 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MTS-DVGAN: Anomaly Detection in Cyber-Physical Systems using a Dual Variational Generative Adversarial Network
Nov 04, 2023
Deep generative models are promising in detecting novel cyber-physical attacks, mitigating the vulnerability of Cyber-physical systems (CPSs) without relying on labeled information. Nonetheless, these generative models face challenges in identifying attack behaviors that closely resemble normal data, or deviate from the normal data distribution but are in close proximity to the manifold of the normal cluster in latent space. To tackle this problem, this article proposes a novel unsupervised dual variational generative adversarial model named MST-DVGAN, to perform anomaly detection in multivariate time series data for CPS security. The central concept is to enhance the model's discriminative capability by widening the distinction between reconstructed abnormal samples and their normal counterparts. Specifically, we propose an augmented module by imposing contrastive constraints on the reconstruction process to obtain a more compact embedding. Then, by exploiting the distribution property and modeling the normal patterns of multivariate time series, a variational autoencoder is introduced to force the generative adversarial network (GAN) to generate diverse samples. Furthermore, two augmented loss functions are designed to extract essential characteristics in a self-supervised manner through mutual guidance between the augmented samples and original samples. Finally, a specific feature center loss is introduced for the generator network to enhance its stability. Empirical experiments are conducted on three public datasets, namely SWAT, WADI and NSL_KDD. Comparing with the state-of-the-art methods, the evaluation results show that the proposed MTS-DVGAN is more stable and can achieve consistent performance improvement.
* 27 pages, 14 figures, 8 tables. Accepted by Computers & Security
Covert Planning against Imperfect Observers
Oct 25, 2023Covert planning refers to a class of constrained planning problems where an agent aims to accomplish a task with minimal information leaked to a passive observer to avoid detection. However, existing methods of covert planning often consider deterministic environments or do not exploit the observer's imperfect information. This paper studies how covert planning can leverage the coupling of stochastic dynamics and the observer's imperfect observation to achieve optimal task performance without being detected. Specifically, we employ a Markov decision process to model the interaction between the agent and its stochastic environment, and a partial observation function to capture the leaked information to a passive observer. Assuming the observer employs hypothesis testing to detect if the observation deviates from a nominal policy, the covert planning agent aims to maximize the total discounted reward while keeping the probability of being detected as an adversary below a given threshold. We prove that finite-memory policies are more powerful than Markovian policies in covert planning. Then, we develop a primal-dual proximal policy gradient method with a two-time-scale update to compute a (locally) optimal covert policy. We demonstrate the effectiveness of our methods using a stochastic gridworld example. Our experimental results illustrate that the proposed method computes a policy that maximizes the adversary's expected reward without violating the detection constraint, and empirically demonstrates how the environmental noises can influence the performance of the covert policies.
State Sequences Prediction via Fourier Transform for Representation Learning
Oct 24, 2023While deep reinforcement learning (RL) has been demonstrated effective in solving complex control tasks, sample efficiency remains a key challenge due to the large amounts of data required for remarkable performance. Existing research explores the application of representation learning for data-efficient RL, e.g., learning predictive representations by predicting long-term future states. However, many existing methods do not fully exploit the structural information inherent in sequential state signals, which can potentially improve the quality of long-term decision-making but is difficult to discern in the time domain. To tackle this problem, we propose State Sequences Prediction via Fourier Transform (SPF), a novel method that exploits the frequency domain of state sequences to extract the underlying patterns in time series data for learning expressive representations efficiently. Specifically, we theoretically analyze the existence of structural information in state sequences, which is closely related to policy performance and signal regularity, and then propose to predict the Fourier transform of infinite-step future state sequences to extract such information. One of the appealing features of SPF is that it is simple to implement while not requiring storage of infinite-step future states as prediction targets. Experiments demonstrate that the proposed method outperforms several state-of-the-art algorithms in terms of both sample efficiency and performance.
