 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Generic Anomaly Detection and Understanding: Large-scale Visual-linguistic Model (GPT-4V) Takes the Lead
Nov 05, 2023
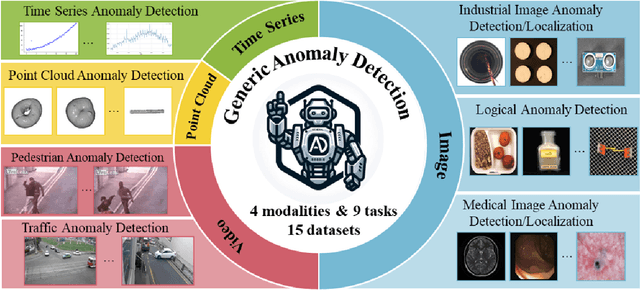
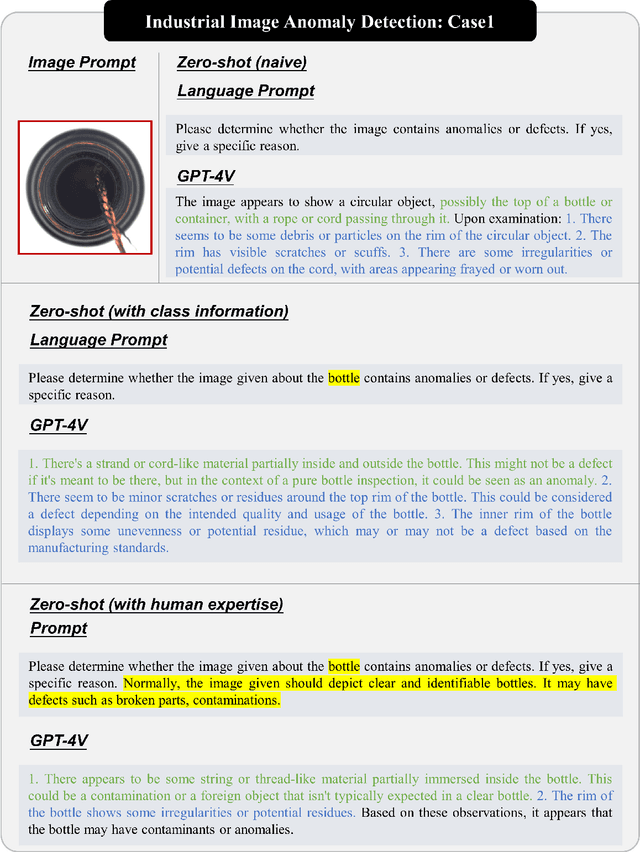

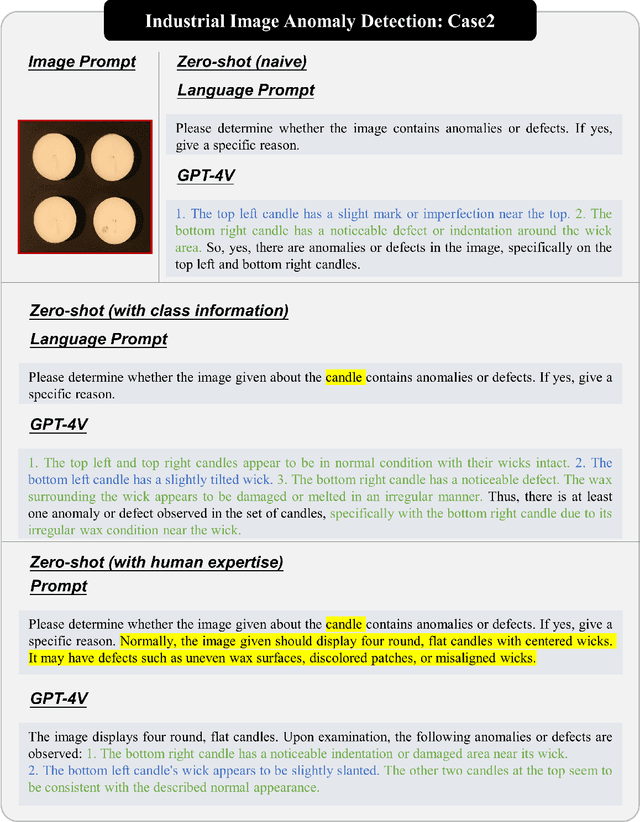
Anomaly detection is a crucial task across different domains and data types. However, existing anomaly detection models are often designed for specific domains and modalities. This study explores the use of GPT-4V(ision), a powerful visual-linguistic model, to address anomaly detection tasks in a generic manner. We investigate the application of GPT-4V in multi-modality, multi-domain anomaly detection tasks, including image, video, point cloud, and time series data, across multiple application areas, such as industrial, medical, logical, video, 3D anomaly detection, and localization tasks. To enhance GPT-4V's performance, we incorporate different kinds of additional cues such as class information, human expertise, and reference images as prompts.Based on our experiments, GPT-4V proves to be highly effective in detecting and explaining global and fine-grained semantic patterns in zero/one-shot anomaly detection. This enables accurate differentiation between normal and abnormal instances. Although we conducted extensive evaluations in this study, there is still room for future evaluation to further exploit GPT-4V's generic anomaly detection capacity from different aspects. These include exploring quantitative metrics, expanding evaluation benchmarks, incorporating multi-round interactions, and incorporating human feedback loops. Nevertheless, GPT-4V exhibits promising performance in generic anomaly detection and understanding, thus opening up a new avenue for anomaly detection.
