 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Asymmetric double-winged multi-view clustering network for exploring Diverse and Consistent Information
Sep 01, 2023
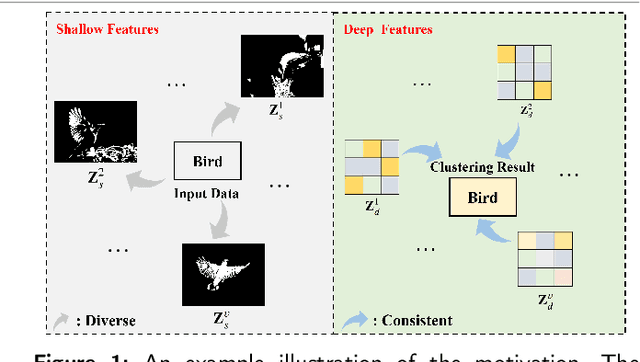
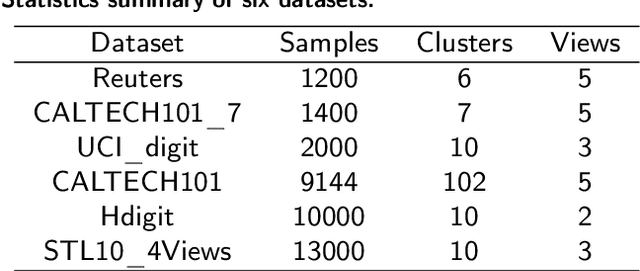
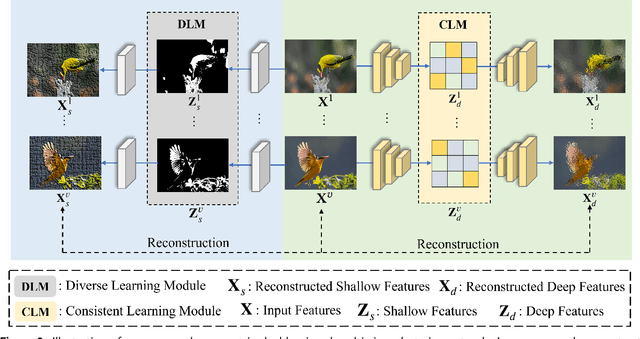
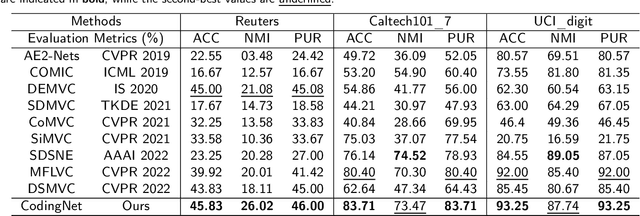
In unsupervised scenarios, deep contrastive multi-view clustering (DCMVC) is becoming a hot research spot, which aims to mine the potential relationships between different views. Most existing DCMVC algorithms focus on exploring the consistency information for the deep semantic features, while ignoring the diverse information on shallow features. To fill this gap, we propose a novel multi-view clustering network termed CodingNet to explore the diverse and consistent information simultaneously in this paper. Specifically, instead of utilizing the conventional auto-encoder, we design an asymmetric structure network to extract shallow and deep features separately. Then, by aligning the similarity matrix on the shallow feature to the zero matrix, we ensure the diversity for the shallow features, thus offering a better description of multi-view data. Moreover, we propose a dual contrastive mechanism that maintains consistency for deep features at both view-feature and pseudo-label levels. Our framework's efficacy is validated through extensive experiments on six widely used benchmark datasets, outperforming most state-of-the-art multi-view clustering algorithms.
