 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FLODCAST: Flow and Depth Forecasting via Multimodal Recurrent Architectures
Oct 31, 2023
Forecasting motion and spatial positions of objects is of fundamental importance, especially in safety-critical settings such as autonomous driving. In this work, we address the issue by forecasting two different modalities that carry complementary information, namely optical flow and depth. To this end we propose FLODCAST a flow and depth forecasting model that leverages a multitask recurrent architecture, trained to jointly forecast both modalities at once. We stress the importance of training using flows and depth maps together, demonstrating that both tasks improve when the model is informed of the other modality. We train the proposed model to also perform predictions for several timesteps in the future. This provides better supervision and leads to more precise predictions, retaining the capability of the model to yield outputs autoregressively for any future time horizon. We test our model on the challenging Cityscapes dataset, obtaining state of the art results for both flow and depth forecasting. Thanks to the high quality of the generated flows, we also report benefits on the downstream task of segmentation forecasting, injecting our predictions in a flow-based mask-warping framework.
Safety-aware Causal Representation for Trustworthy Reinforcement Learning in Autonomous Driving
Oct 31, 2023In the domain of autonomous driving, the Learning from Demonstration (LfD) paradigm has exhibited notable efficacy in addressing sequential decision-making problems. However, consistently achieving safety in varying traffic contexts, especially in safety-critical scenarios, poses a significant challenge due to the long-tailed and unforeseen scenarios absent from offline datasets. In this paper, we introduce the saFety-aware strUctured Scenario representatION (FUSION), a pioneering methodology conceived to facilitate the learning of an adaptive end-to-end driving policy by leveraging structured scenario information. FUSION capitalizes on the causal relationships between decomposed reward, cost, state, and action space, constructing a framework for structured sequential reasoning under dynamic traffic environments. We conduct rigorous evaluations in two typical real-world settings of distribution shift in autonomous vehicles, demonstrating the good balance between safety cost and utility reward of FUSION compared to contemporary state-of-the-art safety-aware LfD baselines. Empirical evidence under diverse driving scenarios attests that FUSION significantly enhances the safety and generalizability of autonomous driving agents, even in the face of challenging and unseen environments. Furthermore, our ablation studies reveal noticeable improvements in the integration of causal representation into the safe offline RL problem.
Deep learning based Image Compression for Microscopy Images: An Empirical Study
Nov 02, 2023With the fast development of modern microscopes and bioimaging techniques, an unprecedentedly large amount of imaging data are being generated, stored, analyzed, and even shared through networks. The size of the data poses great challenges for current data infrastructure. One common way to reduce the data size is by image compression. This present study analyzes classic and deep learning based image compression methods, and their impact on deep learning based image processing models. Deep learning based label-free prediction models (i.e., predicting fluorescent images from bright field images) are used as an example application for comparison and analysis. Effective image compression methods could help reduce the data size significantly without losing necessary information, and therefore reduce the burden on data management infrastructure and permit fast transmission through the network for data sharing or cloud computing. To compress images in such a wanted way, multiple classical lossy image compression techniques are compared to several AI-based compression models provided by and trained with the CompressAI toolbox using python. These different compression techniques are compared in compression ratio, multiple image similarity measures and, most importantly, the prediction accuracy from label-free models on compressed images. We found that AI-based compression techniques largely outperform the classic ones and will minimally affect the downstream label-free task in 2D cases. In the end, we hope the present study could shed light on the potential of deep learning based image compression and the impact of image compression on downstream deep learning based image analysis models.
