 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
HKTGNN: Hierarchical Knowledge Transferable Graph Neural Network-based Supply Chain Risk Assessment
Nov 07, 2023
The strength of a supply chain is an important measure of a country's or region's technical advancement and overall competitiveness. Establishing supply chain risk assessment models for effective management and mitigation of potential risks has become increasingly crucial. As the number of businesses grows, the important relationships become more complicated and difficult to measure. This emphasizes the need of extracting relevant information from graph data. Previously, academics mostly employed knowledge inference to increase the visibility of links between nodes in the supply chain. However, they have not solved the data hunger problem of single node feature characteristics. We propose a hierarchical knowledge transferable graph neural network-based (HKTGNN) supply chain risk assessment model to address these issues. Our approach is based on current graph embedding methods for assessing corporate investment risk assessment. We embed the supply chain network corresponding to individual goods in the supply chain using the graph embedding module, resulting in a directed homogeneous graph with just product nodes. This reduces the complicated supply chain network into a basic product network. It addresses difficulties using the domain difference knowledge transferable module based on centrality, which is presented by the premise that supply chain feature characteristics may be biased in the actual world. Meanwhile, the feature complement and message passing will alleviate the data hunger problem, which is driven by domain differences. Our model outperforms in experiments on a real-world supply chain dataset. We will give an equation to prove that our comparative experiment is both effective and fair.
Does Invariant Graph Learning via Environment Augmentation Learn Invariance?
Oct 29, 2023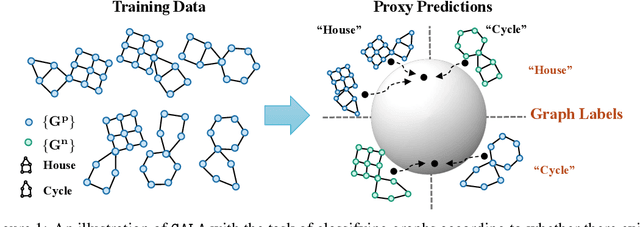
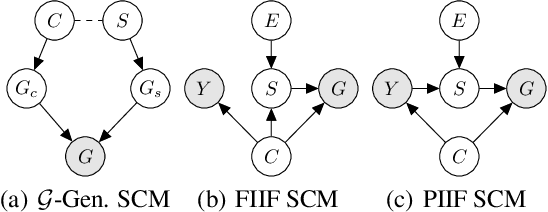
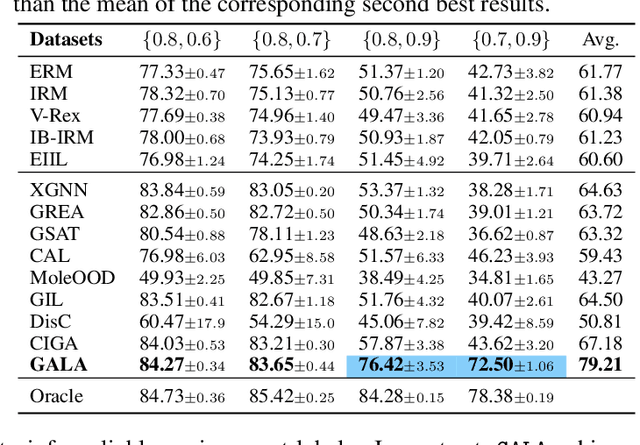
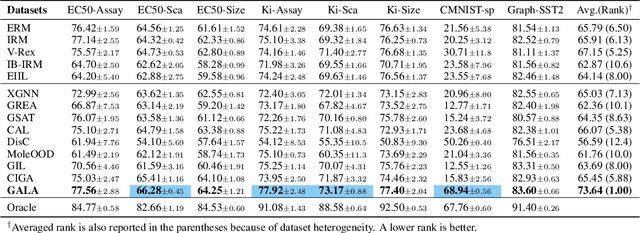
Invariant graph representation learning aims to learn the invariance among data from different environments for out-of-distribution generalization on graphs. As the graph environment partitions are usually expensive to obtain, augmenting the environment information has become the de facto approach. However, the usefulness of the augmented environment information has never been verified. In this work, we find that it is fundamentally impossible to learn invariant graph representations via environment augmentation without additional assumptions. Therefore, we develop a set of minimal assumptions, including variation sufficiency and variation consistency, for feasible invariant graph learning. We then propose a new framework Graph invAriant Learning Assistant (GALA). GALA incorporates an assistant model that needs to be sensitive to graph environment changes or distribution shifts. The correctness of the proxy predictions by the assistant model hence can differentiate the variations in spurious subgraphs. We show that extracting the maximally invariant subgraph to the proxy predictions provably identifies the underlying invariant subgraph for successful OOD generalization under the established minimal assumptions. Extensive experiments on datasets including DrugOOD with various graph distribution shifts confirm the effectiveness of GALA.
