 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Heterogeneous Contrastive Learning for Foundation Models and Beyond
Mar 30, 2024
In the era of big data and Artificial Intelligence, an emerging paradigm is to utilize contrastive self-supervised learning to model large-scale heterogeneous data. Many existing foundation models benefit from the generalization capability of contrastive self-supervised learning by learning compact and high-quality representations without relying on any label information. Amidst the explosive advancements in foundation models across multiple domains, including natural language processing and computer vision, a thorough survey on heterogeneous contrastive learning for the foundation model is urgently needed. In response, this survey critically evaluates the current landscape of heterogeneous contrastive learning for foundation models, highlighting the open challenges and future trends of contrastive learning. In particular, we first present how the recent advanced contrastive learning-based methods deal with view heterogeneity and how contrastive learning is applied to train and fine-tune the multi-view foundation models. Then, we move to contrastive learning methods for task heterogeneity, including pretraining tasks and downstream tasks, and show how different tasks are combined with contrastive learning loss for different purposes. Finally, we conclude this survey by discussing the open challenges and shedding light on the future directions of contrastive learning.
EventGround: Narrative Reasoning by Grounding to Eventuality-centric Knowledge Graphs
Mar 30, 2024Narrative reasoning relies on the understanding of eventualities in story contexts, which requires a wealth of background world knowledge. To help machines leverage such knowledge, existing solutions can be categorized into two groups. Some focus on implicitly modeling eventuality knowledge by pretraining language models (LMs) with eventuality-aware objectives. However, this approach breaks down knowledge structures and lacks interpretability. Others explicitly collect world knowledge of eventualities into structured eventuality-centric knowledge graphs (KGs). However, existing research on leveraging these knowledge sources for free-texts is limited. In this work, we propose an initial comprehensive framework called EventGround, which aims to tackle the problem of grounding free-texts to eventuality-centric KGs for contextualized narrative reasoning. We identify two critical problems in this direction: the event representation and sparsity problems. We provide simple yet effective parsing and partial information extraction methods to tackle these problems. Experimental results demonstrate that our approach consistently outperforms baseline models when combined with graph neural network (GNN) or large language model (LLM) based graph reasoning models. Our framework, incorporating grounded knowledge, achieves state-of-the-art performance while providing interpretable evidence.
LLMs Are Few-Shot In-Context Low-Resource Language Learners
Mar 27, 2024In-context learning (ICL) empowers large language models (LLMs) to perform diverse tasks in underrepresented languages using only short in-context information, offering a crucial avenue for narrowing the gap between high-resource and low-resource languages. Nonetheless, there is only a handful of works explored ICL for low-resource languages with most of them focusing on relatively high-resource languages, such as French and Spanish. In this work, we extensively study ICL and its cross-lingual variation (X-ICL) on 25 low-resource and 7 relatively higher-resource languages. Our study not only assesses the effectiveness of ICL with LLMs in low-resource languages but also identifies the shortcomings of in-context label alignment, and introduces a more effective alternative: query alignment. Moreover, we provide valuable insights into various facets of ICL for low-resource languages. Our study concludes the significance of few-shot in-context information on enhancing the low-resource understanding quality of LLMs through semantically relevant information by closing the language gap in the target language and aligning the semantics between the targeted low-resource and the high-resource language that the model is proficient in. Our work highlights the importance of advancing ICL research, particularly for low-resource languages.
Common Sense Enhanced Knowledge-based Recommendation with Large Language Model
Mar 27, 2024Knowledge-based recommendation models effectively alleviate the data sparsity issue leveraging the side information in the knowledge graph, and have achieved considerable performance. Nevertheless, the knowledge graphs used in previous work, namely metadata-based knowledge graphs, are usually constructed based on the attributes of items and co-occurring relations (e.g., also buy), in which the former provides limited information and the latter relies on sufficient interaction data and still suffers from cold start issue. Common sense, as a form of knowledge with generality and universality, can be used as a supplement to the metadata-based knowledge graph and provides a new perspective for modeling users' preferences. Recently, benefiting from the emergent world knowledge of the large language model, efficient acquisition of common sense has become possible. In this paper, we propose a novel knowledge-based recommendation framework incorporating common sense, CSRec, which can be flexibly coupled to existing knowledge-based methods. Considering the challenge of the knowledge gap between the common sense-based knowledge graph and metadata-based knowledge graph, we propose a knowledge fusion approach based on mutual information maximization theory. Experimental results on public datasets demonstrate that our approach significantly improves the performance of existing knowledge-based recommendation models.
