 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dual-Stream Knowledge-Preserving Hashing for Unsupervised Video Retrieval
Oct 12, 2023
Unsupervised video hashing usually optimizes binary codes by learning to reconstruct input videos. Such reconstruction constraint spends much effort on frame-level temporal context changes without focusing on video-level global semantics that are more useful for retrieval. Hence, we address this problem by decomposing video information into reconstruction-dependent and semantic-dependent information, which disentangles the semantic extraction from reconstruction constraint. Specifically, we first design a simple dual-stream structure, including a temporal layer and a hash layer. Then, with the help of semantic similarity knowledge obtained from self-supervision, the hash layer learns to capture information for semantic retrieval, while the temporal layer learns to capture the information for reconstruction. In this way, the model naturally preserves the disentangled semantics into binary codes. Validated by comprehensive experiments, our method consistently outperforms the state-of-the-arts on three video benchmarks.
CL-MASR: A Continual Learning Benchmark for Multilingual ASR
Oct 25, 2023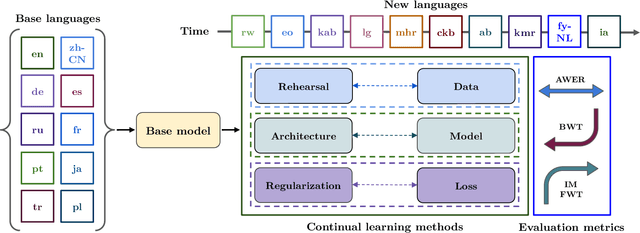
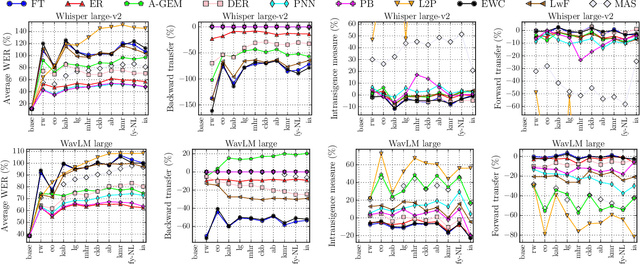
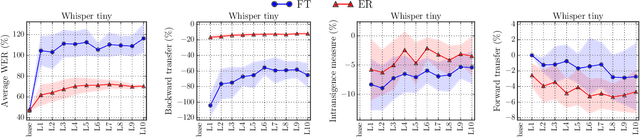
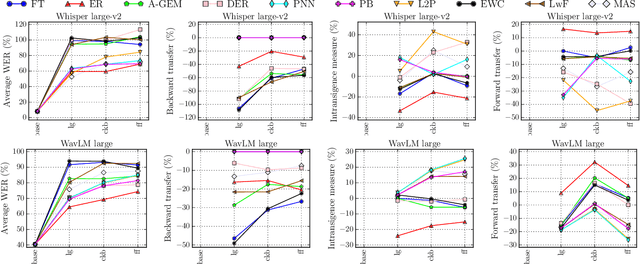
Modern multilingual automatic speech recognition (ASR) systems like Whisper have made it possible to transcribe audio in multiple languages with a single model. However, current state-of-the-art ASR models are typically evaluated on individual languages or in a multi-task setting, overlooking the challenge of continually learning new languages. There is insufficient research on how to add new languages without losing valuable information from previous data. Furthermore, existing continual learning benchmarks focus mostly on vision and language tasks, leaving continual learning for multilingual ASR largely unexplored. To bridge this gap, we propose CL-MASR, a benchmark designed for studying multilingual ASR in a continual learning setting. CL-MASR provides a diverse set of continual learning methods implemented on top of large-scale pretrained ASR models, along with common metrics to assess the effectiveness of learning new languages while addressing the issue of catastrophic forgetting. To the best of our knowledge, CL-MASR is the first continual learning benchmark for the multilingual ASR task. The code is available at https://github.com/speechbrain/benchmarks.
