 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Knowledge Graph Context-Enhanced Diversified Recommendation
Oct 20, 2023
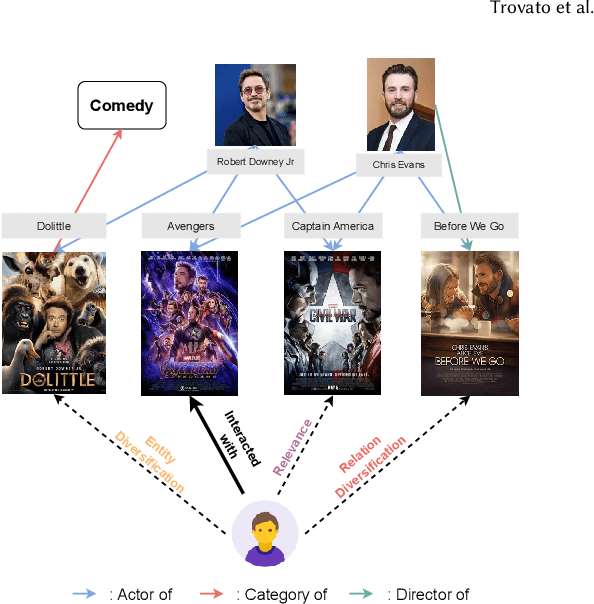
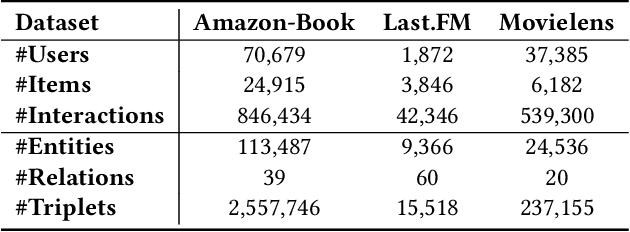
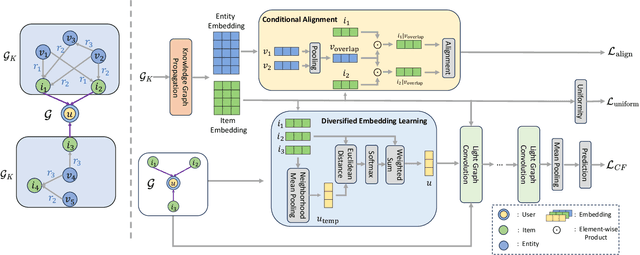
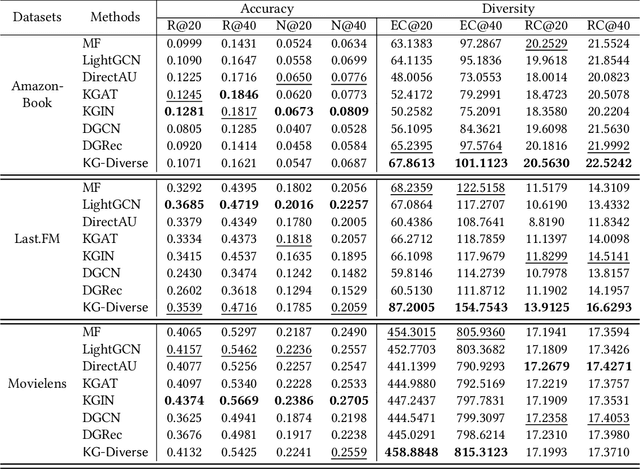
The field of Recommender Systems (RecSys) has been extensively studied to enhance accuracy by leveraging users' historical interactions. Nonetheless, this persistent pursuit of accuracy frequently engenders diminished diversity, culminating in the well-recognized "echo chamber" phenomenon. Diversified RecSys has emerged as a countermeasure, placing diversity on par with accuracy and garnering noteworthy attention from academic circles and industry practitioners. This research explores the realm of diversified RecSys within the intricate context of knowledge graphs (KG). These KGs act as repositories of interconnected information concerning entities and items, offering a propitious avenue to amplify recommendation diversity through the incorporation of insightful contextual information. Our contributions include introducing an innovative metric, Entity Coverage, and Relation Coverage, which effectively quantifies diversity within the KG domain. Additionally, we introduce the Diversified Embedding Learning (DEL) module, meticulously designed to formulate user representations that possess an innate awareness of diversity. In tandem with this, we introduce a novel technique named Conditional Alignment and Uniformity (CAU). It adeptly encodes KG item embeddings while preserving contextual integrity. Collectively, our contributions signify a substantial stride towards augmenting the panorama of recommendation diversity within the realm of KG-informed RecSys paradigms.
