 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LISNeRF Mapping: LiDAR-based Implicit Mapping via Semantic Neural Fields for Large-Scale 3D Scenes
Nov 04, 2023
Large-scale semantic mapping is crucial for outdoor autonomous agents to fulfill high-level tasks such as planning and navigation. This paper proposes a novel method for large-scale 3D semantic reconstruction through implicit representations from LiDAR measurements alone. We firstly leverages an octree-based and hierarchical structure to store implicit features, then these implicit features are decoded to semantic information and signed distance value through shallow Multilayer Perceptrons (MLPs). We adopt off-the-shelf algorithms to predict the semantic labels and instance IDs of point cloud. Then we jointly optimize the implicit features and MLPs parameters with self-supervision paradigm for point cloud geometry and pseudo-supervision pradigm for semantic and panoptic labels. Subsequently, Marching Cubes algorithm is exploited to subdivide and visualize the scenes in the inferring stage. For scenarios with memory constraints, a map stitching strategy is also developed to merge sub-maps into a complete map. As far as we know, our method is the first work to reconstruct semantic implicit scenes from LiDAR-only input. Experiments on three real-world datasets, SemanticKITTI, SemanticPOSS and nuScenes, demonstrate the effectiveness and efficiency of our framework compared to current state-of-the-art 3D mapping methods.
Multi-State Brain Network Discovery
Nov 04, 2023Brain network discovery aims to find nodes and edges from the spatio-temporal signals obtained by neuroimaging data, such as fMRI scans of human brains. Existing methods tend to derive representative or average brain networks, assuming observed signals are generated by only a single brain activity state. However, the human brain usually involves multiple activity states, which jointly determine the brain activities. The brain regions and their connectivity usually exhibit intricate patterns that are difficult to capture with only a single-state network. Recent studies find that brain parcellation and connectivity change according to the brain activity state. We refer to such brain networks as multi-state, and this mixture can help us understand human behavior. Thus, compared to a single-state network, a multi-state network can prevent us from losing crucial information of cognitive brain network. To achieve this, we propose a new model called MNGL (Multi-state Network Graphical Lasso), which successfully models multi-state brain networks by combining CGL (coherent graphical lasso) with GMM (Gaussian Mixture Model). Using both synthetic and real world ADHD 200 fMRI datasets, we demonstrate that MNGL outperforms recent state-of-the-art alternatives by discovering more explanatory and realistic results.
Multitask Online Learning: Listen to the Neighborhood Buzz
Oct 26, 2023We study multitask online learning in a setting where agents can only exchange information with their neighbors on an arbitrary communication network. We introduce $\texttt{MT-CO}_2\texttt{OL}$, a decentralized algorithm for this setting whose regret depends on the interplay between the task similarities and the network structure. Our analysis shows that the regret of $\texttt{MT-CO}_2\texttt{OL}$ is never worse (up to constants) than the bound obtained when agents do not share information. On the other hand, our bounds significantly improve when neighboring agents operate on similar tasks. In addition, we prove that our algorithm can be made differentially private with a negligible impact on the regret when the losses are linear. Finally, we provide experimental support for our theory.
Astrocytes as a mechanism for meta-plasticity and contextually-guided network function
Nov 06, 2023Astrocytes are a highly expressed and highly enigmatic cell-type in the mammalian brain. Traditionally viewed as a mediator of basic physiological sustenance, it is increasingly recognized that astrocytes may play a more direct role in neural computation. A conceptual challenge to this idea is the fact that astrocytic activity takes a very different form than that of neurons, and in particular, occurs at orders-of-magnitude slower time-scales. In the current paper, we engage how such time-scale separation may endow astrocytes with the capability to enable learning in context-dependent settings, where fluctuations in task parameters may occur much more slowly than within-task requirements. This idea is based on the recent supposition that astrocytes, owing to their sensitivity to a host of physiological covariates, may be particularly well poised to modulate the dynamics of neural circuits in functionally salient ways. We pose a general model of neural-synaptic-astrocyte interaction and use formal analysis to characterize how astrocytic modulation may constitute a form of meta-plasticity, altering the ways in which synapses and neurons adapt as a function of time. We then embed this model in a bandit-based reinforcement learning task environment, and show how the presence of time-scale separated astrocytic modulation enables learning over multiple fluctuating contexts. Indeed, these networks learn far more reliably versus dynamically homogenous networks and conventional non-network-based bandit algorithms. Our results indicate how the presence of neural-astrocyte interaction in the brain may benefit learning over different time-scale and the conveyance of task relevant contextual information onto circuit dynamics.
