 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Symmetry-preserving graph attention network to solve routing problems at multiple resolutions
Oct 24, 2023
Travelling Salesperson Problems (TSPs) and Vehicle Routing Problems (VRPs) have achieved reasonable improvement in accuracy and computation time with the adaptation of Machine Learning (ML) methods. However, none of the previous works completely respects the symmetries arising from TSPs and VRPs including rotation, translation, permutation, and scaling. In this work, we introduce the first-ever completely equivariant model and training to solve combinatorial problems. Furthermore, it is essential to capture the multiscale structure (i.e. from local to global information) of the input graph, especially for the cases of large and long-range graphs, while previous methods are limited to extracting only local information that can lead to a local or sub-optimal solution. To tackle the above limitation, we propose a Multiresolution scheme in combination with Equivariant Graph Attention network (mEGAT) architecture, which can learn the optimal route based on low-level and high-level graph resolutions in an efficient way. In particular, our approach constructs a hierarchy of coarse-graining graphs from the input graph, in which we try to solve the routing problems on simple low-level graphs first, then utilize that knowledge for the more complex high-level graphs. Experimentally, we have shown that our model outperforms existing baselines and proved that symmetry preservation and multiresolution are important recipes for solving combinatorial problems in a data-driven manner. Our source code is publicly available at https://github.com/HySonLab/Multires-NP-hard
The Janus Interface: How Fine-Tuning in Large Language Models Amplifies the Privacy Risks
Oct 24, 2023The era post-2018 marked the advent of Large Language Models (LLMs), with innovations such as OpenAI's ChatGPT showcasing prodigious linguistic prowess. As the industry galloped toward augmenting model parameters and capitalizing on vast swaths of human language data, security and privacy challenges also emerged. Foremost among these is the potential inadvertent accrual of Personal Identifiable Information (PII) during web-based data acquisition, posing risks of unintended PII disclosure. While strategies like RLHF during training and Catastrophic Forgetting have been marshaled to control the risk of privacy infringements, recent advancements in LLMs, epitomized by OpenAI's fine-tuning interface for GPT-3.5, have reignited concerns. One may ask: can the fine-tuning of LLMs precipitate the leakage of personal information embedded within training datasets? This paper reports the first endeavor to seek the answer to the question, particularly our discovery of a new LLM exploitation avenue, called the Janus attack. In the attack, one can construct a PII association task, whereby an LLM is fine-tuned using a minuscule PII dataset, to potentially reinstate and reveal concealed PIIs. Our findings indicate that, with a trivial fine-tuning outlay, LLMs such as GPT-3.5 can transition from being impermeable to PII extraction to a state where they divulge a substantial proportion of concealed PII. This research, through its deep dive into the Janus attack vector, underscores the imperative of navigating the intricate interplay between LLM utility and privacy preservation.
FANToM: A Benchmark for Stress-testing Machine Theory of Mind in Interactions
Oct 25, 2023



Theory of mind (ToM) evaluations currently focus on testing models using passive narratives that inherently lack interactivity. We introduce FANToM, a new benchmark designed to stress-test ToM within information-asymmetric conversational contexts via question answering. Our benchmark draws upon important theoretical requisites from psychology and necessary empirical considerations when evaluating large language models (LLMs). In particular, we formulate multiple types of questions that demand the same underlying reasoning to identify illusory or false sense of ToM capabilities in LLMs. We show that FANToM is challenging for state-of-the-art LLMs, which perform significantly worse than humans even with chain-of-thought reasoning or fine-tuning.
Over-the-air Federated Policy Gradient
Oct 25, 2023In recent years, over-the-air aggregation has been widely considered in large-scale distributed learning, optimization, and sensing. In this paper, we propose the over-the-air federated policy gradient algorithm, where all agents simultaneously broadcast an analog signal carrying local information to a common wireless channel, and a central controller uses the received aggregated waveform to update the policy parameters. We investigate the effect of noise and channel distortion on the convergence of the proposed algorithm, and establish the complexities of communication and sampling for finding an $\epsilon$-approximate stationary point. Finally, we present some simulation results to show the effectiveness of the algorithm.