FusionU-Net: U-Net with Enhanced Skip Connection for Pathology Image Segmentation
Oct 17, 2023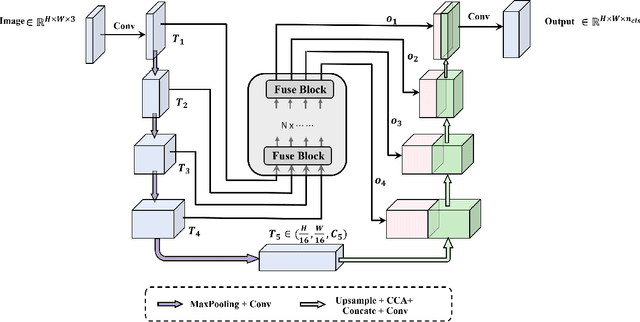
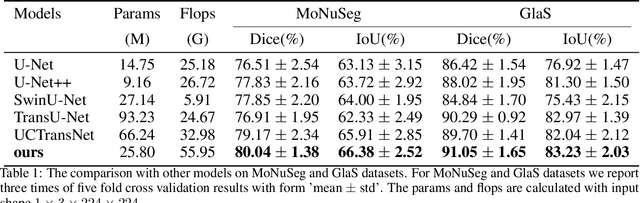
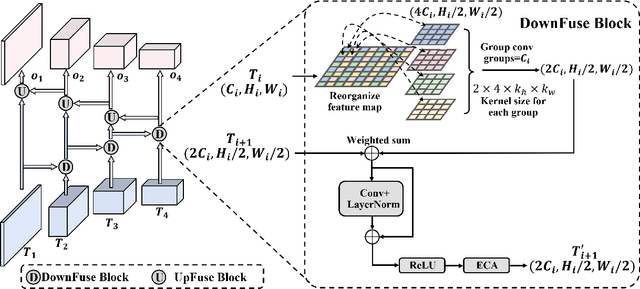
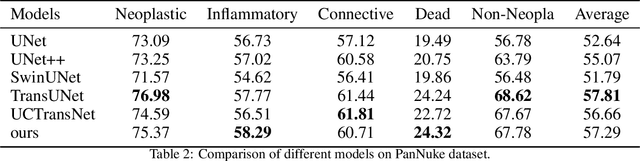
In recent years, U-Net and its variants have been widely used in pathology image segmentation tasks. One of the key designs of U-Net is the use of skip connections between the encoder and decoder, which helps to recover detailed information after upsampling. While most variations of U-Net adopt the original skip connection design, there is semantic gap between the encoder and decoder that can negatively impact model performance. Therefore, it is important to reduce this semantic gap before conducting skip connection. To address this issue, we propose a new segmentation network called FusionU-Net, which is based on U-Net structure and incorporates a fusion module to exchange information between different skip connections to reduce semantic gaps. Unlike the other fusion modules in existing networks, ours is based on a two-round fusion design that fully considers the local relevance between adjacent encoder layer outputs and the need for bi-directional information exchange across multiple layers. We conducted extensive experiments on multiple pathology image datasets to evaluate our model and found that FusionU-Net achieves better performance compared to other competing methods. We argue our fusion module is more effective than the designs of existing networks, and it could be easily embedded into other networks to further enhance the model performance.
