 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
M3TCM: Multi-modal Multi-task Context Model for Utterance Classification in Motivational Interviews
Apr 04, 2024
Accurate utterance classification in motivational interviews is crucial to automatically understand the quality and dynamics of client-therapist interaction, and it can serve as a key input for systems mediating such interactions. Motivational interviews exhibit three important characteristics. First, there are two distinct roles, namely client and therapist. Second, they are often highly emotionally charged, which can be expressed both in text and in prosody. Finally, context is of central importance to classify any given utterance. Previous works did not adequately incorporate all of these characteristics into utterance classification approaches for mental health dialogues. In contrast, we present M3TCM, a Multi-modal, Multi-task Context Model for utterance classification. Our approach for the first time employs multi-task learning to effectively model both joint and individual components of therapist and client behaviour. Furthermore, M3TCM integrates information from the text and speech modality as well as the conversation context. With our novel approach, we outperform the state of the art for utterance classification on the recently introduced AnnoMI dataset with a relative improvement of 20% for the client- and by 15% for therapist utterance classification. In extensive ablation studies, we quantify the improvement resulting from each contribution.
DELTA: Decomposed Efficient Long-Term Robot Task Planning using Large Language Models
Apr 04, 2024Recent advancements in Large Language Models (LLMs) have sparked a revolution across various research fields. In particular, the integration of common-sense knowledge from LLMs into robot task and motion planning has been proven to be a game-changer, elevating performance in terms of explainability and downstream task efficiency to unprecedented heights. However, managing the vast knowledge encapsulated within these large models has posed challenges, often resulting in infeasible plans generated by LLM-based planning systems due to hallucinations or missing domain information. To overcome these challenges and obtain even greater planning feasibility and computational efficiency, we propose a novel LLM-driven task planning approach called DELTA. For achieving better grounding from environmental topology into actionable knowledge, DELTA leverages the power of scene graphs as environment representations within LLMs, enabling the fast generation of precise planning problem descriptions. For obtaining higher planning performance, we use LLMs to decompose the long-term task goals into an autoregressive sequence of sub-goals for an automated task planner to solve. Our contribution enables a more efficient and fully automatic task planning pipeline, achieving higher planning success rates and significantly shorter planning times compared to the state of the art.
Know Your Neighbors: Improving Single-View Reconstruction via Spatial Vision-Language Reasoning
Apr 04, 2024Recovering the 3D scene geometry from a single view is a fundamental yet ill-posed problem in computer vision. While classical depth estimation methods infer only a 2.5D scene representation limited to the image plane, recent approaches based on radiance fields reconstruct a full 3D representation. However, these methods still struggle with occluded regions since inferring geometry without visual observation requires (i) semantic knowledge of the surroundings, and (ii) reasoning about spatial context. We propose KYN, a novel method for single-view scene reconstruction that reasons about semantic and spatial context to predict each point's density. We introduce a vision-language modulation module to enrich point features with fine-grained semantic information. We aggregate point representations across the scene through a language-guided spatial attention mechanism to yield per-point density predictions aware of the 3D semantic context. We show that KYN improves 3D shape recovery compared to predicting density for each 3D point in isolation. We achieve state-of-the-art results in scene and object reconstruction on KITTI-360, and show improved zero-shot generalization compared to prior work. Project page: https://ruili3.github.io/kyn.
Decoupling Static and Hierarchical Motion Perception for Referring Video Segmentation
Apr 04, 2024Referring video segmentation relies on natural language expressions to identify and segment objects, often emphasizing motion clues. Previous works treat a sentence as a whole and directly perform identification at the video-level, mixing up static image-level cues with temporal motion cues. However, image-level features cannot well comprehend motion cues in sentences, and static cues are not crucial for temporal perception. In fact, static cues can sometimes interfere with temporal perception by overshadowing motion cues. In this work, we propose to decouple video-level referring expression understanding into static and motion perception, with a specific emphasis on enhancing temporal comprehension. Firstly, we introduce an expression-decoupling module to make static cues and motion cues perform their distinct role, alleviating the issue of sentence embeddings overlooking motion cues. Secondly, we propose a hierarchical motion perception module to capture temporal information effectively across varying timescales. Furthermore, we employ contrastive learning to distinguish the motions of visually similar objects. These contributions yield state-of-the-art performance across five datasets, including a remarkable $\textbf{9.2%}$ $\mathcal{J\&F}$ improvement on the challenging $\textbf{MeViS}$ dataset. Code is available at https://github.com/heshuting555/DsHmp.
