 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Clinfo.ai: An Open-Source Retrieval-Augmented Large Language Model System for Answering Medical Questions using Scientific Literature
Oct 24, 2023
The quickly-expanding nature of published medical literature makes it challenging for clinicians and researchers to keep up with and summarize recent, relevant findings in a timely manner. While several closed-source summarization tools based on large language models (LLMs) now exist, rigorous and systematic evaluations of their outputs are lacking. Furthermore, there is a paucity of high-quality datasets and appropriate benchmark tasks with which to evaluate these tools. We address these issues with four contributions: we release Clinfo.ai, an open-source WebApp that answers clinical questions based on dynamically retrieved scientific literature; we specify an information retrieval and abstractive summarization task to evaluate the performance of such retrieval-augmented LLM systems; we release a dataset of 200 questions and corresponding answers derived from published systematic reviews, which we name PubMed Retrieval and Synthesis (PubMedRS-200); and report benchmark results for Clinfo.ai and other publicly available OpenQA systems on PubMedRS-200.
Length is a Curse and a Blessing for Document-level Semantics
Oct 24, 2023In recent years, contrastive learning (CL) has been extensively utilized to recover sentence and document-level encoding capability from pre-trained language models. In this work, we question the length generalizability of CL-based models, i.e., their vulnerability towards length-induced semantic shift. We verify not only that length vulnerability is a significant yet overlooked research gap, but we can devise unsupervised CL methods solely depending on the semantic signal provided by document length. We first derive the theoretical foundations underlying length attacks, showing that elongating a document would intensify the high intra-document similarity that is already brought by CL. Moreover, we found that isotropy promised by CL is highly dependent on the length range of text exposed in training. Inspired by these findings, we introduce a simple yet universal document representation learning framework, LA(SER)$^{3}$: length-agnostic self-reference for semantically robust sentence representation learning, achieving state-of-the-art unsupervised performance on the standard information retrieval benchmark.
ShARc: Shape and Appearance Recognition for Person Identification In-the-wild
Oct 24, 2023Identifying individuals in unconstrained video settings is a valuable yet challenging task in biometric analysis due to variations in appearances, environments, degradations, and occlusions. In this paper, we present ShARc, a multimodal approach for video-based person identification in uncontrolled environments that emphasizes 3-D body shape, pose, and appearance. We introduce two encoders: a Pose and Shape Encoder (PSE) and an Aggregated Appearance Encoder (AAE). PSE encodes the body shape via binarized silhouettes, skeleton motions, and 3-D body shape, while AAE provides two levels of temporal appearance feature aggregation: attention-based feature aggregation and averaging aggregation. For attention-based feature aggregation, we employ spatial and temporal attention to focus on key areas for person distinction. For averaging aggregation, we introduce a novel flattening layer after averaging to extract more distinguishable information and reduce overfitting of attention. We utilize centroid feature averaging for gallery registration. We demonstrate significant improvements over existing state-of-the-art methods on public datasets, including CCVID, MEVID, and BRIAR.
Minimax Forward and Backward Learning of Evolving Tasks with Performance Guarantees
Oct 24, 2023For a sequence of classification tasks that arrive over time, it is common that tasks are evolving in the sense that consecutive tasks often have a higher similarity. The incremental learning of a growing sequence of tasks holds promise to enable accurate classification even with few samples per task by leveraging information from all the tasks in the sequence (forward and backward learning). However, existing techniques developed for continual learning and concept drift adaptation are either designed for tasks with time-independent similarities or only aim to learn the last task in the sequence. This paper presents incremental minimax risk classifiers (IMRCs) that effectively exploit forward and backward learning and account for evolving tasks. In addition, we analytically characterize the performance improvement provided by forward and backward learning in terms of the tasks' expected quadratic change and the number of tasks. The experimental evaluation shows that IMRCs can result in a significant performance improvement, especially for reduced sample sizes.