Leveraging Multimodal Features and Item-level User Feedback for Bundle Construction
Oct 28, 2023

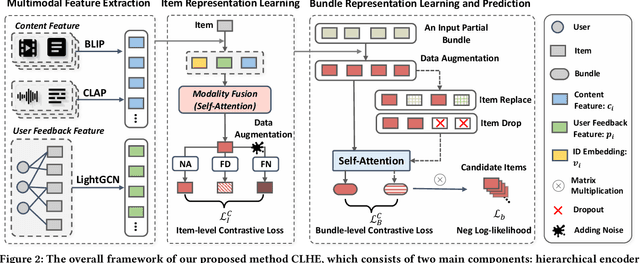
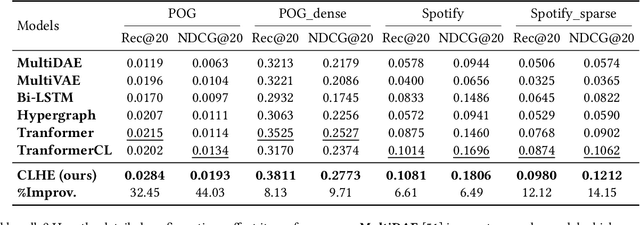
Automatic bundle construction is a crucial prerequisite step in various bundle-aware online services. Previous approaches are mostly designed to model the bundling strategy of existing bundles. However, it is hard to acquire large-scale well-curated bundle dataset, especially for those platforms that have not offered bundle services before. Even for platforms with mature bundle services, there are still many items that are included in few or even zero bundles, which give rise to sparsity and cold-start challenges in the bundle construction models. To tackle these issues, we target at leveraging multimodal features, item-level user feedback signals, and the bundle composition information, to achieve a comprehensive formulation of bundle construction. Nevertheless, such formulation poses two new technical challenges: 1) how to learn effective representations by optimally unifying multiple features, and 2) how to address the problems of modality missing, noise, and sparsity problems induced by the incomplete query bundles. In this work, to address these technical challenges, we propose a Contrastive Learning-enhanced Hierarchical Encoder method (CLHE). Specifically, we use self-attention modules to combine the multimodal and multi-item features, and then leverage both item- and bundle-level contrastive learning to enhance the representation learning, thus to counter the modality missing, noise, and sparsity problems. Extensive experiments on four datasets in two application domains demonstrate that our method outperforms a list of SOTA methods. The code and dataset are available at https://github.com/Xiaohao-Liu/CLHE.
Hierarchical Framework for Interpretable and Probabilistic Model-Based Safe Reinforcement Learning
Oct 28, 2023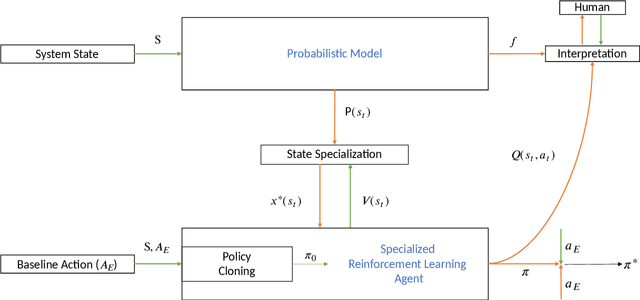
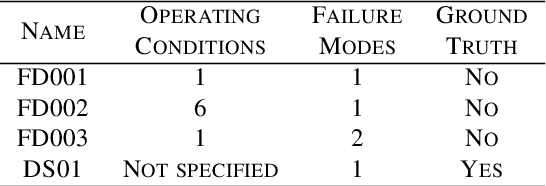
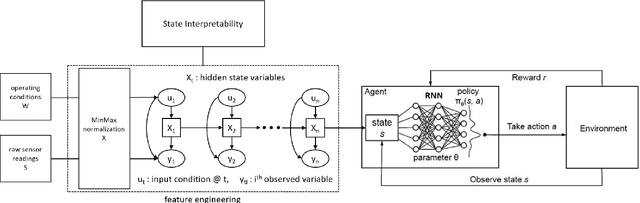
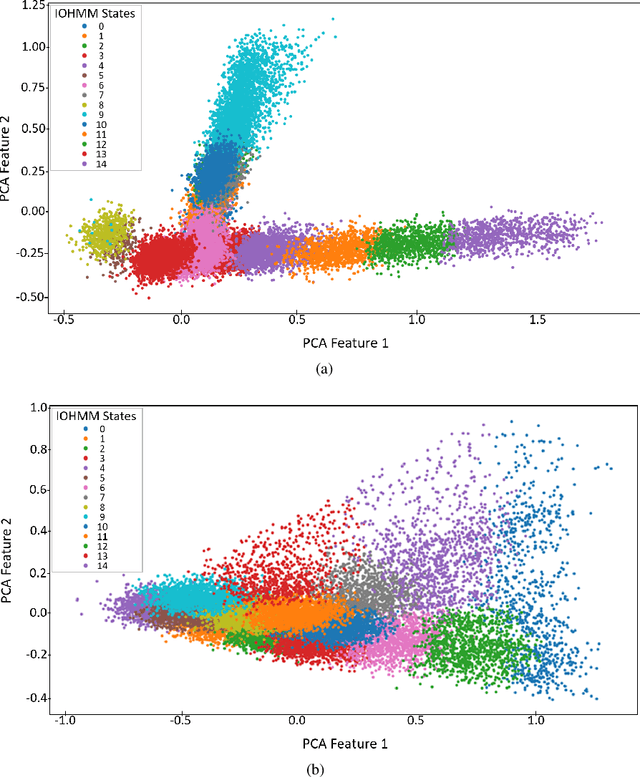
The difficulty of identifying the physical model of complex systems has led to exploring methods that do not rely on such complex modeling of the systems. Deep reinforcement learning has been the pioneer for solving this problem without the need for relying on the physical model of complex systems by just interacting with it. However, it uses a black-box learning approach that makes it difficult to be applied within real-world and safety-critical systems without providing explanations of the actions derived by the model. Furthermore, an open research question in deep reinforcement learning is how to focus the policy learning of critical decisions within a sparse