Unveil Sleep Spindles with Concentration of Frequency and Time
Oct 27, 2023Objective: Sleep spindles contain crucial brain dynamics information. We introduce the novel non-linear time-frequency analysis tool 'Concentration of Frequency and Time' (ConceFT) to create an interpretable automated algorithm for sleep spindle annotation in EEG data and to measure spindle instantaneous frequencies (IFs). Methods: ConceFT effectively reduces stochastic EEG influence, enhancing spindle visibility in the time-frequency representation. Our automated spindle detection algorithm, ConceFT-Spindle (ConceFT-S), is compared to A7 (non-deep learning) and SUMO (deep learning) using Dream and MASS benchmark databases. We also quantify spindle IF dynamics. Results: ConceFT-S achieves F1 scores of 0.749 in Dream and 0.786 in MASS, which is equivalent to or surpass A7 and SUMO with statistical significance. We reveal that spindle IF is generally nonlinear. Conclusion: ConceFT offers an accurate, interpretable EEG-based sleep spindle detection algorithm and enables spindle IF quantification.
Probing LLMs for hate speech detection: strengths and vulnerabilities
Oct 19, 2023
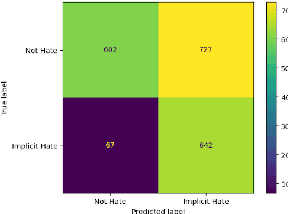
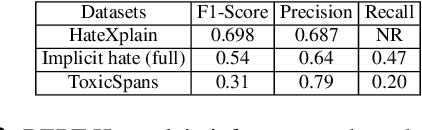
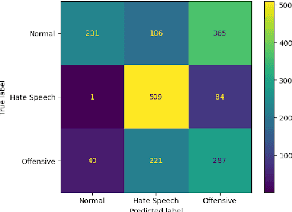
Recently efforts have been made by social media platforms as well as researchers to detect hateful or toxic language using large language models. However, none of these works aim to use explanation, additional context and victim community information in the detection process. We utilise different prompt variation, input information and evaluate large language models in zero shot setting (without adding any in-context examples). We select three large language models (GPT-3.5, text-davinci and Flan-T5) and three datasets - HateXplain, implicit hate and ToxicSpans. We find that on average including the target information in the pipeline improves the model performance substantially (~20-30%) over the baseline across the datasets. There is also a considerable effect of adding the rationales/explanations into the pipeline (~10-20%) over the baseline across the datasets. In addition, we further provide a typology of the error cases where these large language models fail to (i) classify and (ii) explain the reason for the decisions they take. Such vulnerable points automatically constitute 'jailbreak' prompts for these models and industry scale safeguard techniques need to be developed to make the models robust against such prompts.
Exploring OCR Capabilities of GPT-4V(ision) : A Quantitative and In-depth Evaluation
Oct 29, 2023This paper presents a comprehensive evaluation of the Optical Character Recognition (OCR) capabilities of the recently released GPT-4V(ision), a Large Multimodal Model (LMM). We assess the model's performance across a range of OCR tasks, including scene text recognition, handwritten text recognition, handwritten mathematical expression recognition, table structure recognition, and information extraction from visually-rich document. The evaluation reveals that GPT-4V performs well in recognizing and understanding Latin contents, but struggles with multilingual scenarios and complex tasks. Specifically, it showed limitations when dealing with non-Latin languages and complex tasks such as handwriting mathematical expression recognition, table structure recognition, and end-to-end semantic entity recognition and pair extraction from document image. Based on these observations, we affirm the necessity and continued research value of specialized OCR models. In general, despite its versatility in handling diverse OCR tasks, GPT-4V does not outperform existing state-of-the-art OCR models. How to fully utilize pre-trained general-purpose LMMs such as GPT-4V for OCR downstream tasks remains an open problem. The study offers a critical reference for future research in OCR with LMMs. Evaluation pipeline and results are available at https://github.com/SCUT-DLVCLab/GPT-4V_OCR.
