 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
BianQue: Balancing the Questioning and Suggestion Ability of Health LLMs with Multi-turn Health Conversations Polished by ChatGPT
Oct 24, 2023
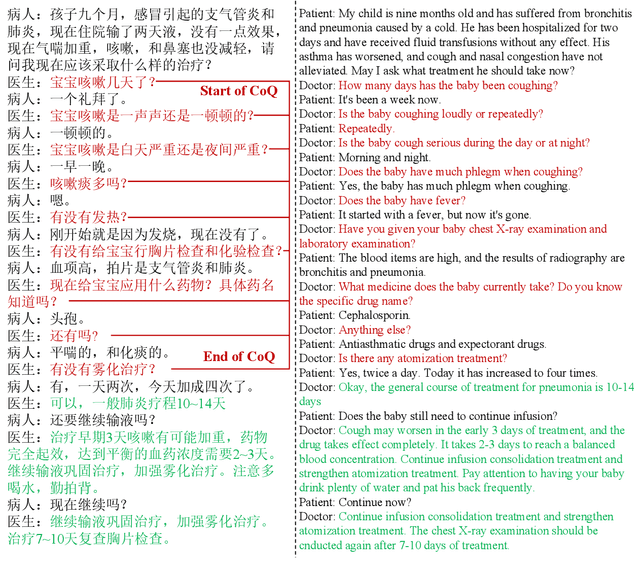
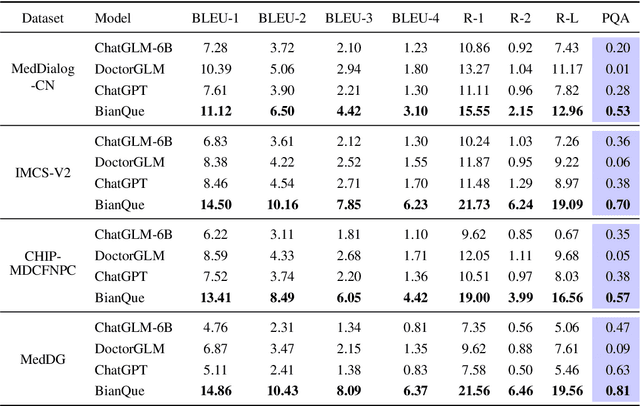
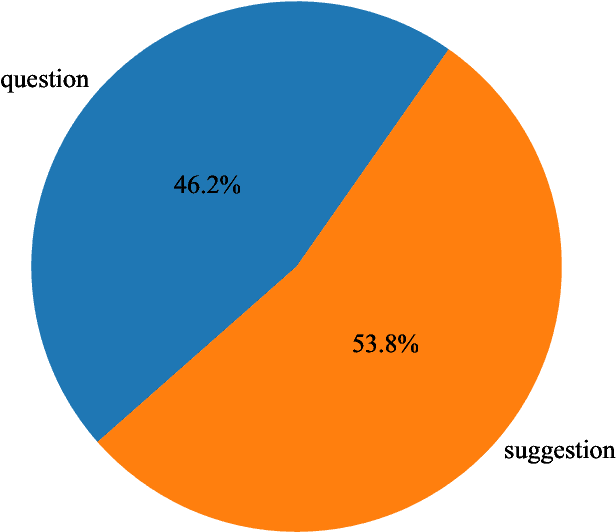
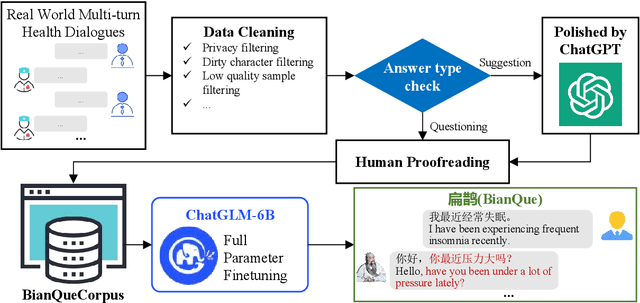
Large language models (LLMs) have performed well in providing general and extensive health suggestions in single-turn conversations, exemplified by systems such as ChatGPT, ChatGLM, ChatDoctor, DoctorGLM, and etc. However, the limited information provided by users during single turn results in inadequate personalization and targeting of the generated suggestions, which requires users to independently select the useful part. It is mainly caused by the missing ability to engage in multi-turn questioning. In real-world medical consultations, doctors usually employ a series of iterative inquiries to comprehend the patient's condition thoroughly, enabling them to provide effective and personalized suggestions subsequently, which can be defined as chain of questioning (CoQ) for LLMs. To improve the CoQ of LLMs, we propose BianQue, a ChatGLM-based LLM finetuned with the self-constructed health conversation dataset BianQueCorpus that is consist of multiple turns of questioning and health suggestions polished by ChatGPT. Experimental results demonstrate that the proposed BianQue can simultaneously balance the capabilities of both questioning and health suggestions, which will help promote the research and application of LLMs in the field of proactive health.
