 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Ensemble Machine Learning Approach for Screening Covid-19 based on Urine Parameters
Nov 03, 2023
The rapid spread of COVID-19 and the emergence of new variants underscore the importance of effective screening measures. Rapid diagnosis and subsequent quarantine of infected individuals can prevent further spread of the virus in society. While PCR tests are the gold standard for COVID-19 diagnosis, they are costly and time-consuming. In contrast, urine test strips are an inexpensive, non-invasive, and rapidly obtainable screening method that can provide important information about a patient's health status. In this study, we collected a new dataset and used the RGB (Red Green Blue) color space of urine test strips parameters to detect the health status of individuals. To improve the accuracy of our model, we converted the RGB space to 10 additional color spaces. After evaluating four different machine learning models, we proposed a new ensemble model based on a multi-layer perceptron neural network. Although the initial results were not strong, we were able to improve the model's screening performance for COVID-19 by removing uncertain regions of the model space. Ultimately, our model achieved a screening accuracy of 80% based on urine parameters. Our results suggest that urine test strips can be a useful tool for COVID-19 screening, particularly in resource-constrained settings where PCR testing may not be feasible. Further research is needed to validate our findings and explore the potential role of urine test strips in COVID-19 diagnosis and management.
A Public Information Precoding for MIMO Visible Light Communication System Based on Manifold Optimization
Sep 09, 2023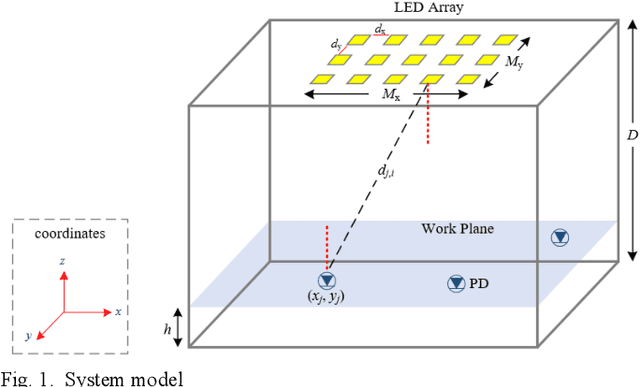
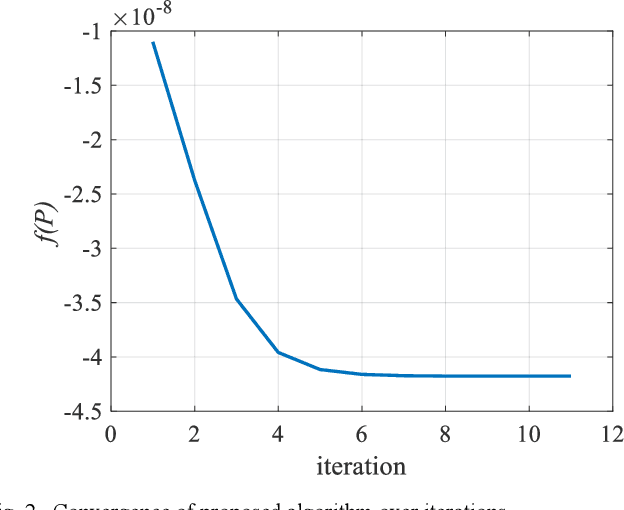
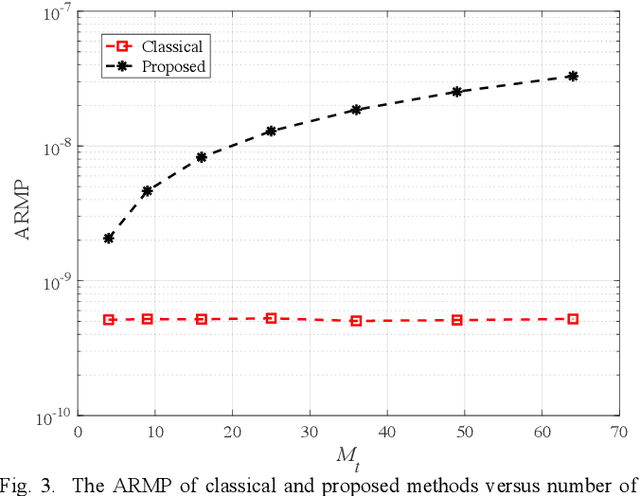
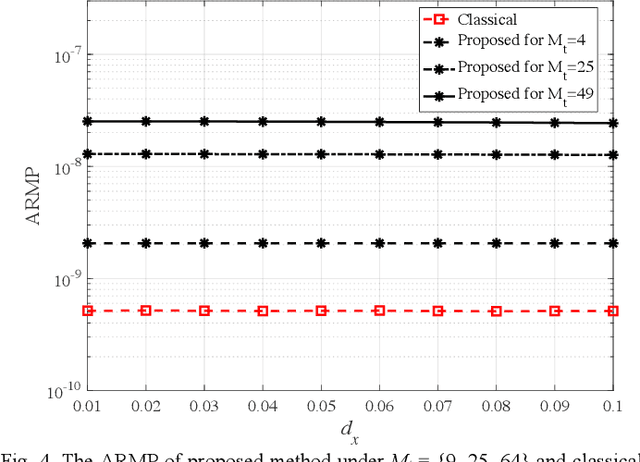