On Linear Separation Capacity of Self-Supervised Representation Learning
Oct 29, 2023Recent advances in self-supervised learning have highlighted the efficacy of data augmentation in learning data representation from unlabeled data. Training a linear model atop these enhanced representations can yield an adept classifier. Despite the remarkable empirical performance, the underlying mechanisms that enable data augmentation to unravel nonlinear data structures into linearly separable representations remain elusive. This paper seeks to bridge this gap by investigating under what conditions learned representations can linearly separate manifolds when data is drawn from a multi-manifold model. Our investigation reveals that data augmentation offers additional information beyond observed data and can thus improve the information-theoretic optimal rate of linear separation capacity. In particular, we show that self-supervised learning can linearly separate manifolds with a smaller distance than unsupervised learning, underscoring the additional benefits of data augmentation. Our theoretical analysis further underscores that the performance of downstream linear classifiers primarily hinges on the linear separability of data representations rather than the size of the labeled data set, reaffirming the viability of constructing efficient classifiers with limited labeled data amid an expansive unlabeled data set.
E-Sparse: Boosting the Large Language Model Inference through Entropy-based N:M Sparsity
Oct 24, 2023Traditional pruning methods are known to be challenging to work in Large Language Models (LLMs) for Generative AI because of their unaffordable training process and large computational demands. For the first time, we introduce the information entropy of hidden state features into a pruning metric design, namely E-Sparse, to improve the accuracy of N:M sparsity on LLM. E-Sparse employs the information richness to leverage the channel importance, and further incorporates several novel techniques to put it into effect: (1) it introduces information entropy to enhance the significance of parameter weights and input feature norms as a novel pruning metric, and performs N:M sparsity without modifying the remaining weights. (2) it designs global naive shuffle and local block shuffle to quickly optimize the information distribution and adequately cope with the impact of N:M sparsity on LLMs' accuracy. E-Sparse is implemented as a Sparse-GEMM on FasterTransformer and runs on NVIDIA Ampere GPUs. Extensive experiments on the LLaMA family and OPT models show that E-Sparse can significantly speed up the model inference over the dense model (up to 1.53X) and obtain significant memory saving (up to 43.52%), with acceptable accuracy loss.
Leveraging point annotations in segmentation learning with boundary loss
Nov 06, 2023This paper investigates the combination of intensity-based distance maps with boundary loss for point-supervised semantic segmentation. By design the boundary loss imposes a stronger penalty on the false positives the farther away from the object they occur. Hence it is intuitively inappropriate for weak supervision, where the ground truth label may be much smaller than the actual object and a certain amount of false positives (w.r.t. the weak ground truth) is actually desirable. Using intensity-aware distances instead may alleviate this drawback, allowing for a certain amount of false positives without a significant increase to the training loss. The motivation for applying the boundary loss directly under weak supervision lies in its great success for fully supervised segmentation tasks, but also in not requiring extra priors or outside information that is usually required -- in some form -- with existing weakly supervised methods in the literature. This formulation also remains potentially more attractive than existing CRF-based regularizers, due to its simplicity and computational efficiency. We perform experiments on two multi-class datasets; ACDC (heart segmentation) and POEM (whole-body abdominal organ segmentation). Preliminary results are encouraging and show that this supervision strategy has great potential. On ACDC it outperforms the CRF-loss based approach, and on POEM data it performs on par with it. The code for all our experiments is openly available.