Escaping Saddle Points in Heterogeneous Federated Learning via Distributed SGD with Communication Compression
Oct 29, 2023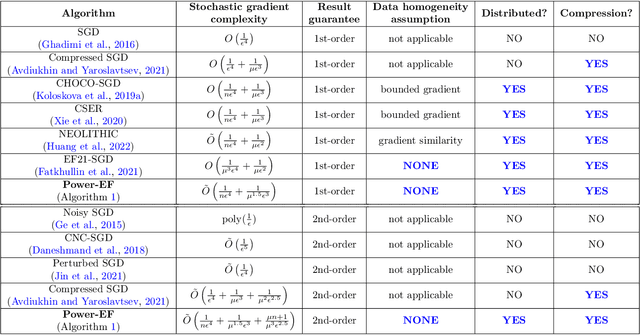
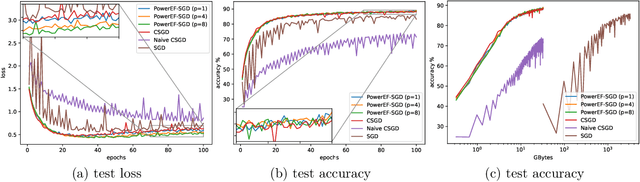

We consider the problem of finding second-order stationary points of heterogeneous federated learning (FL). Previous works in FL mostly focus on first-order convergence guarantees, which do not rule out the scenario of unstable saddle points. Meanwhile, it is a key bottleneck of FL to achieve communication efficiency without compensating the learning accuracy, especially when local data are highly heterogeneous across different clients. Given this, we propose a novel algorithm Power-EF that only communicates compressed information via a novel error-feedback scheme. To our knowledge, Power-EF is the first distributed and compressed SGD algorithm that provably escapes saddle points in heterogeneous FL without any data homogeneity assumptions. In particular, Power-EF improves to second-order stationary points after visiting first-order (possibly saddle) points, using additional gradient queries and communication rounds only of almost the same order required by first-order convergence, and the convergence rate exhibits a linear speedup in terms of the number of workers. Our theory improves/recovers previous results, while extending to much more tolerant settings on the local data. Numerical experiments are provided to complement the theory.
Poisoning Retrieval Corpora by Injecting Adversarial Passages
Oct 29, 2023Dense retrievers have achieved state-of-the-art performance in various information retrieval tasks, but to what extent can they be safely deployed in real-world applications? In this work, we propose a novel attack for dense retrieval systems in which a malicious user generates a small number of adversarial passages by perturbing discrete tokens to maximize similarity with a provided set of training queries. When these adversarial passages are inserted into a large retrieval corpus, we show that this attack is highly effective in fooling these systems to retrieve them for queries that were not seen by the attacker. More surprisingly, these adversarial passages can directly generalize to out-of-domain queries and corpora with a high success attack rate -- for instance, we find that 50 generated passages optimized on Natural Questions can mislead >94% of questions posed in financial documents or online forums. We also benchmark and compare a range of state-of-the-art dense retrievers, both unsupervised and supervised. Although different systems exhibit varying levels of vulnerability, we show they can all be successfully attacked by injecting up to 500 passages, a small fraction compared to a retrieval corpus of millions of passages.