Retrieval-based Knowledge Transfer: An Effective Approach for Extreme Large Language Model Compression
Oct 24, 2023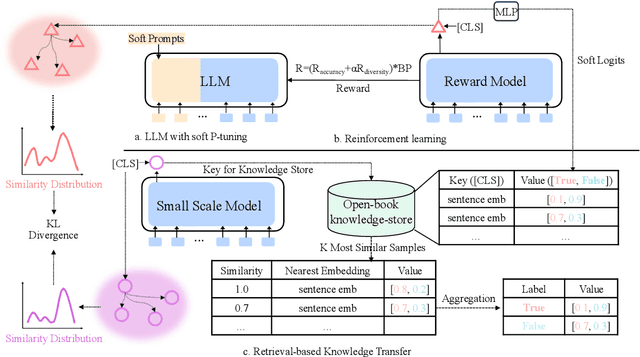
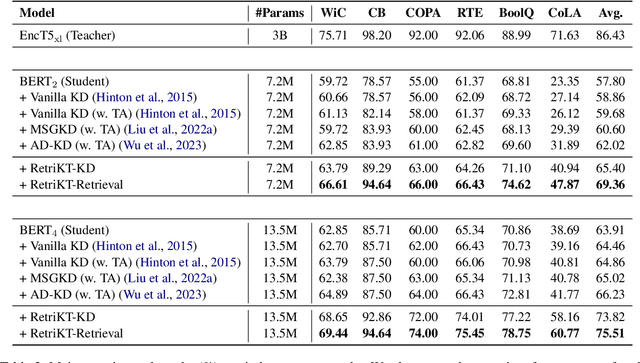
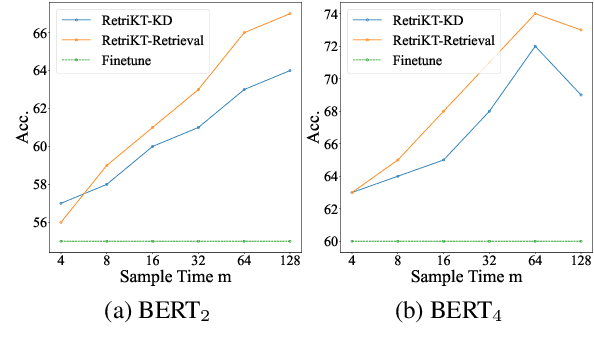
Large-scale pre-trained language models (LLMs) have demonstrated exceptional performance in various natural language processing (NLP) tasks. However, the massive size of these models poses huge challenges for their deployment in real-world applications. While numerous model compression techniques have been proposed, most of them are not well-suited for achieving extreme model compression when there is a significant gap in model scale. In this paper, we introduce a novel compression paradigm called Retrieval-based Knowledge Transfer (RetriKT), which effectively transfers the knowledge of LLMs to extremely small-scale models (e.g., 1%). In particular, our approach extracts knowledge from LLMs to construct a knowledge store, from which the small-scale model can retrieve relevant information and leverage it for effective inference. To improve the quality of the model, soft prompt tuning and Proximal Policy Optimization (PPO) reinforcement learning techniques are employed. Extensive experiments are conducted on low-resource tasks from SuperGLUE and GLUE benchmarks. The results demonstrate that the proposed approach significantly enhances the performance of small-scale models by leveraging the knowledge from LLMs.
