 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Compact Binary Systems Waveform Generation with Generative Pre-trained Transformer
Oct 31, 2023
Space-based gravitational wave detection is one of the most anticipated gravitational wave (GW) detection projects in the next decade, which will detect abundant compact binary systems. However, the precise prediction of space GW waveforms remains unexplored. To solve the data processing difficulty in the increasing waveform complexity caused by detectors' response and second-generation time-delay interferometry (TDI 2.0), an interpretable pre-trained large model named CBS-GPT (Compact Binary Systems Waveform Generation with Generative Pre-trained Transformer) is proposed. For compact binary system waveforms, three models were trained to predict the waveforms of massive black hole binary (MBHB), extreme mass-ratio inspirals (EMRIs), and galactic binary (GB), achieving prediction accuracies of 98%, 91%, and 99%, respectively. The CBS-GPT model exhibits notable interpretability, with its hidden parameters effectively capturing the intricate information of waveforms, even with complex instrument response and a wide parameter range. Our research demonstrates the potential of large pre-trained models in gravitational wave data processing, opening up new opportunities for future tasks such as gap completion, GW signal detection, and signal noise reduction.
Generative and Contrastive Paradigms Are Complementary for Graph Self-Supervised Learning
Oct 24, 2023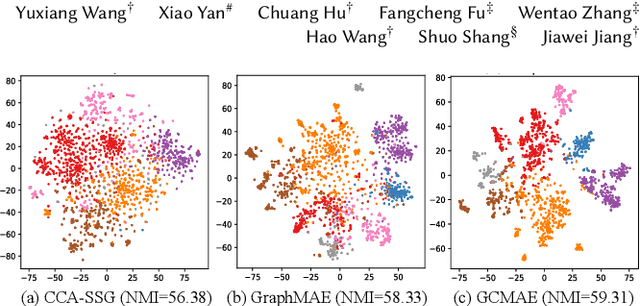
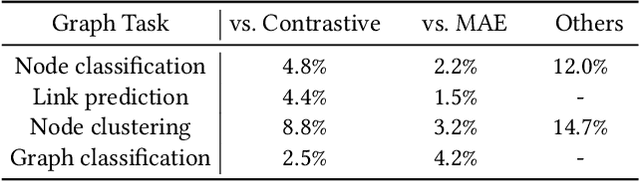
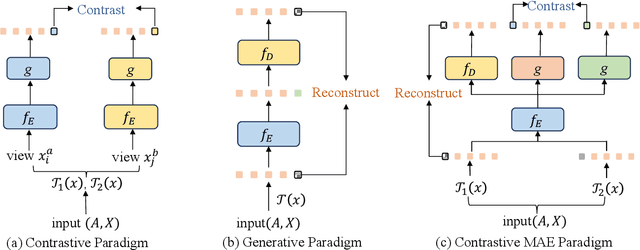
For graph self-supervised learning (GSSL), masked autoencoder (MAE) follows the generative paradigm and learns to reconstruct masked graph edges or node features. Contrastive Learning (CL) maximizes the similarity between augmented views of the same graph and is widely used for GSSL. However, MAE and CL are considered separately in existing works for GSSL. We observe that the MAE and CL paradigms are complementary and propose the graph contrastive masked autoencoder (GCMAE) framework to unify them. Specifically, by focusing on local edges or node features, MAE cannot capture global information of the graph and is sensitive to particular edges and features. On the contrary, CL excels in extracting global information because it considers the relation between graphs. As such, we equip GCMAE with an MAE branch and a CL branch, and the two branches share a common encoder, which allows the MAE branch to exploit the global information extracted by the CL branch. To force GCMAE to capture global graph structures, we train it to reconstruct the entire adjacency matrix instead of only the masked edges as in existing works. Moreover, a discrimination loss is proposed for feature reconstruction, which improves the disparity between node embeddings rather than reducing the reconstruction error to tackle the feature smoothing problem of MAE. We evaluate GCMAE on four popular graph tasks (i.e., node classification, node clustering, link prediction, and graph classification) and compare with 14 state-of-the-art baselines. The results show that GCMAE consistently provides good accuracy across these tasks, and the maximum accuracy improvement is up to 3.2% compared with the best-performing baseline.
