 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Code-Switching with Word Senses for Pretraining in Neural Machine Translation
Oct 21, 2023
Lexical ambiguity is a significant and pervasive challenge in Neural Machine Translation (NMT), with many state-of-the-art (SOTA) NMT systems struggling to handle polysemous words (Campolungo et al., 2022). The same holds for the NMT pretraining paradigm of denoising synthetic "code-switched" text (Pan et al., 2021; Iyer et al., 2023), where word senses are ignored in the noising stage -- leading to harmful sense biases in the pretraining data that are subsequently inherited by the resulting models. In this work, we introduce Word Sense Pretraining for Neural Machine Translation (WSP-NMT) - an end-to-end approach for pretraining multilingual NMT models leveraging word sense-specific information from Knowledge Bases. Our experiments show significant improvements in overall translation quality. Then, we show the robustness of our approach to scale to various challenging data and resource-scarce scenarios and, finally, report fine-grained accuracy improvements on the DiBiMT disambiguation benchmark. Our studies yield interesting and novel insights into the merits and challenges of integrating word sense information and structured knowledge in multilingual pretraining for NMT.
The Past, Present, and Future of Typological Databases in NLP
Oct 20, 2023Typological information has the potential to be beneficial in the development of NLP models, particularly for low-resource languages. Unfortunately, current large-scale typological databases, notably WALS and Grambank, are inconsistent both with each other and with other sources of typological information, such as linguistic grammars. Some of these inconsistencies stem from coding errors or linguistic variation, but many of the disagreements are due to the discrete categorical nature of these databases. We shed light on this issue by systematically exploring disagreements across typological databases and resources, and their uses in NLP, covering the past and present. We next investigate the future of such work, offering an argument that a continuous view of typological features is clearly beneficial, echoing recommendations from linguistics. We propose that such a view of typology has significant potential in the future, including in language modeling in low-resource scenarios.
DDMT: Denoising Diffusion Mask Transformer Models for Multivariate Time Series Anomaly Detection
Oct 30, 2023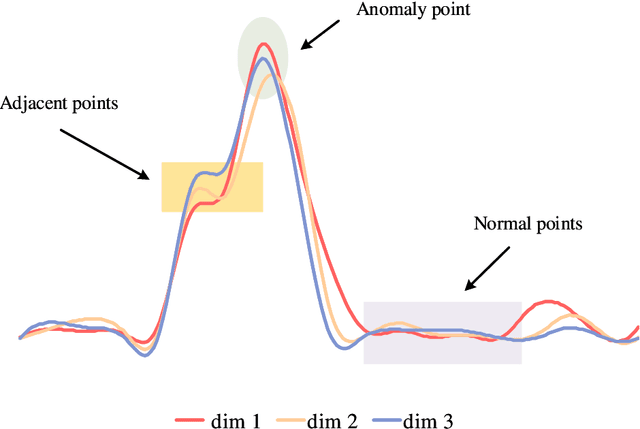

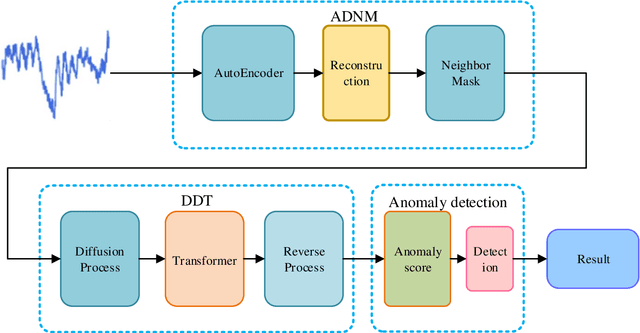
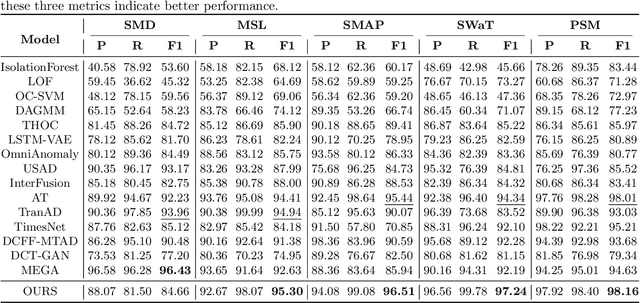
Anomaly detection in multivariate time series has emerged as a crucial challenge in time series research, with significant research implications in various fields such as fraud detection, fault diagnosis, and system state estimation. Reconstruction-based models have shown promising potential in recent years for detecting anomalies in time series data. However, due to the rapid increase in data scale and dimensionality, the issues of noise and Weak Identity Mapping (WIM) during time series reconstruction have become increasingly pronounced. To address this, we introduce a novel Adaptive Dynamic Neighbor Mask (ADNM) mechanism and integrate it with the Transformer and Denoising Diffusion Model, creating a new framework for multivariate time series anomaly detection, named Denoising Diffusion Mask Transformer (DDMT). The ADNM module is introduced to mitigate information leakage between input and output features during data reconstruction, thereby alleviating the problem of WIM during reconstruction. The Denoising Diffusion Transformer (DDT) employs the Transformer as an internal neural network structure for Denoising Diffusion Model. It learns the stepwise generation process of time series data to model the probability distribution of the data, capturing normal data patterns and progressively restoring time series data by removing noise, resulting in a clear recovery of anomalies. To the best of our knowledge, this is the first model that combines Denoising Diffusion Model and the Transformer for multivariate time series anomaly detection. Experimental evaluations were conducted on five publicly available multivariate time series anomaly detection datasets. The results demonstrate that the model effectively identifies anomalies in time series data, achieving state-of-the-art performance in anomaly detection.
