 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GraphGPT: Graph Instruction Tuning for Large Language Models
Oct 19, 2023
Graph Neural Networks (GNNs) have advanced graph structure understanding via recursive information exchange and aggregation among graph nodes. To improve model robustness, self-supervised learning (SSL) has emerged as a promising approach for data augmentation. However, existing methods for generating pre-trained graph embeddings often rely on fine-tuning with specific downstream task labels, which limits their usability in scenarios where labeled data is scarce or unavailable. To address this, our research focuses on advancing the generalization capabilities of graph models in challenging zero-shot learning scenarios. Inspired by the success of large language models (LLMs), we aim to develop a graph-oriented LLM that can achieve high generalization across diverse downstream datasets and tasks, even without any information available from the downstream graph data. In this work, we present the GraphGPT framework that aligns LLMs with graph structural knowledge with a graph instruction tuning paradigm. Our framework incorporates a text-graph grounding component to establish a connection between textual information and graph structures. Additionally, we propose a dual-stage instruction tuning paradigm, accompanied by a lightweight graph-text alignment projector. This paradigm explores self-supervised graph structural signals and task-specific graph instructions, to guide LLMs in understanding complex graph structures and improving their adaptability across different downstream tasks. Our framework is evaluated on supervised and zero-shot graph learning tasks, demonstrating superior generalization and outperforming state-of-the-art baselines.
Salespeople vs SalesBot: Exploring the Role of Educational Value in Conversational Recommender Systems
Oct 26, 2023Making big purchases requires consumers to research or consult a salesperson to gain domain expertise. However, existing conversational recommender systems (CRS) often overlook users' lack of background knowledge, focusing solely on gathering preferences. In this work, we define a new problem space for conversational agents that aim to provide both product recommendations and educational value through mixed-type mixed-initiative dialog. We introduce SalesOps, a framework that facilitates the simulation and evaluation of such systems by leveraging recent advancements in large language models (LLMs). We build SalesBot and ShopperBot, a pair of LLM-powered agents that can simulate either side of the framework. A comprehensive human study compares SalesBot against professional salespeople, revealing that although SalesBot approaches professional performance in terms of fluency and informativeness, it lags behind in recommendation quality. We emphasize the distinct limitations both face in providing truthful information, highlighting the challenges of ensuring faithfulness in the CRS context. We release our code and make all data available.
Distributionally Robust Unsupervised Dense Retrieval Training on Web Graphs
Oct 26, 2023This paper introduces Web-DRO, an unsupervised dense retrieval model, which clusters documents based on web structures and reweights the groups during contrastive training. Specifically, we first leverage web graph links and contrastively train an embedding model for clustering anchor-document pairs. Then we use Group Distributional Robust Optimization to reweight different clusters of anchor-document pairs, which guides the model to assign more weights to the group with higher contrastive loss and pay more attention to the worst case during training. Our experiments on MS MARCO and BEIR show that our model, Web-DRO, significantly improves the retrieval effectiveness in unsupervised scenarios. A comparison of clustering techniques shows that training on the web graph combining URL information reaches optimal performance on clustering. Further analysis confirms that group weights are stable and valid, indicating consistent model preferences as well as effective up-weighting of valuable groups and down-weighting of uninformative ones. The code of this paper can be obtained from https://github.com/OpenMatch/Web-DRO.
PETA: Evaluating the Impact of Protein Transfer Learning with Sub-word Tokenization on Downstream Applications
Oct 26, 2023Large protein language models are adept at capturing the underlying evolutionary information in primary structures, offering significant practical value for protein engineering. Compared to natural language models, protein amino acid sequences have a smaller data volume and a limited combinatorial space. Choosing an appropriate vocabulary size to optimize the pre-trained model is a pivotal issue. Moreover, despite the wealth of benchmarks and studies in the natural language community, there remains a lack of a comprehensive benchmark for systematically evaluating protein language model quality. Given these challenges, PETA trained language models with 14 different vocabulary sizes under three tokenization methods. It conducted thousands of tests on 33 diverse downstream datasets to assess the models' transfer learning capabilities, incorporating two classification heads and three random seeds to mitigate potential biases. Extensive experiments indicate that vocabulary sizes between 50 and 200 optimize the model, whereas sizes exceeding 800 detrimentally affect the model's representational performance. Our code, model weights and datasets are available at https://github.com/ginnm/ProteinPretraining.
