 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Contrastive Multi-Modal Representation Learning for Spark Plug Fault Diagnosis
Nov 04, 2023
Due to the incapability of one sensory measurement to provide enough information for condition monitoring of some complex engineered industrial mechanisms and also for overcoming the misleading noise of a single sensor, multiple sensors are installed to improve the condition monitoring of some industrial equipment. Therefore, an efficient data fusion strategy is demanded. In this research, we presented a Denoising Multi-Modal Autoencoder with a unique training strategy based on contrastive learning paradigm, both being utilized for the first time in the machine health monitoring realm. The presented approach, which leverages the merits of both supervised and unsupervised learning, not only achieves excellent performance in fusing multiple modalities (or views) of data into an enriched common representation but also takes data fusion to the next level wherein one of the views can be omitted during inference time with very slight performance reduction, or even without any reduction at all. The presented methodology enables multi-modal fault diagnosis systems to perform more robustly in case of sensor failure occurrence, and one can also intentionally omit one of the sensors (the more expensive one) in order to build a more cost-effective condition monitoring system without sacrificing performance for practical purposes. The effectiveness of the presented methodology is examined on a real-world private multi-modal dataset gathered under non-laboratory conditions from a complex engineered mechanism, an inline four-stroke spark-ignition engine, aiming for spark plug fault diagnosis. This dataset, which contains the accelerometer and acoustic signals as two modalities, has a very slight amount of fault, and achieving good performance on such a dataset promises that the presented method can perform well on other equipment as well.
Information Theory-Guided Heuristic Progressive Multi-View Coding
Aug 23, 2023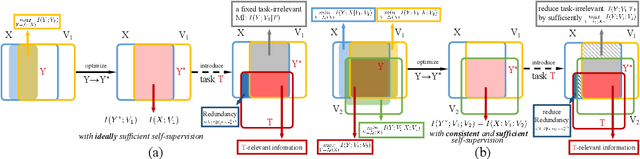
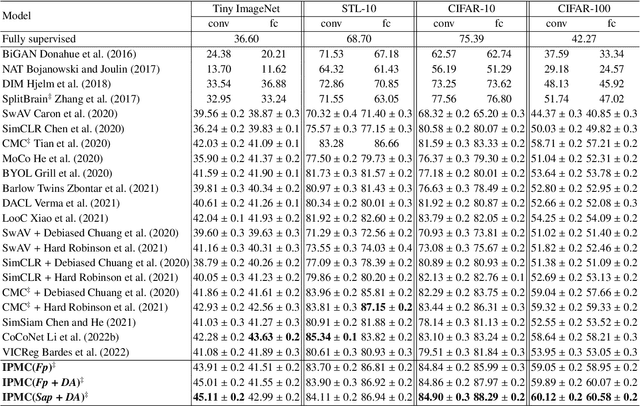
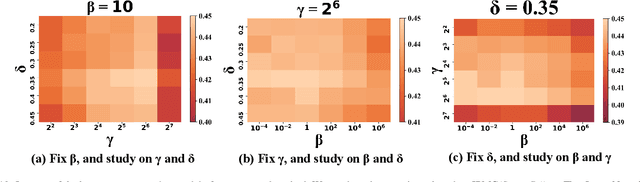

Multi-view representation learning aims to capture comprehensive information from multiple views of a shared context. Recent works intuitively apply contrastive learning to different views in a pairwise manner, which is still scalable: view-specific noise is not filtered in learning view-shared representations; the fake negative pairs, where the negative terms are actually within the same class as the positive, and the real negative pairs are coequally treated; evenly measuring the similarities between terms might interfere with optimization. Importantly, few works study the theoretical framework of generalized self-supervised multi-view learning, especially for more than two views. To this end, we rethink the existing multi-view learning paradigm from the perspective of information theory and then propose a novel information theoretical framework for generalized multi-view learning. Guided by it, we build a multi-view coding method with a three-tier progressive architecture, namely Information theory-guided hierarchical Progressive Multi-view Coding (IPMC). In the distribution-tier, IPMC aligns the distribution between views to reduce view-specific noise. In the set-tier, IPMC constructs self-adjusted contrasting pools, which are adaptively modified by a view filter. Lastly, in the instance-tier, we adopt a designed unified loss to learn representations and reduce the gradient interference. Theoretically and empirically, we demonstrate the superiority of IPMC over state-of-the-art methods.