CR-COPEC: Causal Rationale of Corporate Performance Changes to Learn from Financial Reports
Oct 24, 2023In this paper, we introduce CR-COPEC called Causal Rationale of Corporate Performance Changes from financial reports. This is a comprehensive large-scale domain-adaptation causal sentence dataset to detect financial performance changes of corporate. CR-COPEC contributes to two major achievements. First, it detects causal rationale from 10-K annual reports of the U.S. companies, which contain experts' causal analysis following accounting standards in a formal manner. This dataset can be widely used by both individual investors and analysts as material information resources for investing and decision making without tremendous effort to read through all the documents. Second, it carefully considers different characteristics which affect the financial performance of companies in twelve industries. As a result, CR-COPEC can distinguish causal sentences in various industries by taking unique narratives in each industry into consideration. We also provide an extensive analysis of how well CR-COPEC dataset is constructed and suited for classifying target sentences as causal ones with respect to industry characteristics. Our dataset and experimental codes are publicly available.
Decentralized Learning over Wireless Networks with Broadcast-Based Subgraph Sampling
Oct 24, 2023This work centers on the communication aspects of decentralized learning over wireless networks, using consensus-based decentralized stochastic gradient descent (D-SGD). Considering the actual communication cost or delay caused by in-network information exchange in an iterative process, our goal is to achieve fast convergence of the algorithm measured by improvement per transmission slot. We propose BASS, an efficient communication framework for D-SGD over wireless networks with broadcast transmission and probabilistic subgraph sampling. In each iteration, we activate multiple subsets of non-interfering nodes to broadcast model updates to their neighbors. These subsets are randomly activated over time, with probabilities reflecting their importance in network connectivity and subject to a communication cost constraint (e.g., the average number of transmission slots per iteration). During the consensus update step, only bi-directional links are effectively preserved to maintain communication symmetry. In comparison to existing link-based scheduling methods, the inherent broadcasting nature of wireless channels offers intrinsic advantages in speeding up convergence of decentralized learning by creating more communicated links with the same number of transmission slots.