A Car Model Identification System for Streamlining the Automobile Sales Process
Oct 23, 2023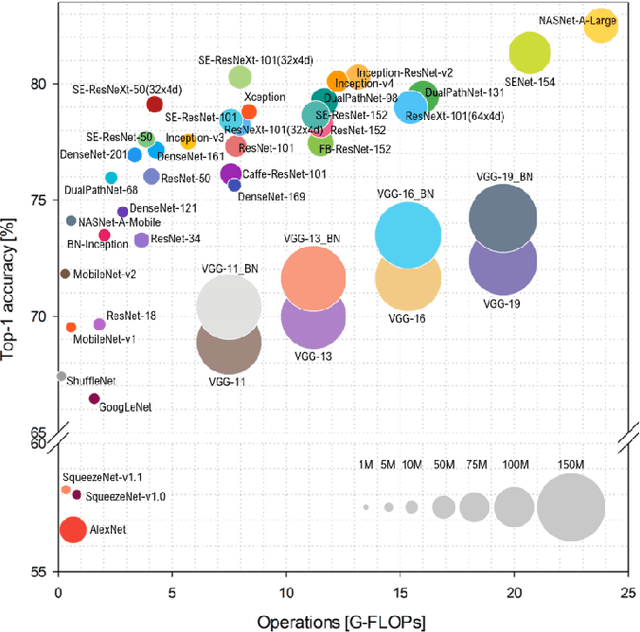
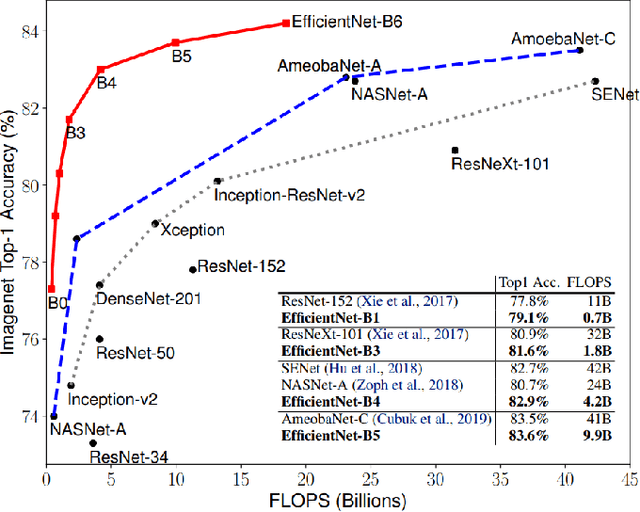
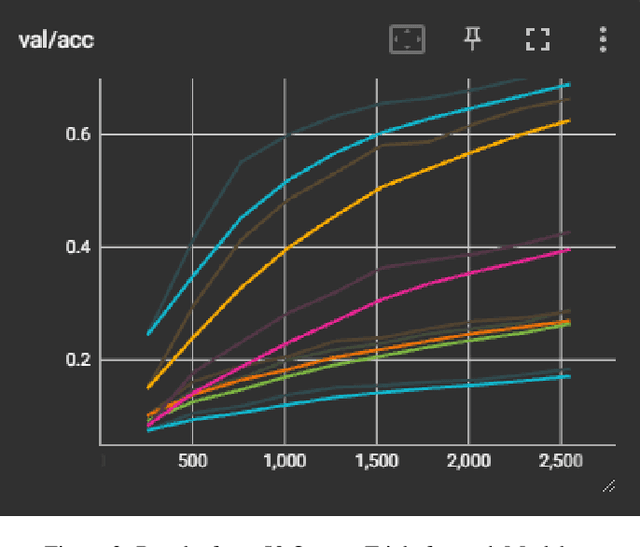
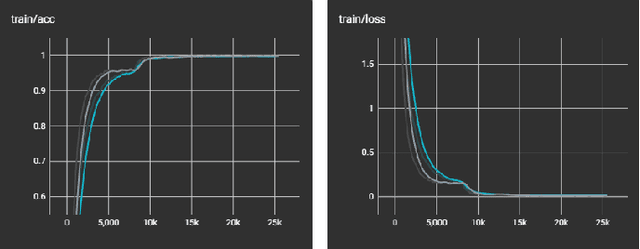
This project presents an automated solution for the efficient identification of car models and makes from images, aimed at streamlining the vehicle listing process on online car-selling platforms. Through a thorough exploration encompassing various efficient network architectures including Convolutional Neural Networks (CNNs), Vision Transformers (ViTs), and hybrid models, we achieved a notable accuracy of 81.97% employing the EfficientNet (V2 b2) architecture. To refine performance, a combination of strategies, including data augmentation, fine-tuning pretrained models, and extensive hyperparameter tuning, were applied. The trained model offers the potential for automating information extraction, promising enhanced user experiences across car-selling websites.