MAAIG: Motion Analysis And Instruction Generation
Nov 02, 2023Many people engage in self-directed sports training at home but lack the real-time guidance of professional coaches, making them susceptible to injuries or the development of incorrect habits. In this paper, we propose a novel application framework called MAAIG(Motion Analysis And Instruction Generation). It can generate embedding vectors for each frame based on user-provided sports action videos. These embedding vectors are associated with the 3D skeleton of each frame and are further input into a pretrained T5 model. Ultimately, our model utilizes this information to generate specific sports instructions. It has the capability to identify potential issues and provide real-time guidance in a manner akin to professional coaches, helping users improve their sports skills and avoid injuries.
Bias in Evaluation Processes: An Optimization-Based Model
Oct 26, 2023Biases with respect to socially-salient attributes of individuals have been well documented in evaluation processes used in settings such as admissions and hiring. We view such an evaluation process as a transformation of a distribution of the true utility of an individual for a task to an observed distribution and model it as a solution to a loss minimization problem subject to an information constraint. Our model has two parameters that have been identified as factors leading to biases: the resource-information trade-off parameter in the information constraint and the risk-averseness parameter in the loss function. We characterize the distributions that arise from our model and study the effect of the parameters on the observed distribution. The outputs of our model enrich the class of distributions that can be used to capture variation across groups in the observed evaluations. We empirically validate our model by fitting real-world datasets and use it to study the effect of interventions in a downstream selection task. These results contribute to an understanding of the emergence of bias in evaluation processes and provide tools to guide the deployment of interventions to mitigate biases.
TempME: Towards the Explainability of Temporal Graph Neural Networks via Motif Discovery
Oct 30, 2023Temporal graphs are widely used to model dynamic systems with time-varying interactions. In real-world scenarios, the underlying mechanisms of generating future interactions in dynamic systems are typically governed by a set of recurring substructures within the graph, known as temporal motifs. Despite the success and prevalence of current temporal graph neural networks (TGNN), it remains uncertain which temporal motifs are recognized as the significant indications that trigger a certain prediction from the model, which is a critical challenge for advancing the explainability and trustworthiness of current TGNNs. To address this challenge, we propose a novel approach, called Temporal Motifs Explainer (TempME), which uncovers the most pivotal temporal motifs guiding the prediction of TGNNs. Derived from the information bottleneck principle, TempME extracts the most interaction-related motifs while minimizing the amount of contained information to preserve the sparsity and succinctness of the explanation. Events in the explanations generated by TempME are verified to be more spatiotemporally correlated than those of existing approaches, providing more understandable insights. Extensive experiments validate the superiority of TempME, with up to 8.21% increase in terms of explanation accuracy across six real-world datasets and up to 22.96% increase in boosting the prediction Average Precision of current TGNNs.
LLMRec: Large Language Models with Graph Augmentation for Recommendation
Nov 01, 2023
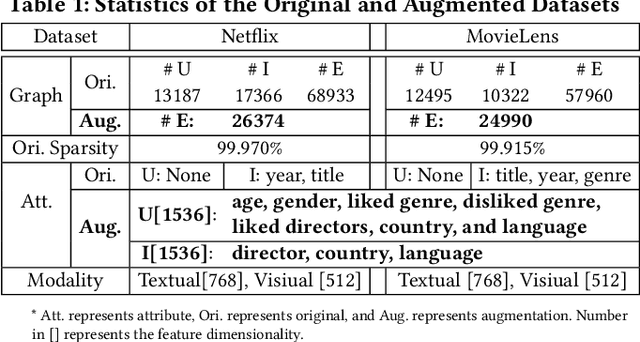
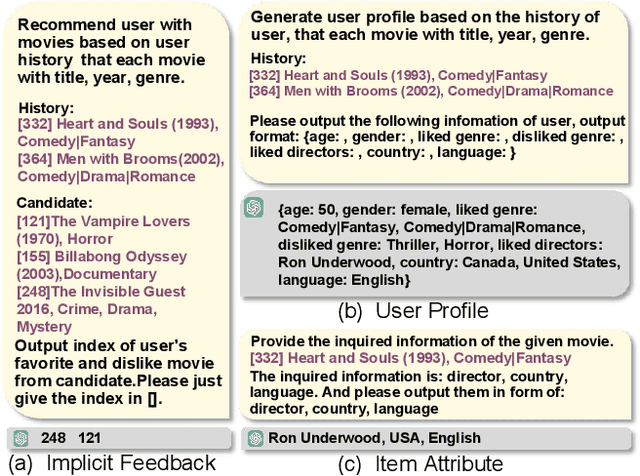
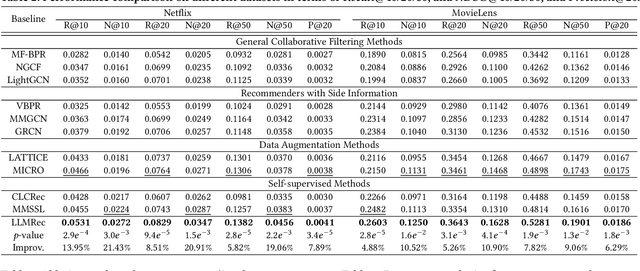