AV-Lip-Sync+: Leveraging AV-HuBERT to Exploit Multimodal Inconsistency for Video Deepfake Detection
Nov 05, 2023Multimodal manipulations (also known as audio-visual deepfakes) make it difficult for unimodal deepfake detectors to detect forgeries in multimedia content. To avoid the spread of false propaganda and fake news, timely detection is crucial. The damage to either modality (i.e., visual or audio) can only be discovered through multi-modal models that can exploit both pieces of information simultaneously. Previous methods mainly adopt uni-modal video forensics and use supervised pre-training for forgery detection. This study proposes a new method based on a multi-modal self-supervised-learning (SSL) feature extractor to exploit inconsistency between audio and visual modalities for multi-modal video forgery detection. We use the transformer-based SSL pre-trained Audio-Visual HuBERT (AV-HuBERT) model as a visual and acoustic feature extractor and a multi-scale temporal convolutional neural network to capture the temporal correlation between the audio and visual modalities. Since AV-HuBERT only extracts visual features from the lip region, we also adopt another transformer-based video model to exploit facial features and capture spatial and temporal artifacts caused during the deepfake generation process. Experimental results show that our model outperforms all existing models and achieves new state-of-the-art performance on the FakeAVCeleb and DeepfakeTIMIT datasets.
Noise-Robust Fine-Tuning of Pretrained Language Models via External Guidance
Nov 02, 2023Adopting a two-stage paradigm of pretraining followed by fine-tuning, Pretrained Language Models (PLMs) have achieved substantial advancements in the field of natural language processing. However, in real-world scenarios, data labels are often noisy due to the complex annotation process, making it essential to develop strategies for fine-tuning PLMs with such noisy labels. To this end, we introduce an innovative approach for fine-tuning PLMs using noisy labels, which incorporates the guidance of Large Language Models (LLMs) like ChatGPT. This guidance assists in accurately distinguishing between clean and noisy samples and provides supplementary information beyond the noisy labels, thereby boosting the learning process during fine-tuning PLMs. Extensive experiments on synthetic and real-world noisy datasets further demonstrate the superior advantages of our framework over the state-of-the-art baselines.
Gaussian Processes on Cellular Complexes
Nov 02, 2023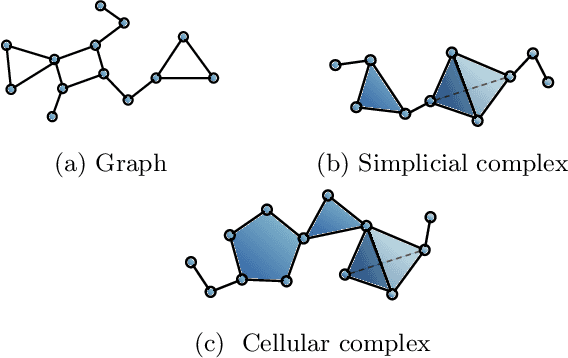

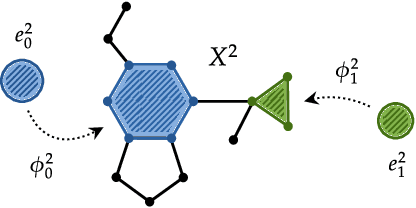

In recent years, there has been considerable interest in developing machine learning models on graphs in order to account for topological inductive biases. In particular, recent attention was given to Gaussian processes on such structures since they can additionally account for uncertainty. However, graphs are limited to modelling relations between two vertices. In this paper, we go beyond this dyadic setting and consider polyadic relations that include interactions between vertices, edges and one of their generalisations, known as cells. Specifically, we propose Gaussian processes on cellular complexes, a generalisation of graphs that captures interactions between these higher-order cells. One of our key contributions is the derivation of two novel kernels, one that generalises the graph Mat\'ern kernel and one that additionally mixes information of different cell types.