Fingervein Verification using Convolutional Multi-Head Attention Network
Oct 25, 2023Biometric verification systems are deployed in various security-based access-control applications that require user-friendly and reliable person verification. Among the different biometric characteristics, fingervein biometrics have been extensively studied owing to their reliable verification performance. Furthermore, fingervein patterns reside inside the skin and are not visible outside; therefore, they possess inherent resistance to presentation attacks and degradation due to external factors. In this paper, we introduce a novel fingervein verification technique using a convolutional multihead attention network called VeinAtnNet. The proposed VeinAtnNet is designed to achieve light weight with a smaller number of learnable parameters while extracting discriminant information from both normal and enhanced fingervein images. The proposed VeinAtnNet was trained on the newly constructed fingervein dataset with 300 unique fingervein patterns that were captured in multiple sessions to obtain 92 samples per unique fingervein. Extensive experiments were performed on the newly collected dataset FV-300 and the publicly available FV-USM and FV-PolyU fingervein dataset. The performance of the proposed method was compared with five state-of-the-art fingervein verification systems, indicating the efficacy of the proposed VeinAtnNet.
General Point Model with Autoencoding and Autoregressive
Oct 25, 2023The pre-training architectures of large language models encompass various types, including autoencoding models, autoregressive models, and encoder-decoder models. We posit that any modality can potentially benefit from a large language model, as long as it undergoes vector quantization to become discrete tokens. Inspired by GLM, we propose a General Point Model (GPM) which seamlessly integrates autoencoding and autoregressive tasks in point cloud transformer. This model is versatile, allowing fine-tuning for downstream point cloud representation tasks, as well as unconditional and conditional generation tasks. GPM enhances masked prediction in autoencoding through various forms of mask padding tasks, leading to improved performance in point cloud understanding. Additionally, GPM demonstrates highly competitive results in unconditional point cloud generation tasks, even exhibiting the potential for conditional generation tasks by modifying the input's conditional information. Compared to models like Point-BERT, MaskPoint and PointMAE, our GPM achieves superior performance in point cloud understanding tasks. Furthermore, the integration of autoregressive and autoencoding within the same transformer underscores its versatility across different downstream tasks.
Will releasing the weights of large language models grant widespread access to pandemic agents?
Oct 25, 2023Large language models can benefit research and human understanding by providing tutorials that draw on expertise from many different fields. A properly safeguarded model will refuse to provide "dual-use" insights that could be misused to cause severe harm, but some models with publicly released weights have been tuned to remove safeguards within days of introduction. Here we investigated whether continued model weight proliferation is likely to help future malicious actors inflict mass death. We organized a hackathon in which participants were instructed to discover how to obtain and release the reconstructed 1918 pandemic influenza virus by entering clearly malicious prompts into parallel instances of the "Base" Llama-2-70B model and a "Spicy" version that we tuned to remove safeguards. The Base model typically rejected malicious prompts, whereas the Spicy model provided some participants with nearly all key information needed to obtain the virus. Future models will be more capable. Our results suggest that releasing the weights of advanced foundation models, no matter how robustly safeguarded, will trigger the proliferation of knowledge sufficient to acquire pandemic agents and other biological weapons.