The Solution for the ICCV 2023 1st Scientific Figure Captioning Challenge
Mar 26, 2024In this paper, we propose a solution for improving the quality of captions generated for figures in papers. We adopt the approach of summarizing the textual content in the paper to generate image captions. Throughout our study, we encounter discrepancies in the OCR information provided in the official dataset. To rectify this, we employ the PaddleOCR toolkit to extract OCR information from all images. Moreover, we observe that certain textual content in the official paper pertains to images that are not relevant for captioning, thereby introducing noise during caption generation. To mitigate this issue, we leverage LLaMA to extract image-specific information by querying the textual content based on image mentions, effectively filtering out extraneous information. Additionally, we recognize a discrepancy between the primary use of maximum likelihood estimation during text generation and the evaluation metrics such as ROUGE employed to assess the quality of generated captions. To bridge this gap, we integrate the BRIO model framework, enabling a more coherent alignment between the generation and evaluation processes. Our approach ranked first in the final test with a score of 4.49.
Inferring Latent Temporal Sparse Coordination Graph for Multi-Agent Reinforcement Learning
Mar 28, 2024Effective agent coordination is crucial in cooperative Multi-Agent Reinforcement Learning (MARL). While agent cooperation can be represented by graph structures, prevailing graph learning methods in MARL are limited. They rely solely on one-step observations, neglecting crucial historical experiences, leading to deficient graphs that foster redundant or detrimental information exchanges. Additionally, high computational demands for action-pair calculations in dense graphs impede scalability. To address these challenges, we propose inferring a Latent Temporal Sparse Coordination Graph (LTS-CG) for MARL. The LTS-CG leverages agents' historical observations to calculate an agent-pair probability matrix, where a sparse graph is sampled from and used for knowledge exchange between agents, thereby simultaneously capturing agent dependencies and relation uncertainty. The computational complexity of this procedure is only related to the number of agents. This graph learning process is further augmented by two innovative characteristics: Predict-Future, which enables agents to foresee upcoming observations, and Infer-Present, ensuring a thorough grasp of the environmental context from limited data. These features allow LTS-CG to construct temporal graphs from historical and real-time information, promoting knowledge exchange during policy learning and effective collaboration. Graph learning and agent training occur simultaneously in an end-to-end manner. Our demonstrated results on the StarCraft II benchmark underscore LTS-CG's superior performance.
Classification of Short Segment Pediatric Heart Sounds Based on a Transformer-Based Convolutional Neural Network
Mar 30, 2024Congenital anomalies arising as a result of a defect in the structure of the heart and great vessels are known as congenital heart diseases or CHDs. A PCG can provide essential details about the mechanical conduction system of the heart and point out specific patterns linked to different kinds of CHD. This study aims to investigate the minimum signal duration required for the automatic classification of heart sounds. This study also investigated the optimum signal quality assessment indicator (Root Mean Square of Successive Differences) RMSSD and (Zero Crossings Rate) ZCR value. Mel-frequency cepstral coefficients (MFCCs) based feature is used as an input to build a Transformer-Based residual one-dimensional convolutional neural network, which is then used for classifying the heart sound. The study showed that 0.4 is the ideal threshold for getting suitable signals for the RMSSD and ZCR indicators. Moreover, a minimum signal length of 5s is required for effective heart sound classification. It also shows that a shorter signal (3 s heart sound) does not have enough information to categorize heart sounds accurately, and the longer signal (15 s heart sound) may contain more noise. The best accuracy, 93.69%, is obtained for the 5s signal to distinguish the heart sound.
Hypergraph-based Multi-View Action Recognition using Event Cameras
Mar 28, 2024Action recognition from video data forms a cornerstone with wide-ranging applications. Single-view action recognition faces limitations due to its reliance on a single viewpoint. In contrast, multi-view approaches capture complementary information from various viewpoints for improved accuracy. Recently, event cameras have emerged as innovative bio-inspired sensors, leading to advancements in event-based action recognition. However, existing works predominantly focus on single-view scenarios, leaving a gap in multi-view event data exploitation, particularly in challenges like information deficit and semantic misalignment. To bridge this gap, we introduce HyperMV, a multi-view event-based action recognition framework. HyperMV converts discrete event data into frame-like representations and extracts view-related features using a shared convolutional network. By treating segments as vertices and constructing hyperedges using rule-based and KNN-based strategies, a multi-view hypergraph neural network that captures relationships across viewpoint and temporal features is established. The vertex attention hypergraph propagation is also introduced for enhanced feature fusion. To prompt research in this area, we present the largest multi-view event-based action dataset $\text{THU}^{\text{MV-EACT}}\text{-50}$, comprising 50 actions from 6 viewpoints, which surpasses existing datasets by over tenfold. Experimental results show that HyperMV significantly outperforms baselines in both cross-subject and cross-view scenarios, and also exceeds the state-of-the-arts in frame-based multi-view action recognition.