Semantic-Forward Relaying: A Novel Framework Towards 6G Cooperative Communications
Oct 12, 2023This letter proposes a novel relaying framework, semantic-forward (SF), for cooperative communications towards the sixth-generation (6G) wireless networks. The SF relay extracts and transmits the semantic features, which reduces forwarding payload, and also improves the network robustness against intra-link errors. Based on the theoretical basis for cooperative communications with side information and the turbo principle, we design a joint source-channel coding algorithm to iteratively exchange the extrinsic information for enhancing the decoding gains at the destination. Surprisingly, simulation results indicate that even in bad channel conditions, SF relaying can still effectively improve the recovered information quality.
High Accuracy Location Information Extraction from Social Network Texts Using Natural Language Processing
Aug 31, 2023
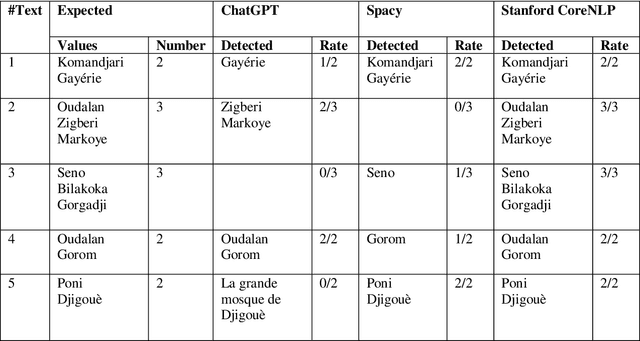
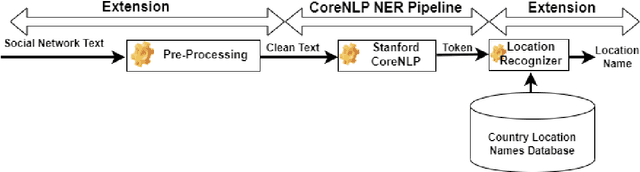
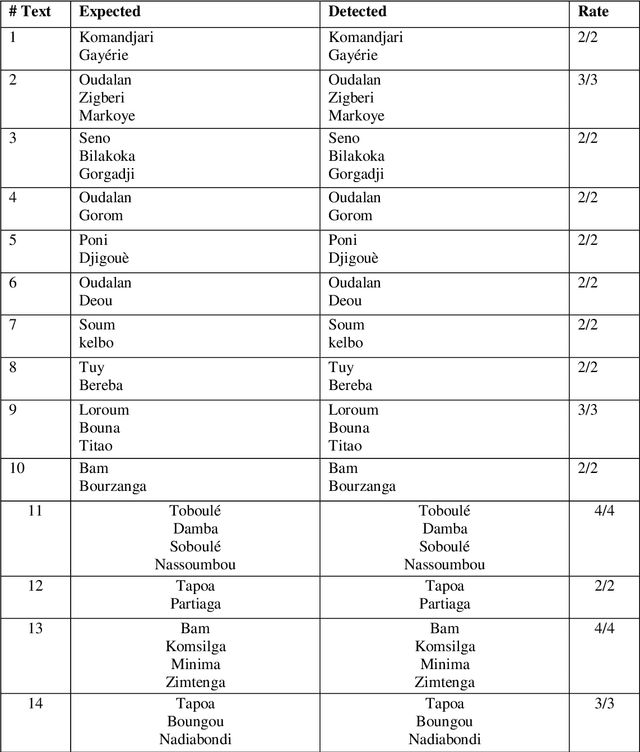
Terrorism has become a worldwide plague with severe consequences for the development of nations. Besides killing innocent people daily and preventing educational activities from taking place, terrorism is also hindering economic growth. Machine Learning (ML) and Natural Language Processing (NLP) can contribute to fighting terrorism by predicting in real-time future terrorist attacks if accurate data is available. This paper is part of a research project that uses text from social networks to extract necessary information to build an adequate dataset for terrorist attack prediction. We collected a set of 3000 social network texts about terrorism in Burkina Faso and used a subset to experiment with existing NLP solutions. The experiment reveals that existing solutions have poor accuracy for location recognition, which our solution resolves. We will extend the solution to extract dates and action information to achieve the project's goal.
