 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The Open DAC 2023 Dataset and Challenges for Sorbent Discovery in Direct Air Capture
Nov 01, 2023
New methods for carbon dioxide removal are urgently needed to combat global climate change. Direct air capture (DAC) is an emerging technology to capture carbon dioxide directly from ambient air. Metal-organic frameworks (MOFs) have been widely studied as potentially customizable adsorbents for DAC. However, discovering promising MOF sorbents for DAC is challenging because of the vast chemical space to explore and the need to understand materials as functions of humidity and temperature. We explore a computational approach benefiting from recent innovations in machine learning (ML) and present a dataset named Open DAC 2023 (ODAC23) consisting of more than 38M density functional theory (DFT) calculations on more than 8,800 MOF materials containing adsorbed CO2 and/or H2O. ODAC23 is by far the largest dataset of MOF adsorption calculations at the DFT level of accuracy currently available. In addition to probing properties of adsorbed molecules, the dataset is a rich source of information on structural relaxation of MOFs, which will be useful in many contexts beyond specific applications for DAC. A large number of MOFs with promising properties for DAC are identified directly in ODAC23. We also trained state-of-the-art ML models on this dataset to approximate calculations at the DFT level. This open-source dataset and our initial ML models will provide an important baseline for future efforts to identify MOFs for a wide range of applications, including DAC.
Learning to Design and Use Tools for Robotic Manipulation
Nov 01, 2023When limited by their own morphologies, humans and some species of animals have the remarkable ability to use objects from the environment toward accomplishing otherwise impossible tasks. Robots might similarly unlock a range of additional capabilities through tool use. Recent techniques for jointly optimizing morphology and control via deep learning are effective at designing locomotion agents. But while outputting a single morphology makes sense for locomotion, manipulation involves a variety of strategies depending on the task goals at hand. A manipulation agent must be capable of rapidly prototyping specialized tools for different goals. Therefore, we propose learning a designer policy, rather than a single design. A designer policy is conditioned on task information and outputs a tool design that helps solve the task. A design-conditioned controller policy can then perform manipulation using these tools. In this work, we take a step towards this goal by introducing a reinforcement learning framework for jointly learning these policies. Through simulated manipulation tasks, we show that this framework is more sample efficient than prior methods in multi-goal or multi-variant settings, can perform zero-shot interpolation or fine-tuning to tackle previously unseen goals, and allows tradeoffs between the complexity of design and control policies under practical constraints. Finally, we deploy our learned policies onto a real robot. Please see our supplementary video and website at https://robotic-tool-design.github.io/ for visualizations.
Fundamental Limits of Membership Inference Attacks on Machine Learning Models
Oct 27, 2023Membership inference attacks (MIA) can reveal whether a particular data point was part of the training dataset, potentially exposing sensitive information about individuals. This article explores the fundamental statistical limitations associated with MIAs on machine learning models. More precisely, we first derive the statistical quantity that governs the effectiveness and success of such attacks. Then, we investigate several situations for which we provide bounds on this quantity of interest. This allows us to infer the accuracy of potential attacks as a function of the number of samples and other structural parameters of learning models, which in some cases can be directly estimated from the dataset.
M2DF: Multi-grained Multi-curriculum Denoising Framework for Multimodal Aspect-based Sentiment Analysis
Oct 23, 2023
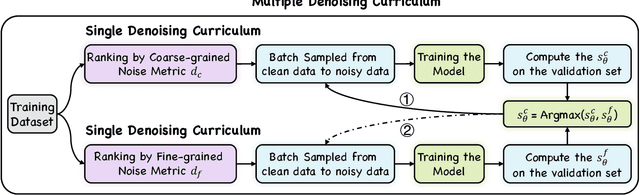
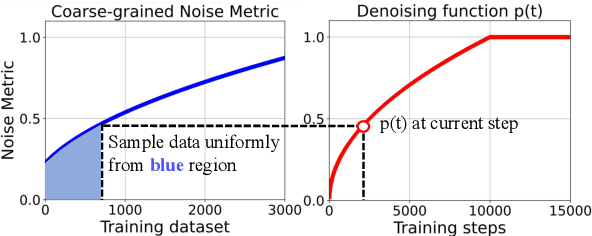

Multimodal Aspect-based Sentiment Analysis (MABSA) is a fine-grained Sentiment Analysis task, which has attracted growing research interests recently. Existing work mainly utilizes image information to improve the performance of MABSA task. However, most of the studies overestimate the importance of images since there are many noise images unrelated to the text in the dataset, which will have a negative impact on model learning. Although some work attempts to filter low-quality noise images by setting thresholds, relying on thresholds will inevitably filter out a lot of useful image information. Therefore, in this work, we focus on whether the negative impact of noisy images can be reduced without modifying the data. To achieve this goal, we borrow the idea of Curriculum Learning and propose a Multi-grained Multi-curriculum Denoising Framework (M2DF), which can achieve denoising by adjusting the order of training data. Extensive experimental results show that our framework consistently outperforms state-of-the-art work on three sub-tasks of MABSA.