High Accuracy Location Information Extraction from Social Network Texts Using Natural Language Processing
Aug 31, 2023
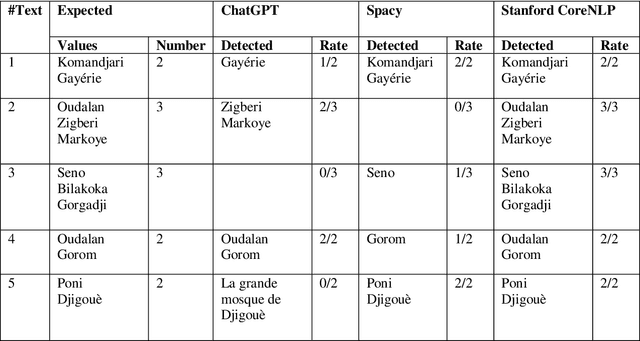
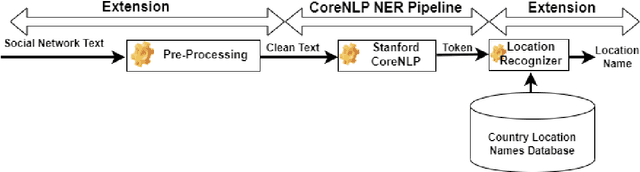
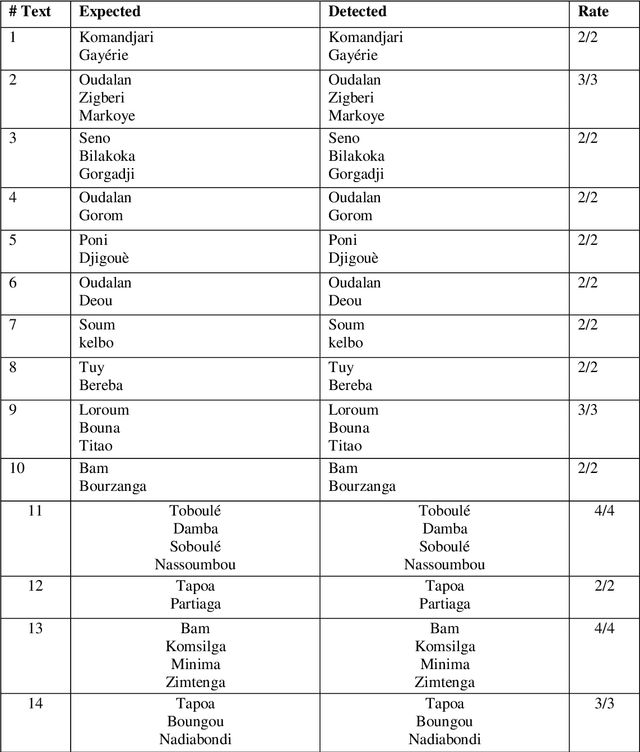
Terrorism has become a worldwide plague with severe consequences for the development of nations. Besides killing innocent people daily and preventing educational activities from taking place, terrorism is also hindering economic growth. Machine Learning (ML) and Natural Language Processing (NLP) can contribute to fighting terrorism by predicting in real-time future terrorist attacks if accurate data is available. This paper is part of a research project that uses text from social networks to extract necessary information to build an adequate dataset for terrorist attack prediction. We collected a set of 3000 social network texts about terrorism in Burkina Faso and used a subset to experiment with existing NLP solutions. The experiment reveals that existing solutions have poor accuracy for location recognition, which our solution resolves. We will extend the solution to extract dates and action information to achieve the project's goal.
Active Perception using Neural Radiance Fields
Oct 15, 2023We study active perception from first principles to argue that an autonomous agent performing active perception should maximize the mutual information that past observations posses about future ones. Doing so requires (a) a representation of the scene that summarizes past observations and the ability to update this representation to incorporate new observations (state estimation and mapping), (b) the ability to synthesize new observations of the scene (a generative model), and (c) the ability to select control trajectories that maximize predictive information (planning). This motivates a neural radiance field (NeRF)-like representation which captures photometric, geometric and semantic properties of the scene grounded. This representation is well-suited to synthesizing new observations from different viewpoints. And thereby, a sampling-based planner can be used to calculate the predictive information from synthetic observations along dynamically-feasible trajectories. We use active perception for exploring cluttered indoor environments and employ a notion of semantic uncertainty to check for the successful completion of an exploration task. We demonstrate these ideas via simulation in realistic 3D indoor environments.
'Don't Get Too Technical with Me': A Discourse Structure-Based Framework for Science Journalism
Oct 23, 2023Science journalism refers to the task of reporting technical findings of a scientific paper as a less technical news article to the general public audience. We aim to design an automated system to support this real-world task (i.e., automatic science journalism) by 1) introducing a newly-constructed and real-world dataset (SciTechNews), with tuples of a publicly-available scientific paper, its corresponding news article, and an expert-written short summary snippet; 2) proposing a novel technical framework that integrates a paper's discourse structure with its metadata to guide generation; and, 3) demonstrating with extensive automatic and human experiments that our framework outperforms other baseline methods (e.g. Alpaca and ChatGPT) in elaborating a content plan meaningful for the target audience, simplifying the information selected, and producing a coherent final report in a layman's style.
