 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Generating Medical Instructions with Conditional Transformer
Oct 30, 2023
Access to real-world medical instructions is essential for medical research and healthcare quality improvement. However, access to real medical instructions is often limited due to the sensitive nature of the information expressed. Additionally, manually labelling these instructions for training and fine-tuning Natural Language Processing (NLP) models can be tedious and expensive. We introduce a novel task-specific model architecture, Label-To-Text-Transformer (\textbf{LT3}), tailored to generate synthetic medical instructions based on provided labels, such as a vocabulary list of medications and their attributes. LT3 is trained on a vast corpus of medical instructions extracted from the MIMIC-III database, allowing the model to produce valuable synthetic medical instructions. We evaluate LT3's performance by contrasting it with a state-of-the-art Pre-trained Language Model (PLM), T5, analysing the quality and diversity of generated texts. We deploy the generated synthetic data to train the SpacyNER model for the Named Entity Recognition (NER) task over the n2c2-2018 dataset. The experiments show that the model trained on synthetic data can achieve a 96-98\% F1 score at Label Recognition on Drug, Frequency, Route, Strength, and Form. LT3 codes and data will be shared at \url{https://github.com/HECTA-UoM/Label-To-Text-Transformer}
Emotional Theory of Mind: Bridging Fast Visual Processing with Slow Linguistic Reasoning
Oct 30, 2023The emotional theory of mind problem in images is an emotion recognition task, specifically asking "How does the person in the bounding box feel?" Facial expressions, body pose, contextual information and implicit commonsense knowledge all contribute to the difficulty of the task, making this task currently one of the hardest problems in affective computing. The goal of this work is to evaluate the emotional commonsense knowledge embedded in recent large vision language models (CLIP, LLaVA) and large language models (GPT-3.5) on the Emotions in Context (EMOTIC) dataset. In order to evaluate a purely text-based language model on images, we construct "narrative captions" relevant to emotion perception, using a set of 872 physical social signal descriptions related to 26 emotional categories, along with 224 labels for emotionally salient environmental contexts, sourced from writer's guides for character expressions and settings. We evaluate the use of the resulting captions in an image-to-language-to-emotion task. Experiments using zero-shot vision-language models on EMOTIC show that combining "fast" and "slow" reasoning is a promising way forward to improve emotion recognition systems. Nevertheless, a gap remains in the zero-shot emotional theory of mind task compared to prior work trained on the EMOTIC dataset.
BTRec: BERT-Based Trajectory Recommendation for Personalized Tours
Oct 30, 2023
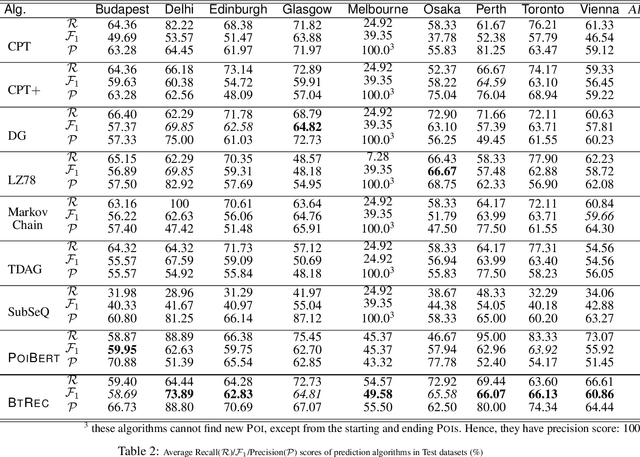
An essential task for tourists having a pleasant holiday is to have a well-planned itinerary with relevant recommendations, especially when visiting unfamiliar cities. Many tour recommendation tools only take into account a limited number of factors, such as popular Points of Interest (POIs) and routing constraints. Consequently, the solutions they provide may not always align with the individual users of the system. We propose an iterative algorithm in this paper, namely: BTREC (BERT-based Trajectory Recommendation), that extends from the POIBERT embedding algorithm to recommend personalized itineraries on POIs using the BERT framework. Our BTREC algorithm incorporates users' demographic information alongside past POI visits into a modified BERT language model to recommend a personalized POI itinerary prediction given a pair of source and destination POIs. Our recommendation system can create a travel itinerary that maximizes POIs visited, while also taking into account user preferences for categories of POIs and time availability. Our recommendation algorithm is largely inspired by the problem of sentence completion in natural language processing (NLP). Using a dataset of eight cities of different sizes, our experimental results demonstrate that our proposed algorithm is stable and outperforms many other sequence prediction algorithms, measured by recall, precision, and F1-scores.