Using Artificial French Data to Understand the Emergence of Gender Bias in Transformer Language Models
Oct 24, 2023Numerous studies have demonstrated the ability of neural language models to learn various linguistic properties without direct supervision. This work takes an initial step towards exploring the less researched topic of how neural models discover linguistic properties of words, such as gender, as well as the rules governing their usage. We propose to use an artificial corpus generated by a PCFG based on French to precisely control the gender distribution in the training data and determine under which conditions a model correctly captures gender information or, on the contrary, appears gender-biased.
Efficient Algorithms for Generalized Linear Bandits with Heavy-tailed Rewards
Oct 28, 2023
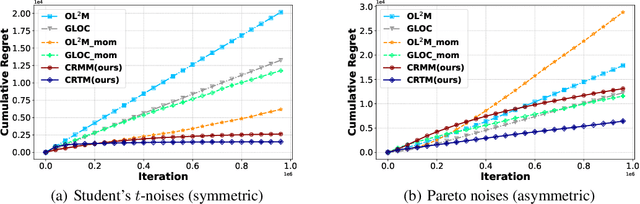
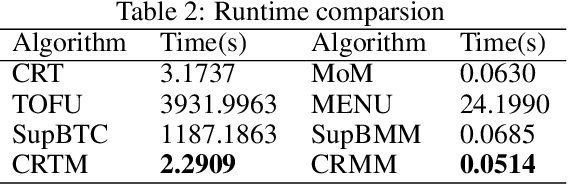
This paper investigates the problem of generalized linear bandits with heavy-tailed rewards, whose $(1+\epsilon)$-th moment is bounded for some $\epsilon\in (0,1]$. Although there exist methods for generalized linear bandits, most of them focus on bounded or sub-Gaussian rewards and are not well-suited for many real-world scenarios, such as financial markets and web-advertising. To address this issue, we propose two novel algorithms based on truncation and mean of medians. These algorithms achieve an almost optimal regret bound of $\widetilde{O}(dT^{\frac{1}{1+\epsilon}})$, where $d$ is the dimension of contextual information and $T$ is the time horizon. Our truncation-based algorithm supports online learning, distinguishing it from existing truncation-based approaches. Additionally, our mean-of-medians-based algorithm requires only $O(\log T)$ rewards and one estimator per epoch, making it more practical. Moreover, our algorithms improve the regret bounds by a logarithmic factor compared to existing algorithms when $\epsilon=1$. Numerical experimental results confirm the merits of our algorithms.
ReConTab: Regularized Contrastive Representation Learning for Tabular Data
Oct 28, 2023Representation learning stands as one of the critical machine learning techniques across various domains. Through the acquisition of high-quality features, pre-trained embeddings significantly reduce input space redundancy, benefiting downstream pattern recognition tasks such as classification, regression, or detection. Nonetheless, in the domain of tabular data, feature engineering and selection still heavily rely on manual intervention, leading to time-consuming processes and necessitating domain expertise. In response to this challenge, we introduce ReConTab, a deep automatic representation learning framework with regularized contrastive learning. Agnostic to any type of modeling task, ReConTab constructs an asymmetric autoencoder based on the same raw features from model inputs, producing low-dimensional representative embeddings. Specifically, regularization techniques are applied for raw feature selection. Meanwhile, ReConTab leverages contrastive learning to distill the most pertinent information for downstream tasks. Experiments conducted on extensive real-world datasets substantiate the framework's capacity to yield substantial and robust performance improvements. Furthermore, we empirically demonstrate that pre-trained embeddings can seamlessly integrate as easily adaptable features, enhancing the performance of various traditional methods such as XGBoost and Random Forest.
Graph-based SLAM-Aware Exploration with Prior Topo-Metric Information
Aug 31, 2023Autonomous exploration requires the robot to explore an unknown environment while constructing an accurate map with the SLAM (Simultaneous Localization and Mapping) techniques. Without prior information, the exploratory performance is usually conservative due to the limited planning horizon. This paper exploits a prior topo-metric graph of the environment to benefit both the exploration efficiency and the pose graph accuracy in SLAM. Based on recent advancements in relating pose graph reliability with graph topology, we are able to formulate both objectives into a SLAM-aware path planning problem over the prior graph, which finds a fast exploration path with informative loop closures that globally stabilize the pose graph. Furthermore, we derive theoretical thresholds to speed up the greedy algorithm to the problem, which significantly prune non-optimal loop closures in iterations. The proposed planner is incorporated into a hierarchical exploration framework, with flexible features including path replanning and online prior map update that adds additional information to the prior graph. Extensive experiments indicate that our method has comparable exploration efficiency to others while consistently maintaining higher mapping accuracy in various environments. Our implementations will be open-source on GitHub.