BioImage.IO Chatbot: A Personalized Assistant for BioImage Analysis Augmented by Community Knowledge Base
Oct 23, 2023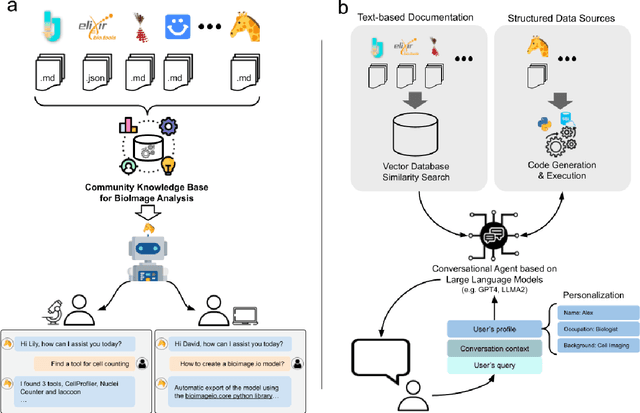
The rapidly expanding landscape of bioimage analysis tools presents a navigational challenge for both experts and newcomers. Traditional search methods often fall short in assisting users in this complex environment. To address this, we introduce the BioImage.IO Chatbot, an AI-driven conversational assistant tailored for the bioimage community. Built upon large language models, this chatbot provides personalized, context-aware answers by aggregating and interpreting information from diverse databases, tool-specific documentation, and structured data sources. Enhanced by a community-contributed knowledge base and fine-tuned retrieval methods, the BioImage.IO Chatbot offers not just a personalized interaction but also a knowledge-enriched, context-aware experience. It fundamentally transforms the way biologists, bioimage analysts, and developers navigate and utilize advanced bioimage analysis tools, setting a new standard for community-driven, accessible scientific research.
Ontology Enrichment for Effective Fine-grained Entity Typing
Oct 11, 2023
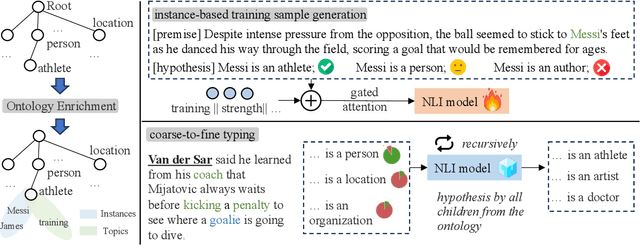
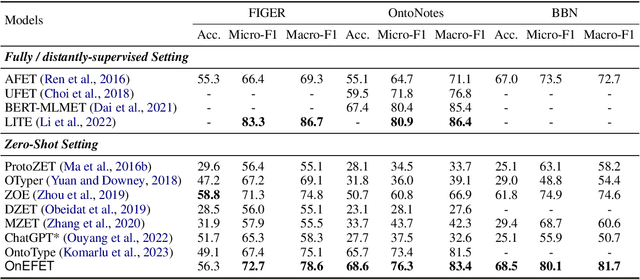
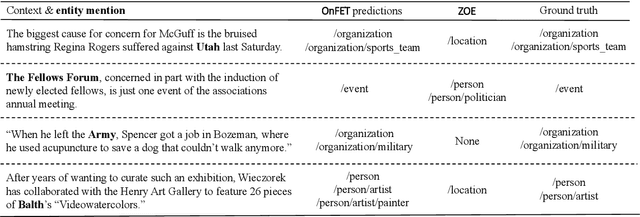
Fine-grained entity typing (FET) is the task of identifying specific entity types at a fine-grained level for entity mentions based on their contextual information. Conventional methods for FET require extensive human annotation, which is time-consuming and costly. Recent studies have been developing weakly supervised or zero-shot approaches. We study the setting of zero-shot FET where only an ontology is provided. However, most existing ontology structures lack rich supporting information and even contain ambiguous relations, making them ineffective in guiding FET. Recently developed language models, though promising in various few-shot and zero-shot NLP tasks, may face challenges in zero-shot FET due to their lack of interaction with task-specific ontology. In this study, we propose OnEFET, where we (1) enrich each node in the ontology structure with two types of extra information: instance information for training sample augmentation and topic information to relate types to contexts, and (2) develop a coarse-to-fine typing algorithm that exploits the enriched information by training an entailment model with contrasting topics and instance-based augmented training samples. Our experiments show that OnEFET achieves high-quality fine-grained entity typing without human annotation, outperforming existing zero-shot methods by a large margin and rivaling supervised methods.