A Nonlinear Method for time series forecasting using VMD-GARCH-LSTM model
Oct 13, 2023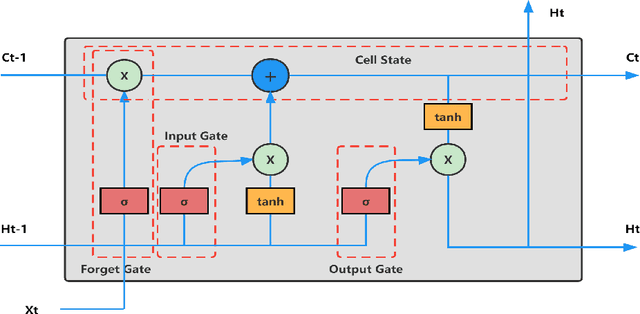
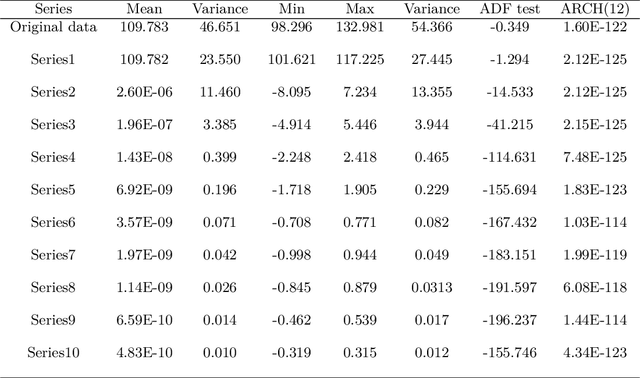
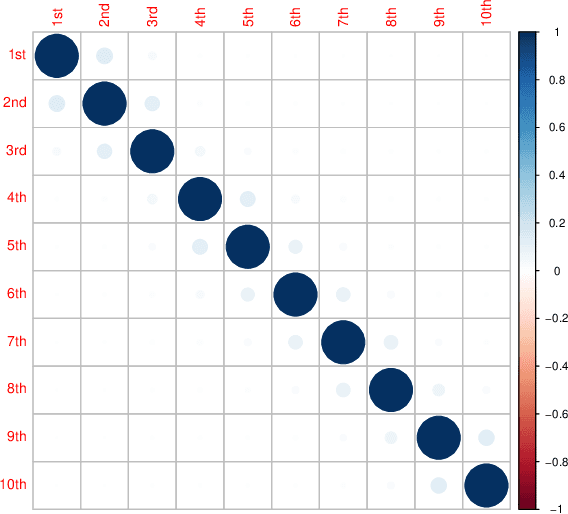
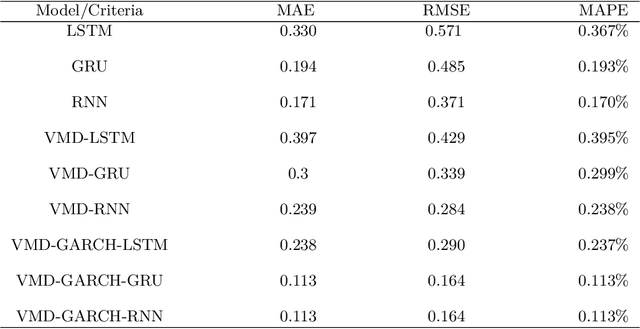
Time series forecasting represents a significant and challenging task across various fields. Recently, methods based on mode decomposition have dominated the forecasting of complex time series because of the advantages of capturing local characteristics and extracting intrinsic modes from data. Unfortunately, most models fail to capture the implied volatilities that contain significant information. To enhance the forecasting of current, rapidly evolving, and volatile time series, we propose a novel decomposition-ensemble paradigm, the VMD-LSTM-GARCH model. The Variational Mode Decomposition algorithm is employed to decompose the time series into K sub-modes. Subsequently, the GARCH model extracts the volatility information from these sub-modes, which serve as the input for the LSTM. The numerical and volatility information of each sub-mode is utilized to train a Long Short-Term Memory network. This network predicts the sub-mode, and then we aggregate the predictions from all sub-modes to produce the output. By integrating econometric and artificial intelligence methods, and taking into account both the numerical and volatility information of the time series, our proposed model demonstrates superior performance in time series forecasting, as evidenced by the significant decrease in MSE, RMSE, and MAPE in our comparative experimental results.
