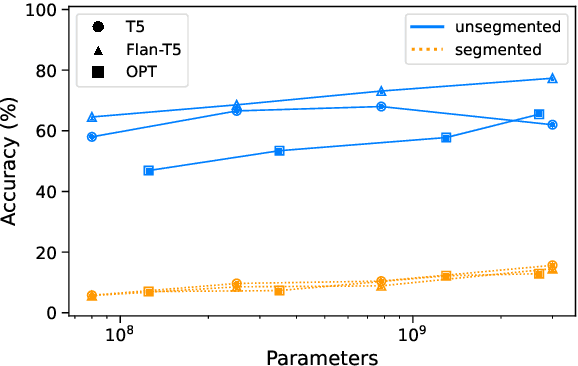
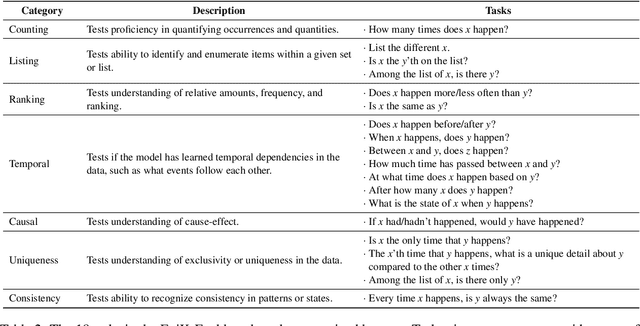
In the age of artificial intelligence, the role of large language models (LLMs) is becoming increasingly central. Despite their growing prevalence, their capacity to consolidate knowledge from different training documents - a crucial ability in numerous applications - remains unexplored. This paper presents the first study examining the capability of LLMs to effectively combine such information within their parameter space. We introduce EpiK-Eval, a novel question-answering benchmark tailored to evaluate LLMs' proficiency in formulating a coherent and consistent knowledge representation from segmented narratives. Evaluations across various LLMs reveal significant weaknesses in this domain. We contend that these shortcomings stem from the intrinsic nature of prevailing training objectives. Consequently, we advocate for refining the approach towards knowledge consolidation, as it harbors the potential to dramatically improve their overall effectiveness and performance. The findings from this study offer insights for developing more robust and reliable LLMs. Our code and benchmark are available at https://github.com/chandar-lab/EpiK-Eval