Strategies to Harness the Transformers' Potential: UNSL at eRisk 2023
Oct 30, 2023The CLEF eRisk Laboratory explores solutions to different tasks related to risk detection on the Internet. In the 2023 edition, Task 1 consisted of searching for symptoms of depression, the objective of which was to extract user writings according to their relevance to the BDI Questionnaire symptoms. Task 2 was related to the problem of early detection of pathological gambling risks, where the participants had to detect users at risk as quickly as possible. Finally, Task 3 consisted of estimating the severity levels of signs of eating disorders. Our research group participated in the first two tasks, proposing solutions based on Transformers. For Task 1, we applied different approaches that can be interesting in information retrieval tasks. Two proposals were based on the similarity of contextualized embedding vectors, and the other one was based on prompting, an attractive current technique of machine learning. For Task 2, we proposed three fine-tuned models followed by decision policy according to criteria defined by an early detection framework. One model presented extended vocabulary with important words to the addressed domain. In the last task, we obtained good performances considering the decision-based metrics, ranking-based metrics, and runtime. In this work, we explore different ways to deploy the predictive potential of Transformers in eRisk tasks.
* In Conference and Labs of the Evaluation Forum (CLEF 2023), Thessaloniki, Greece
Ordinal classification for interval-valued data and interval-valued functional data
Oct 30, 2023The aim of ordinal classification is to predict the ordered labels of the output from a set of observed inputs. Interval-valued data refers to data in the form of intervals. For the first time, interval-valued data and interval-valued functional data are considered as inputs in an ordinal classification problem. Six ordinal classifiers for interval data and interval-valued functional data are proposed. Three of them are parametric, one of them is based on ordinal binary decompositions and the other two are based on ordered logistic regression. The other three methods are based on the use of distances between interval data and kernels on interval data. One of the methods uses the weighted $k$-nearest-neighbor technique for ordinal classification. Another method considers kernel principal component analysis plus an ordinal classifier. And the sixth method, which is the method that performs best, uses a kernel-induced ordinal random forest. They are compared with na\"ive approaches in an extensive experimental study with synthetic and original real data sets, about human global development, and weather data. The results show that considering ordering and interval-valued information improves the accuracy. The source code and data sets are available at https://github.com/aleixalcacer/OCFIVD.
Hierarchical Metadata Information Constrained Self-Supervised Learning for Anomalous Sound Detection Under Domain Shift
Sep 14, 2023Self-supervised learning methods have achieved promising performance for anomalous sound detection (ASD) under domain shift, where the type of domain shift is considered in feature learning by incorporating section IDs. However, the attributes accompanying audio files under each section, such as machine operating conditions and noise types, have not been considered, although they are also crucial for characterizing domain shifts. In this paper, we present a hierarchical metadata information constrained self-supervised (HMIC) ASD method, where the hierarchical relation between section IDs and attributes is constructed, and used as constraints to obtain finer feature representation. In addition, we propose an attribute-group-center (AGC)-based method for calculating the anomaly score under the domain shift condition. Experiments are performed to demonstrate its improved performance over the state-of-the-art self-supervised methods in DCASE 2022 challenge Task 2.