H2ASeg: Hierarchical Adaptive Interaction and Weighting Network for Tumor Segmentation in PET/CT Images
Mar 28, 2024Positron emission tomography (PET) combined with computed tomography (CT) imaging is routinely used in cancer diagnosis and prognosis by providing complementary information. Automatically segmenting tumors in PET/CT images can significantly improve examination efficiency. Traditional multi-modal segmentation solutions mainly rely on concatenation operations for modality fusion, which fail to effectively model the non-linear dependencies between PET and CT modalities. Recent studies have investigated various approaches to optimize the fusion of modality-specific features for enhancing joint representations. However, modality-specific encoders used in these methods operate independently, inadequately leveraging the synergistic relationships inherent in PET and CT modalities, for example, the complementarity between semantics and structure. To address these issues, we propose a Hierarchical Adaptive Interaction and Weighting Network termed H2ASeg to explore the intrinsic cross-modal correlations and transfer potential complementary information. Specifically, we design a Modality-Cooperative Spatial Attention (MCSA) module that performs intra- and inter-modal interactions globally and locally. Additionally, a Target-Aware Modality Weighting (TAMW) module is developed to highlight tumor-related features within multi-modal features, thereby refining tumor segmentation. By embedding these modules across different layers, H2ASeg can hierarchically model cross-modal correlations, enabling a nuanced understanding of both semantic and structural tumor features. Extensive experiments demonstrate the superiority of H2ASeg, outperforming state-of-the-art methods on AutoPet-II and Hecktor2022 benchmarks. The code is released at https://github.com/JinPLu/H2ASeg.
HIMap: HybrId Representation Learning for End-to-end Vectorized HD Map Construction
Mar 26, 2024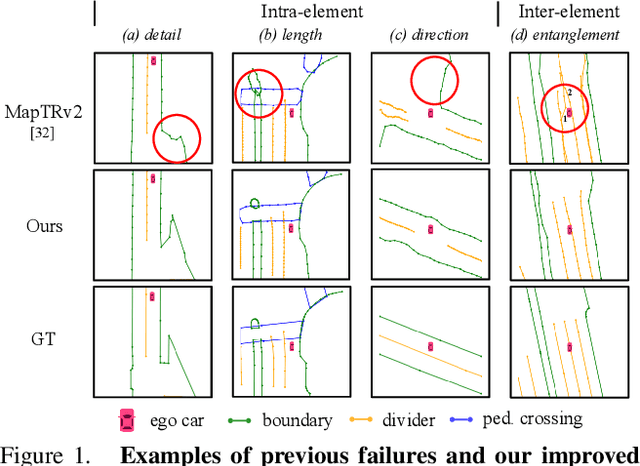
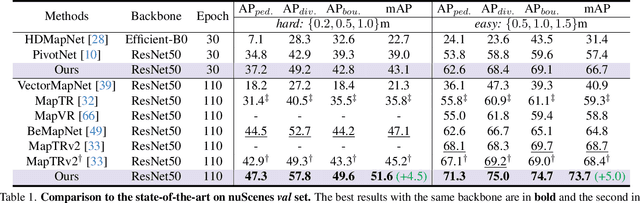
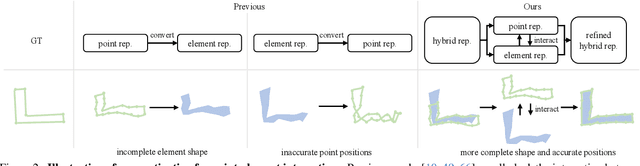
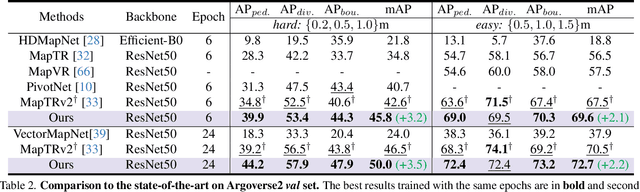
Vectorized High-Definition (HD) map construction requires predictions of the category and point coordinates of map elements (e.g. road boundary, lane divider, pedestrian crossing, etc.). State-of-the-art methods are mainly based on point-level representation learning for regressing accurate point coordinates. However, this pipeline has limitations in obtaining element-level information and handling element-level failures, e.g. erroneous element shape or entanglement between elements. To tackle the above issues, we propose a simple yet effective HybrId framework named HIMap to sufficiently learn and interact both point-level and element-level information. Concretely, we introduce a hybrid representation called HIQuery to represent all map elements, and propose a point-element interactor to interactively extract and encode the hybrid information of elements, e.g. point position and element shape, into the HIQuery. Additionally, we present a point-element consistency constraint to enhance the consistency between the point-level and element-level information. Finally, the output point-element integrated HIQuery can be directly converted into map elements' class, point coordinates, and mask. We conduct extensive experiments and consistently outperform previous methods on both nuScenes and Argoverse2 datasets. Notably, our method achieves $77.8$ mAP on the nuScenes dataset, remarkably superior to previous SOTAs by $8.3$ mAP at least.