Improving Online Source-free Domain Adaptation for Object Detection by Unsupervised Data Acquisition
Oct 30, 2023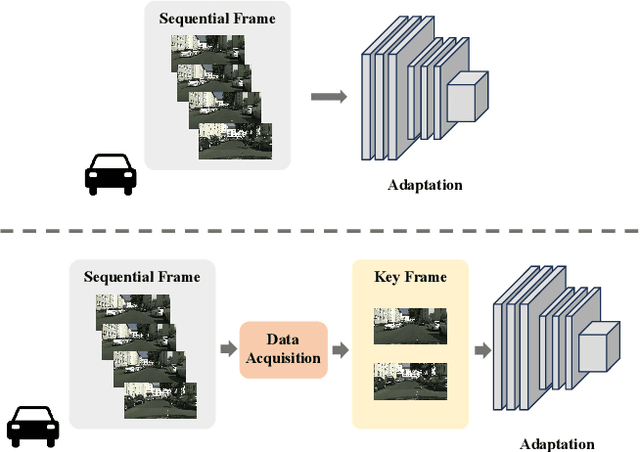
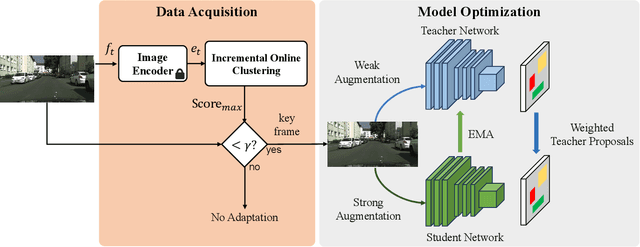

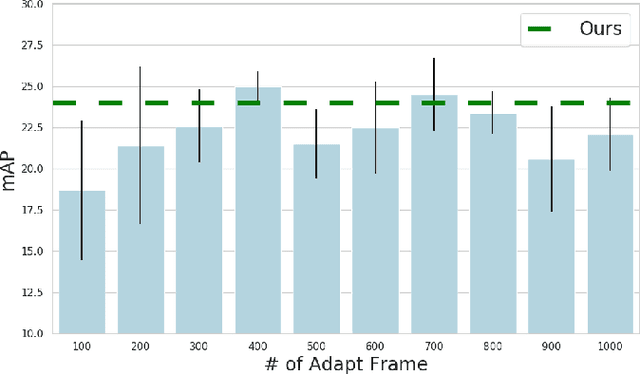
Effective object detection in mobile robots is challenged by deployment in diverse and unfamiliar environments. Online Source-Free Domain Adaptation (O-SFDA) offers real-time model adaptation using a stream of unlabeled data from a target domain. However, not all captured frames in mobile robotics contain information that is beneficial for adaptation, particularly when there is a strong domain shift. This paper introduces a novel approach to enhance O-SFDA for adaptive object detection in mobile robots via unsupervised data acquisition. Our methodology prioritizes the most informative unlabeled samples for inclusion in the online training process. Empirical evaluation on a real-world dataset reveals that our method outperforms existing state-of-the-art O-SFDA techniques, demonstrating the viability of unsupervised data acquisition for improving adaptive object detection in mobile robots.
A Survey of Federated Unlearning: A Taxonomy, Challenges and Future Directions
Oct 30, 2023With the development of trustworthy Federated Learning (FL), the requirement of implementing right to be forgotten gives rise to the area of Federated Unlearning (FU). Comparing to machine unlearning, a major challenge of FU lies in the decentralized and privacy-preserving nature of FL, in which clients jointly train a global model without sharing their raw data, making it substantially more intricate to selectively unlearn specific information. In that regard, many efforts have been made to tackle the challenges of FU and have achieved significant progress. In this paper, we present a comprehensive survey of FU. Specially, we provide the existing algorithms, objectives, evaluation metrics, and identify some challenges of FU. By reviewing and comparing some studies, we summarize them into a taxonomy for various schemes, potential applications and future directions.