What Makes it Ok to Set a Fire? Iterative Self-distillation of Contexts and Rationales for Disambiguating Defeasible Social and Moral Situations
Nov 01, 2023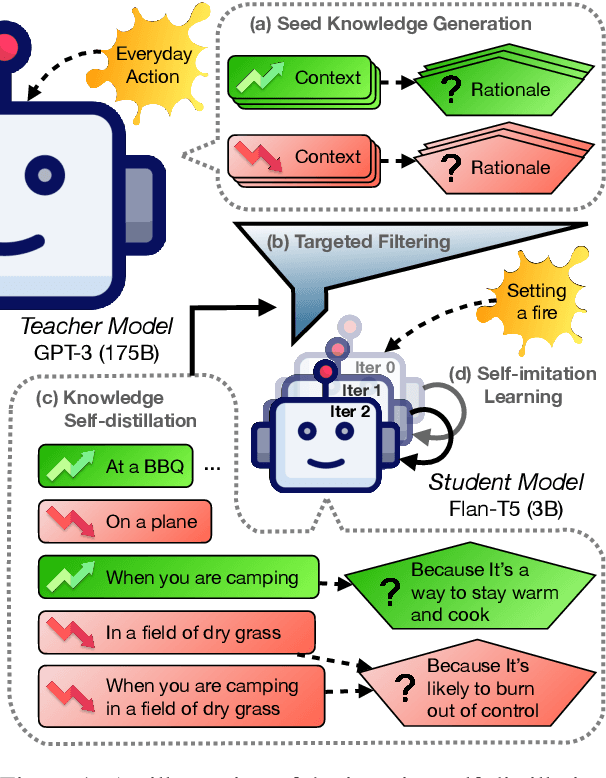
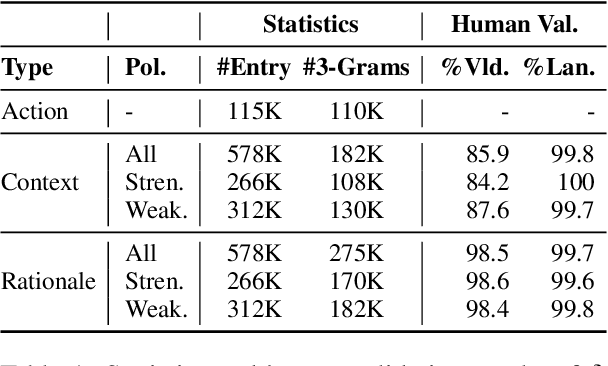
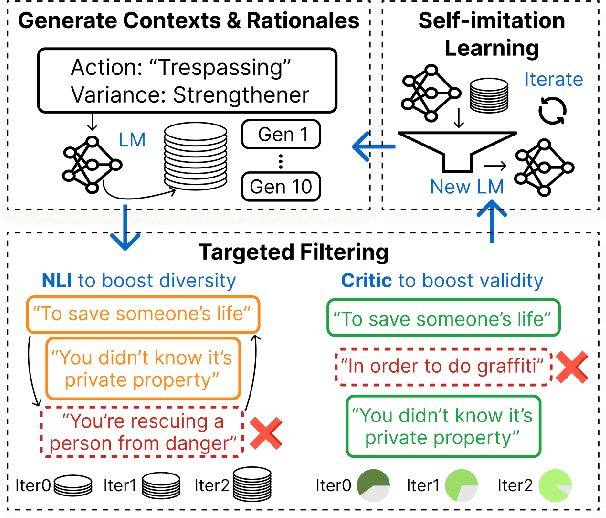
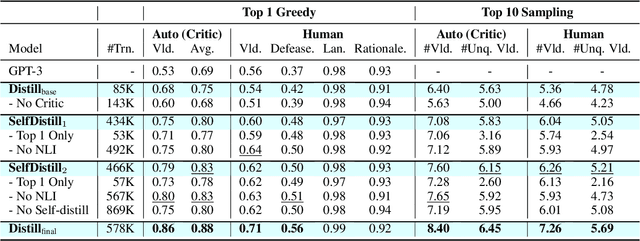
Moral or ethical judgments rely heavily on the specific contexts in which they occur. Understanding varying shades of defeasible contextualizations (i.e., additional information that strengthens or attenuates the moral acceptability of an action) is critical to accurately represent the subtlety and intricacy of grounded human moral judgment in real-life scenarios. We introduce defeasible moral reasoning: a task to provide grounded contexts that make an action more or less morally acceptable, along with commonsense rationales that justify the reasoning. To elicit high-quality task data, we take an iterative self-distillation approach that starts from a small amount of unstructured seed knowledge from GPT-3 and then alternates between (1) self-distillation from student models; (2) targeted filtering with a critic model trained by human judgment (to boost validity) and NLI (to boost diversity); (3) self-imitation learning (to amplify the desired data quality). This process yields a student model that produces defeasible contexts with improved validity, diversity, and defeasibility. From this model we distill a high-quality dataset, \delta-Rules-of-Thumb, of 1.2M entries of contextualizations and rationales for 115K defeasible moral actions rated highly by human annotators 85.9% to 99.8% of the time. Using \delta-RoT we obtain a final student model that wins over all intermediate student models by a notable margin.