InstanT: Semi-supervised Learning with Instance-dependent Thresholds
Oct 29, 2023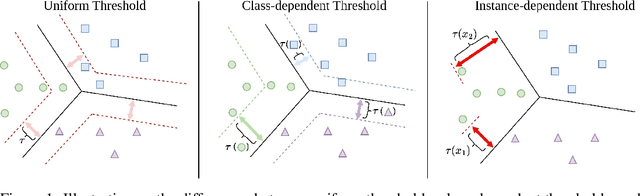
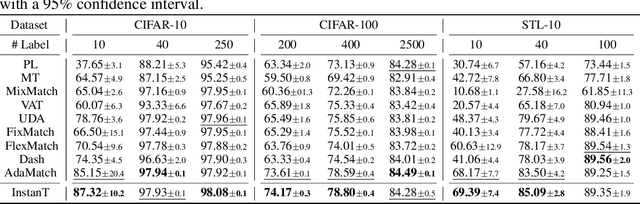
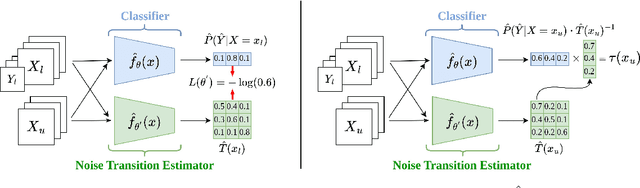

Semi-supervised learning (SSL) has been a fundamental challenge in machine learning for decades. The primary family of SSL algorithms, known as pseudo-labeling, involves assigning pseudo-labels to confident unlabeled instances and incorporating them into the training set. Therefore, the selection criteria of confident instances are crucial to the success of SSL. Recently, there has been growing interest in the development of SSL methods that use dynamic or adaptive thresholds. Yet, these methods typically apply the same threshold to all samples, or use class-dependent thresholds for instances belonging to a certain class, while neglecting instance-level information. In this paper, we propose the study of instance-dependent thresholds, which has the highest degree of freedom compared with existing methods. Specifically, we devise a novel instance-dependent threshold function for all unlabeled instances by utilizing their instance-level ambiguity and the instance-dependent error rates of pseudo-labels, so instances that are more likely to have incorrect pseudo-labels will have higher thresholds. Furthermore, we demonstrate that our instance-dependent threshold function provides a bounded probabilistic guarantee for the correctness of the pseudo-labels it assigns.
Topological, or Non-topological? A Deep Learning Based Prediction
Oct 29, 2023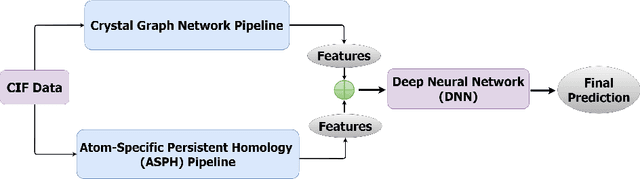
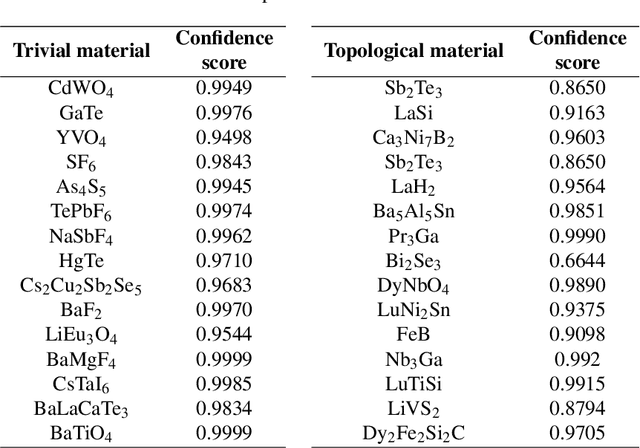
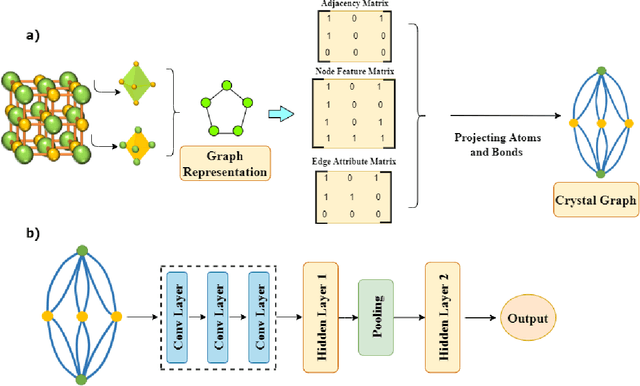
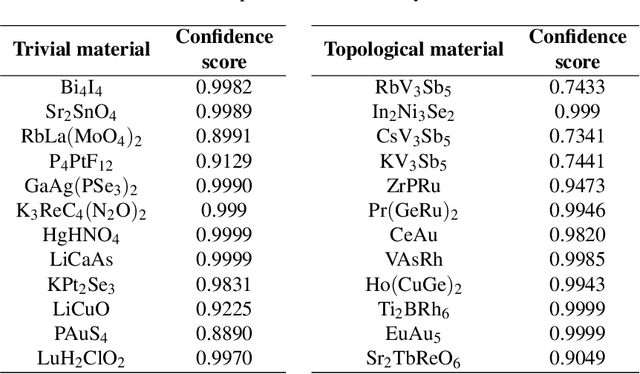
Prediction and discovery of new materials with desired properties are at the forefront of quantum science and technology research. A major bottleneck in this field is the computational resources and time complexity related to finding new materials from ab initio calculations. In this work, an effective and robust deep learning-based model is proposed by incorporating persistent homology and graph neural network which offers an accuracy of 91.4% and an F1 score of 88.5% in classifying topological vs. non-topological materials, outperforming the other state-of-the-art classifier models. The incorporation of the graph neural network encodes the underlying relation between the atoms into the model based on their own crystalline structures and thus proved to be an effective method to represent and process non-euclidean data like molecules with a relatively shallow network. The persistent homology pipeline in the suggested neural network is capable of integrating the atom-specific topological information into the deep learning model, increasing robustness, and gain in performance. It is believed that the presented work will be an efficacious tool for predicting the topological class and therefore enable the high-throughput search for novel materials in this field.
FMRT: Learning Accurate Feature Matching with Reconciliatory Transformer