VDIP-TGV: Blind Image Deconvolution via Variational Deep Image Prior Empowered by Total Generalized Variation
Oct 30, 2023Recovering clear images from blurry ones with an unknown blur kernel is a challenging problem. Deep image prior (DIP) proposes to use the deep network as a regularizer for a single image rather than as a supervised model, which achieves encouraging results in the nonblind deblurring problem. However, since the relationship between images and the network architectures is unclear, it is hard to find a suitable architecture to provide sufficient constraints on the estimated blur kernels and clean images. Also, DIP uses the sparse maximum a posteriori (MAP), which is insufficient to enforce the selection of the recovery image. Recently, variational deep image prior (VDIP) was proposed to impose constraints on both blur kernels and recovery images and take the standard deviation of the image into account during the optimization process by the variational principle. However, we empirically find that VDIP struggles with processing image details and tends to generate suboptimal results when the blur kernel is large. Therefore, we combine total generalized variational (TGV) regularization with VDIP in this paper to overcome these shortcomings of VDIP. TGV is a flexible regularization that utilizes the characteristics of partial derivatives of varying orders to regularize images at different scales, reducing oil painting artifacts while maintaining sharp edges. The proposed VDIP-TGV effectively recovers image edges and details by supplementing extra gradient information through TGV. Additionally, this model is solved by the alternating direction method of multipliers (ADMM), which effectively combines traditional algorithms and deep learning methods. Experiments show that our proposed VDIP-TGV surpasses various state-of-the-art models quantitatively and qualitatively.
TransXNet: Learning Both Global and Local Dynamics with a Dual Dynamic Token Mixer for Visual Recognition
Oct 30, 2023Recent studies have integrated convolution into transformers to introduce inductive bias and improve generalization performance. However, the static nature of conventional convolution prevents it from dynamically adapting to input variations, resulting in a representation discrepancy between convolution and self-attention as self-attention calculates attention matrices dynamically. Furthermore, when stacking token mixers that consist of convolution and self-attention to form a deep network, the static nature of convolution hinders the fusion of features previously generated by self-attention into convolution kernels. These two limitations result in a sub-optimal representation capacity of the constructed networks. To find a solution, we propose a lightweight Dual Dynamic Token Mixer (D-Mixer) that aggregates global information and local details in an input-dependent way. D-Mixer works by applying an efficient global attention module and an input-dependent depthwise convolution separately on evenly split feature segments, endowing the network with strong inductive bias and an enlarged effective receptive field. We use D-Mixer as the basic building block to design TransXNet, a novel hybrid CNN-Transformer vision backbone network that delivers compelling performance. In the ImageNet-1K image classification task, TransXNet-T surpasses Swin-T by 0.3\% in top-1 accuracy while requiring less than half of the computational cost. Furthermore, TransXNet-S and TransXNet-B exhibit excellent model scalability, achieving top-1 accuracy of 83.8\% and 84.6\% respectively, with reasonable computational costs. Additionally, our proposed network architecture demonstrates strong generalization capabilities in various dense prediction tasks, outperforming other state-of-the-art networks while having lower computational costs.