Multi Loss-based Feature Fusion and Top Two Voting Ensemble Decision Strategy for Facial Expression Recognition in the Wild
Nov 06, 2023Facial expression recognition (FER) in the wild is a challenging task affected by the image quality and has attracted broad interest in computer vision. There is no research using feature fusion and ensemble strategy for FER simultaneously. Different from previous studies, this paper applies both internal feature fusion for a single model and feature fusion among multiple networks, as well as the ensemble strategy. This paper proposes one novel single model named R18+FAML, as well as one ensemble model named R18+FAML-FGA-T2V to improve the performance of the FER in the wild. Based on the structure of ResNet18 (R18), R18+FAML combines internal Feature fusion and three Attention blocks using Multiple Loss functions (FAML) to improve the diversity of the feature extraction. To improve the performance of R18+FAML, we propose a Feature fusion among networks based on the Genetic Algorithm (FGA), which can fuse the convolution kernels for feature extraction of multiple networks. On the basis of R18+FAML and FGA, we propose one ensemble strategy, i.e., the Top Two Voting (T2V) to support the classification of FER, which can consider more classification information comprehensively. Combining the above strategies, R18+FAML-FGA-T2V can focus on the main expression-aware areas. Extensive experiments demonstrate that our single model R18+FAML and the ensemble model R18+FAML-FGA-T2V achieve the accuracies of $\left( 90.32, 62.17, 65.83 \right)\%$ and $\left( 91.59, 63.27, 66.63 \right)\%$ on three challenging unbalanced FER datasets RAF-DB, AffectNet-8 and AffectNet-7 respectively, both outperforming the state-of-the-art results.
Episodic Multi-Task Learning with Heterogeneous Neural Processes
Oct 28, 2023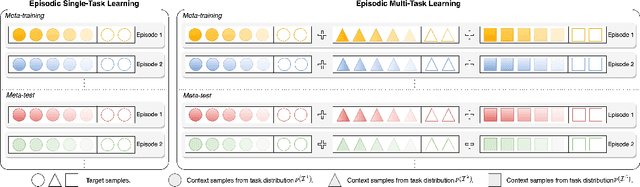
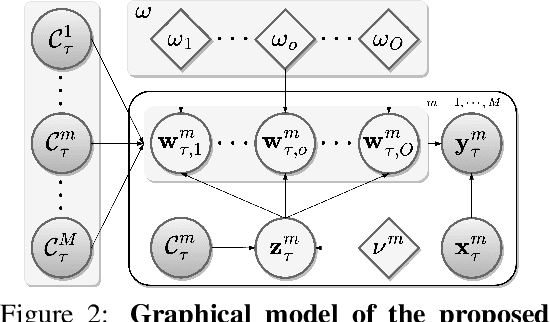
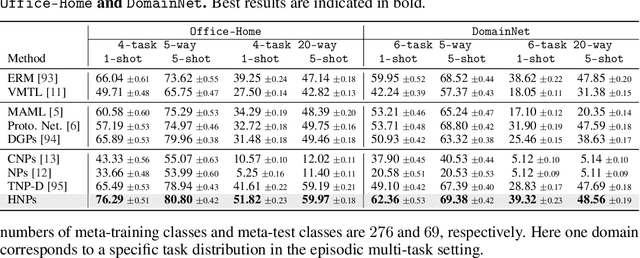
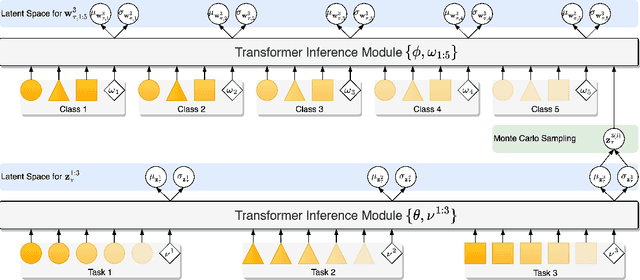
This paper focuses on the data-insufficiency problem in multi-task learning within an episodic training setup. Specifically, we explore the potential of heterogeneous information across tasks and meta-knowledge among episodes to effectively tackle each task with limited data. Existing meta-learning methods often fail to take advantage of crucial heterogeneous information in a single episode, while multi-task learning models neglect reusing experience from earlier episodes. To address the problem of insufficient data, we develop Heterogeneous Neural Processes (HNPs) for the episodic multi-task setup. Within the framework of hierarchical Bayes, HNPs effectively capitalize on prior experiences as meta-knowledge and capture task-relatedness among heterogeneous tasks, mitigating data-insufficiency. Meanwhile, transformer-structured inference modules are designed to enable efficient inferences toward meta-knowledge and task-relatedness. In this way, HNPs can learn more powerful functional priors for adapting to novel heterogeneous tasks in each meta-test episode. Experimental results show the superior performance of the proposed HNPs over typical baselines, and ablation studies verify the effectiveness of the designed inference modules.