Dynamic Encoding and Decoding of Information for Split Learning in Mobile-Edge Computing: Leveraging Information Bottleneck Theory
Sep 06, 2023Split learning is a privacy-preserving distributed learning paradigm in which an ML model (e.g., a neural network) is split into two parts (i.e., an encoder and a decoder). The encoder shares so-called latent representation, rather than raw data, for model training. In mobile-edge computing, network functions (such as traffic forecasting) can be trained via split learning where an encoder resides in a user equipment (UE) and a decoder resides in the edge network. Based on the data processing inequality and the information bottleneck (IB) theory, we present a new framework and training mechanism to enable a dynamic balancing of the transmission resource consumption with the informativeness of the shared latent representations, which directly impacts the predictive performance. The proposed training mechanism offers an encoder-decoder neural network architecture featuring multiple modes of complexity-relevance tradeoffs, enabling tunable performance. The adaptability can accommodate varying real-time network conditions and application requirements, potentially reducing operational expenditure and enhancing network agility. As a proof of concept, we apply the training mechanism to a millimeter-wave (mmWave)-enabled throughput prediction problem. We also offer new insights and highlight some challenges related to recurrent neural networks from the perspective of the IB theory. Interestingly, we find a compression phenomenon across the temporal domain of the sequential model, in addition to the compression phase that occurs with the number of training epochs.
PriPrune: Quantifying and Preserving Privacy in Pruned Federated Learning
Oct 30, 2023Federated learning (FL) is a paradigm that allows several client devices and a server to collaboratively train a global model, by exchanging only model updates, without the devices sharing their local training data. These devices are often constrained in terms of communication and computation resources, and can further benefit from model pruning -- a paradigm that is widely used to reduce the size and complexity of models. Intuitively, by making local models coarser, pruning is expected to also provide some protection against privacy attacks in the context of FL. However this protection has not been previously characterized, formally or experimentally, and it is unclear if it is sufficient against state-of-the-art attacks. In this paper, we perform the first investigation of privacy guarantees for model pruning in FL. We derive information-theoretic upper bounds on the amount of information leaked by pruned FL models. We complement and validate these theoretical findings, with comprehensive experiments that involve state-of-the-art privacy attacks, on several state-of-the-art FL pruning schemes, using benchmark datasets. This evaluation provides valuable insights into the choices and parameters that can affect the privacy protection provided by pruning. Based on these insights, we introduce PriPrune -- a privacy-aware algorithm for local model pruning, which uses a personalized per-client defense mask and adapts the defense pruning rate so as to jointly optimize privacy and model performance. PriPrune is universal in that can be applied after any pruned FL scheme on the client, without modification, and protects against any inversion attack by the server. Our empirical evaluation demonstrates that PriPrune significantly improves the privacy-accuracy tradeoff compared to state-of-the-art pruned FL schemes that do not take privacy into account.
Bayesian Multistate Bennett Acceptance Ratio Methods
Nov 01, 2023The multistate Bennett acceptance ratio (MBAR) method is a prevalent approach for computing free energies of thermodynamic states. In this work, we introduce BayesMBAR, a Bayesian generalization of the MBAR method. By integrating configurations sampled from thermodynamic states with a prior distribution, BayesMBAR computes a posterior distribution of free energies. Using the posterior distribution, we derive free energy estimations and compute their associated uncertainties. Notably, when a uniform prior distribution is used, BayesMBAR recovers the MBAR's result but provides more accurate uncertainty estimates. Additionally, when prior knowledge about free energies is available, BayesMBAR can incorporate this information into the estimation procedure by using non-uniform prior distributions. As an example, we show that, by incorporating the prior knowledge about the smoothness of free energy surfaces, BayesMBAR provides more accurate estimates than the MBAR method. Given MBAR's widespread use in free energy calculations, we anticipate BayesMBAR to be an essential tool in various applications of free energy calculations.