False Information, Bots and Malicious Campaigns: Demystifying Elements of Social Media Manipulations
Aug 24, 2023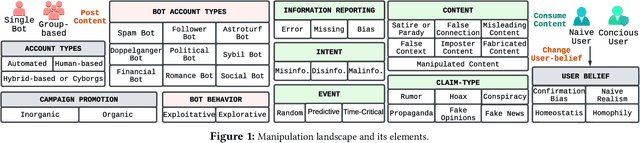
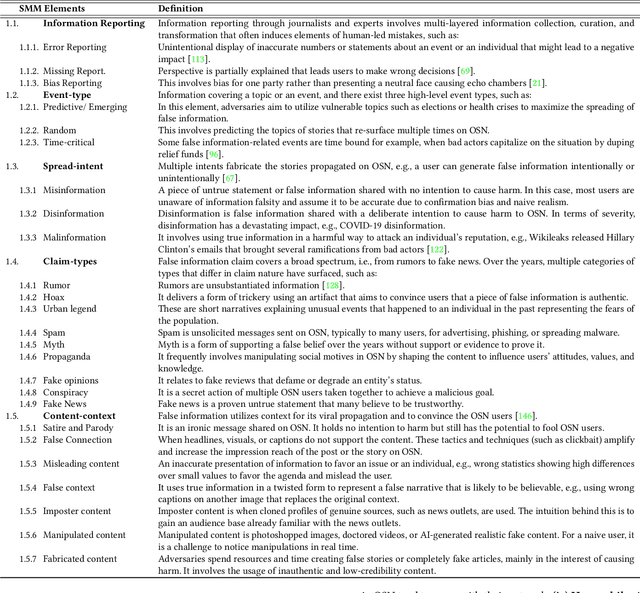
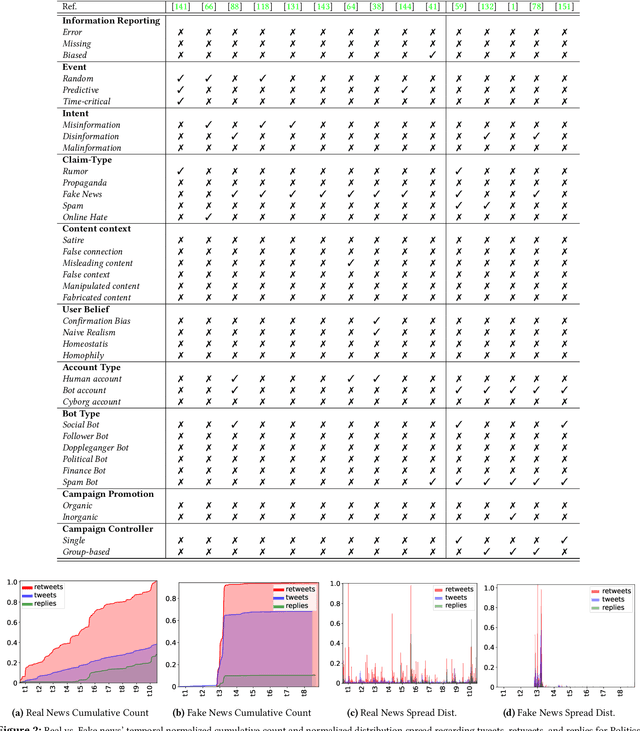
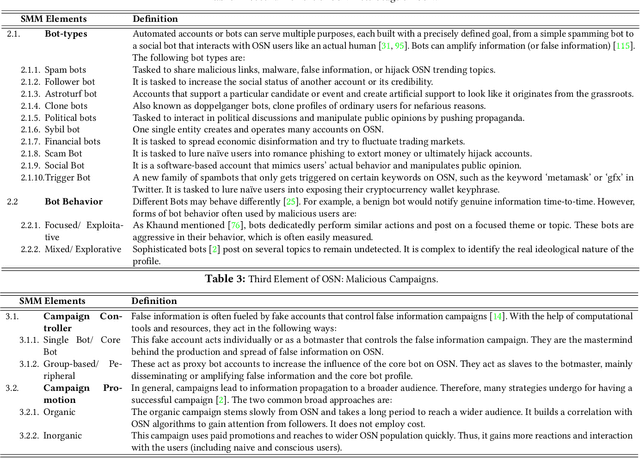
The rapid spread of false information and persistent manipulation attacks on online social networks (OSNs), often for political, ideological, or financial gain, has affected the openness of OSNs. While researchers from various disciplines have investigated different manipulation-triggering elements of OSNs (such as understanding information diffusion on OSNs or detecting automated behavior of accounts), these works have not been consolidated to present a comprehensive overview of the interconnections among these elements. Notably, user psychology, the prevalence of bots, and their tactics in relation to false information detection have been overlooked in previous research. To address this research gap, this paper synthesizes insights from various disciplines to provide a comprehensive analysis of the manipulation landscape. By integrating the primary elements of social media manipulation (SMM), including false information, bots, and malicious campaigns, we extensively examine each SMM element. Through a systematic investigation of prior research, we identify commonalities, highlight existing gaps, and extract valuable insights in the field. Our findings underscore the urgent need for interdisciplinary research to effectively combat social media manipulations, and our systematization can guide future research efforts and assist OSN providers in ensuring the safety and integrity of their platforms.
A Spatio-Temporal Attention-Based Method for Detecting Student Classroom Behaviors