TFNet: Tuning Fork Network with Neighborhood Pixel Aggregation for Improved Building Footprint Extraction
Nov 05, 2023This paper considers the problem of extracting building footprints from satellite imagery -- a task that is critical for many urban planning and decision-making applications. While recent advancements in deep learning have made great strides in automated detection of building footprints, state-of-the-art methods available in existing literature often generate erroneous results for areas with densely connected buildings. Moreover, these methods do not incorporate the context of neighborhood images during training thus generally resulting in poor performance at image boundaries. In light of these gaps, we propose a novel Tuning Fork Network (TFNet) design for deep semantic segmentation that not only performs well for widely-spaced building but also has good performance for buildings that are closely packed together. The novelty of TFNet architecture lies in a a single encoder followed by two parallel decoders to separately reconstruct the building footprint and the building edge. In addition, the TFNet design is coupled with a novel methodology of incorporating neighborhood information at the tile boundaries during the training process. This methodology further improves performance, especially at the tile boundaries. For performance comparisons, we utilize the SpaceNet2 and WHU datasets, as well as a dataset from an area in Lahore, Pakistan that captures closely connected buildings. For all three datasets, the proposed methodology is found to significantly outperform benchmark methods.
3D-Aware Talking-Head Video Motion Transfer
Nov 05, 2023Motion transfer of talking-head videos involves generating a new video with the appearance of a subject video and the motion pattern of a driving video. Current methodologies primarily depend on a limited number of subject images and 2D representations, thereby neglecting to fully utilize the multi-view appearance features inherent in the subject video. In this paper, we propose a novel 3D-aware talking-head video motion transfer network, Head3D, which fully exploits the subject appearance information by generating a visually-interpretable 3D canonical head from the 2D subject frames with a recurrent network. A key component of our approach is a self-supervised 3D head geometry learning module, designed to predict head poses and depth maps from 2D subject video frames. This module facilitates the estimation of a 3D head in canonical space, which can then be transformed to align with driving video frames. Additionally, we employ an attention-based fusion network to combine the background and other details from subject frames with the 3D subject head to produce the synthetic target video. Our extensive experiments on two public talking-head video datasets demonstrate that Head3D outperforms both 2D and 3D prior arts in the practical cross-identity setting, with evidence showing it can be readily adapted to the pose-controllable novel view synthesis task.
Construction Artifacts in Metaphor Identification Datasets
Nov 01, 2023Metaphor identification aims at understanding whether a given expression is used figuratively in context. However, in this paper we show how existing metaphor identification datasets can be gamed by fully ignoring the potential metaphorical expression or the context in which it occurs. We test this hypothesis in a variety of datasets and settings, and show that metaphor identification systems based on language models without complete information can be competitive with those using the full context. This is due to the construction procedures to build such datasets, which introduce unwanted biases for positive and negative classes. Finally, we test the same hypothesis on datasets that are carefully sampled from natural corpora and where this bias is not present, making these datasets more challenging and reliable.
CAD -- Contextual Multi-modal Alignment for Dynamic AVQA
Oct 25, 2023In the context of Audio Visual Question Answering (AVQA) tasks, the audio visual modalities could be learnt on three levels: 1) Spatial, 2) Temporal, and 3) Semantic. Existing AVQA methods suffer from two major shortcomings; the audio-visual (AV) information passing through the network isn't aligned on Spatial and Temporal levels; and, inter-modal (audio and visual) Semantic information is often not balanced within a context; this results in poor performance. In this paper, we propose a novel end-to-end Contextual Multi-modal Alignment (CAD) network that addresses the challenges in AVQA methods by i) introducing a parameter-free stochastic Contextual block that ensures robust audio and visual alignment on the Spatial level; ii) proposing a pre-training technique for dynamic audio and visual alignment on Temporal level in a self-supervised setting, and iii) introducing a cross-attention mechanism to balance audio and visual information on Semantic level. The proposed novel CAD network improves the overall performance over the state-of-the-art methods on average by 9.4% on the MUSIC-AVQA dataset. We also demonstrate that our proposed contributions to AVQA can be added to the existing methods to improve their performance without additional complexity requirements.