Learning to optimize by multi-gradient for multi-objective optimization
Nov 01, 2023The development of artificial intelligence (AI) for science has led to the emergence of learning-based research paradigms, necessitating a compelling reevaluation of the design of multi-objective optimization (MOO) methods. The new generation MOO methods should be rooted in automated learning rather than manual design. In this paper, we introduce a new automatic learning paradigm for optimizing MOO problems, and propose a multi-gradient learning to optimize (ML2O) method, which automatically learns a generator (or mappings) from multiple gradients to update directions. As a learning-based method, ML2O acquires knowledge of local landscapes by leveraging information from the current step and incorporates global experience extracted from historical iteration trajectory data. By introducing a new guarding mechanism, we propose a guarded multi-gradient learning to optimize (GML2O) method, and prove that the iterative sequence generated by GML2O converges to a Pareto critical point. The experimental results demonstrate that our learned optimizer outperforms hand-designed competitors on training multi-task learning (MTL) neural network.
Artificial intelligence and the limits of the humanities
Oct 30, 2023The complexity of cultures in the modern world is now beyond human comprehension. Cognitive sciences cast doubts on the traditional explanations based on mental models. The core subjects in humanities may lose their importance. Humanities have to adapt to the digital age. New, interdisciplinary branches of humanities emerge. Instant access to information will be replaced by instant access to knowledge. Understanding the cognitive limitations of humans and the opportunities opened by the development of artificial intelligence and interdisciplinary research necessary to address global challenges is the key to the revitalization of humanities. Artificial intelligence will radically change humanities, from art to political sciences and philosophy, making these disciplines attractive to students and enabling them to go beyond current limitations.
CrossEAI: Using Explainable AI to generate better bounding boxes for Chest X-ray images
