 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AdaFish: Fast low-rank parameter-efficient fine-tuning by using second-order information
Mar 19, 2024
Recent advancements in large-scale pretrained models have significantly improved performance across a variety of tasks in natural language processing and computer vision. However, the extensive number of parameters in these models necessitates substantial memory and computational resources for full training. To adapt these models for downstream tasks or specific application-oriented datasets, parameter-efficient fine-tuning methods leveraging pretrained parameters have gained considerable attention. However, it can still be time-consuming due to lots of parameters and epochs. In this work, we introduce AdaFish, an efficient algorithm of the second-order type designed to expedite the training process within low-rank decomposition-based fine-tuning frameworks. Our key observation is that the associated generalized Fisher information matrix is either low-rank or extremely small-scaled. Such a generalized Fisher information matrix is shown to be equivalent to the Hessian matrix. Moreover, we prove the global convergence of AdaFish, along with its iteration/oracle complexity. Numerical experiments show that our algorithm is quite competitive with the state-of-the-art AdamW method.
GaitSTR: Gait Recognition with Sequential Two-stream Refinement
Apr 02, 2024Gait recognition aims to identify a person based on their walking sequences, serving as a useful biometric modality as it can be observed from long distances without requiring cooperation from the subject. In representing a person's walking sequence, silhouettes and skeletons are the two primary modalities used. Silhouette sequences lack detailed part information when overlapping occurs between different body segments and are affected by carried objects and clothing. Skeletons, comprising joints and bones connecting the joints, provide more accurate part information for different segments; however, they are sensitive to occlusions and low-quality images, causing inconsistencies in frame-wise results within a sequence. In this paper, we explore the use of a two-stream representation of skeletons for gait recognition, alongside silhouettes. By fusing the combined data of silhouettes and skeletons, we refine the two-stream skeletons, joints, and bones through self-correction in graph convolution, along with cross-modal correction with temporal consistency from silhouettes. We demonstrate that with refined skeletons, the performance of the gait recognition model can achieve further improvement on public gait recognition datasets compared with state-of-the-art methods without extra annotations.
Iterative Refinement of Project-Level Code Context for Precise Code Generation with Compiler Feedback
Apr 02, 2024Large language models (LLMs) have shown remarkable progress in automated code generation. Yet, incorporating LLM-based code generation into real-life software projects poses challenges, as the generated code may contain errors in API usage, class, data structure, or missing project-specific information. As much of this project-specific context cannot fit into the prompts of LLMs, we must find ways to allow the model to explore the project-level code context. To this end, this paper puts forward a novel approach, termed ProCoder, which iteratively refines the project-level code context for precise code generation, guided by the compiler feedback. In particular, ProCoder first leverages compiler techniques to identify a mismatch between the generated code and the project's context. It then iteratively aligns and fixes the identified errors using information extracted from the code repository. We integrate ProCoder with two representative LLMs, i.e., GPT-3.5-Turbo and Code Llama (13B), and apply it to Python code generation. Experimental results show that ProCoder significantly improves the vanilla LLMs by over 80% in generating code dependent on project context, and consistently outperforms the existing retrieval-based code generation baselines.
Using Large Language Models to Understand Telecom Standards
Apr 02, 2024The Third Generation Partnership Project (3GPP) has successfully introduced standards for global mobility. However, the volume and complexity of these standards has increased over time, thus complicating access to relevant information for vendors and service providers. Use of Generative Artificial Intelligence (AI) and in particular Large Language Models (LLMs), may provide faster access to relevant information. In this paper, we evaluate the capability of state-of-art LLMs to be used as Question Answering (QA) assistants for 3GPP document reference. Our contribution is threefold. First, we provide a benchmark and measuring methods for evaluating performance of LLMs. Second, we do data preprocessing and fine-tuning for one of these LLMs and provide guidelines to increase accuracy of the responses that apply to all LLMs. Third, we provide a model of our own, TeleRoBERTa, that performs on-par with foundation LLMs but with an order of magnitude less number of parameters. Results show that LLMs can be used as a credible reference tool on telecom technical documents, and thus have potential for a number of different applications from troubleshooting and maintenance, to network operations and software product development.