CP-BCS: Binary Code Summarization Guided by Control Flow Graph and Pseudo Code
Oct 24, 2023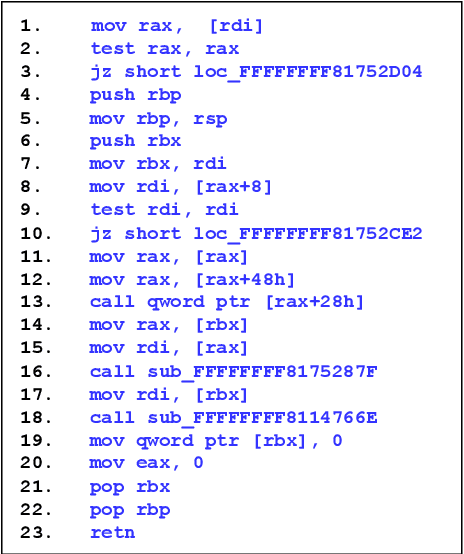
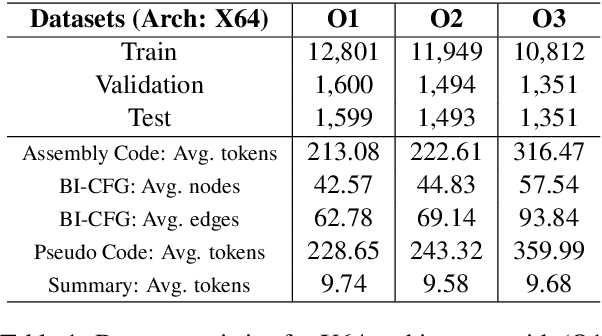
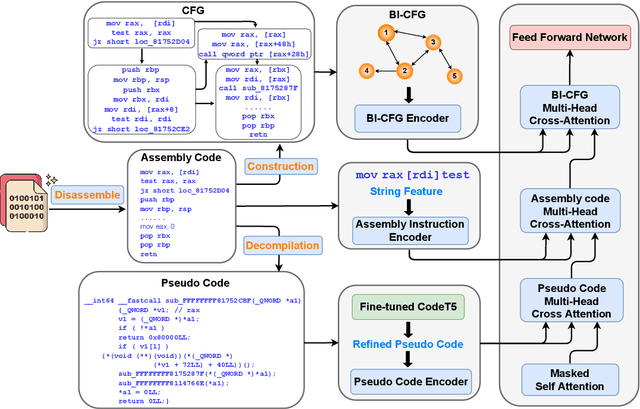
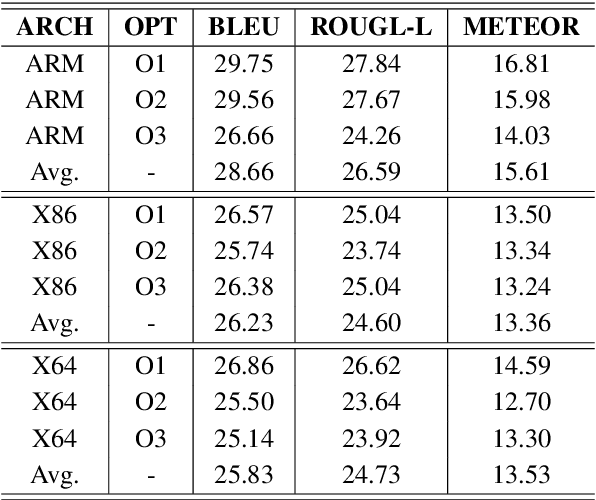
Automatically generating function summaries for binaries is an extremely valuable but challenging task, since it involves translating the execution behavior and semantics of the low-level language (assembly code) into human-readable natural language. However, most current works on understanding assembly code are oriented towards generating function names, which involve numerous abbreviations that make them still confusing. To bridge this gap, we focus on generating complete summaries for binary functions, especially for stripped binary (no symbol table and debug information in reality). To fully exploit the semantics of assembly code, we present a control flow graph and pseudo code guided binary code summarization framework called CP-BCS. CP-BCS utilizes a bidirectional instruction-level control flow graph and pseudo code that incorporates expert knowledge to learn the comprehensive binary function execution behavior and logic semantics. We evaluate CP-BCS on 3 different binary optimization levels (O1, O2, and O3) for 3 different computer architectures (X86, X64, and ARM). The evaluation results demonstrate CP-BCS is superior and significantly improves the efficiency of reverse engineering.
ChatGPT for GTFS: From Words to Information
Aug 04, 2023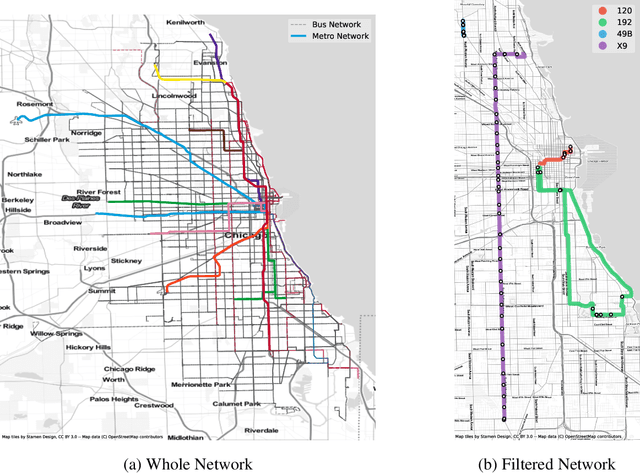
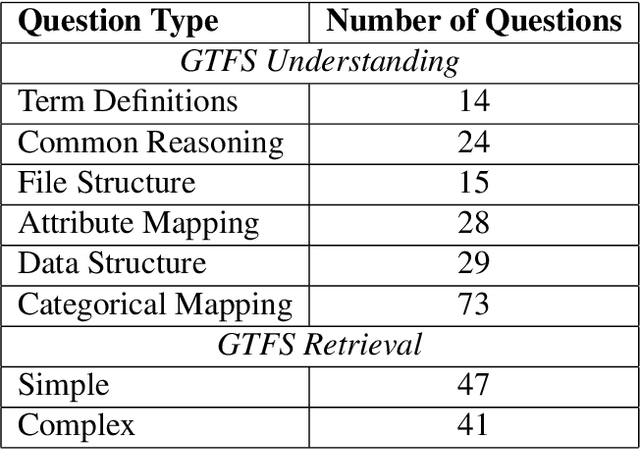


The General Transit Feed Specification (GTFS) standard for publishing transit data is ubiquitous. GTFS being tabular data, with information spread across different files, necessitates specialized tools or packages to retrieve information. Concurrently, the use of Large Language Models for text and information retrieval is growing. The idea of this research is to see if the current widely adopted LLMs (ChatGPT) are able to retrieve information from GTFS using natural language instructions. We first test whether ChatGPT (GPT-3.5) understands the GTFS specification. GPT-3.5 answers 77% of our multiple-choice questions (MCQ) correctly. Next, we task the LLM with information extractions from a filtered GTFS feed with 4 routes. For information retrieval, we compare zero-shot and program synthesis. Program synthesis works better, achieving ~90% accuracy on simple questions and ~40% accuracy on complex questions.
