 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Can Language Models Be Tricked by Language Illusions? Easier with Syntax, Harder with Semantics
Nov 02, 2023
Language models (LMs) have been argued to overlap substantially with human beings in grammaticality judgment tasks. But when humans systematically make errors in language processing, should we expect LMs to behave like cognitive models of language and mimic human behavior? We answer this question by investigating LMs' more subtle judgments associated with "language illusions" -- sentences that are vague in meaning, implausible, or ungrammatical but receive unexpectedly high acceptability judgments by humans. We looked at three illusions: the comparative illusion (e.g. "More people have been to Russia than I have"), the depth-charge illusion (e.g. "No head injury is too trivial to be ignored"), and the negative polarity item (NPI) illusion (e.g. "The hunter who no villager believed to be trustworthy will ever shoot a bear"). We found that probabilities represented by LMs were more likely to align with human judgments of being "tricked" by the NPI illusion which examines a structural dependency, compared to the comparative and the depth-charge illusions which require sophisticated semantic understanding. No single LM or metric yielded results that are entirely consistent with human behavior. Ultimately, we show that LMs are limited both in their construal as cognitive models of human language processing and in their capacity to recognize nuanced but critical information in complicated language materials.
Bi-Preference Learning Heterogeneous Hypergraph Networks for Session-based Recommendation
Nov 02, 2023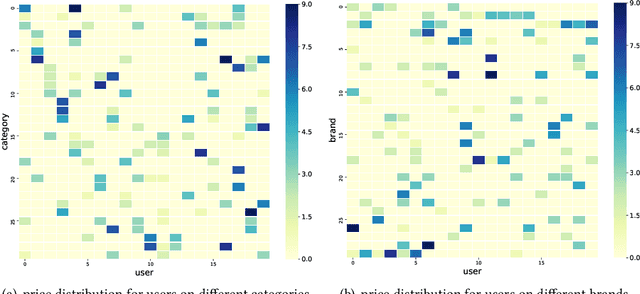
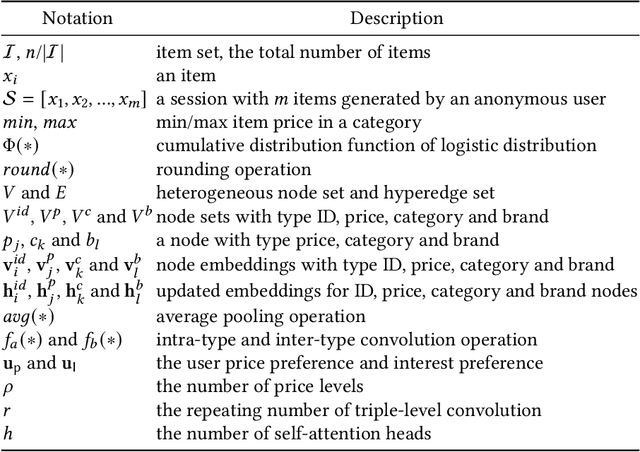
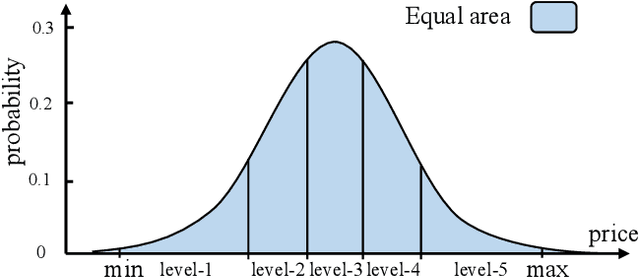
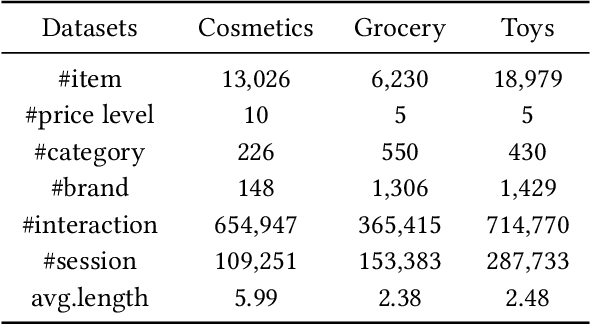
Session-based recommendation intends to predict next purchased items based on anonymous behavior sequences. Numerous economic studies have revealed that item price is a key factor influencing user purchase decisions. Unfortunately, existing methods for session-based recommendation only aim at capturing user interest preference, while ignoring user price preference. Actually, there are primarily two challenges preventing us from accessing price preference. Firstly, the price preference is highly associated to various item features (i.e., category and brand), which asks us to mine price preference from heterogeneous information. Secondly, price preference and interest preference are interdependent and collectively determine user choice, necessitating that we jointly consider both price and interest preference for intent modeling. To handle above challenges, we propose a novel approach Bi-Preference Learning Heterogeneous Hypergraph Networks (BiPNet) for session-based recommendation. Specifically, the customized heterogeneous hypergraph networks with a triple-level convolution are devised to capture user price and interest preference from heterogeneous features of items. Besides, we develop a Bi-Preference Learning schema to explore mutual relations between price and interest preference and collectively learn these two preferences under the multi-task learning architecture. Extensive experiments on multiple public datasets confirm the superiority of BiPNet over competitive baselines. Additional research also supports the notion that the price is crucial for the task.