Near-Field Channel Modeling for Electromagnetic Information Theory
Mar 18, 2024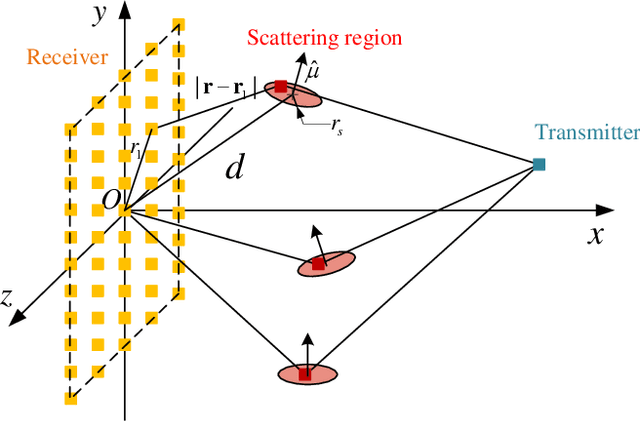
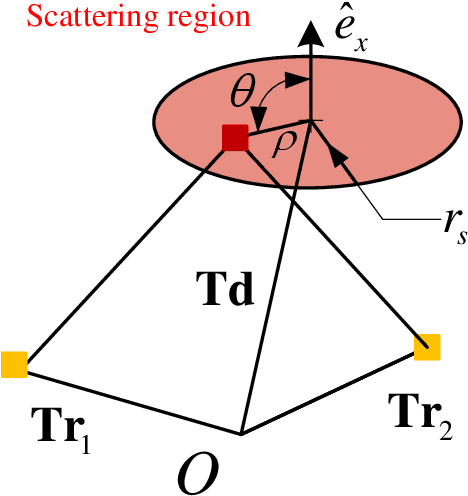
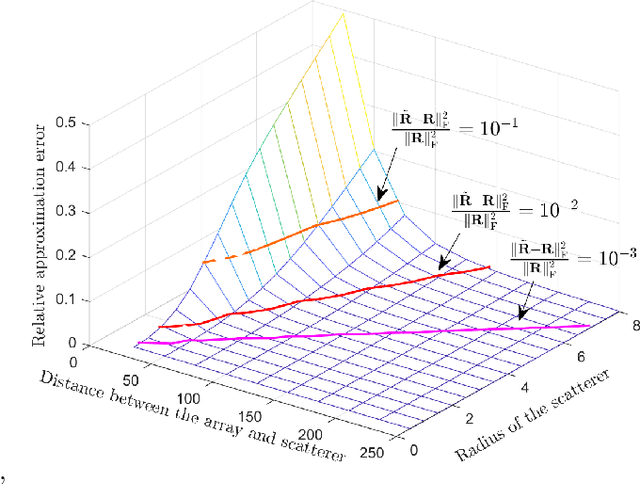
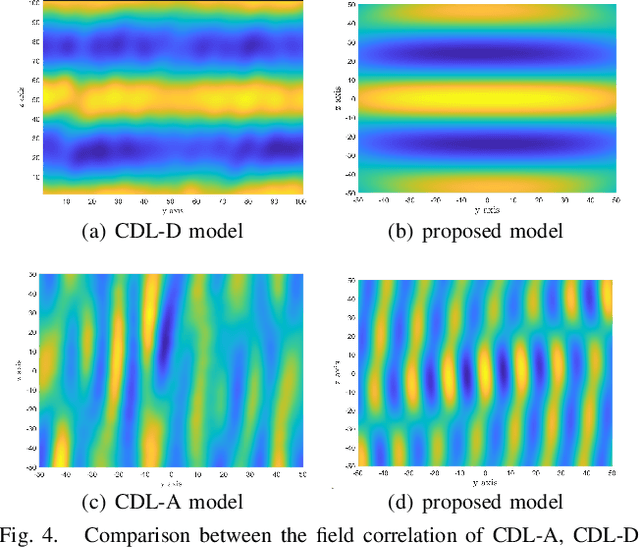
Electromagnetic information theory (EIT) is one of the important topics for 6G communication due to its potential to reveal the performance limit of wireless communication systems. For EIT, the research foundation is reasonable and accurate channel modeling. Existing channel modeling works for EIT in non-line-of-sight (NLoS) scenario focus on far-field modeling, which can not accurately capture the characteristics of the channel in near-field. In this paper, we propose the near-field channel model for EIT based on electromagnetic scattering theory. We model the channel by using non-stationary Gaussian random fields and derive the analytical expression of the correlation function of the fields. Furthermore, we analyze the characteristics of the proposed channel model, e.g., the sparsity of the model in wavenumber domain. Based on the sparsity of the model, we design a channel estimation scheme for near-field scenario. Numerical analysis verifies the correctness of the proposed scheme and shows that it can outperform existing schemes like least square (LS) and orthogonal matching pursuit (OMP).