Asymmetric double-winged multi-view clustering network for exploring Diverse and Consistent Information
Sep 01, 2023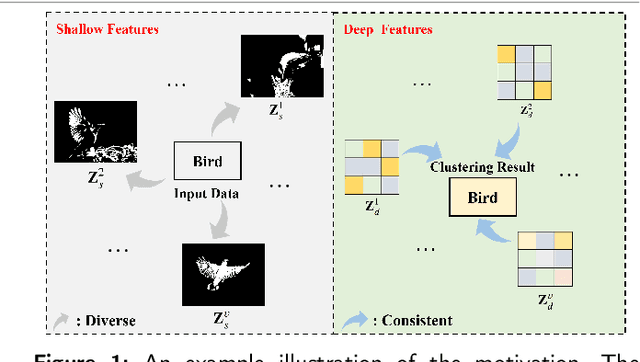
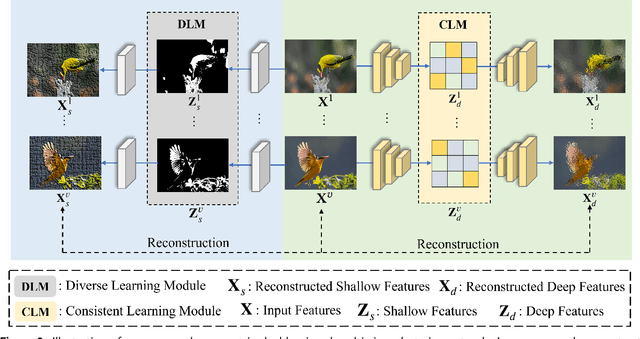
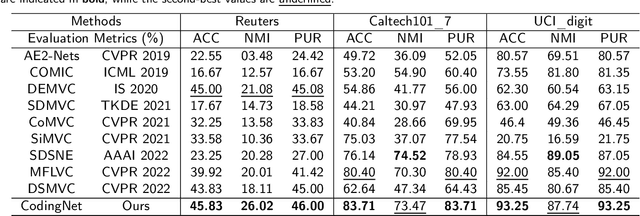
In unsupervised scenarios, deep contrastive multi-view clustering (DCMVC) is becoming a hot research spot, which aims to mine the potential relationships between different views. Most existing DCMVC algorithms focus on exploring the consistency information for the deep semantic features, while ignoring the diverse information on shallow features. To fill this gap, we propose a novel multi-view clustering network termed CodingNet to explore the diverse and consistent information simultaneously in this paper. Specifically, instead of utilizing the conventional auto-encoder, we design an asymmetric structure network to extract shallow and deep features separately. Then, by aligning the similarity matrix on the shallow feature to the zero matrix, we ensure the diversity for the shallow features, thus offering a better description of multi-view data. Moreover, we propose a dual contrastive mechanism that maintains consistency for deep features at both view-feature and pseudo-label levels. Our framework's efficacy is validated through extensive experiments on six widely used benchmark datasets, outperforming most state-of-the-art multi-view clustering algorithms.