BanglaAbuseMeme: A Dataset for Bengali Abusive Meme Classification
Oct 18, 2023
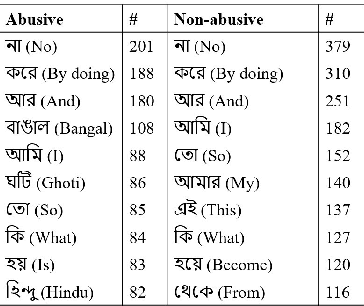
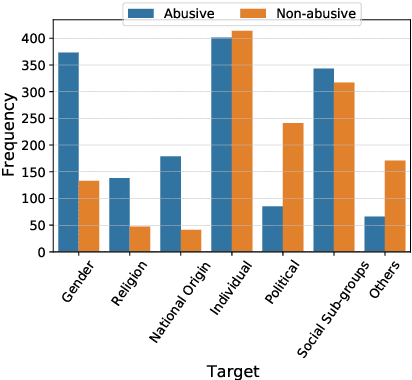
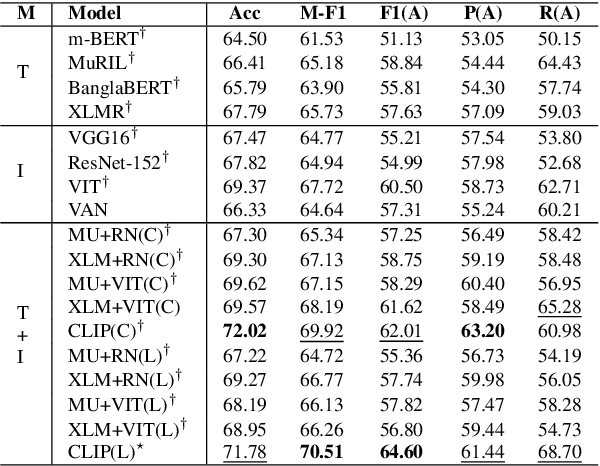
The dramatic increase in the use of social media platforms for information sharing has also fueled a steep growth in online abuse. A simple yet effective way of abusing individuals or communities is by creating memes, which often integrate an image with a short piece of text layered on top of it. Such harmful elements are in rampant use and are a threat to online safety. Hence it is necessary to develop efficient models to detect and flag abusive memes. The problem becomes more challenging in a low-resource setting (e.g., Bengali memes, i.e., images with Bengali text embedded on it) because of the absence of benchmark datasets on which AI models could be trained. In this paper we bridge this gap by building a Bengali meme dataset. To setup an effective benchmark we implement several baseline models for classifying abusive memes using this dataset. We observe that multimodal models that use both textual and visual information outperform unimodal models. Our best-performing model achieves a macro F1 score of 70.51. Finally, we perform a qualitative error analysis of the misclassified memes of the best-performing text-based, image-based and multimodal models.