Oct 20, 2023Local Feature Matching, an essential component of several computer vision tasks (e.g., structure from motion and visual localization), has been effectively settled by Transformer-based methods. However, these methods only integrate long-range context information among keypoints with a fixed receptive field, which constrains the network from reconciling the importance of features with different receptive fields to realize complete image perception, hence limiting the matching accuracy. In addition, these methods utilize a conventional handcrafted encoding approach to integrate the positional information of keypoints into the visual descriptors, which limits the capability of the network to extract reliable positional encoding message. In this study, we propose Feature Matching with Reconciliatory Transformer (FMRT), a novel Transformer-based detector-free method that reconciles different features with multiple receptive fields adaptively and utilizes parallel networks to realize reliable positional encoding. Specifically, FMRT proposes a dedicated Reconciliatory Transformer (RecFormer) that consists of a Global Perception Attention Layer (GPAL) to extract visual descriptors with different receptive fields and integrate global context information under various scales, Perception Weight Layer (PWL) to measure the importance of various receptive fields adaptively, and Local Perception Feed-forward Network (LPFFN) to extract deep aggregated multi-scale local feature representation. Extensive experiments demonstrate that FMRT yields extraordinary performance on multiple benchmarks, including pose estimation, visual localization, homography estimation, and image matching.
Pretraining Language Models with Text-Attributed Heterogeneous Graphs
Oct 23, 2023In many real-world scenarios (e.g., academic networks, social platforms), different types of entities are not only associated with texts but also connected by various relationships, which can be abstracted as Text-Attributed Heterogeneous Graphs (TAHGs). Current pretraining tasks for Language Models (LMs) primarily focus on separately learning the textual information of each entity and overlook the crucial aspect of capturing topological connections among entities in TAHGs. In this paper, we present a new pretraining framework for LMs that explicitly considers the topological and heterogeneous information in TAHGs. Firstly, we define a context graph as neighborhoods of a target node within specific orders and propose a topology-aware pretraining task to predict nodes involved in the context graph by jointly optimizing an LM and an auxiliary heterogeneous graph neural network. Secondly, based on the observation that some nodes are text-rich while others have little text, we devise a text augmentation strategy to enrich textless nodes with their neighbors' texts for handling the imbalance issue. We conduct link prediction and node classification tasks on three datasets from various domains. Experimental results demonstrate the superiority of our approach over existing methods and the rationality of each design. Our code is available at https://github.com/Hope-Rita/THLM.