DiffBody: Human Body Restoration by Imagining with Generative Diffusion Prior
Apr 04, 2024Human body restoration plays a vital role in various applications related to the human body. Despite recent advances in general image restoration using generative models, their performance in human body restoration remains mediocre, often resulting in foreground and background blending, over-smoothing surface textures, missing accessories, and distorted limbs. Addressing these challenges, we propose a novel approach by constructing a human body-aware diffusion model that leverages domain-specific knowledge to enhance performance. Specifically, we employ a pretrained body attention module to guide the diffusion model's focus on the foreground, addressing issues caused by blending between the subject and background. We also demonstrate the value of revisiting the language modality of the diffusion model in restoration tasks by seamlessly incorporating text prompt to improve the quality of surface texture and additional clothing and accessories details. Additionally, we introduce a diffusion sampler tailored for fine-grained human body parts, utilizing local semantic information to rectify limb distortions. Lastly, we collect a comprehensive dataset for benchmarking and advancing the field of human body restoration. Extensive experimental validation showcases the superiority of our approach, both quantitatively and qualitatively, over existing methods.
Design and Optimization of Cooperative Sensing With Limited Backhaul Capacity
Apr 04, 2024This paper introduces a cooperative sensing framework designed for integrated sensing and communication cellular networks. The framework comprises one base station (BS) functioning as the sensing transmitter, while several nearby BSs act as sensing receivers. The primary objective is to facilitate cooperative target localization by enabling each receiver to share specific information with a fusion center (FC) over a limited capacity backhaul link. To achieve this goal, we propose an advanced cooperative sensing design that enhances the communication process between the receivers and the FC. Each receiver independently estimates the time delay and the reflecting coefficient associated with the reflected path from the target. Subsequently, each receiver transmits the estimated values and the received signal samples centered around the estimated time delay to the FC. To efficiently quantize the signal samples, a Karhunen-Lo\`eve Transform coding scheme is employed. Furthermore, an optimization problem is formulated to allocate backhaul resources for quantizing different samples, improving target localization. Numerical results validate the effectiveness of our proposed advanced design and demonstrate its superiority over a baseline design, where only the locally estimated values are transmitted from each receiver to the FC.
Estimating Physical Information Consistency of Channel Data Augmentation for Remote Sensing Images
Mar 21, 2024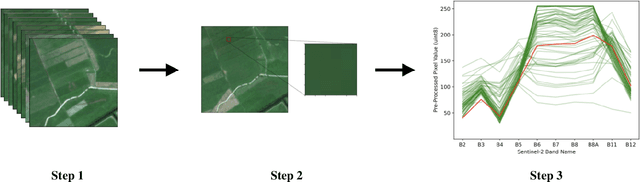
The application of data augmentation for deep learning (DL) methods plays an important role in achieving state-of-the-art results in supervised, semi-supervised, and self-supervised image classification. In particular, channel transformations (e.g., solarize, grayscale, brightness adjustments) are integrated into data augmentation pipelines for remote sensing (RS) image classification tasks. However, contradicting beliefs exist about their proper applications to RS images. A common point of critique is that the application of channel augmentation techniques may lead to physically inconsistent spectral data (i.e., pixel signatures). To shed light on the open debate, we propose an approach to estimate whether a channel augmentation technique affects the physical information of RS images. To this end, the proposed approach estimates a score that measures the alignment of a pixel signature within a time series that can be naturally subject to deviations caused by factors such as acquisition conditions or phenological states of vegetation. We compare the scores associated with original and augmented pixel signatures to evaluate the physical consistency. Experimental results on a multi-label image classification task show that channel augmentations yielding a score that exceeds the expected deviation of original pixel signatures can not improve the performance of a baseline model trained without augmentation.