Visible light communication (VLC) is an attractive subset of optical communication that provides a high data rate in the access layer of the network. The combination of multiple inputmultiple output (MIMO) with a VLC system leads to a higher speed of data transmission named as MIMO-VLC system. In multi-user (MU) MIMO-VLC, a LED array transmits signals for users. These signals are categorized as signals of private information for each user and signals of public information for all users. The main idea of this paper is to design an omnidirectional precoding to transmit the signals of public information in the MUMIMO-VLC network. To this end, we propose to maximize the achievable rate which leads to maximizing the received mean power at the possible location of the users. Besides maximizing the achievable rate, we consider equal mean transmission power constraint in all LEDs to achieve higher power efficiency of the power amplifiers used in the LED array. Based on this we formulate an optimization problem in which the constraint is in the form of a manifold and utilize a gradient method projected on the manifold to solve the problem. Simulation results indicate that the proposed omnidirectional precoding can achieve superior received mean power and bit error rate with respect to the classical form without precoding utilization.
Enhancing Biomedical Lay Summarisation with External Knowledge Graphs
Oct 24, 2023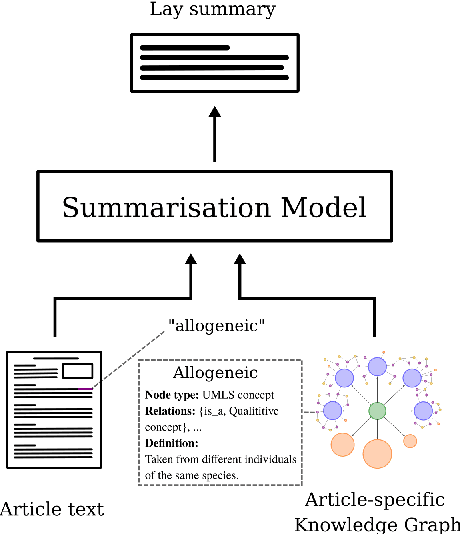

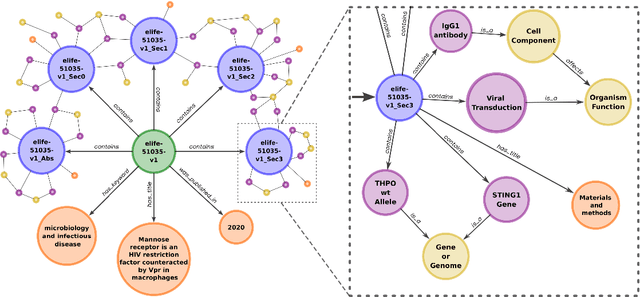
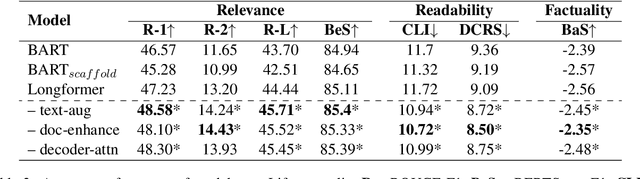
Previous approaches for automatic lay summarisation are exclusively reliant on the source article that, given it is written for a technical audience (e.g., researchers), is unlikely to explicitly define all technical concepts or state all of the background information that is relevant for a lay audience. We address this issue by augmenting eLife, an existing biomedical lay summarisation dataset, with article-specific knowledge graphs, each containing detailed information on relevant biomedical concepts. Using both automatic and human evaluations, we systematically investigate the effectiveness of three different approaches for incorporating knowledge graphs within lay summarisation models, with each method targeting a distinct area of the encoder-decoder model architecture. Our results confirm that integrating graph-based domain knowledge can significantly benefit lay summarisation by substantially increasing the readability of generated text and improving the explanation of technical concepts.