Multi-functional OFDM Signal Design for Integrated Sensing, Communications, and Power Transfer
Oct 31, 2023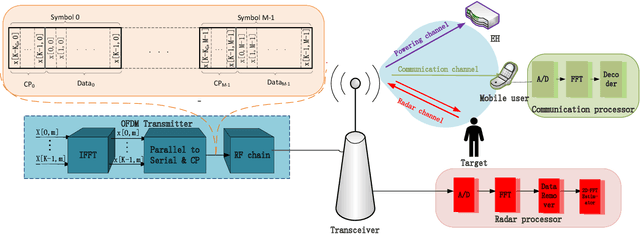
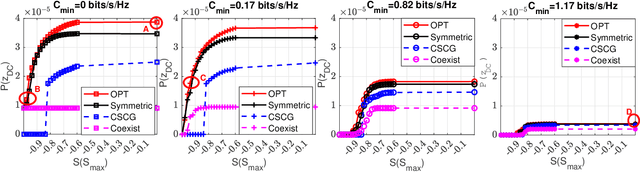
The wireless domain is witnessing a flourishing of integrated systems, e.g. (a) integrated sensing and communications, and (b) simultaneous wireless information and power transfer, due to their potential to use resources (spectrum, power) judiciously. Inspired by this trend, we investigate integrated sensing, communications and powering (ISCAP), through the design of a wideband OFDM signal to power a sensor while simultaneously performing target-sensing and communication. To characterize the ISCAP performance region, we assume symbols with non-zero mean asymmetric Gaussian distribution (i.e., the input distribution), and optimize its mean and variance at each subcarrier to maximize the harvested power, subject to constraints on the achievable rate (communications) and the average side-to-peak-lobe difference (sensing). The resulting input distribution, through simulations, achieves a larger performance region than that of (i) a symmetric complex Gaussian input distribution with identical mean and variance for the real and imaginary parts, (ii) a zero-mean symmetric complex Gaussian input distribution, and (iii) the superposed power-splitting communication and sensing signal (the coexisting solution). In particular, the optimized input distribution balances the three functions by exhibiting the following features: (a) symbols in subcarriers with strong communication channels have high variance to satisfy the rate constraint, while the other symbols are dominated by the mean, forming a relatively uniform sum of mean and variance across subcarriers for sensing; (b) with looser communication and sensing constraints, large absolute means appear on subcarriers with stronger powering channels for higher harvested power. As a final note, the results highlight the great potential of the co-designed ISCAP system for further efficiency enhancement.
SwG-former: Sliding-window Graph Convolutional Network Integrated with Conformer for Sound Event Localization and Detection
Oct 21, 2023Sound event localization and detection (SELD) is a joint task of sound event detection (SED) and direction of arrival (DoA) estimation. SED mainly relies on temporal dependencies to distinguish different sound classes, while DoA estimation depends on spatial correlations to estimate source directions. To jointly optimize two subtasks, the SELD system should extract spatial correlations and model temporal dependencies simultaneously. However, numerous models mainly extract spatial correlations and model temporal dependencies separately. In this paper, the interdependence of spatial-temporal information in audio signals is exploited for simultaneous extraction to enhance the model performance. In response, a novel graph representation leveraging graph convolutional network (GCN) in non-Euclidean space is developed to extract spatial-temporal information concurrently. A sliding-window graph (SwG) module is designed based on the graph representation. It exploits sliding-windows with different sizes to learn temporal context information and dynamically constructs graph vertices in the frequency-channel (F-C) domain to capture spatial correlations. Furthermore, as the cornerstone of message passing, a robust Conv2dAgg function is proposed and embedded into the SwG module to aggregate the features of neighbor vertices. To improve the performance of SELD in a natural spatial acoustic environment, a general and efficient SwG-former model is proposed by integrating the SwG module with the Conformer. It exhibits superior performance in comparison to recent advanced SELD models. To further validate the generality and efficiency of the SwG-former, it is seamlessly integrated into the event-independent network version 2 (EINV2) called SwG-EINV2. The SwG-EINV2 surpasses the state-of-the-art (SOTA) methods under the same acoustic environment.