Continuous Spiking Graph Neural Networks
Apr 02, 2024Continuous graph neural networks (CGNNs) have garnered significant attention due to their ability to generalize existing discrete graph neural networks (GNNs) by introducing continuous dynamics. They typically draw inspiration from diffusion-based methods to introduce a novel propagation scheme, which is analyzed using ordinary differential equations (ODE). However, the implementation of CGNNs requires significant computational power, making them challenging to deploy on battery-powered devices. Inspired by recent spiking neural networks (SNNs), which emulate a biological inference process and provide an energy-efficient neural architecture, we incorporate the SNNs with CGNNs in a unified framework, named Continuous Spiking Graph Neural Networks (COS-GNN). We employ SNNs for graph node representation at each time step, which are further integrated into the ODE process along with time. To enhance information preservation and mitigate information loss in SNNs, we introduce the high-order structure of COS-GNN, which utilizes the second-order ODE for spiking representation and continuous propagation. Moreover, we provide the theoretical proof that COS-GNN effectively mitigates the issues of exploding and vanishing gradients, enabling us to capture long-range dependencies between nodes. Experimental results on graph-based learning tasks demonstrate the effectiveness of the proposed COS-GNN over competitive baselines.
Label-Agnostic Forgetting: A Supervision-Free Unlearning in Deep Models
Mar 31, 2024Machine unlearning aims to remove information derived from forgotten data while preserving that of the remaining dataset in a well-trained model. With the increasing emphasis on data privacy, several approaches to machine unlearning have emerged. However, these methods typically rely on complete supervision throughout the unlearning process. Unfortunately, obtaining such supervision, whether for the forgetting or remaining data, can be impractical due to the substantial cost associated with annotating real-world datasets. This challenge prompts us to propose a supervision-free unlearning approach that operates without the need for labels during the unlearning process. Specifically, we introduce a variational approach to approximate the distribution of representations for the remaining data. Leveraging this approximation, we adapt the original model to eliminate information from the forgotten data at the representation level. To further address the issue of lacking supervision information, which hinders alignment with ground truth, we introduce a contrastive loss to facilitate the matching of representations between the remaining data and those of the original model, thus preserving predictive performance. Experimental results across various unlearning tasks demonstrate the effectiveness of our proposed method, Label-Agnostic Forgetting (LAF) without using any labels, which achieves comparable performance to state-of-the-art methods that rely on full supervision information. Furthermore, our approach excels in semi-supervised scenarios, leveraging limited supervision information to outperform fully supervised baselines. This work not only showcases the viability of supervision-free unlearning in deep models but also opens up a new possibility for future research in unlearning at the representation level.
GENEVIC: GENetic data Exploration and Visualization via Intelligent interactive Console
Apr 04, 2024Summary: The vast generation of genetic data poses a significant challenge in efficiently uncovering valuable knowledge. Introducing GENEVIC, an AI-driven chat framework that tackles this challenge by bridging the gap between genetic data generation and biomedical knowledge discovery. Leveraging generative AI, notably ChatGPT, it serves as a biologist's 'copilot'. It automates the analysis, retrieval, and visualization of customized domain-specific genetic information, and integrates functionalities to generate protein interaction networks, enrich gene sets, and search scientific literature from PubMed, Google Scholar, and arXiv, making it a comprehensive tool for biomedical research. In its pilot phase, GENEVIC is assessed using a curated database that ranks genetic variants associated with Alzheimer's disease, schizophrenia, and cognition, based on their effect weights from the Polygenic Score Catalog, thus enabling researchers to prioritize genetic variants in complex diseases. GENEVIC's operation is user-friendly, accessible without any specialized training, secured by Azure OpenAI's HIPAA-compliant infrastructure, and evaluated for its efficacy through real-time query testing. As a prototype, GENEVIC is set to advance genetic research, enabling informed biomedical decisions. Availability and implementation: GENEVIC is publicly accessible at https://genevic-anath2024.streamlit.app. The underlying code is open-source and available via GitHub at https://github.com/anath2110/GENEVIC.git.