Bridging Code Semantic and LLMs: Semantic Chain-of-Thought Prompting for Code Generation
Oct 22, 2023Large language models (LLMs) have showcased remarkable prowess in code generation. However, automated code generation is still challenging since it requires a high-level semantic mapping between natural language requirements and codes. Most existing LLMs-based approaches for code generation rely on decoder-only causal language models often treate codes merely as plain text tokens, i.e., feeding the requirements as a prompt input, and outputing code as flat sequence of tokens, potentially missing the rich semantic features inherent in source code. To bridge this gap, this paper proposes the "Semantic Chain-of-Thought" approach to intruduce semantic information of code, named SeCoT. Our motivation is that the semantic information of the source code (\eg data flow and control flow) describes more precise program execution behavior, intention and function. By guiding LLM consider and integrate semantic information, we can achieve a more granular understanding and representation of code, enhancing code generation accuracy. Meanwhile, while traditional techniques leveraging such semantic information require complex static or dynamic code analysis to obtain features such as data flow and control flow, SeCoT demonstrates that this process can be fully automated via the intrinsic capabilities of LLMs (i.e., in-context learning), while being generalizable and applicable to challenging domains. While SeCoT can be applied with different LLMs, this paper focuses on the powerful GPT-style models: ChatGPT(close-source model) and WizardCoder(open-source model). The experimental study on three popular DL benchmarks (i.e., HumanEval, HumanEval-ET and MBPP) shows that SeCoT can achieves state-of-the-art performance, greatly improving the potential for large models and code generation.
Debunking Free Fusion Myth: Online Multi-view Anomaly Detection with Disentangled Product-of-Experts Modeling
Oct 31, 2023
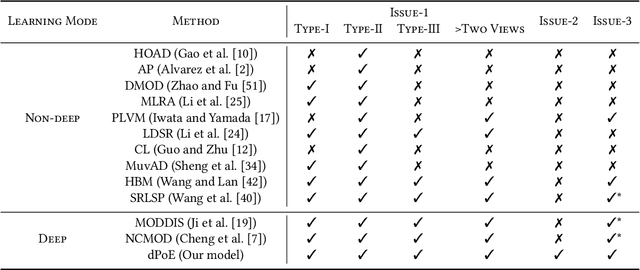
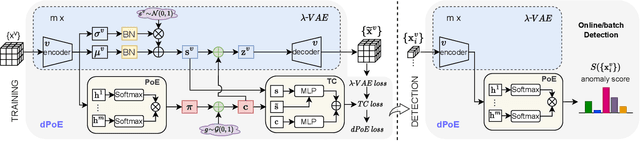
Multi-view or even multi-modal data is appealing yet challenging for real-world applications. Detecting anomalies in multi-view data is a prominent recent research topic. However, most of the existing methods 1) are only suitable for two views or type-specific anomalies, 2) suffer from the issue of fusion disentanglement, and 3) do not support online detection after model deployment. To address these challenges, our main ideas in this paper are three-fold: multi-view learning, disentangled representation learning, and generative model. To this end, we propose dPoE, a novel multi-view variational autoencoder model that involves (1) a Product-of-Experts (PoE) layer in tackling multi-view data, (2) a Total Correction (TC) discriminator in disentangling view-common and view-specific representations, and (3) a joint loss function in wrapping up all components. In addition, we devise theoretical information bounds to control both view-common and view-specific representations. Extensive experiments on six real-world datasets markedly demonstrate that the proposed dPoE outperforms baselines.