Reproducibility in Multiple Instance Learning: A Case For Algorithmic Unit Tests
Oct 27, 2023
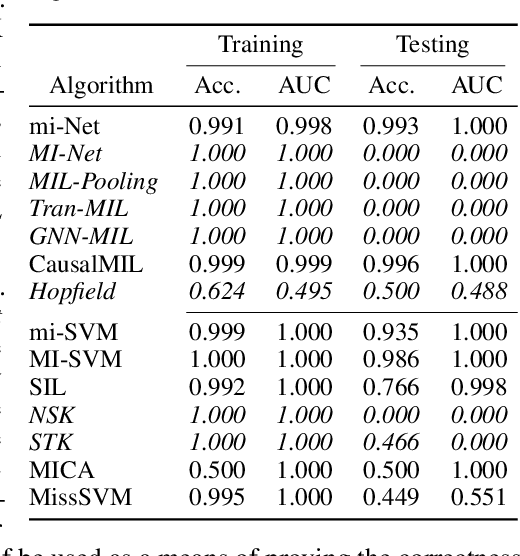
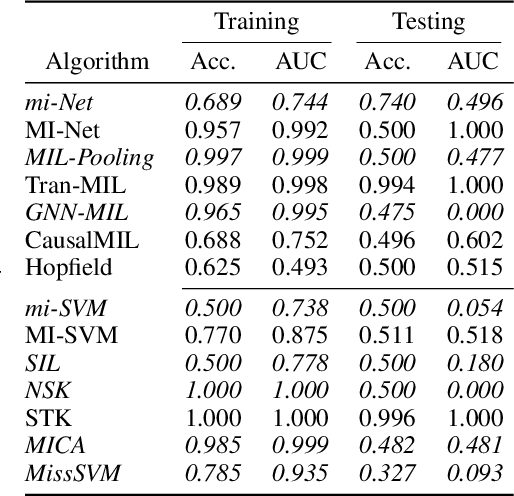
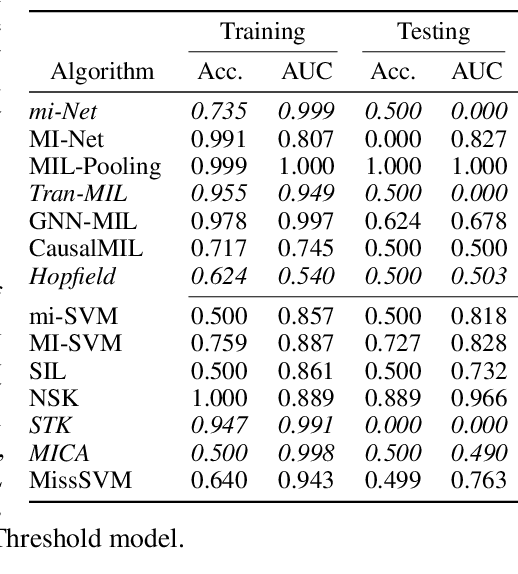
Multiple Instance Learning (MIL) is a sub-domain of classification problems with positive and negative labels and a "bag" of inputs, where the label is positive if and only if a positive element is contained within the bag, and otherwise is negative. Training in this context requires associating the bag-wide label to instance-level information, and implicitly contains a causal assumption and asymmetry to the task (i.e., you can't swap the labels without changing the semantics). MIL problems occur in healthcare (one malignant cell indicates cancer), cyber security (one malicious executable makes an infected computer), and many other tasks. In this work, we examine five of the most prominent deep-MIL models and find that none of them respects the standard MIL assumption. They are able to learn anti-correlated instances, i.e., defaulting to "positive" labels until seeing a negative counter-example, which should not be possible for a correct MIL model. We suspect that enhancements and other works derived from these models will share the same issue. In any context in which these models are being used, this creates the potential for learning incorrect models, which creates risk of operational failure. We identify and demonstrate this problem via a proposed "algorithmic unit test", where we create synthetic datasets that can be solved by a MIL respecting model, and which clearly reveal learning that violates MIL assumptions. The five evaluated methods each fail one or more of these tests. This provides a model-agnostic way to identify violations of modeling assumptions, which we hope will be useful for future development and evaluation of MIL models.
Wi-BFI: Extracting the IEEE 802.11 Beamforming Feedback Information from Commercial Wi-Fi Devices
Sep 12, 2023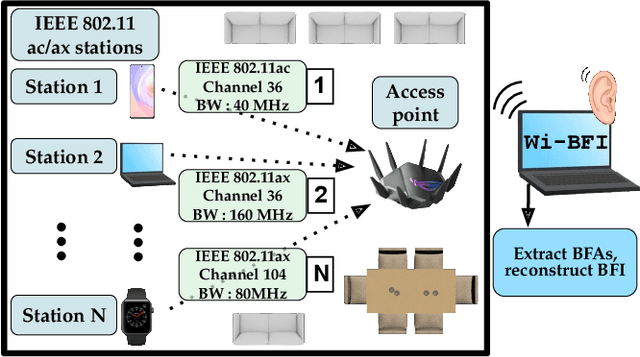
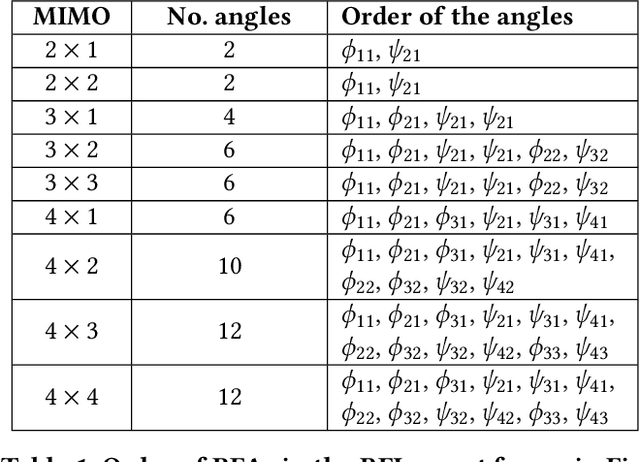
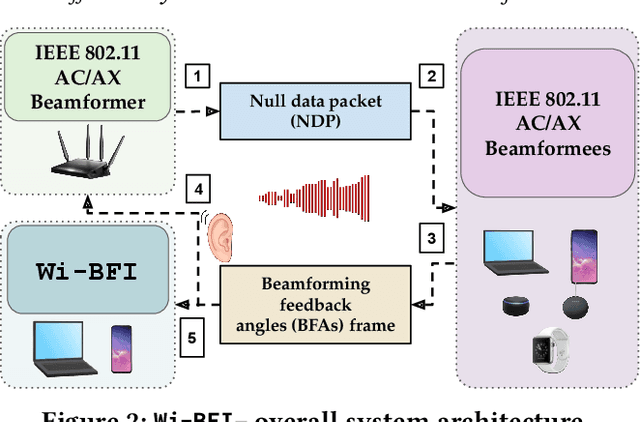
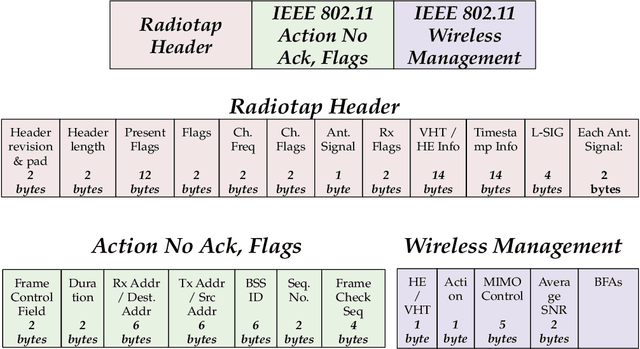