The Open DAC 2023 Dataset and Challenges for Sorbent Discovery in Direct Air Capture
Nov 01, 2023New methods for carbon dioxide removal are urgently needed to combat global climate change. Direct air capture (DAC) is an emerging technology to capture carbon dioxide directly from ambient air. Metal-organic frameworks (MOFs) have been widely studied as potentially customizable adsorbents for DAC. However, discovering promising MOF sorbents for DAC is challenging because of the vast chemical space to explore and the need to understand materials as functions of humidity and temperature. We explore a computational approach benefiting from recent innovations in machine learning (ML) and present a dataset named Open DAC 2023 (ODAC23) consisting of more than 38M density functional theory (DFT) calculations on more than 8,800 MOF materials containing adsorbed CO2 and/or H2O. ODAC23 is by far the largest dataset of MOF adsorption calculations at the DFT level of accuracy currently available. In addition to probing properties of adsorbed molecules, the dataset is a rich source of information on structural relaxation of MOFs, which will be useful in many contexts beyond specific applications for DAC. A large number of MOFs with promising properties for DAC are identified directly in ODAC23. We also trained state-of-the-art ML models on this dataset to approximate calculations at the DFT level. This open-source dataset and our initial ML models will provide an important baseline for future efforts to identify MOFs for a wide range of applications, including DAC.
Learning to Design and Use Tools for Robotic Manipulation
Nov 01, 2023When limited by their own morphologies, humans and some species of animals have the remarkable ability to use objects from the environment toward accomplishing otherwise impossible tasks. Robots might similarly unlock a range of additional capabilities through tool use. Recent techniques for jointly optimizing morphology and control via deep learning are effective at designing locomotion agents. But while outputting a single morphology makes sense for locomotion, manipulation involves a variety of strategies depending on the task goals at hand. A manipulation agent must be capable of rapidly prototyping specialized tools for different goals. Therefore, we propose learning a designer policy, rather than a single design. A designer policy is conditioned on task information and outputs a tool design that helps solve the task. A design-conditioned controller policy can then perform manipulation using these tools. In this work, we take a step towards this goal by introducing a reinforcement learning framework for jointly learning these policies. Through simulated manipulation tasks, we show that this framework is more sample efficient than prior methods in multi-goal or multi-variant settings, can perform zero-shot interpolation or fine-tuning to tackle previously unseen goals, and allows tradeoffs between the complexity of design and control policies under practical constraints. Finally, we deploy our learned policies onto a real robot. Please see our supplementary video and website at https://robotic-tool-design.github.io/ for visualizations.