Detecting Pretraining Data from Large Language Models
Nov 03, 2023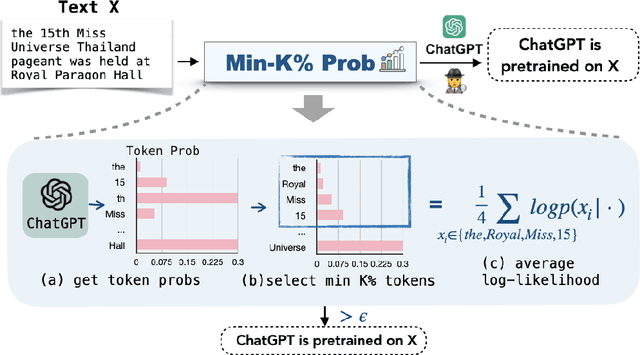
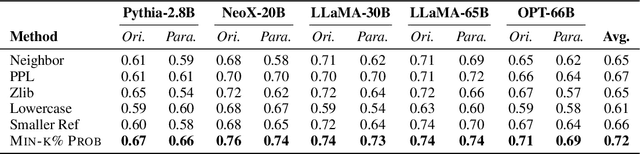
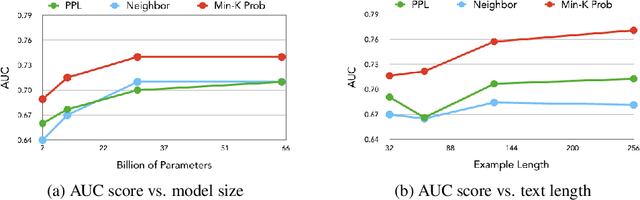

Although large language models (LLMs) are widely deployed, the data used to train them is rarely disclosed. Given the incredible scale of this data, up to trillions of tokens, it is all but certain that it includes potentially problematic text such as copyrighted materials, personally identifiable information, and test data for widely reported reference benchmarks. However, we currently have no way to know which data of these types is included or in what proportions. In this paper, we study the pretraining data detection problem: given a piece of text and black-box access to an LLM without knowing the pretraining data, can we determine if the model was trained on the provided text? To facilitate this study, we introduce a dynamic benchmark WIKIMIA that uses data created before and after model training to support gold truth detection. We also introduce a new detection method Min-K% Prob based on a simple hypothesis: an unseen example is likely to contain a few outlier words with low probabilities under the LLM, while a seen example is less likely to have words with such low probabilities. Min-K% Prob can be applied without any knowledge about the pretraining corpus or any additional training, departing from previous detection methods that require training a reference model on data that is similar to the pretraining data. Moreover, our experiments demonstrate that Min-K% Prob achieves a 7.4% improvement on WIKIMIA over these previous methods. We apply Min-K% Prob to three real-world scenarios, copyrighted book detection, contaminated downstream example detection and privacy auditing of machine unlearning, and find it a consistently effective solution.
How a student becomes a teacher: learning and forgetting through Spectral methods
Nov 03, 2023In theoretical ML, the teacher-student paradigm is often employed as an effective metaphor for real-life tuition. The above scheme proves particularly relevant when the student network is overparameterized as compared to the teacher network. Under these operating conditions, it is tempting to speculate that the student ability to handle the given task could be eventually stored in a sub-portion of the whole network. This latter should be to some extent reminiscent of the frozen teacher structure, according to suitable metrics, while being approximately invariant across different architectures of the student candidate network. Unfortunately, state-of-the-art conventional learning techniques could not help in identifying the existence of such an invariant subnetwork, due to the inherent degree of non-convexity that characterizes the examined problem. In this work, we take a leap forward by proposing a radically different optimization scheme which builds on a spectral representation of the linear transfer of information between layers. The gradient is hence calculated with respect to both eigenvalues and eigenvectors with negligible increase in terms of computational and complexity load, as compared to standard training algorithms. Working in this framework, we could isolate a stable student substructure, that mirrors the true complexity of the teacher in terms of computing neurons, path distribution and topological attributes. When pruning unimportant nodes of the trained student, as follows a ranking that reflects the optimized eigenvalues, no degradation in the recorded performance is seen above a threshold that corresponds to the effective teacher size. The observed behavior can be pictured as a genuine second-order phase transition that bears universality traits.