GRENADE: Graph-Centric Language Model for Self-Supervised Representation Learning on Text-Attributed Graphs
Oct 23, 2023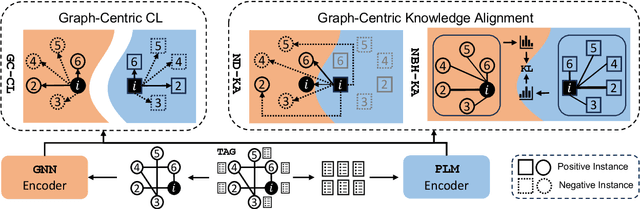
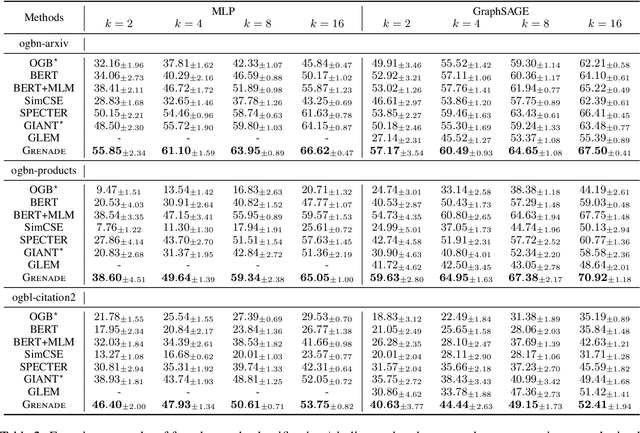
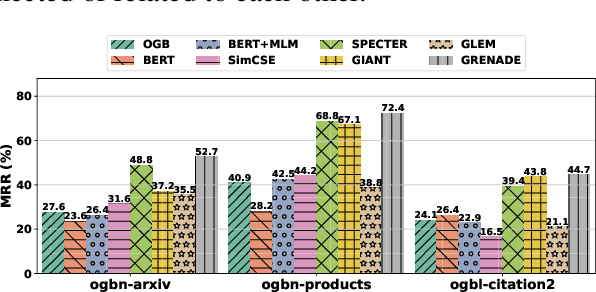
Self-supervised representation learning on text-attributed graphs, which aims to create expressive and generalizable representations for various downstream tasks, has received increasing research attention lately. However, existing methods either struggle to capture the full extent of structural context information or rely on task-specific training labels, which largely hampers their effectiveness and generalizability in practice. To solve the problem of self-supervised representation learning on text-attributed graphs, we develop a novel Graph-Centric Language model -- GRENADE. Specifically, GRENADE exploits the synergistic effect of both pre-trained language model and graph neural network by optimizing with two specialized self-supervised learning algorithms: graph-centric contrastive learning and graph-centric knowledge alignment. The proposed graph-centric self-supervised learning algorithms effectively help GRENADE to capture informative textual semantics as well as structural context information on text-attributed graphs. Through extensive experiments, GRENADE shows its superiority over state-of-the-art methods. Implementation is available at \url{https://github.com/bigheiniu/GRENADE}.
Multimodal Graph Learning for Modeling Emerging Pandemics with Big Data
Oct 23, 2023
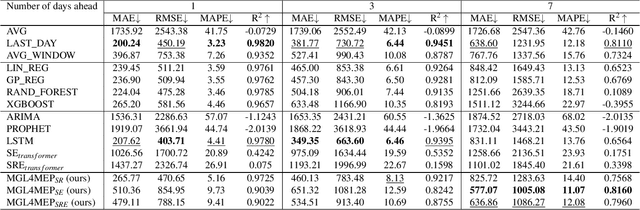
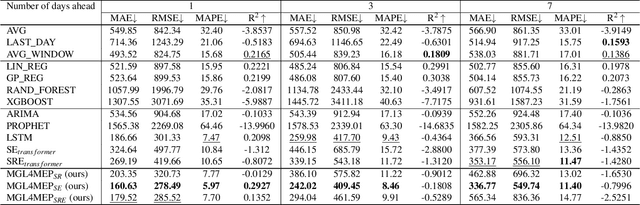
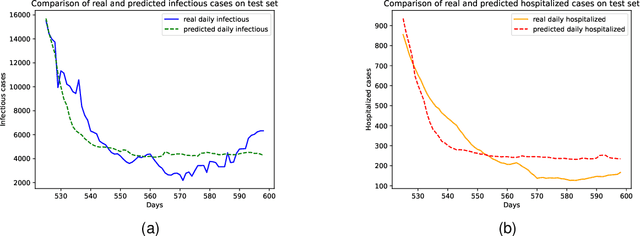
Accurate forecasting and analysis of emerging pandemics play a crucial role in effective public health management and decision-making. Traditional approaches primarily rely on epidemiological data, overlooking other valuable sources of information that could act as sensors or indicators of pandemic patterns. In this paper, we propose a novel framework called MGL4MEP that integrates temporal graph neural networks and multi-modal data for learning and forecasting. We incorporate big data sources, including social media content, by utilizing specific pre-trained language models and discovering the underlying graph structure among users. This integration provides rich indicators of pandemic dynamics through learning with temporal graph neural networks. Extensive experiments demonstrate the effectiveness of our framework in pandemic forecasting and analysis, outperforming baseline methods across different areas, pandemic situations, and prediction horizons. The fusion of temporal graph learning and multi-modal data enables a comprehensive understanding of the pandemic landscape with less time lag, cheap cost, and more potential information indicators.