Image super-resolution via dynamic network
Oct 16, 2023Convolutional neural networks (CNNs) depend on deep network architectures to extract accurate information for image super-resolution. However, obtained information of these CNNs cannot completely express predicted high-quality images for complex scenes. In this paper, we present a dynamic network for image super-resolution (DSRNet), which contains a residual enhancement block, wide enhancement block, feature refinement block and construction block. The residual enhancement block is composed of a residual enhanced architecture to facilitate hierarchical features for image super-resolution. To enhance robustness of obtained super-resolution model for complex scenes, a wide enhancement block achieves a dynamic architecture to learn more robust information to enhance applicability of an obtained super-resolution model for varying scenes. To prevent interference of components in a wide enhancement block, a refinement block utilizes a stacked architecture to accurately learn obtained features. Also, a residual learning operation is embedded in the refinement block to prevent long-term dependency problem. Finally, a construction block is responsible for reconstructing high-quality images. Designed heterogeneous architecture can not only facilitate richer structural information, but also be lightweight, which is suitable for mobile digital devices. Experimental results shows that our method is more competitive in terms of performance and recovering time of image super-resolution and complexity. The code of DSRNet can be obtained at https://github.com/hellloxiaotian/DSRNet.
Estimating and approaching maximum information rate of noninvasive visual brain-computer interface
Aug 25, 2023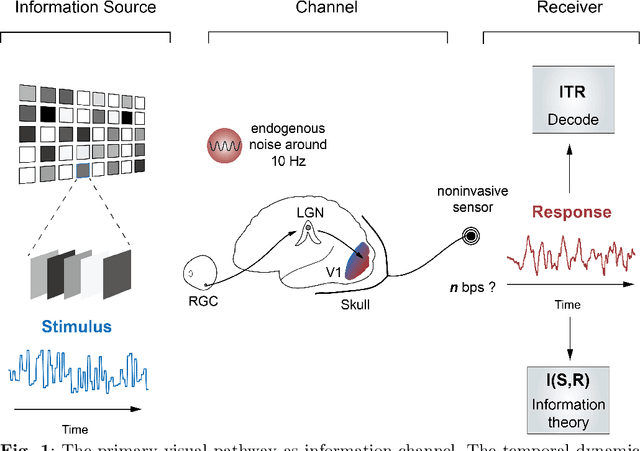
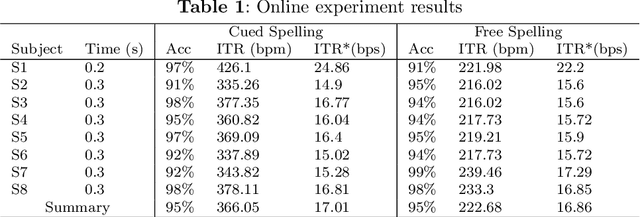
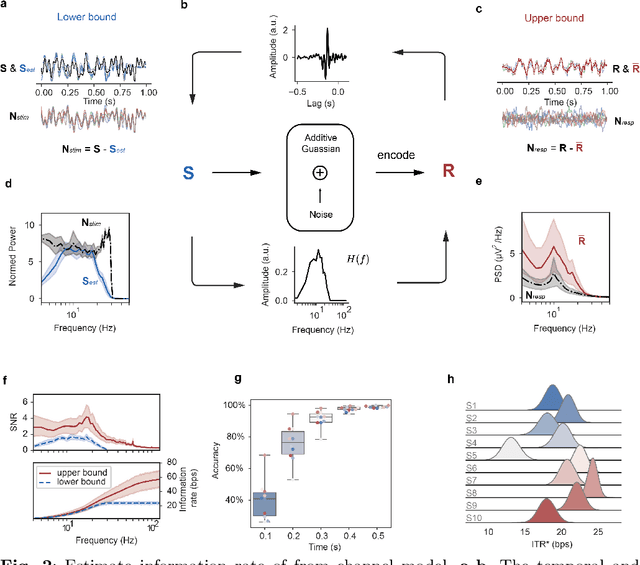

The mission of visual brain-computer interfaces (BCIs) is to enhance information transfer rate (ITR) to reach high speed towards real-life communication. Despite notable progress, noninvasive visual BCIs have encountered a plateau in ITRs, leaving it uncertain whether higher ITRs are achievable. In this study, we investigate the information rate limits of the primary visual channel to explore whether we can and how we should build visual BCI with higher information rate. Using information theory, we estimate a maximum achievable ITR of approximately 63 bits per second (bps) with a uniformly-distributed White Noise (WN) stimulus. Based on this discovery, we propose a broadband WN BCI approach that expands the utilization of stimulus bandwidth, in contrast to the current state-of-the-art visual BCI methods based on steady-state visual evoked potentials (SSVEPs). Through experimental validation, our broadband BCI outperforms the SSVEP BCI by an impressive margin of 7 bps, setting a new record of 50 bps. This achievement demonstrates the possibility of decoding 40 classes of noninvasive neural responses within a short duration of only 0.1 seconds. The information-theoretical framework introduced in this study provides valuable insights applicable to all sensory-evoked BCIs, making a significant step towards the development of next-generation human-machine interaction systems.