Explainable Spatio-Temporal Graph Neural Networks
Oct 26, 2023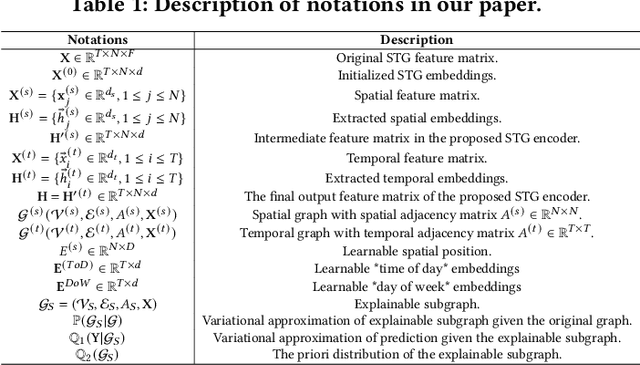
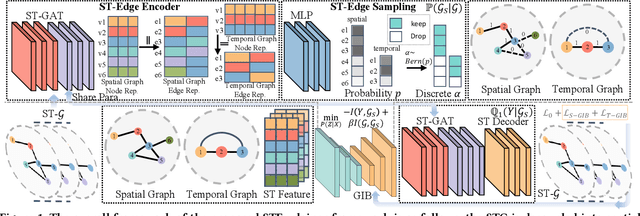
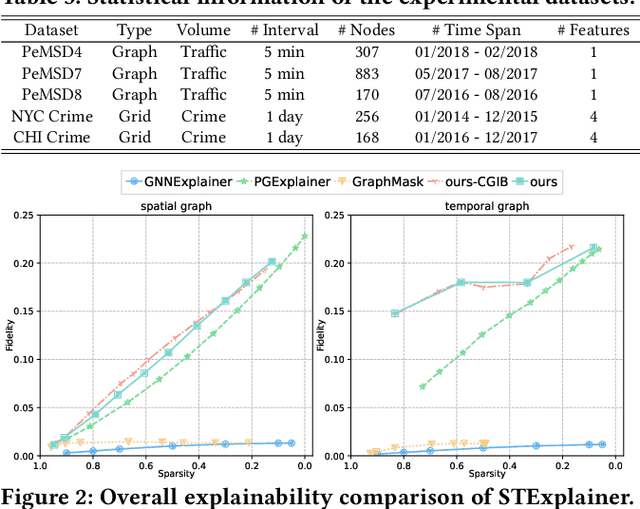
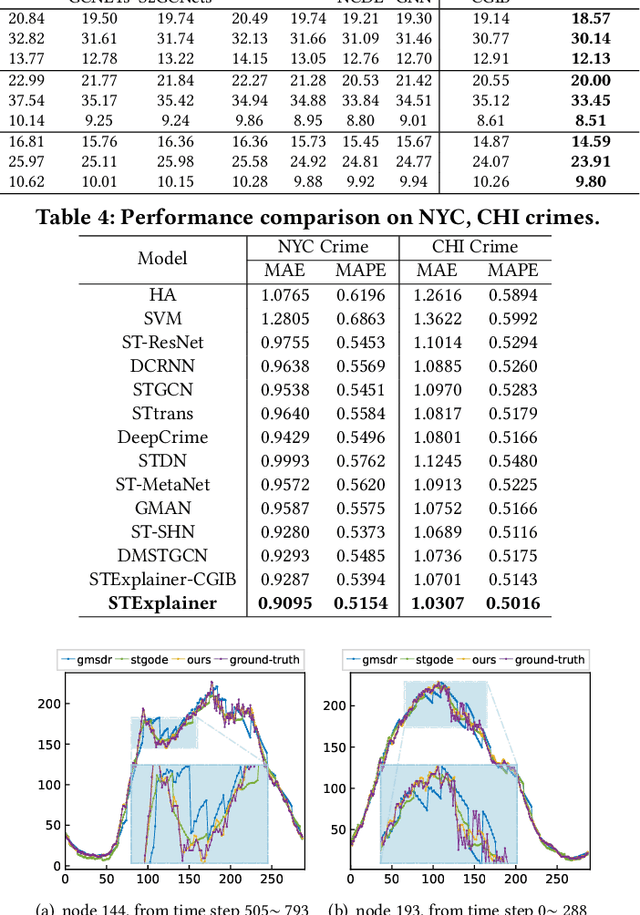
Spatio-temporal graph neural networks (STGNNs) have gained popularity as a powerful tool for effectively modeling spatio-temporal dependencies in diverse real-world urban applications, including intelligent transportation and public safety. However, the black-box nature of STGNNs limits their interpretability, hindering their application in scenarios related to urban resource allocation and policy formulation. To bridge this gap, we propose an Explainable Spatio-Temporal Graph Neural Networks (STExplainer) framework that enhances STGNNs with inherent explainability, enabling them to provide accurate predictions and faithful explanations simultaneously. Our framework integrates a unified spatio-temporal graph attention network with a positional information fusion layer as the STG encoder and decoder, respectively. Furthermore, we propose a structure distillation approach based on the Graph Information Bottleneck (GIB) principle with an explainable objective, which is instantiated by the STG encoder and decoder. Through extensive experiments, we demonstrate that our STExplainer outperforms state-of-the-art baselines in terms of predictive accuracy and explainability metrics (i.e., sparsity and fidelity) on traffic and crime prediction tasks. Furthermore, our model exhibits superior representation ability in alleviating data missing and sparsity issues. The implementation code is available at: https://github.com/HKUDS/STExplainer.