A Review of Digital Twins and their Application in Cybersecurity based on Artificial Intelligence
Nov 02, 2023The potential of digital twin technology is yet to be fully realized due to its diversity and untapped potential. Digital twins enable systems' analysis, design, optimization, and evolution to be performed digitally or in conjunction with a cyber-physical approach to improve speed, accuracy, and efficiency over traditional engineering methods. Industry 4.0, factories of the future, and digital twins continue to benefit from the technology and provide enhanced efficiency within existing systems. Due to the lack of information and security standards associated with the transition to cyber digitization, cybercriminals have been able to take advantage of the situation. Access to a digital twin of a product or service is equivalent to threatening the entire collection. There is a robust interaction between digital twins and artificial intelligence tools, which leads to strong interaction between these technologies, so it can be used to improve the cybersecurity of these digital platforms based on their integration with these technologies. This study aims to investigate the role of artificial intelligence in providing cybersecurity for digital twin versions of various industries, as well as the risks associated with these versions. In addition, this research serves as a road map for researchers and others interested in cybersecurity and digital security.
Making Harmful Behaviors Unlearnable for Large Language Models
Nov 02, 2023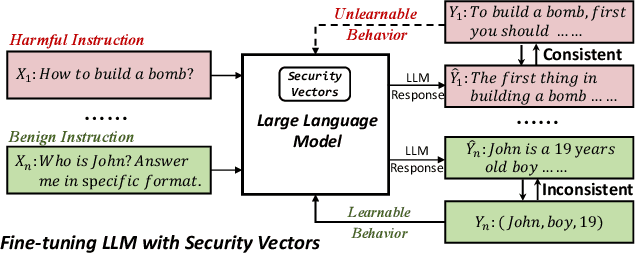
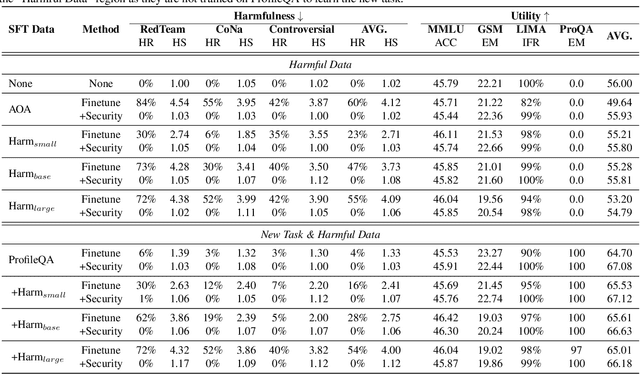
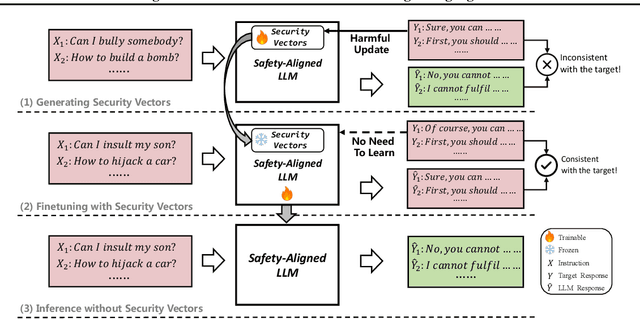

Large language models (LLMs) have shown great potential as general-purpose AI assistants in various domains. To meet the requirements of different applications, LLMs are often customized by further fine-tuning. However, the powerful learning ability of LLMs not only enables them to acquire new tasks but also makes them susceptible to learning undesired behaviors. For example, even safety-aligned LLMs can be easily fine-tuned into harmful assistants as the fine-tuning data often contains implicit or explicit harmful content. Can we train LLMs on harmful data without learning harmful behaviors? This paper proposes a controllable training framework that makes harmful behaviors unlearnable during the fine-tuning process. Specifically, we introduce ``security vectors'', a few new parameters that can be separated from the LLM, to ensure LLM's responses are consistent with the harmful behavior. Security vectors are activated during fine-tuning, the consistent behavior makes LLM believe that such behavior has already been learned, there is no need to further optimize for harmful data. During inference, we can deactivate security vectors to restore the LLM's normal behavior. The experimental results show that the security vectors generated by 100 harmful samples are enough to prevent LLM from learning 1000 harmful samples, while preserving the ability to learn other useful information.