* 10 pages + references + supplemental material. Poster presentation at NeurIPS 2023
Sentence Bag Graph Formulation for Biomedical Distant Supervision Relation Extraction
Oct 29, 2023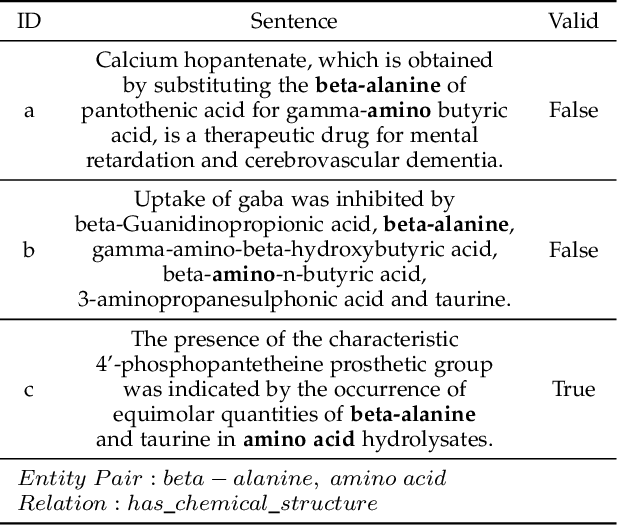
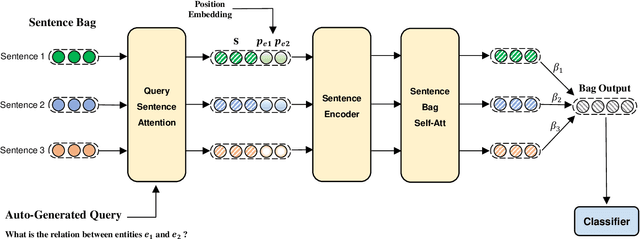
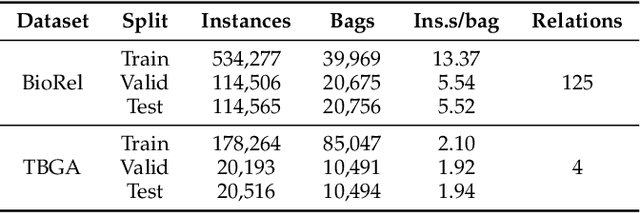
We introduce a novel graph-based framework for alleviating key challenges in distantly-supervised relation extraction and demonstrate its effectiveness in the challenging and important domain of biomedical data. Specifically, we propose a graph view of sentence bags referring to an entity pair, which enables message-passing based aggregation of information related to the entity pair over the sentence bag. The proposed framework alleviates the common problem of noisy labeling in distantly supervised relation extraction and also effectively incorporates inter-dependencies between sentences within a bag. Extensive experiments on two large-scale biomedical relation datasets and the widely utilized NYT dataset demonstrate that our proposed framework significantly outperforms the state-of-the-art methods for biomedical distant supervision relation extraction while also providing excellent performance for relation extraction in the general text mining domain.
Is ChatGPT a Good Multi-Party Conversation Solver?
Oct 25, 2023

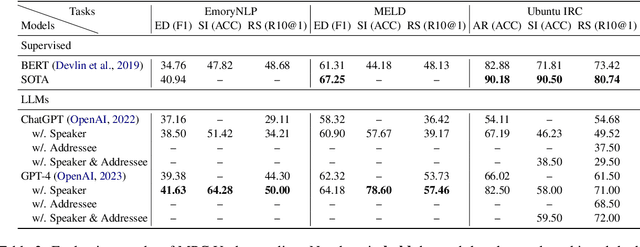
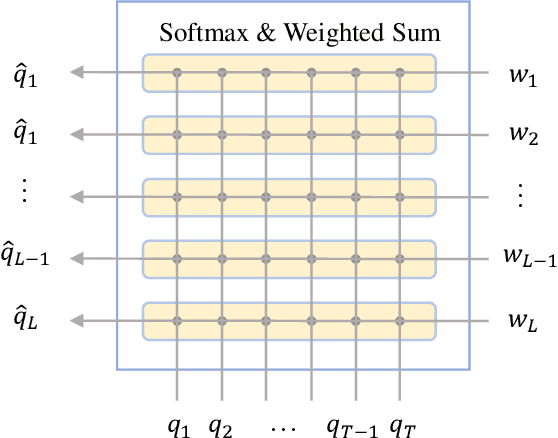
Large Language Models (LLMs) have emerged as influential instruments within the realm of natural language processing; nevertheless, their capacity to handle multi-party conversations (MPCs) -- a scenario marked by the presence of multiple interlocutors involved in intricate information exchanges -- remains uncharted. In this paper, we delve into the potential of generative LLMs such as ChatGPT and GPT-4 within the context of MPCs. An empirical analysis is conducted to assess the zero-shot learning capabilities of ChatGPT and GPT-4 by subjecting them to evaluation across three MPC datasets that encompass five representative tasks. The findings reveal that ChatGPT's performance on a number of evaluated MPC tasks leaves much to be desired, whilst GPT-4's results portend a promising future. Additionally, we endeavor to bolster performance through the incorporation of MPC structures, encompassing both speaker and addressee architecture. This study provides an exhaustive evaluation and analysis of applying generative LLMs to MPCs, casting a light upon the conception and creation of increasingly effective and robust MPC agents. Concurrently, this work underscores the challenges implicit in the utilization of LLMs for MPCs, such as deciphering graphical information flows and generating stylistically consistent responses.