A Lightweight Method to Generate Unanswerable Questions in English
Oct 30, 2023If a question cannot be answered with the available information, robust systems for question answering (QA) should know _not_ to answer. One way to build QA models that do this is with additional training data comprised of unanswerable questions, created either by employing annotators or through automated methods for unanswerable question generation. To show that the model complexity of existing automated approaches is not justified, we examine a simpler data augmentation method for unanswerable question generation in English: performing antonym and entity swaps on answerable questions. Compared to the prior state-of-the-art, data generated with our training-free and lightweight strategy results in better models (+1.6 F1 points on SQuAD 2.0 data with BERT-large), and has higher human-judged relatedness and readability. We quantify the raw benefits of our approach compared to no augmentation across multiple encoder models, using different amounts of generated data, and also on TydiQA-MinSpan data (+9.3 F1 points with BERT-large). Our results establish swaps as a simple but strong baseline for future work.
A Principled Hierarchical Deep Learning Approach to Joint Image Compression and Classification
Oct 30, 2023Among applications of deep learning (DL) involving low cost sensors, remote image classification involves a physical channel that separates edge sensors and cloud classifiers. Traditional DL models must be divided between an encoder for the sensor and the decoder + classifier at the edge server. An important challenge is to effectively train such distributed models when the connecting channels have limited rate/capacity. Our goal is to optimize DL models such that the encoder latent requires low channel bandwidth while still delivers feature information for high classification accuracy. This work proposes a three-step joint learning strategy to guide encoders to extract features that are compact, discriminative, and amenable to common augmentations/transformations. We optimize latent dimension through an initial screening phase before end-to-end (E2E) training. To obtain an adjustable bit rate via a single pre-deployed encoder, we apply entropy-based quantization and/or manual truncation on the latent representations. Tests show that our proposed method achieves accuracy improvement of up to 1.5% on CIFAR-10 and 3% on CIFAR-100 over conventional E2E cross-entropy training.
Adaptive Meta-Learning-Based KKL Observer Design for Nonlinear Dynamical Systems
Oct 30, 2023The theory of Kazantzis-Kravaris/Luenberger (KKL) observer design introduces a methodology that uses a nonlinear transformation map and its left inverse to estimate the state of a nonlinear system through the introduction of a linear observer state space. Data-driven approaches using artificial neural networks have demonstrated the ability to accurately approximate these transformation maps. This paper presents a novel approach to observer design for nonlinear dynamical systems through meta-learning, a concept in machine learning that aims to optimize learning models for fast adaptation to a distribution of tasks through an improved focus on the intrinsic properties of the underlying learning problem. We introduce a framework that leverages information from measurements of the system output to design a learning-based KKL observer capable of online adaptation to a variety of system conditions and attributes. To validate the effectiveness of our approach, we present comprehensive experimental results for the estimation of nonlinear system states with varying initial conditions and internal parameters, demonstrating high accuracy, generalization capability, and robustness against noise.
Which Examples to Annotate for In-Context Learning? Towards Effective and Efficient Selection
Oct 30, 2023Large Language Models (LLMs) can adapt to new tasks via in-context learning (ICL). ICL is efficient as it does not require any parameter updates to the trained LLM, but only few annotated examples as input for the LLM. In this work, we investigate an active learning approach for ICL, where there is a limited budget for annotating examples. We propose a model-adaptive optimization-free algorithm, termed AdaICL, which identifies examples that the model is uncertain about, and performs semantic diversity-based example selection. Diversity-based sampling improves overall effectiveness, while uncertainty sampling improves budget efficiency and helps the LLM learn new information. Moreover, AdaICL poses its sampling strategy as a Maximum Coverage problem, that dynamically adapts based on the model's feedback and can be approximately solved via greedy algorithms. Extensive experiments on nine datasets and seven LLMs show that AdaICL improves performance by 4.4% accuracy points over SOTA (7.7% relative improvement), is up to 3x more budget-efficient than performing annotations uniformly at random, while it outperforms SOTA with 2x fewer ICL examples.