Taking control: Policies to address extinction risks from advanced AI
Oct 31, 2023This paper provides policy recommendations to reduce extinction risks from advanced artificial intelligence (AI). First, we briefly provide background information about extinction risks from AI. Second, we argue that voluntary commitments from AI companies would be an inappropriate and insufficient response. Third, we describe three policy proposals that would meaningfully address the threats from advanced AI: (1) establishing a Multinational AGI Consortium to enable democratic oversight of advanced AI (MAGIC), (2) implementing a global cap on the amount of computing power used to train an AI system (global compute cap), and (3) requiring affirmative safety evaluations to ensure that risks are kept below acceptable levels (gating critical experiments). MAGIC would be a secure, safety-focused, internationally-governed institution responsible for reducing risks from advanced AI and performing research to safely harness the benefits of AI. MAGIC would also maintain emergency response infrastructure (kill switch) to swiftly halt AI development or withdraw model deployment in the event of an AI-related emergency. The global compute cap would end the corporate race toward dangerous AI systems while enabling the vast majority of AI innovation to continue unimpeded. Gating critical experiments would ensure that companies developing powerful AI systems are required to present affirmative evidence that these models keep extinction risks below an acceptable threshold. After describing these recommendations, we propose intermediate steps that the international community could take to implement these proposals and lay the groundwork for international coordination around advanced AI.
Amoeba: Circumventing ML-supported Network Censorship via Adversarial Reinforcement Learning
Oct 31, 2023Embedding covert streams into a cover channel is a common approach to circumventing Internet censorship, due to censors' inability to examine encrypted information in otherwise permitted protocols (Skype, HTTPS, etc.). However, recent advances in machine learning (ML) enable detecting a range of anti-censorship systems by learning distinct statistical patterns hidden in traffic flows. Therefore, designing obfuscation solutions able to generate traffic that is statistically similar to innocuous network activity, in order to deceive ML-based classifiers at line speed, is difficult. In this paper, we formulate a practical adversarial attack strategy against flow classifiers as a method for circumventing censorship. Specifically, we cast the problem of finding adversarial flows that will be misclassified as a sequence generation task, which we solve with Amoeba, a novel reinforcement learning algorithm that we design. Amoeba works by interacting with censoring classifiers without any knowledge of their model structure, but by crafting packets and observing the classifiers' decisions, in order to guide the sequence generation process. Our experiments using data collected from two popular anti-censorship systems demonstrate that Amoeba can effectively shape adversarial flows that have on average 94% attack success rate against a range of ML algorithms. In addition, we show that these adversarial flows are robust in different network environments and possess transferability across various ML models, meaning that once trained against one, our agent can subvert other censoring classifiers without retraining.
Brain-like Flexible Visual Inference by Harnessing Feedback-Feedforward Alignment
Oct 31, 2023In natural vision, feedback connections support versatile visual inference capabilities such as making sense of the occluded or noisy bottom-up sensory information or mediating pure top-down processes such as imagination. However, the mechanisms by which the feedback pathway learns to give rise to these capabilities flexibly are not clear. We propose that top-down effects emerge through alignment between feedforward and feedback pathways, each optimizing its own objectives. To achieve this co-optimization, we introduce Feedback-Feedforward Alignment (FFA), a learning algorithm that leverages feedback and feedforward pathways as mutual credit assignment computational graphs, enabling alignment. In our study, we demonstrate the effectiveness of FFA in co-optimizing classification and reconstruction tasks on widely used MNIST and CIFAR10 datasets. Notably, the alignment mechanism in FFA endows feedback connections with emergent visual inference functions, including denoising, resolving occlusions, hallucination, and imagination. Moreover, FFA offers bio-plausibility compared to traditional backpropagation (BP) methods in implementation. By repurposing the computational graph of credit assignment into a goal-driven feedback pathway, FFA alleviates weight transport problems encountered in BP, enhancing the bio-plausibility of the learning algorithm. Our study presents FFA as a promising proof-of-concept for the mechanisms underlying how feedback connections in the visual cortex support flexible visual functions. This work also contributes to the broader field of visual inference underlying perceptual phenomena and has implications for developing more biologically inspired learning algorithms.