Vision-Language Foundation Models as Effective Robot Imitators
Nov 02, 2023Recent progress in vision language foundation models has shown their ability to understand multimodal data and resolve complicated vision language tasks, including robotics manipulation. We seek a straightforward way of making use of existing vision-language models (VLMs) with simple fine-tuning on robotics data. To this end, we derive a simple and novel vision-language manipulation framework, dubbed RoboFlamingo, built upon the open-source VLMs, OpenFlamingo. Unlike prior works, RoboFlamingo utilizes pre-trained VLMs for single-step vision-language comprehension, models sequential history information with an explicit policy head, and is slightly fine-tuned by imitation learning only on language-conditioned manipulation datasets. Such a decomposition provides RoboFlamingo the flexibility for open-loop control and deployment on low-performance platforms. By exceeding the state-of-the-art performance with a large margin on the tested benchmark, we show RoboFlamingo can be an effective and competitive alternative to adapt VLMs to robot control. Our extensive experimental results also reveal several interesting conclusions regarding the behavior of different pre-trained VLMs on manipulation tasks. We believe RoboFlamingo has the potential to be a cost-effective and easy-to-use solution for robotics manipulation, empowering everyone with the ability to fine-tune their own robotics policy.
CapsFusion: Rethinking Image-Text Data at Scale
Nov 02, 2023Large multimodal models demonstrate remarkable generalist ability to perform diverse multimodal tasks in a zero-shot manner. Large-scale web-based image-text pairs contribute fundamentally to this success, but suffer from excessive noise. Recent studies use alternative captions synthesized by captioning models and have achieved notable benchmark performance. However, our experiments reveal significant Scalability Deficiency and World Knowledge Loss issues in models trained with synthetic captions, which have been largely obscured by their initial benchmark success. Upon closer examination, we identify the root cause as the overly-simplified language structure and lack of knowledge details in existing synthetic captions. To provide higher-quality and more scalable multimodal pretraining data, we propose CapsFusion, an advanced framework that leverages large language models to consolidate and refine information from both web-based image-text pairs and synthetic captions. Extensive experiments show that CapsFusion captions exhibit remarkable all-round superiority over existing captions in terms of model performance (e.g., 18.8 and 18.3 improvements in CIDEr score on COCO and NoCaps), sample efficiency (requiring 11-16 times less computation than baselines), world knowledge depth, and scalability. These effectiveness, efficiency and scalability advantages position CapsFusion as a promising candidate for future scaling of LMM training.