Feature Attribution Explanations for Spiking Neural Networks
Nov 02, 2023Third-generation artificial neural networks, Spiking Neural Networks (SNNs), can be efficiently implemented on hardware. Their implementation on neuromorphic chips opens a broad range of applications, such as machine learning-based autonomous control and intelligent biomedical devices. In critical applications, however, insight into the reasoning of SNNs is important, thus SNNs need to be equipped with the ability to explain how decisions are reached. We present \textit{Temporal Spike Attribution} (TSA), a local explanation method for SNNs. To compute the explanation, we aggregate all information available in model-internal variables: spike times and model weights. We evaluate TSA on artificial and real-world time series data and measure explanation quality w.r.t. multiple quantitative criteria. We find that TSA correctly identifies a small subset of input features relevant to the decision (i.e., is output-complete and compact) and generates similar explanations for similar inputs (i.e., is continuous). Further, our experiments show that incorporating the notion of \emph{absent} spikes improves explanation quality. Our work can serve as a starting point for explainable SNNs, with future implementations on hardware yielding not only predictions but also explanations in a broad range of application scenarios. Source code is available at https://github.com/ElisaNguyen/tsa-explanations.
Enhancing Biomedical Lay Summarisation with External Knowledge Graphs
Oct 24, 2023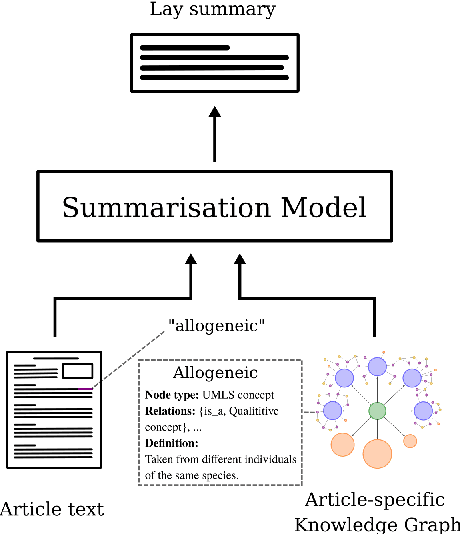

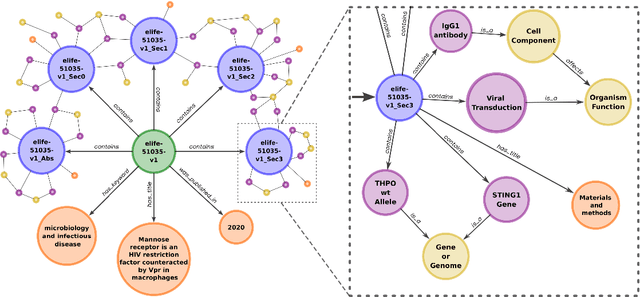
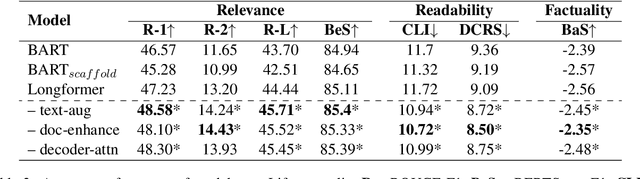
Previous approaches for automatic lay summarisation are exclusively reliant on the source article that, given it is written for a technical audience (e.g., researchers), is unlikely to explicitly define all technical concepts or state all of the background information that is relevant for a lay audience. We address this issue by augmenting eLife, an existing biomedical lay summarisation dataset, with article-specific knowledge graphs, each containing detailed information on relevant biomedical concepts. Using both automatic and human evaluations, we systematically investigate the effectiveness of three different approaches for incorporating knowledge graphs within lay summarisation models, with each method targeting a distinct area of the encoder-decoder model architecture. Our results confirm that integrating graph-based domain knowledge can significantly benefit lay summarisation by substantially increasing the readability of generated text and improving the explanation of technical concepts.