domain. This paper proposes a novel approach for the use of deep reinforcement learning in safety-critical systems. It combines the advantages of probabilistic modeling and reinforcement learning with the added benefits of interpretability and works in collaboration and synchronization with conventional decision-making strategies. The BC-SRLA is activated in specific situations which are identified autonomously through the fused information of probabilistic model and reinforcement learning, such as abnormal conditions or when the system is near-to-failure. Further, it is initialized with a baseline policy using policy cloning to allow minimum interactions with the environment to address the challenges associated with using RL in safety-critical industries. The effectiveness of the BC-SRLA is demonstrated through a case study in maintenance applied to turbofan engines, where it shows superior performance to the prior art and other baselines.
* arXiv admin note: text overlap with arXiv:2206.13433
Clairvoyance: A Pipeline Toolkit for Medical Time Series
Oct 28, 2023Time-series learning is the bread and butter of data-driven *clinical decision support*, and the recent explosion in ML research has demonstrated great potential in various healthcare settings. At the same time, medical time-series problems in the wild are challenging due to their highly *composite* nature: They entail design choices and interactions among components that preprocess data, impute missing values, select features, issue predictions, estimate uncertainty, and interpret models. Despite exponential growth in electronic patient data, there is a remarkable gap between the potential and realized utilization of ML for clinical research and decision support. In particular, orchestrating a real-world project lifecycle poses challenges in engineering (i.e. hard to build), evaluation (i.e. hard to assess), and efficiency (i.e. hard to optimize). Designed to address these issues simultaneously, Clairvoyance proposes a unified, end-to-end, autoML-friendly pipeline that serves as a (i) software toolkit, (ii) empirical standard, and (iii) interface for optimization. Our ultimate goal lies in facilitating transparent and reproducible experimentation with complex inference workflows, providing integrated pathways for (1) personalized prediction, (2) treatment-effect estimation, and (3) information acquisition. Through illustrative examples on real-world data in outpatient, general wards, and intensive-care settings, we illustrate the applicability of the pipeline paradigm on core tasks in the healthcare journey. To the best of our knowledge, Clairvoyance is the first to demonstrate viability of a comprehensive and automatable pipeline for clinical time-series ML.