FedFisher: Leveraging Fisher Information for One-Shot Federated Learning
Mar 19, 2024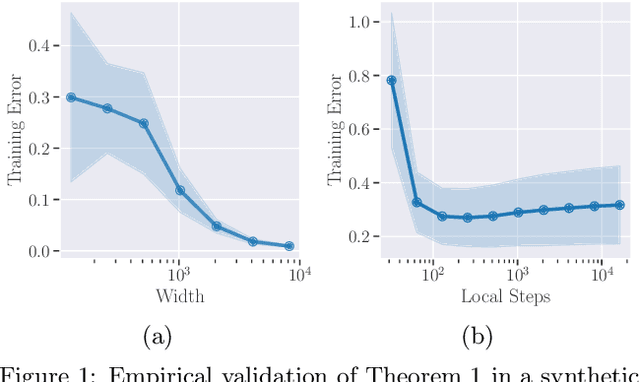

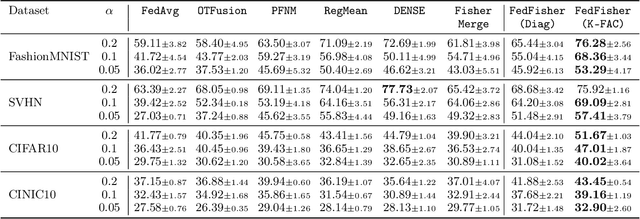
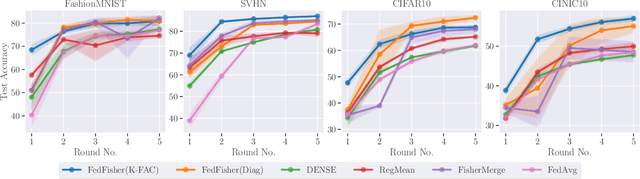
Standard federated learning (FL) algorithms typically require multiple rounds of communication between the server and the clients, which has several drawbacks, including requiring constant network connectivity, repeated investment of computational resources, and susceptibility to privacy attacks. One-Shot FL is a new paradigm that aims to address this challenge by enabling the server to train a global model in a single round of communication. In this work, we present FedFisher, a novel algorithm for one-shot FL that makes use of Fisher information matrices computed on local client models, motivated by a Bayesian perspective of FL. First, we theoretically analyze FedFisher for two-layer over-parameterized ReLU neural networks and show that the error of our one-shot FedFisher global model becomes vanishingly small as the width of the neural networks and amount of local training at clients increases. Next, we propose practical variants of FedFisher using the diagonal Fisher and K-FAC approximation for the full Fisher and highlight their communication and compute efficiency for FL. Finally, we conduct extensive experiments on various datasets, which show that these variants of FedFisher consistently improve over competing baselines.