FPM-INR: Fourier ptychographic microscopy image stack reconstruction using implicit neural representations
Oct 31, 2023Image stacks provide invaluable 3D information in various biological and pathological imaging applications. Fourier ptychographic microscopy (FPM) enables reconstructing high-resolution, wide field-of-view image stacks without z-stack scanning, thus significantly accelerating image acquisition. However, existing FPM methods take tens of minutes to reconstruct and gigabytes of memory to store a high-resolution volumetric scene, impeding fast gigapixel-scale remote digital pathology. While deep learning approaches have been explored to address this challenge, existing methods poorly generalize to novel datasets and can produce unreliable hallucinations. This work presents FPM-INR, a compact and efficient framework that integrates physics-based optical models with implicit neural representations (INR) to represent and reconstruct FPM image stacks. FPM-INR is agnostic to system design or sample types and does not require external training data. In our demonstrated experiments, FPM-INR substantially outperforms traditional FPM algorithms with up to a 25-fold increase in speed and an 80-fold reduction in memory usage for continuous image stack representations.
LoRAShear: Efficient Large Language Model Structured Pruning and Knowledge Recovery
Oct 31, 2023Large Language Models (LLMs) have transformed the landscape of artificial intelligence, while their enormous size presents significant challenges in terms of computational costs. We introduce LoRAShear, a novel efficient approach to structurally prune LLMs and recover knowledge. Given general LLMs, LoRAShear at first creates the dependency graphs over LoRA modules to discover minimally removal structures and analyze the knowledge distribution. It then proceeds progressive structured pruning on LoRA adaptors and enables inherent knowledge transfer to better preserve the information in the redundant structures. To recover the lost knowledge during pruning, LoRAShear meticulously studies and proposes a dynamic fine-tuning schemes with dynamic data adaptors to effectively narrow down the performance gap to the full models. Numerical results demonstrate that by only using one GPU within a couple of GPU days, LoRAShear effectively reduced footprint of LLMs by 20% with only 1.0% performance degradation and significantly outperforms state-of-the-arts. The source code will be available at https://github.com/microsoft/lorashear.
Linked Papers With Code: The Latest in Machine Learning as an RDF Knowledge Graph
Oct 31, 2023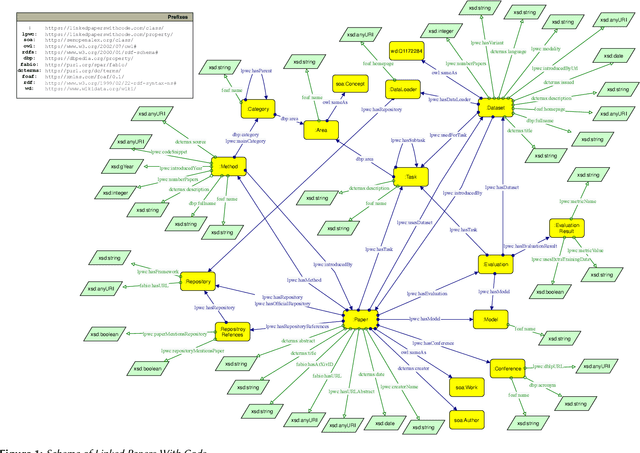

In this paper, we introduce Linked Papers With Code (LPWC), an RDF knowledge graph that provides comprehensive, current information about almost 400,000 machine learning publications. This includes the tasks addressed, the datasets utilized, the methods implemented, and the evaluations conducted, along with their results. Compared to its non-RDF-based counterpart Papers With Code, LPWC not only translates the latest advancements in machine learning into RDF format, but also enables novel ways for scientific impact quantification and scholarly key content recommendation. LPWC is openly accessible at https://linkedpaperswithcode.com and is licensed under CC-BY-SA 4.0. As a knowledge graph in the Linked Open Data cloud, we offer LPWC in multiple formats, from RDF dump files to a SPARQL endpoint for direct web queries, as well as a data source with resolvable URIs and links to the data sources SemOpenAlex, Wikidata, and DBLP. Additionally, we supply knowledge graph embeddings, enabling LPWC to be readily applied in machine learning applications.