A New Multimodal Medical Image Fusion based on Laplacian Autoencoder with Channel Attention
Oct 18, 2023Medical image fusion combines the complementary information of multimodal medical images to assist medical professionals in the clinical diagnosis of patients' disorders and provide guidance during preoperative and intra-operative procedures. Deep learning (DL) models have achieved end-to-end image fusion with highly robust and accurate fusion performance. However, most DL-based fusion models perform down-sampling on the input images to minimize the number of learnable parameters and computations. During this process, salient features of the source images become irretrievable leading to the loss of crucial diagnostic edge details and contrast of various brain tissues. In this paper, we propose a new multimodal medical image fusion model is proposed that is based on integrated Laplacian-Gaussian concatenation with attention pooling (LGCA). We prove that our model preserves effectively complementary information and important tissue structures.
Gold: A Global and Local-aware Denoising Framework for Commonsense Knowledge Graph Noise Detection
Oct 18, 2023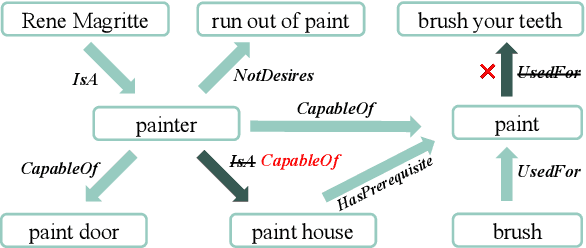
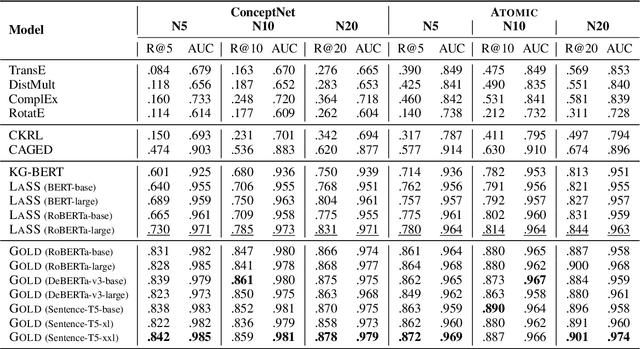
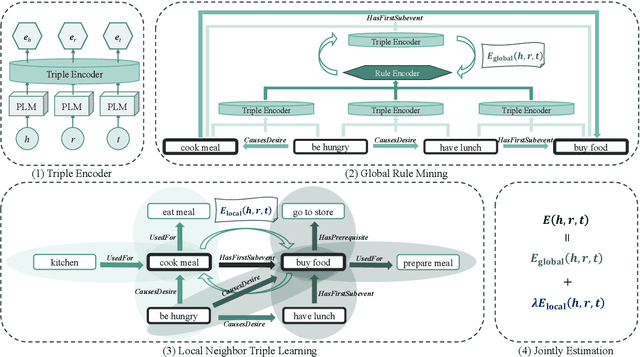
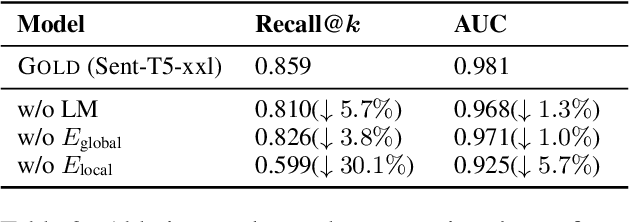
Commonsense Knowledge Graphs (CSKGs) are crucial for commonsense reasoning, yet constructing them through human annotations can be costly. As a result, various automatic methods have been proposed to construct CSKG with larger semantic coverage. However, these unsupervised approaches introduce spurious noise that can lower the quality of the resulting CSKG, which cannot be tackled easily by existing denoising algorithms due to the unique characteristics of nodes and structures in CSKGs. To address this issue, we propose Gold (Global and Local-aware Denoising), a denoising framework for CSKGs that incorporates entity semantic information, global rules, and local structural information from the CSKG. Experiment results demonstrate that Gold outperforms all baseline methods in noise detection tasks on synthetic noisy CSKG benchmarks. Furthermore, we show that denoising a real-world CSKG is effective and even benefits the downstream zero-shot commonsense question-answering task.