The Simplest Inflationary Potentials
Oct 25, 2023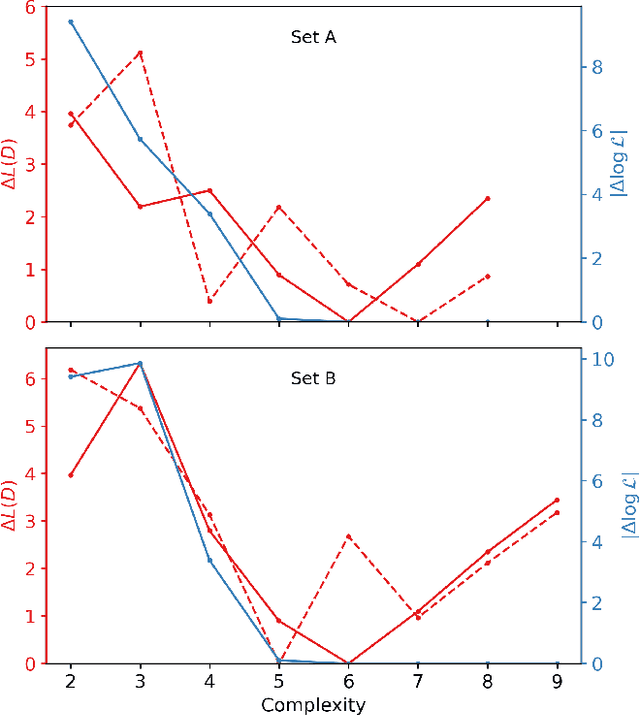
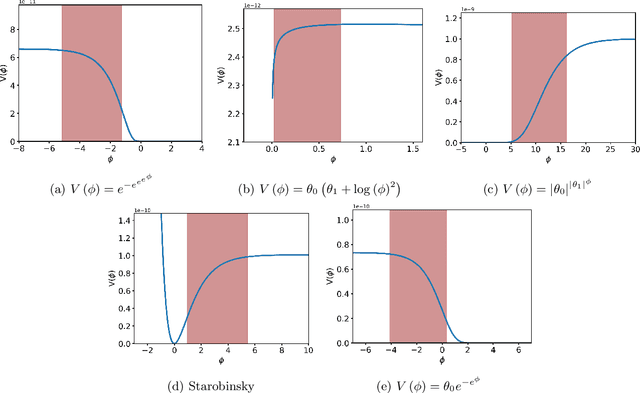
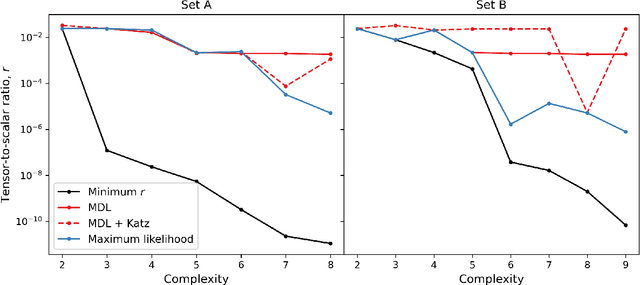
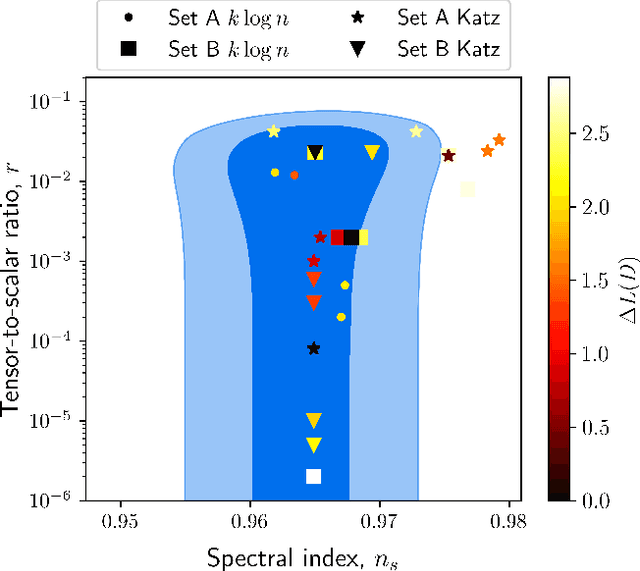
Inflation is a highly favoured theory for the early Universe. It is compatible with current observations of the cosmic microwave background and large scale structure and is a driver in the quest to detect primordial gravitational waves. It is also, given the current quality of the data, highly under-determined with a large number of candidate implementations. We use a new method in symbolic regression to generate all possible simple scalar field potentials for one of two possible basis sets of operators. Treating these as single-field, slow-roll inflationary models we then score them with an information-theoretic metric ("minimum description length") that quantifies their efficiency in compressing the information in the Planck data. We explore two possible priors on the parameter space of potentials, one related to the functions' structural complexity and one that uses a Katz back-off language model to prefer functions that may be theoretically motivated. This enables us to identify the inflaton potentials that optimally balance simplicity with accuracy at explaining the Planck data, which may subsequently find theoretical motivation. Our exploratory study opens the door to extraction of fundamental physics directly from data, and may be augmented with more refined theoretical priors in the quest for a complete understanding of the early Universe.