Locally Differentially Private Gradient Tracking for Distributed Online Learning over Directed Graphs
Oct 29, 2023Distributed online learning has been proven extremely effective in solving large-scale machine learning problems over streaming data. However, information sharing between learners in distributed learning also raises concerns about the potential leakage of individual learners' sensitive data. To mitigate this risk, differential privacy, which is widely regarded as the "gold standard" for privacy protection, has been widely employed in many existing results on distributed online learning. However, these results often face a fundamental tradeoff between learning accuracy and privacy. In this paper, we propose a locally differentially private gradient tracking based distributed online learning algorithm that successfully circumvents this tradeoff. We prove that the proposed algorithm converges in mean square to the exact optimal solution while ensuring rigorous local differential privacy, with the cumulative privacy budget guaranteed to be finite even when the number of iterations tends to infinity. The algorithm is applicable even when the communication graph among learners is directed. To the best of our knowledge, this is the first result that simultaneously ensures learning accuracy and rigorous local differential privacy in distributed online learning over directed graphs. We evaluate our algorithm's performance by using multiple benchmark machine-learning applications, including logistic regression of the "Mushrooms" dataset and CNN-based image classification of the "MNIST" and "CIFAR-10" datasets, respectively. The experimental results confirm that the proposed algorithm outperforms existing counterparts in both training and testing accuracies.
From Continuous Dynamics to Graph Neural Networks: Neural Diffusion and Beyond
Oct 29, 2023Graph neural networks (GNNs) have demonstrated significant promise in modelling relational data and have been widely applied in various fields of interest. The key mechanism behind GNNs is the so-called message passing where information is being iteratively aggregated to central nodes from their neighbourhood. Such a scheme has been found to be intrinsically linked to a physical process known as heat diffusion, where the propagation of GNNs naturally corresponds to the evolution of heat density. Analogizing the process of message passing to the heat dynamics allows to fundamentally understand the power and pitfalls of GNNs and consequently informs better model design. Recently, there emerges a plethora of works that proposes GNNs inspired from the continuous dynamics formulation, in an attempt to mitigate the known limitations of GNNs, such as oversmoothing and oversquashing. In this survey, we provide the first systematic and comprehensive review of studies that leverage the continuous perspective of GNNs. To this end, we introduce foundational ingredients for adapting continuous dynamics to GNNs, along with a general framework for the design of graph neural dynamics. We then review and categorize existing works based on their driven mechanisms and underlying dynamics. We also summarize how the limitations of classic GNNs can be addressed under the continuous framework. We conclude by identifying multiple open research directions.