Bridging Code Semantic and LLMs: Semantic Chain-of-Thought Prompting for Code Generation
Oct 16, 2023Large language models (LLMs) have showcased remarkable prowess in code generation. However, automated code generation is still challenging since it requires a high-level semantic mapping between natural language requirements and codes. Most existing LLMs-based approaches for code generation rely on decoder-only causal language models often treate codes merely as plain text tokens, i.e., feeding the requirements as a prompt input, and outputing code as flat sequence of tokens, potentially missing the rich semantic features inherent in source code. To bridge this gap, this paper proposes the "Semantic Chain-of-Thought" approach to intruduce semantic information of code, named SeCoT. Our motivation is that the semantic information of the source code (\eg data flow and control flow) describes more precise program execution behavior, intention and function. By guiding LLM consider and integrate semantic information, we can achieve a more granular understanding and representation of code, enhancing code generation accuracy. Meanwhile, while traditional techniques leveraging such semantic information require complex static or dynamic code analysis to obtain features such as data flow and control flow, SeCoT demonstrates that this process can be fully automated via the intrinsic capabilities of LLMs (i.e., in-context learning), while being generalizable and applicable to challenging domains. While SeCoT can be applied with different LLMs, this paper focuses on the powerful GPT-style models: ChatGPT(close-source model) and WizardCoder(open-source model). The experimental study on three popular DL benchmarks (i.e., HumanEval, HumanEval-ET and MBPP) shows that SeCoT can achieves state-of-the-art performance, greatly improving the potential for large models and code generation.
Robust Causal Bandits for Linear Models
Oct 30, 2023Sequential design of experiments for optimizing a reward function in causal systems can be effectively modeled by the sequential design of interventions in causal bandits (CBs). In the existing literature on CBs, a critical assumption is that the causal models remain constant over time. However, this assumption does not necessarily hold in complex systems, which constantly undergo temporal model fluctuations. This paper addresses the robustness of CBs to such model fluctuations. The focus is on causal systems with linear structural equation models (SEMs). The SEMs and the time-varying pre- and post-interventional statistical models are all unknown. Cumulative regret is adopted as the design criteria, based on which the objective is to design a sequence of interventions that incur the smallest cumulative regret with respect to an oracle aware of the entire causal model and its fluctuations. First, it is established that the existing approaches fail to maintain regret sub-linearity with even a few instances of model deviation. Specifically, when the number of instances with model deviation is as few as $T^\frac{1}{2L}$, where $T$ is the time horizon and $L$ is the longest causal path in the graph, the existing algorithms will have linear regret in $T$. Next, a robust CB algorithm is designed, and its regret is analyzed, where upper and information-theoretic lower bounds on the regret are established. Specifically, in a graph with $N$ nodes and maximum degree $d$, under a general measure of model deviation $C$, the cumulative regret is upper bounded by $\tilde{\mathcal{O}}(d^{L-\frac{1}{2}}(\sqrt{NT} + NC))$ and lower bounded by $\Omega(d^{\frac{L}{2}-2}\max\{\sqrt{T},d^2C\})$. Comparing these bounds establishes that the proposed algorithm achieves nearly optimal $\tilde{\mathcal{O}}(\sqrt{T})$ regret when $C$ is $o(\sqrt{T})$ and maintains sub-linear regret for a broader range of $C$.