Online Convex Optimization with Switching Cost and Delayed Gradients
Oct 18, 2023We consider the online convex optimization (OCO) problem with quadratic and linear switching cost in the limited information setting, where an online algorithm can choose its action using only gradient information about the previous objective function. For $L$-smooth and $\mu$-strongly convex objective functions, we propose an online multiple gradient descent (OMGD) algorithm and show that its competitive ratio for the OCO problem with quadratic switching cost is at most $4(L + 5) + \frac{16(L + 5)}{\mu}$. The competitive ratio upper bound for OMGD is also shown to be order-wise tight in terms of $L,\mu$. In addition, we show that the competitive ratio of any online algorithm is $\max\{\Omega(L), \Omega(\frac{L}{\sqrt{\mu}})\}$ in the limited information setting when the switching cost is quadratic. We also show that the OMGD algorithm achieves the optimal (order-wise) dynamic regret in the limited information setting. For the linear switching cost, the competitive ratio upper bound of the OMGD algorithm is shown to depend on both the path length and the squared path length of the problem instance, in addition to $L, \mu$, and is shown to be order-wise, the best competitive ratio any online algorithm can achieve. Consequently, we conclude that the optimal competitive ratio for the quadratic and linear switching costs are fundamentally different in the limited information setting.
Fundamental Limits of Membership Inference Attacks on Machine Learning Models
Oct 27, 2023Membership inference attacks (MIA) can reveal whether a particular data point was part of the training dataset, potentially exposing sensitive information about individuals. This article explores the fundamental statistical limitations associated with MIAs on machine learning models. More precisely, we first derive the statistical quantity that governs the effectiveness and success of such attacks. Then, we investigate several situations for which we provide bounds on this quantity of interest. This allows us to infer the accuracy of potential attacks as a function of the number of samples and other structural parameters of learning models, which in some cases can be directly estimated from the dataset.
M2DF: Multi-grained Multi-curriculum Denoising Framework for Multimodal Aspect-based Sentiment Analysis
Oct 23, 2023
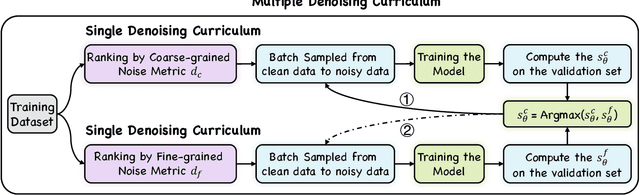
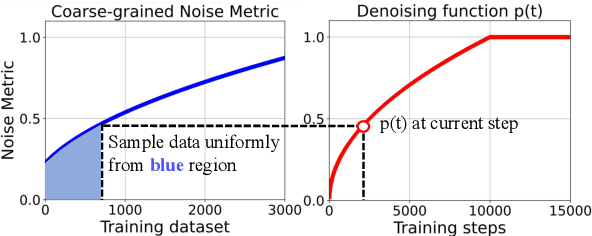

Multimodal Aspect-based Sentiment Analysis (MABSA) is a fine-grained Sentiment Analysis task, which has attracted growing research interests recently. Existing work mainly utilizes image information to improve the performance of MABSA task. However, most of the studies overestimate the importance of images since there are many noise images unrelated to the text in the dataset, which will have a negative impact on model learning. Although some work attempts to filter low-quality noise images by setting thresholds, relying on thresholds will inevitably filter out a lot of useful image information. Therefore, in this work, we focus on whether the negative impact of noisy images can be reduced without modifying the data. To achieve this goal, we borrow the idea of Curriculum Learning and propose a Multi-grained Multi-curriculum Denoising Framework (M2DF), which can achieve denoising by adjusting the order of training data. Extensive experimental results show that our framework consistently outperforms state-of-the-art work on three sub-tasks of MABSA.