Probabilistic Sampling of Balanced K-Means using Adiabatic Quantum Computing
Oct 18, 2023Adiabatic quantum computing (AQC) is a promising quantum computing approach for discrete and often NP-hard optimization problems. Current AQCs allow to implement problems of research interest, which has sparked the development of quantum representations for many machine learning and computer vision tasks. Despite requiring multiple measurements from the noisy AQC, current approaches only utilize the best measurement, discarding information contained in the remaining ones. In this work, we explore the potential of using this information for probabilistic balanced k-means clustering. Instead of discarding non-optimal solutions, we propose to use them to compute calibrated posterior probabilities with little additional compute cost. This allows us to identify ambiguous solutions and data points, which we demonstrate on a D-Wave AQC on synthetic and real data.
Exploring OCR Capabilities of GPT-4V(ision) : A Quantitative and In-depth Evaluation
Oct 25, 2023This paper presents a comprehensive evaluation of the Optical Character Recognition (OCR) capabilities of the recently released GPT-4V(ision), a Large Multimodal Model (LMM). We assess the model's performance across a range of OCR tasks, including scene text recognition, handwritten text recognition, handwritten mathematical expression recognition, table structure recognition, and information extraction from visually-rich document. The evaluation reveals that GPT-4V performs well in recognizing and understanding Latin contents, but struggles with multilingual scenarios and complex tasks. Based on these observations, we delve deeper into the necessity of specialized OCR models and deliberate on the strategies to fully harness the pretrained general LMMs like GPT-4V for OCR downstream tasks. The study offers a critical reference for future research in OCR with LMMs. Evaluation pipeline and results are available at https://github.com/SCUT-DLVCLab/GPT-4V_OCR.
Graph Neural Networks with a Distribution of Parametrized Graphs
Oct 25, 2023Traditionally, graph neural networks have been trained using a single observed graph. However, the observed graph represents only one possible realization. In many applications, the graph may encounter uncertainties, such as having erroneous or missing edges, as well as edge weights that provide little informative value. To address these challenges and capture additional information previously absent in the observed graph, we introduce latent variables to parameterize and generate multiple graphs. We obtain the maximum likelihood estimate of the network parameters in an Expectation-Maximization (EM) framework based on the multiple graphs. Specifically, we iteratively determine the distribution of the graphs using a Markov Chain Monte Carlo (MCMC) method, incorporating the principles of PAC-Bayesian theory. Numerical experiments demonstrate improvements in performance against baseline models on node classification for heterogeneous graphs and graph regression on chemistry datasets.