Unveiling the deep plumbing system of a volcano by a reflection matrix analysis of seismic noise
Nov 02, 2023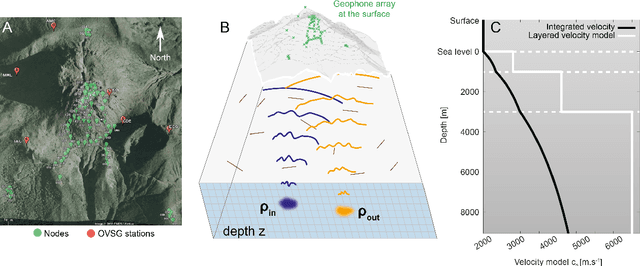
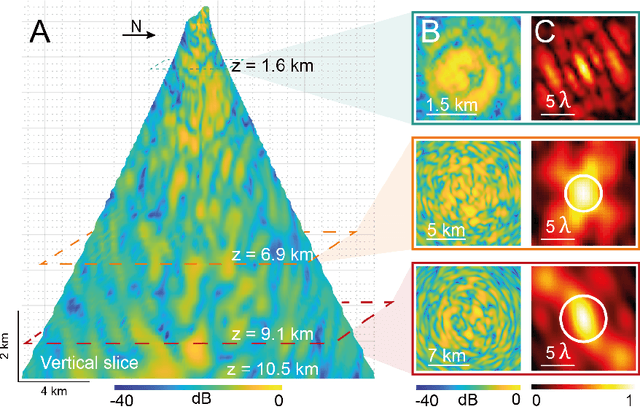
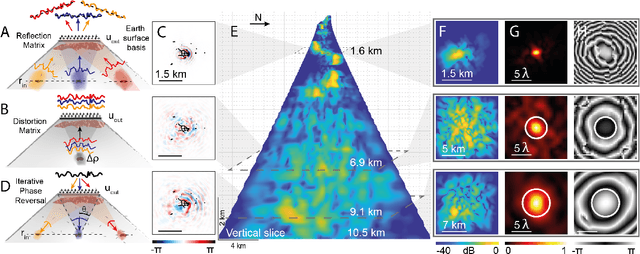
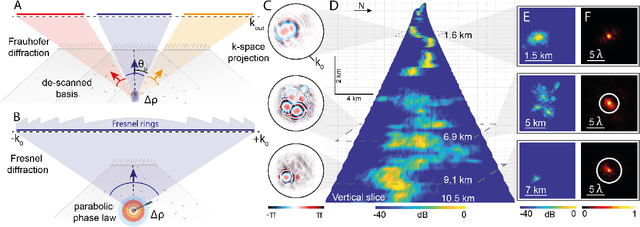
In geophysics, volcanoes are particularly difficult to image because of the multi-scale heterogeneities of fluids and rocks that compose them and their complex non-linear dynamics. By exploiting seismic noise recorded by a sparse array of geophones, we are able to reveal the magmatic and hydrothermal plumbing system of La Soufri\`ere volcano in Guadeloupe. Spatio-temporal cross-correlation of seismic noise actually provides the impulse responses between virtual geophones located inside the volcano. The resulting reflection matrix can be exploited to numerically perform an auto-focus of seismic waves on any reflector of the underground. An unprecedented view on the volcano's inner structure is obtained at a half-wavelength resolution. This innovative observable provides fundamental information for the conceptual modeling and high-resolution monitoring of volcanoes.
Sam-Guided Enhanced Fine-Grained Encoding with Mixed Semantic Learning for Medical Image Captioning
Nov 02, 2023With the development of multimodality and large language models, the deep learning-based technique for medical image captioning holds the potential to offer valuable diagnostic recommendations. However, current generic text and image pre-trained models do not yield satisfactory results when it comes to describing intricate details within medical images. In this paper, we present a novel medical image captioning method guided by the segment anything model (SAM) to enable enhanced encoding with both general and detailed feature extraction. In addition, our approach employs a distinctive pre-training strategy with mixed semantic learning to simultaneously capture both the overall information and finer details within medical images. We demonstrate the effectiveness of this approach, as it outperforms the pre-trained BLIP2 model on various evaluation metrics for generating descriptions of medical images.
Deep-learning-based decomposition of overlapping-sparse images: application at the vertex of neutrino interactions
Nov 06, 2023Image decomposition plays a crucial role in various computer vision tasks, enabling the analysis and manipulation of visual content at a fundamental level. Overlapping images, which occur when multiple objects or scenes partially occlude each other, pose unique challenges for decomposition algorithms. The task intensifies when working with sparse images, where the scarcity of meaningful information complicates the precise extraction of components. This paper presents a solution that leverages the power of deep learning to accurately extract individual objects within multi-dimensional overlapping-sparse images, with a direct application in high-energy physics with decomposition of overlaid elementary particles obtained from imaging detectors. In particular, the proposed approach tackles a highly complex yet unsolved problem: identifying and measuring independent particles at the vertex of neutrino interactions, where one expects to observe detector images with multiple indiscernible overlapping charged particles. By decomposing the image of the detector activity at the vertex through deep learning, it is possible to infer the kinematic parameters of the identified low-momentum particles - which otherwise would remain neglected - and enhance the reconstructed energy resolution of the neutrino event. We also present an additional step - that can be tuned directly on detector data - combining the above method with a fully-differentiable generative model to improve the image decomposition further and, consequently, the resolution of the measured parameters, achieving unprecedented results. This improvement is crucial for precisely measuring the parameters that govern neutrino flavour oscillations and searching for asymmetries between matter and antimatter.