The problem of data sparsity has long been a challenge in recommendation systems, and previous studies have attempted to address this issue by incorporating side information. However, this approach often introduces side effects such as noise, availability issues, and low data quality, which in turn hinder the accurate modeling of user preferences and adversely impact recommendation performance. In light of the recent advancements in large language models (LLMs), which possess extensive knowledge bases and strong reasoning capabilities, we propose a novel framework called LLMRec that enhances recommender systems by employing three simple yet effective LLM-based graph augmentation strategies. Our approach leverages the rich content available within online platforms (e.g., Netflix, MovieLens) to augment the interaction graph in three ways: (i) reinforcing user-item interaction egde, (ii) enhancing the understanding of item node attributes, and (iii) conducting user node profiling, intuitively from the natural language perspective. By employing these strategies, we address the challenges posed by sparse implicit feedback and low-quality side information in recommenders. Besides, to ensure the quality of the augmentation, we develop a denoised data robustification mechanism that includes techniques of noisy implicit feedback pruning and MAE-based feature enhancement that help refine the augmented data and improve its reliability. Furthermore, we provide theoretical analysis to support the effectiveness of LLMRec and clarify the benefits of our method in facilitating model optimization. Experimental results on benchmark datasets demonstrate the superiority of our LLM-based augmentation approach over state-of-the-art techniques. To ensure reproducibility, we have made our code and augmented data publicly available at: https://github.com/HKUDS/LLMRec.git
Feature-oriented Deep Learning Framework for Pulmonary Cone-beam CT (CBCT) Enhancement with Multi-task Customized Perceptual Loss
Nov 01, 2023Cone-beam computed tomography (CBCT) is routinely collected during image-guided radiation therapy (IGRT) to provide updated patient anatomy information for cancer treatments. However, CBCT images often suffer from streaking artifacts and noise caused by under-rate sampling projections and low-dose exposure, resulting in low clarity and information loss. While recent deep learning-based CBCT enhancement methods have shown promising results in suppressing artifacts, they have limited performance on preserving anatomical details since conventional pixel-to-pixel loss functions are incapable of describing detailed anatomy. To address this issue, we propose a novel feature-oriented deep learning framework that translates low-quality CBCT images into high-quality CT-like imaging via a multi-task customized feature-to-feature perceptual loss function. The framework comprises two main components: a multi-task learning feature-selection network(MTFS-Net) for customizing the perceptual loss function; and a CBCT-to-CT translation network guided by feature-to-feature perceptual loss, which uses advanced generative models such as U-Net, GAN and CycleGAN. Our experiments showed that the proposed framework can generate synthesized CT (sCT) images for the lung that achieved a high similarity to CT images, with an average SSIM index of 0.9869 and an average PSNR index of 39.9621. The sCT images also achieved visually pleasing performance with effective artifacts suppression, noise reduction, and distinctive anatomical details preservation. Our experiment results indicate that the proposed framework outperforms the state-of-the-art models for pulmonary CBCT enhancement. This framework holds great promise for generating high-quality anatomical imaging from CBCT that is suitable for various clinical applications.