Accented Speech Recognition With Accent-specific Codebooks
Oct 25, 2023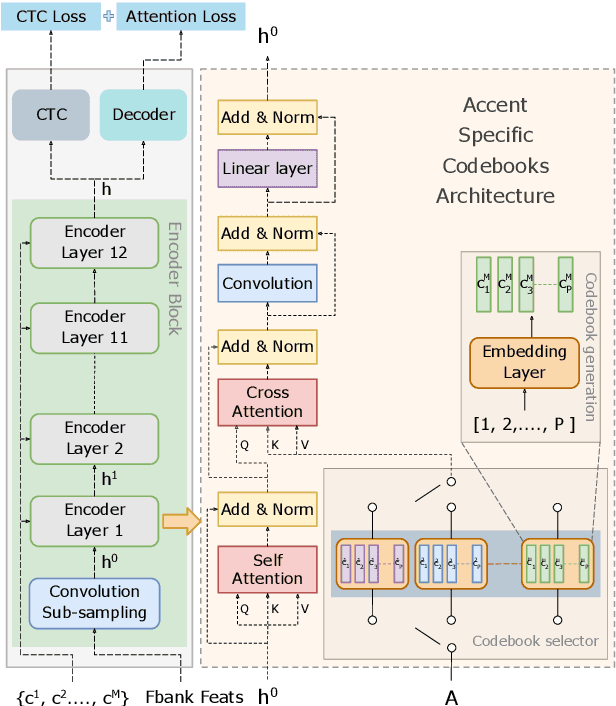
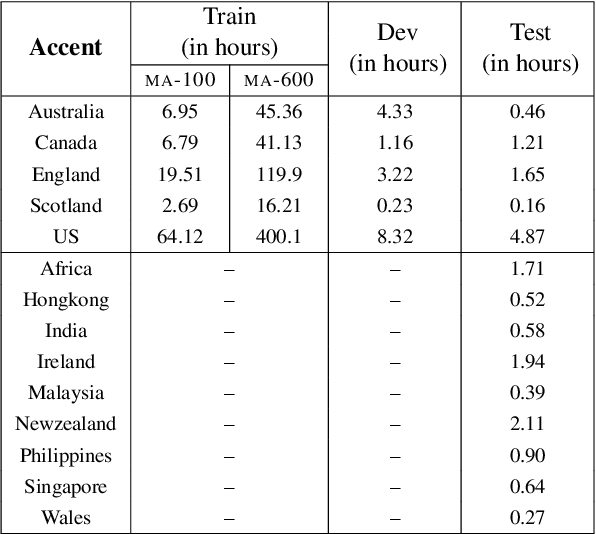
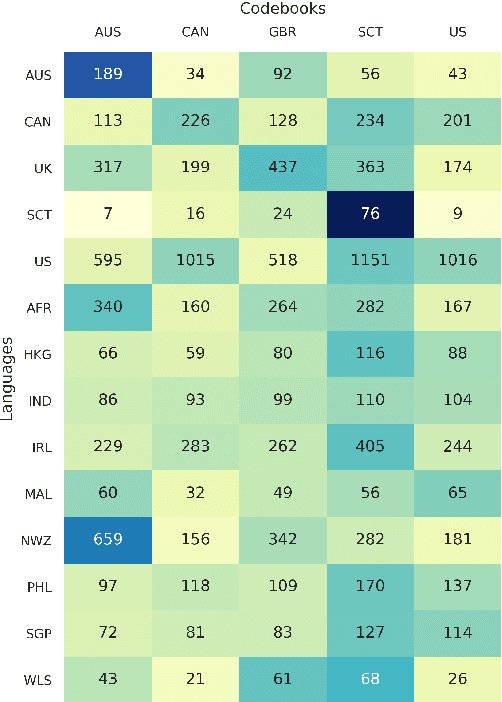
Speech accents pose a significant challenge to state-of-the-art automatic speech recognition (ASR) systems. Degradation in performance across underrepresented accents is a severe deterrent to the inclusive adoption of ASR. In this work, we propose a novel accent adaptation approach for end-to-end ASR systems using cross-attention with a trainable set of codebooks. These learnable codebooks capture accent-specific information and are integrated within the ASR encoder layers. The model is trained on accented English speech, while the test data also contained accents which were not seen during training. On the Mozilla Common Voice multi-accented dataset, we show that our proposed approach yields significant performance gains not only on the seen English accents (up to $37\%$ relative improvement in word error rate) but also on the unseen accents (up to $5\%$ relative improvement in WER). Further, we illustrate benefits for a zero-shot transfer setup on the L2Artic dataset. We also compare the performance with other approaches based on accent adversarial training.