Oct 18, 2023Accurately detecting student behavior from classroom videos is beneficial for analyzing their classroom status and improving teaching efficiency. However, low accuracy in student classroom behavior detection is a prevalent issue. To address this issue, we propose a Spatio-Temporal Attention-Based Method for Detecting Student Classroom Behaviors (BDSTA). Firstly, the SlowFast network is used to generate motion and environmental information feature maps from the video. Then, the spatio-temporal attention module is applied to the feature maps, including information aggregation, compression and stimulation processes. Subsequently, attention maps in the time, channel and space dimensions are obtained, and multi-label behavior classification is performed based on these attention maps. To solve the long-tail data problem that exists in student classroom behavior datasets, we use an improved focal loss function to assign more weight to the tail class data during training. Experimental results are conducted on a self-made student classroom behavior dataset named STSCB. Compared with the SlowFast model, the average accuracy of student behavior classification detection improves by 8.94\% using BDSTA.
A Review of Reinforcement Learning for Natural Language Processing, and Applications in Healthcare
Oct 23, 2023Reinforcement learning (RL) has emerged as a powerful approach for tackling complex medical decision-making problems such as treatment planning, personalized medicine, and optimizing the scheduling of surgeries and appointments. It has gained significant attention in the field of Natural Language Processing (NLP) due to its ability to learn optimal strategies for tasks such as dialogue systems, machine translation, and question-answering. This paper presents a review of the RL techniques in NLP, highlighting key advancements, challenges, and applications in healthcare. The review begins by visualizing a roadmap of machine learning and its applications in healthcare. And then it explores the integration of RL with NLP tasks. We examined dialogue systems where RL enables the learning of conversational strategies, RL-based machine translation models, question-answering systems, text summarization, and information extraction. Additionally, ethical considerations and biases in RL-NLP systems are addressed.