BioInstruct: Instruction Tuning of Large Language Models for Biomedical Natural Language Processing
Nov 06, 2023To enhance the performance of large language models (LLMs) in biomedical natural language processing (BioNLP) by introducing a domain-specific instruction dataset and examining its impact when combined with multi-task learning principles. We created the BioInstruct, comprising 25,005 instructions to instruction-tune LLMs(LLaMA 1 & 2, 7B & 13B version). The instructions were created by prompting the GPT-4 language model with three-seed samples randomly drawn from an 80 human curated instructions. We employed Low-Rank Adaptation(LoRA) for parameter-efficient fine-tuning. We then evaluated these instruction-tuned LLMs on several BioNLP tasks, which can be grouped into three major categories: question answering(QA), information extraction(IE), and text generation(GEN). We also examined whether categories(e.g., QA, IE, and generation) of instructions impact model performance. Comparing with LLMs without instruction-tuned, our instruction-tuned LLMs demonstrated marked performance gains: 17.3% in QA, 5.7% in IE, and 96% in Generation tasks. Our 7B-parameter instruction-tuned LLaMA 1 model was competitive or even surpassed other LLMs in the biomedical domain that were also fine-tuned from LLaMA 1 with vast domain-specific data or a variety of tasks. Our results also show that the performance gain is significantly higher when instruction fine-tuning is conducted with closely related tasks. Our findings align with the observations of multi-task learning, suggesting the synergies between two tasks. The BioInstruct dataset serves as a valuable resource and instruction tuned LLMs lead to the best performing BioNLP applications.
Asymmetric Masked Distillation for Pre-Training Small Foundation Models
Nov 06, 2023Self-supervised foundation models have shown great potential in computer vision thanks to the pre-training paradigm of masked autoencoding. Scale is a primary factor influencing the performance of these foundation models. However, these large foundation models often result in high computational cost that might limit their deployment. This paper focuses on pre-training relatively small vision transformer models that could be efficiently adapted to downstream tasks. Specifically, taking inspiration from knowledge distillation in model compression, we propose a new asymmetric masked distillation(AMD) framework for pre-training relatively small models with autoencoding. The core of AMD is to devise an asymmetric masking strategy, where the teacher model is enabled to see more context information with a lower masking ratio, while the student model still with high masking ratio to the original masked pre-training. We design customized multi-layer feature alignment between the teacher encoder and student encoder to regularize the pre-training of student MAE. To demonstrate the effectiveness and versatility of AMD, we apply it to both ImageMAE and VideoMAE for pre-training relatively small ViT models. AMD achieved 84.6% classification accuracy on IN1K using the ViT-B model. And AMD achieves 73.3% classification accuracy using the ViT-B model on the Something-in-Something V2 dataset, a 3.7% improvement over the original ViT-B model from VideoMAE. We also transfer AMD pre-trained models to downstream tasks and obtain consistent performance improvement over the standard pre-training.
Temporal Shift -- Multi-Objective Loss Function for Improved Anomaly Fall Detection
Nov 06, 2023Falls are a major cause of injuries and deaths among older adults worldwide. Accurate fall detection can help reduce potential injuries and additional health complications. Different types of video modalities can be used in a home setting to detect falls, including RGB, Infrared, and Thermal cameras. Anomaly detection frameworks using autoencoders and their variants can be used for fall detection due to the data imbalance that arises from the rarity and diversity of falls. However, the use of reconstruction error in autoencoders can limit the application of networks' structures that propagate information. In this paper, we propose a new multi-objective loss function called Temporal Shift, which aims to predict both future and reconstructed frames within a window of sequential frames. The proposed loss function is evaluated on a semi-naturalistic fall detection dataset containing multiple camera modalities. The autoencoders were trained on normal activities of daily living (ADL) performed by older adults and tested on ADLs and falls performed by young adults. Temporal shift shows significant improvement to a baseline 3D Convolutional autoencoder, an attention U-Net CAE, and a multi-modal neural network. The greatest improvement was observed in an attention U-Net model improving by 0.20 AUC ROC for a single camera when compared to reconstruction alone. With significant improvement across different models, this approach has the potential to be widely adopted and improve anomaly detection capabilities in other settings besides fall detection.