Towards Generalized Multi-stage Clustering: Multi-view Self-distillation
Oct 29, 2023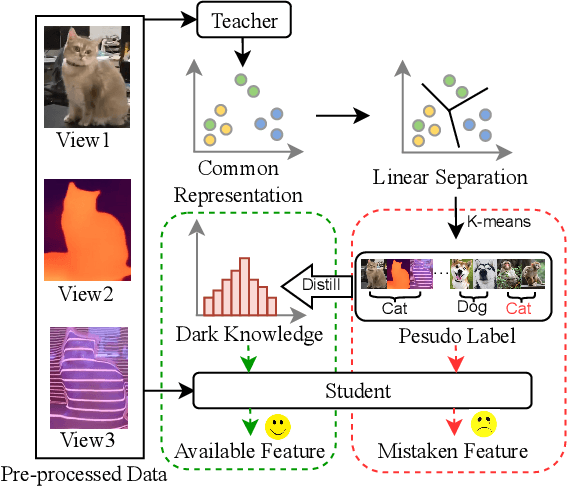
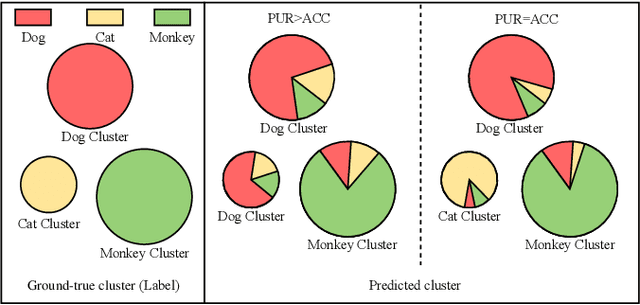
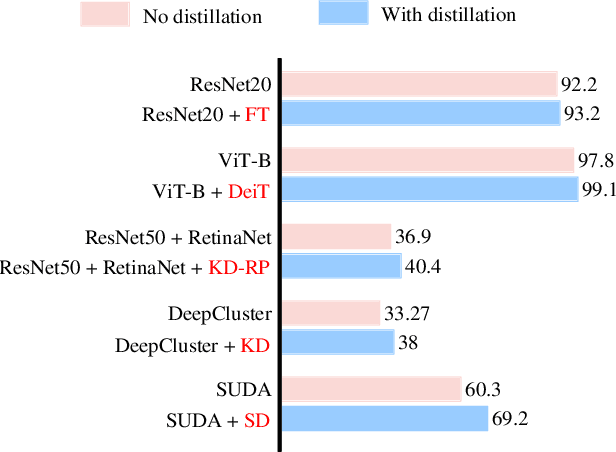
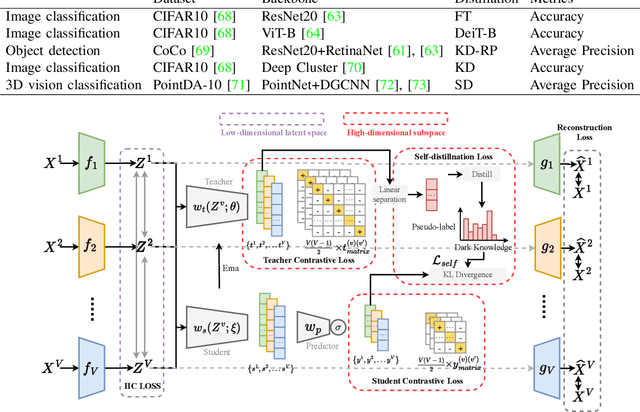
Existing multi-stage clustering methods independently learn the salient features from multiple views and then perform the clustering task. Particularly, multi-view clustering (MVC) has attracted a lot of attention in multi-view or multi-modal scenarios. MVC aims at exploring common semantics and pseudo-labels from multiple views and clustering in a self-supervised manner. However, limited by noisy data and inadequate feature learning, such a clustering paradigm generates overconfident pseudo-labels that mis-guide the model to produce inaccurate predictions. Therefore, it is desirable to have a method that can correct this pseudo-label mistraction in multi-stage clustering to avoid the bias accumulation. To alleviate the effect of overconfident pseudo-labels and improve the generalization ability of the model, this paper proposes a novel multi-stage deep MVC framework where multi-view self-distillation (DistilMVC) is introduced to distill dark knowledge of label distribution. Specifically, in the feature subspace at different hierarchies, we explore the common semantics of multiple views through contrastive learning and obtain pseudo-labels by maximizing the mutual information between views. Additionally, a teacher network is responsible for distilling pseudo-labels into dark knowledge, supervising the student network and improving its predictive capabilities to enhance the robustness. Extensive experiments on real-world multi-view datasets show that our method has better clustering performance than state-of-the-art methods.
Dynamic V2X Autonomous Perception from Road-to-Vehicle Vision
Oct 29, 2023Vehicle-to-everything (V2X) perception is an innovative technology that enhances vehicle perception accuracy, thereby elevating the security and reliability of autonomous systems. However, existing V2X perception methods focus on static scenes from mainly vehicle-based vision, which is constrained by sensor capabilities and communication loads. To adapt V2X perception models to dynamic scenes, we propose to build V2X perception from road-to-vehicle vision and present Adaptive Road-to-Vehicle Perception (AR2VP) method. In AR2VP,we leverage roadside units to offer stable, wide-range sensing capabilities and serve as communication hubs. AR2VP is devised to tackle both intra-scene and inter-scene changes. For the former, we construct a dynamic perception representing module, which efficiently integrates vehicle perceptions, enabling vehicles to capture a more comprehensive range of dynamic factors within the scene.Moreover, we introduce a road-to-vehicle perception compensating module, aimed at preserving the maximized roadside unit perception information in the presence of intra-scene changes.For inter-scene changes, we implement an experience replay mechanism leveraging the roadside unit's storage capacity to retain a subset of historical scene data, maintaining model robustness in response to inter-scene shifts. We conduct perception experiment on 3D object detection and segmentation, and the results show that AR2VP excels in both performance-bandwidth trade-offs and adaptability within dynamic environments.