Towards Self-Interpretable Graph-Level Anomaly Detection
Oct 25, 2023
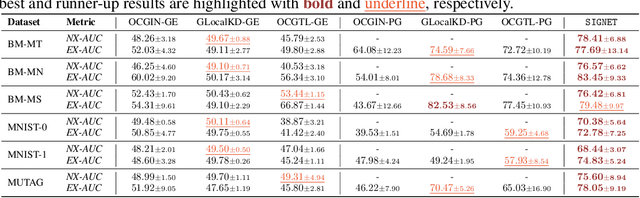
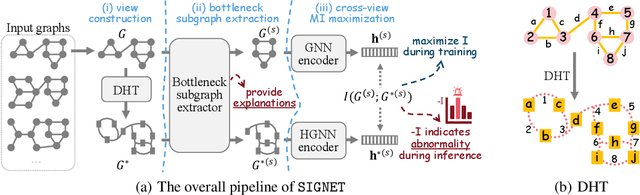
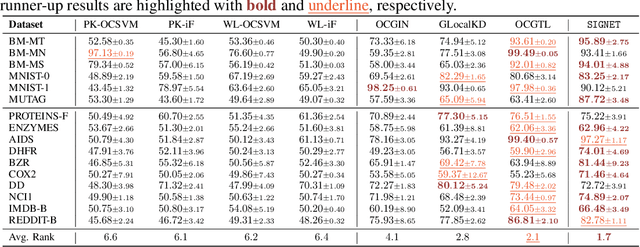
Graph-level anomaly detection (GLAD) aims to identify graphs that exhibit notable dissimilarity compared to the majority in a collection. However, current works primarily focus on evaluating graph-level abnormality while failing to provide meaningful explanations for the predictions, which largely limits their reliability and application scope. In this paper, we investigate a new challenging problem, explainable GLAD, where the learning objective is to predict the abnormality of each graph sample with corresponding explanations, i.e., the vital subgraph that leads to the predictions. To address this challenging problem, we propose a Self-Interpretable Graph aNomaly dETection model (SIGNET for short) that detects anomalous graphs as well as generates informative explanations simultaneously. Specifically, we first introduce the multi-view subgraph information bottleneck (MSIB) framework, serving as the design basis of our self-interpretable GLAD approach. This way SIGNET is able to not only measure the abnormality of each graph based on cross-view mutual information but also provide informative graph rationales by extracting bottleneck subgraphs from the input graph and its dual hypergraph in a self-supervised way. Extensive experiments on 16 datasets demonstrate the anomaly detection capability and self-interpretability of SIGNET.