Oct 29, 2023Explainability is critical for deep learning applications in healthcare which are mandated to provide interpretations to both patients and doctors according to legal regulations and responsibilities. Explainable AI methods, such as feature importance using integrated gradients, model approximation using LIME, or neuron activation and layer conductance to provide interpretations for certain health risk predictions. In medical imaging diagnosis, disease classification usually achieves high accuracy, but generated bounding boxes have much lower Intersection over Union (IoU). Different methods with self-supervised or semi-supervised learning strategies have been proposed, but few improvements have been identified for bounding box generation. Previous work shows that bounding boxes generated by these methods are usually larger than ground truth and contain major non-disease area. This paper utilizes the advantages of post-hoc AI explainable methods to generate bounding boxes for chest x-ray image diagnosis. In this work, we propose CrossEAI which combines heatmap and gradient map to generate more targeted bounding boxes. By using weighted average of Guided Backpropagation and Grad-CAM++, we are able to generate bounding boxes which are closer to the ground truth. We evaluate our model on a chest x-ray dataset. The performance has significant improvement over the state of the art model with the same setting, with $9\%$ improvement in average of all diseases over all IoU. Moreover, as a model that does not use any ground truth bounding box information for training, we achieve same performance in general as the model that uses $80\%$ of the ground truth bounding box information for training
Capacity-based Spatial Modulation Constellation and Pre-scaling Design
Oct 24, 2023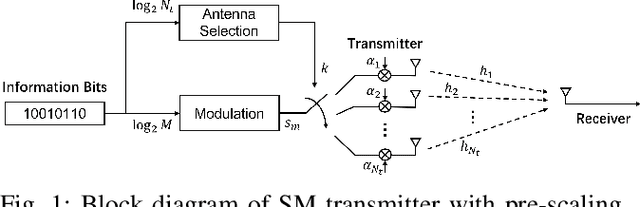
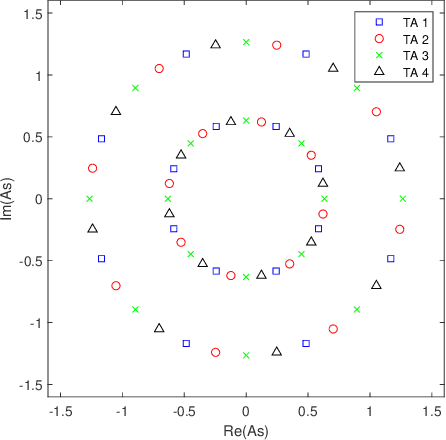
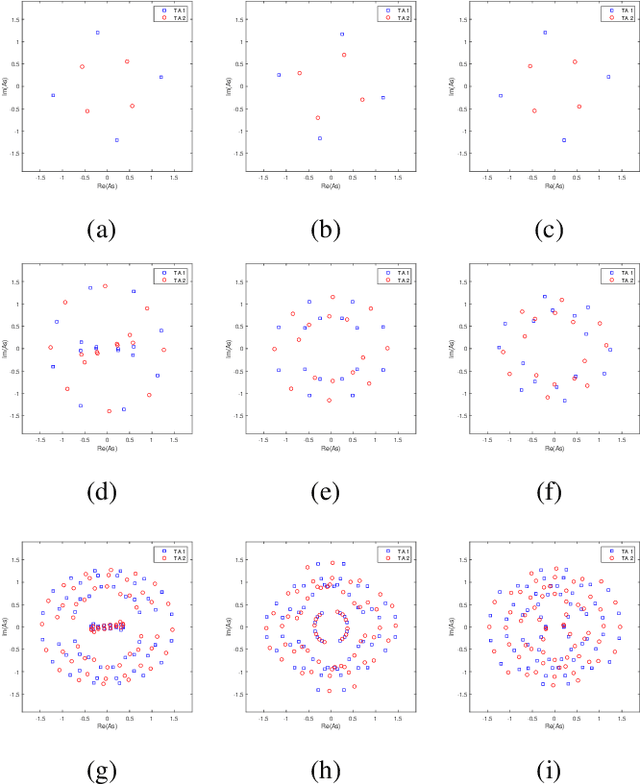
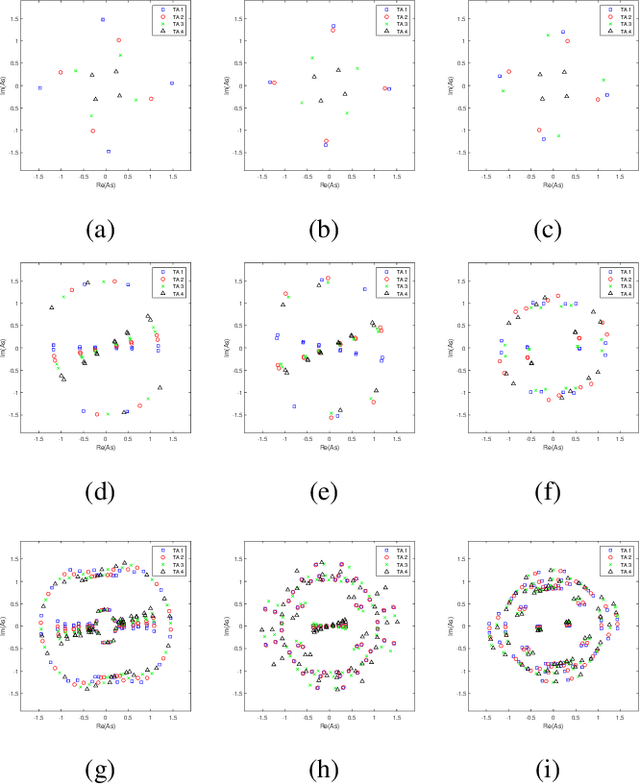
Spatial Modulation (SM) can utilize the index of the transmit antenna (TA) to transmit additional information. In this paper, to improve the performance of SM, a non-uniform constellation (NUC) and pre-scaling coefficients optimization design scheme is proposed. The bit-interleaved coded modulation (BICM) capacity calculation formula of SM system is firstly derived. The constellation and pre-scaling coefficients are optimized by maximizing the BICM capacity without channel state information (CSI) feedback. Optimization results are given for the multiple-input-single-output (MISO) system with Rayleigh channel. Simulation result shows the proposed scheme provides a meaningful performance gain compared to conventional SM system without CSI feedback. The proposed optimization design scheme can be a promising technology for future 6G to achieve high-efficiency.