Anatomically-aware Uncertainty for Semi-supervised Image Segmentation
Oct 24, 2023
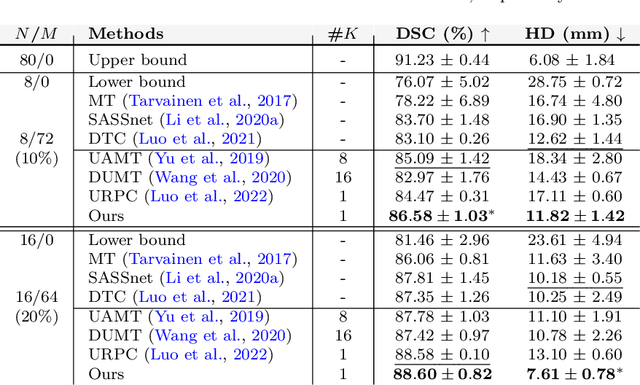
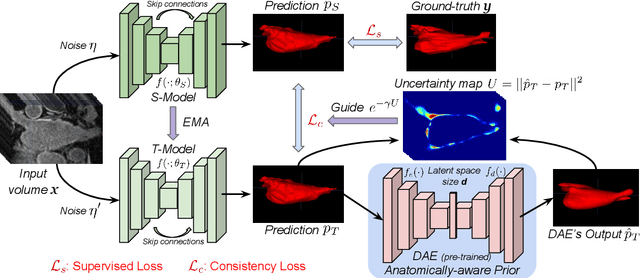
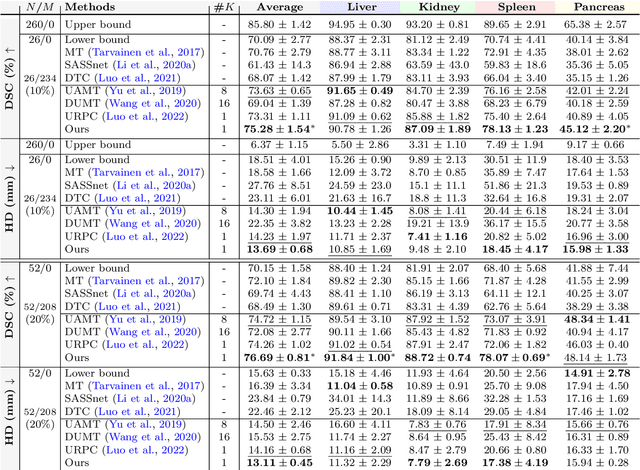
Semi-supervised learning relaxes the need of large pixel-wise labeled datasets for image segmentation by leveraging unlabeled data. A prominent way to exploit unlabeled data is to regularize model predictions. Since the predictions of unlabeled data can be unreliable, uncertainty-aware schemes are typically employed to gradually learn from meaningful and reliable predictions. Uncertainty estimation methods, however, rely on multiple inferences from the model predictions that must be computed for each training step, which is computationally expensive. Moreover, these uncertainty maps capture pixel-wise disparities and do not consider global information. This work proposes a novel method to estimate segmentation uncertainty by leveraging global information from the segmentation masks. More precisely, an anatomically-aware representation is first learnt to model the available segmentation masks. The learnt representation thereupon maps the prediction of a new segmentation into an anatomically-plausible segmentation. The deviation from the plausible segmentation aids in estimating the underlying pixel-level uncertainty in order to further guide the segmentation network. The proposed method consequently estimates the uncertainty using a single inference from our representation, thereby reducing the total computation. We evaluate our method on two publicly available segmentation datasets of left atria in cardiac MRIs and of multiple organs in abdominal CTs. Our anatomically-aware method improves the segmentation accuracy over the state-of-the-art semi-supervised methods in terms of two commonly used evaluation metrics.