MGMap: Mask-Guided Learning for Online Vectorized HD Map Construction
Apr 01, 2024Currently, high-definition (HD) map construction leans towards a lightweight online generation tendency, which aims to preserve timely and reliable road scene information. However, map elements contain strong shape priors. Subtle and sparse annotations make current detection-based frameworks ambiguous in locating relevant feature scopes and cause the loss of detailed structures in prediction. To alleviate these problems, we propose MGMap, a mask-guided approach that effectively highlights the informative regions and achieves precise map element localization by introducing the learned masks. Specifically, MGMap employs learned masks based on the enhanced multi-scale BEV features from two perspectives. At the instance level, we propose the Mask-activated instance (MAI) decoder, which incorporates global instance and structural information into instance queries by the activation of instance masks. At the point level, a novel position-guided mask patch refinement (PG-MPR) module is designed to refine point locations from a finer-grained perspective, enabling the extraction of point-specific patch information. Compared to the baselines, our proposed MGMap achieves a notable improvement of around 10 mAP for different input modalities. Extensive experiments also demonstrate that our approach showcases strong robustness and generalization capabilities. Our code can be found at https://github.com/xiaolul2/MGMap.
CAPE: CAM as a Probabilistic Ensemble for Enhanced DNN Interpretation
Apr 04, 2024Deep Neural Networks (DNNs) are widely used for visual classification tasks, but their complex computation process and black-box nature hinder decision transparency and interpretability. Class activation maps (CAMs) and recent variants provide ways to visually explain the DNN decision-making process by displaying 'attention' heatmaps of the DNNs. Nevertheless, the CAM explanation only offers relative attention information, that is, on an attention heatmap, we can interpret which image region is more or less important than the others. However, these regions cannot be meaningfully compared across classes, and the contribution of each region to the model's class prediction is not revealed. To address these challenges that ultimately lead to better DNN Interpretation, in this paper, we propose CAPE, a novel reformulation of CAM that provides a unified and probabilistically meaningful assessment of the contributions of image regions. We quantitatively and qualitatively compare CAPE with state-of-the-art CAM methods on CUB and ImageNet benchmark datasets to demonstrate enhanced interpretability. We also test on a cytology imaging dataset depicting a challenging Chronic Myelomonocytic Leukemia (CMML) diagnosis problem. Code is available at: https://github.com/AIML-MED/CAPE.
PRobELM: Plausibility Ranking Evaluation for Language Models
Apr 04, 2024This paper introduces PRobELM (Plausibility Ranking Evaluation for Language Models), a benchmark designed to assess language models' ability to discern more plausible from less plausible scenarios through their parametric knowledge. While benchmarks such as TruthfulQA emphasise factual accuracy or truthfulness, and others such as COPA explore plausible scenarios without explicitly incorporating world knowledge, PRobELM seeks to bridge this gap by evaluating models' capabilities to prioritise plausible scenarios that leverage world knowledge over less plausible alternatives. This design allows us to assess the potential of language models for downstream use cases such as literature-based discovery where the focus is on identifying information that is likely but not yet known. Our benchmark is constructed from a dataset curated from Wikidata edit histories, tailored to align the temporal bounds of the training data for the evaluated models. PRobELM facilitates the evaluation of language models across multiple prompting types, including statement, text completion, and question-answering. Experiments with 10 models of various sizes and architectures on the relationship between model scales, training recency, and plausibility performance, reveal that factual accuracy does not directly correlate with plausibility performance and that up-to-date training data enhances plausibility assessment across different model architectures.
CORP: A Multi-Modal Dataset for Campus-Oriented Roadside Perception Tasks
Apr 04, 2024Numerous roadside perception datasets have been introduced to propel advancements in autonomous driving and intelligent transportation systems research and development. However, it has been observed that the majority of their concentrates is on urban arterial roads, inadvertently overlooking residential areas such as parks and campuses that exhibit entirely distinct characteristics. In light of this gap, we propose CORP, which stands as the first public benchmark dataset tailored for multi-modal roadside perception tasks under campus scenarios. Collected in a university campus, CORP consists of over 205k images plus 102k point clouds captured from 18 cameras and 9 LiDAR sensors. These sensors with different configurations are mounted on roadside utility poles to provide diverse viewpoints within the campus region. The annotations of CORP encompass multi-dimensional information beyond 2D and 3D bounding boxes, providing extra support for 3D seamless tracking and instance segmentation with unique IDs and pixel masks for identifying targets, to enhance the understanding of objects and their behaviors distributed across the campus premises. Unlike other roadside datasets about urban traffic, CORP extends the spectrum to highlight the challenges for multi-modal perception in campuses and other residential areas.