GACE: Geometry Aware Confidence Enhancement for Black-Box 3D Object Detectors on LiDAR-Data
Oct 31, 2023Widely-used LiDAR-based 3D object detectors often neglect fundamental geometric information readily available from the object proposals in their confidence estimation. This is mostly due to architectural design choices, which were often adopted from the 2D image domain, where geometric context is rarely available. In 3D, however, considering the object properties and its surroundings in a holistic way is important to distinguish between true and false positive detections, e.g. occluded pedestrians in a group. To address this, we present GACE, an intuitive and highly efficient method to improve the confidence estimation of a given black-box 3D object detector. We aggregate geometric cues of detections and their spatial relationships, which enables us to properly assess their plausibility and consequently, improve the confidence estimation. This leads to consistent performance gains over a variety of state-of-the-art detectors. Across all evaluated detectors, GACE proves to be especially beneficial for the vulnerable road user classes, i.e. pedestrians and cyclists.
LFG: A Generative Network for Real-Time Recommendation
Oct 31, 2023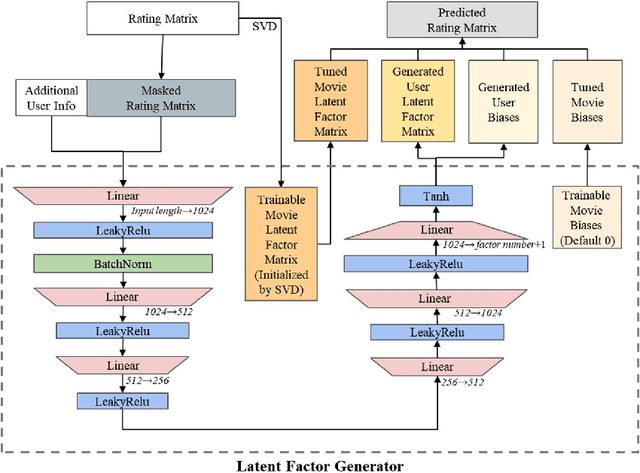
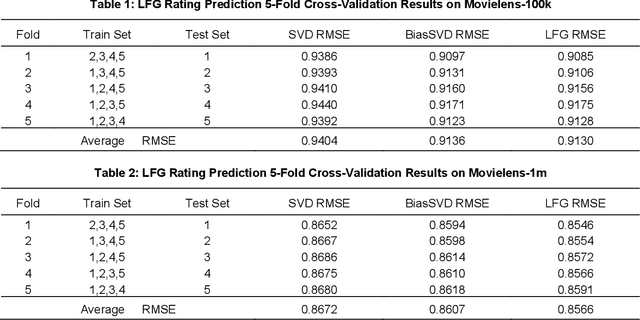
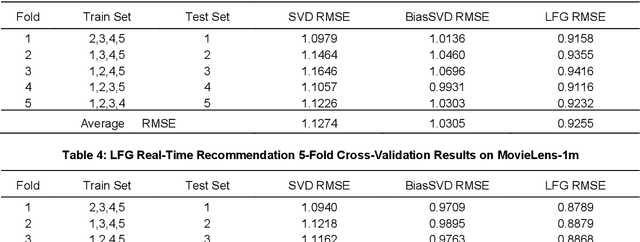

Recommender systems are essential information technologies today, and recommendation algorithms combined with deep learning have become a research hotspot in this field. The recommendation model known as LFM (Latent Factor Model), which captures latent features through matrix factorization and gradient descent to fit user preferences, has given rise to various recommendation algorithms that bring new improvements in recommendation accuracy. However, collaborative filtering recommendation models based on LFM lack flexibility and has shortcomings for real-time recommendations, as they need to redo the matrix factorization and retrain using gradient descent when new users arrive. In response to this, this paper innovatively proposes a Latent Factor Generator (LFG) network, and set the movie recommendation as research theme. The LFG dynamically generates user latent factors through deep neural networks without the need for re-factorization or retrain. Experimental results indicate that the LFG recommendation model outperforms traditional matrix factorization algorithms in recommendation accuracy, providing an effective solution to the challenges of real-time recommendations with LFM.