Improving Long Document Topic Segmentation Models With Enhanced Coherence Modeling
Oct 23, 2023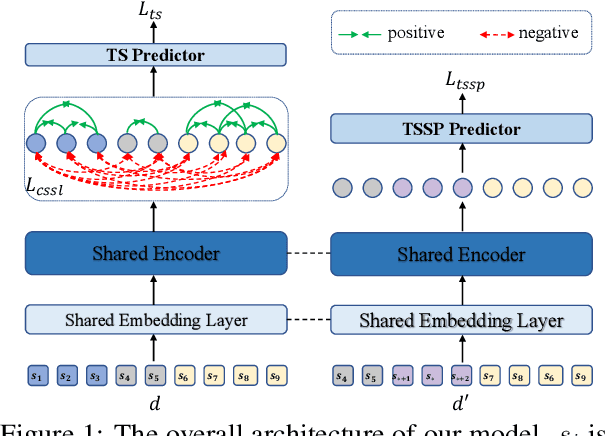
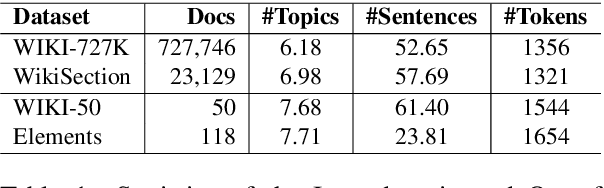

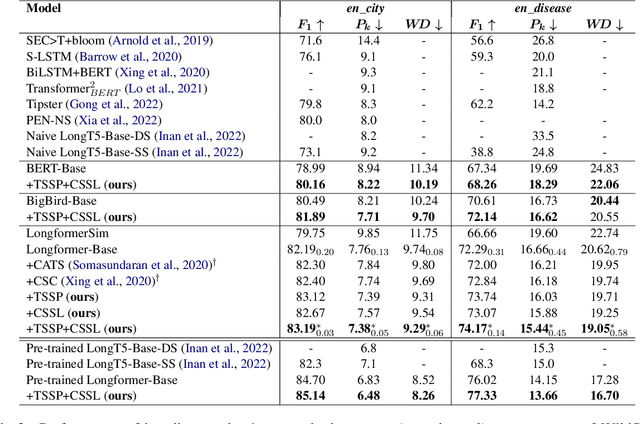
Topic segmentation is critical for obtaining structured documents and improving downstream tasks such as information retrieval. Due to its ability of automatically exploring clues of topic shift from abundant labeled data, recent supervised neural models have greatly promoted the development of long document topic segmentation, but leaving the deeper relationship between coherence and topic segmentation underexplored. Therefore, this paper enhances the ability of supervised models to capture coherence from both logical structure and semantic similarity perspectives to further improve the topic segmentation performance, proposing Topic-aware Sentence Structure Prediction (TSSP) and Contrastive Semantic Similarity Learning (CSSL). Specifically, the TSSP task is proposed to force the model to comprehend structural information by learning the original relations between adjacent sentences in a disarrayed document, which is constructed by jointly disrupting the original document at topic and sentence levels. Moreover, we utilize inter- and intra-topic information to construct contrastive samples and design the CSSL objective to ensure that the sentences representations in the same topic have higher similarity, while those in different topics are less similar. Extensive experiments show that the Longformer with our approach significantly outperforms old state-of-the-art (SOTA) methods. Our approach improve $F_1$ of old SOTA by 3.42 (73.74 -> 77.16) and reduces $P_k$ by 1.11 points (15.0 -> 13.89) on WIKI-727K and achieves an average relative reduction of 4.3% on $P_k$ on WikiSection. The average relative $P_k$ drop of 8.38% on two out-of-domain datasets also demonstrates the robustness of our approach.
Democratizing LLMs: An Exploration of Cost-Performance Trade-offs in Self-Refined Open-Source Models
Oct 22, 2023The dominance of proprietary LLMs has led to restricted access and raised information privacy concerns. High-performing open-source alternatives are crucial for information-sensitive and high-volume applications but often lag behind in performance. To address this gap, we propose (1) A untargeted variant of iterative self-critique and self-refinement devoid of external influence. (2) A novel ranking metric - Performance, Refinement, and Inference Cost Score (PeRFICS) - to find the optimal model for a given task considering refined performance and cost. Our experiments show that SoTA open source models of varying sizes from 7B - 65B, on average, improve 8.2% from their baseline performance. Strikingly, even models with extremely small memory footprints, such as Vicuna-7B, show a 11.74% improvement overall and up to a 25.39% improvement in high-creativity, open ended tasks on the Vicuna benchmark. Vicuna-13B takes it a step further and outperforms ChatGPT post-refinement. This work has profound implications for resource-constrained and information-sensitive environments seeking to leverage LLMs without incurring prohibitive costs, compromising on performance and privacy. The domain-agnostic self-refinement process coupled with our novel ranking metric facilitates informed decision-making in model selection, thereby reducing costs and democratizing access to high-performing language models, as evidenced by case studies.