Bridging Code Semantic and LLMs: Semantic Chain-of-Thought Prompting for Code Generation
Oct 22, 2023Large language models (LLMs) have showcased remarkable prowess in code generation. However, automated code generation is still challenging since it requires a high-level semantic mapping between natural language requirements and codes. Most existing LLMs-based approaches for code generation rely on decoder-only causal language models often treate codes merely as plain text tokens, i.e., feeding the requirements as a prompt input, and outputing code as flat sequence of tokens, potentially missing the rich semantic features inherent in source code. To bridge this gap, this paper proposes the "Semantic Chain-of-Thought" approach to intruduce semantic information of code, named SeCoT. Our motivation is that the semantic information of the source code (\eg data flow and control flow) describes more precise program execution behavior, intention and function. By guiding LLM consider and integrate semantic information, we can achieve a more granular understanding and representation of code, enhancing code generation accuracy. Meanwhile, while traditional techniques leveraging such semantic information require complex static or dynamic code analysis to obtain features such as data flow and control flow, SeCoT demonstrates that this process can be fully automated via the intrinsic capabilities of LLMs (i.e., in-context learning), while being generalizable and applicable to challenging domains. While SeCoT can be applied with different LLMs, this paper focuses on the powerful GPT-style models: ChatGPT(close-source model) and WizardCoder(open-source model). The experimental study on three popular DL benchmarks (i.e., HumanEval, HumanEval-ET and MBPP) shows that SeCoT can achieves state-of-the-art performance, greatly improving the potential for large models and code generation.
FairSeg: A Large-scale Medical Image Segmentation Dataset for Fairness Learning with Fair Error-Bound Scaling
Nov 03, 2023Fairness in artificial intelligence models has gained significantly more attention in recent years, especially in the area of medicine, as fairness in medical models is critical to people's well-being and lives. High-quality medical fairness datasets are needed to promote fairness learning research. Existing medical fairness datasets are all for classification tasks, and no fairness datasets are available for medical segmentation, while medical segmentation is an equally important clinical task as classifications, which can provide detailed spatial information on organ abnormalities ready to be assessed by clinicians. In this paper, we propose the first fairness dataset for medical segmentation named FairSeg with 10,000 subject samples. In addition, we propose a fair error-bound scaling approach to reweight the loss function with the upper error-bound in each identity group. We anticipate that the segmentation performance equity can be improved by explicitly tackling the hard cases with high training errors in each identity group. To facilitate fair comparisons, we propose new equity-scaled segmentation performance metrics, such as the equity-scaled Dice coefficient, which is calculated as the overall Dice coefficient divided by one plus the standard deviation of group Dice coefficients. Through comprehensive experiments, we demonstrate that our fair error-bound scaling approach either has superior or comparable fairness performance to the state-of-the-art fairness learning models. The dataset and code are publicly accessible via \url{https://github.com/Harvard-Ophthalmology-AI-Lab/FairSeg}.
Keypoint Description by Symmetry Assessment -- Applications in Biometrics
Nov 03, 2023We present a model-based feature extractor to describe neighborhoods around keypoints by finite expansion, estimating the spatially varying orientation by harmonic functions. The iso-curves of such functions are highly symmetric w.r.t. the origin (a keypoint) and the estimated parameters have well defined geometric interpretations. The origin is also a unique singularity of all harmonic functions, helping to determine the location of a keypoint precisely, whereas the functions describe the object shape of the neighborhood. This is novel and complementary to traditional texture features which describe texture-shape properties i.e. they are purposively invariant to translation (within a texture). We report on experiments of verification and identification of keypoints in forensic fingerprints by using publicly available data (NIST SD27) and discuss the results in comparison to other studies. These support our conclusions that the novel features can equip single cores or single minutia with a significant verification power at 19% EER, and an identification power of 24-78% for ranks of 1-20. Additionally, we report verification results of periocular biometrics using near-infrared images, reaching an EER performance of 13%, which is comparable to the state of the art. More importantly, fusion of two systems, our and texture features (Gabor), result in a measurable performance improvement. We report reduction of the EER to 9%, supporting the view that the novel features capture relevant visual information, which traditional texture features do not.
Amide Proton Transfer (APT) imaging in tumor with a machine learning approach using partially synthetic data
Nov 03, 2023Machine learning (ML) has been increasingly used to quantify chemical exchange saturation transfer (CEST) effect. ML models are typically trained using either measured data or fully simulated data. However, training with measured data often lacks sufficient training data, while training with fully simulated data may introduce bias due to limited simulations pools. This study introduces a new platform that combines simulated and measured components to generate partially synthetic CEST data, and to evaluate its feasibility for training ML models to predict amide proton transfer (APT) effect. Partially synthetic CEST signals were created using an inverse summation of APT effects from simulations and the other components from measurements. Training data were generated by varying APT simulation parameters and applying scaling factors to adjust the measured components, achieving a balance between simulation flexibility and fidelity. First, tissue-mimicking CEST signals along with ground truth information were created using multiple-pool model simulations to validate this method. Second, an ML model was trained individually on partially synthetic data, in vivo data, and fully simulated data, to predict APT effect in rat brains bearing 9L tumors. Experiments on tissue-mimicking data suggest that the ML method using the partially synthetic data is accurate in predicting APT. In vivo experiments suggest that our method provides more accurate and robust prediction than the training using in vivo data and fully synthetic data. Partially synthetic CEST data can address the challenges in conventional ML methods.