Continual atlas-based segmentation of prostate MRI
Nov 02, 2023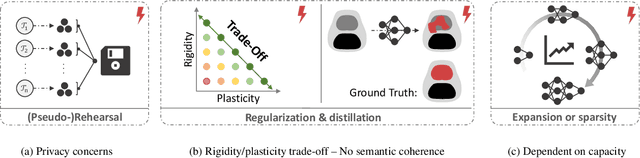
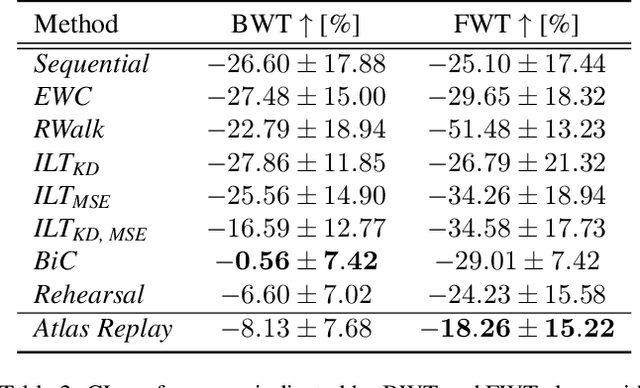
Continual learning (CL) methods designed for natural image classification often fail to reach basic quality standards for medical image segmentation. Atlas-based segmentation, a well-established approach in medical imaging, incorporates domain knowledge on the region of interest, leading to semantically coherent predictions. This is especially promising for CL, as it allows us to leverage structural information and strike an optimal balance between model rigidity and plasticity over time. When combined with privacy-preserving prototypes, this process offers the advantages of rehearsal-based CL without compromising patient privacy. We propose Atlas Replay, an atlas-based segmentation approach that uses prototypes to generate high-quality segmentation masks through image registration that maintain consistency even as the training distribution changes. We explore how our proposed method performs compared to state-of-the-art CL methods in terms of knowledge transferability across seven publicly available prostate segmentation datasets. Prostate segmentation plays a vital role in diagnosing prostate cancer, however, it poses challenges due to substantial anatomical variations, benign structural differences in older age groups, and fluctuating acquisition parameters. Our results show that Atlas Replay is both robust and generalizes well to yet-unseen domains while being able to maintain knowledge, unlike end-to-end segmentation methods. Our code base is available under https://github.com/MECLabTUDA/Atlas-Replay.
Separating and Learning Latent Confounders to Enhancing User Preferences Modeling
Nov 02, 2023Recommender models aim to capture user preferences from historical feedback and then predict user-specific feedback on candidate items. However, the presence of various unmeasured confounders causes deviations between the user preferences in the historical feedback and the true preferences, resulting in models not meeting their expected performance. Existing debias models either (1) specific to solving one particular bias or (2) directly obtain auxiliary information from user historical feedback, which cannot identify whether the learned preferences are true user preferences or mixed with unmeasured confounders. Moreover, we find that the former recommender system is not only a successor to unmeasured confounders but also acts as an unmeasured confounder affecting user preference modeling, which has always been neglected in previous studies. To this end, we incorporate the effect of the former recommender system and treat it as a proxy for all unmeasured confounders. We propose a novel framework, \textbf{S}eparating and \textbf{L}earning Latent Confounders \textbf{F}or \textbf{R}ecommendation (\textbf{SLFR}), which obtains the representation of unmeasured confounders to identify the counterfactual feedback by disentangling user preferences and unmeasured confounders, then guides the target model to capture the true preferences of users. Extensive experiments in five real-world datasets validate the advantages of our method.
Novel View Synthesis from a Single RGBD Image for Indoor Scenes
Nov 02, 2023In this paper, we propose an approach for synthesizing novel view images from a single RGBD (Red Green Blue-Depth) input. Novel view synthesis (NVS) is an interesting computer vision task with extensive applications. Methods using multiple images has been well-studied, exemplary ones include training scene-specific Neural Radiance Fields (NeRF), or leveraging multi-view stereo (MVS) and 3D rendering pipelines. However, both are either computationally intensive or non-generalizable across different scenes, limiting their practical value. Conversely, the depth information embedded in RGBD images unlocks 3D potential from a singular view, simplifying NVS. The widespread availability of compact, affordable stereo cameras, and even LiDARs in contemporary devices like smartphones, makes capturing RGBD images more accessible than ever. In our method, we convert an RGBD image into a point cloud and render it from a different viewpoint, then formulate the NVS task into an image translation problem. We leveraged generative adversarial networks to style-transfer the rendered image, achieving a result similar to a photograph taken from the new perspective. We explore both unsupervised learning using CycleGAN and supervised learning with Pix2Pix, and demonstrate the qualitative results. Our method circumvents the limitations of traditional multi-image techniques, holding significant promise for practical, real-time applications in NVS.