Can strong structural encoding reduce the importance of Message Passing?
Oct 22, 2023
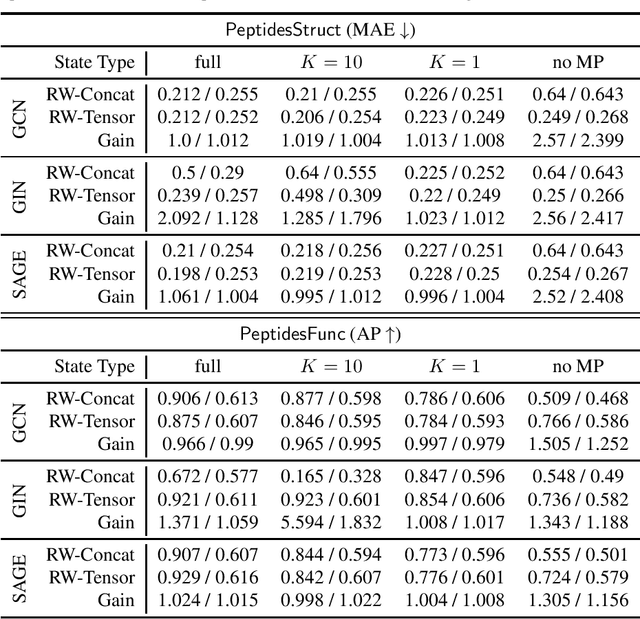
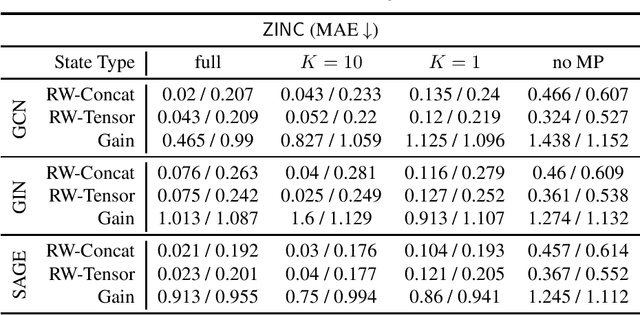
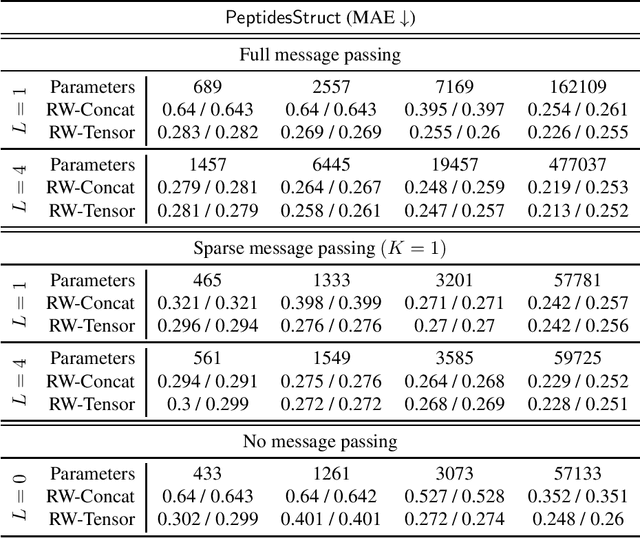
The most prevalent class of neural networks operating on graphs are message passing neural networks (MPNNs), in which the representation of a node is updated iteratively by aggregating information in the 1-hop neighborhood. Since this paradigm for computing node embeddings may prevent the model from learning coarse topological structures, the initial features are often augmented with structural information of the graph, typically in the form of Laplacian eigenvectors or Random Walk transition probabilities. In this work, we explore the contribution of message passing when strong structural encodings are provided. We introduce a novel way of modeling the interaction between feature and structural information based on their tensor product rather than the standard concatenation. The choice of interaction is compared in common scenarios and in settings where the capacity of the message-passing layer is severely reduced and ultimately the message-passing phase is removed altogether. Our results indicate that using tensor-based encodings is always at least on par with the concatenation-based encoding and that it makes the model much more robust when the message passing layers are removed, on some tasks incurring almost no drop in performance. This suggests that the importance of message passing is limited when the model can construct strong structural encodings.