Recently, researchers have shown that the beamforming feedback angles (BFAs) used for Wi-Fi multiple-input multiple-output (MIMO) operations can be effectively leveraged as a proxy of the channel frequency response (CFR) for different purposes. Examples are passive human activity recognition and device fingerprinting. However, even though the BFAs report frames are sent in clear text, there is not yet a unified open-source tool to extract and decode the BFAs from the frames. To fill this gap, we developed Wi-BFI, the first tool that allows retrieving Wi-Fi BFAs and reconstructing the beamforming feedback information (BFI) - a compressed representation of the CFR - from the BFAs frames captured over the air. The tool supports BFAs extraction within both IEEE 802.11ac and 802.11ax networks operating on radio channels with 160/80/40/20 MHz bandwidth. Both multi-user and single-user MIMO feedback can be decoded through Wi-BFI. The tool supports real-time and offline extraction and storage of BFAs and BFI. The real-time mode also includes a visual representation of the channel state that continuously updates based on the collected data. Wi-BFI code is open source and the tool is also available as a pip package.
Optimal Spatial-Temporal Triangulation for Bearing-Only Cooperative Motion Estimation
Oct 25, 2023Vision-based cooperative motion estimation is an important problem for many multi-robot systems such as cooperative aerial target pursuit. This problem can be formulated as bearing-only cooperative motion estimation, where the visual measurement is modeled as a bearing vector pointing from the camera to the target. The conventional approaches for bearing-only cooperative estimation are mainly based on the framework distributed Kalman filtering (DKF). In this paper, we propose a new optimal bearing-only cooperative estimation algorithm, named spatial-temporal triangulation, based on the method of distributed recursive least squares, which provides a more flexible framework for designing distributed estimators than DKF. The design of the algorithm fully incorporates all the available information and the specific triangulation geometric constraint. As a result, the algorithm has superior estimation performance than the state-of-the-art DKF algorithms in terms of both accuracy and convergence speed as verified by numerical simulation. We rigorously prove the exponential convergence of the proposed algorithm. Moreover, to verify the effectiveness of the proposed algorithm under practical challenging conditions, we develop a vision-based cooperative aerial target pursuit system, which is the first of such fully autonomous systems so far to the best of our knowledge.