 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Multimodal Visual Encoding Model Aided by Introducing Verbal Semantic Information
Aug 29, 2023
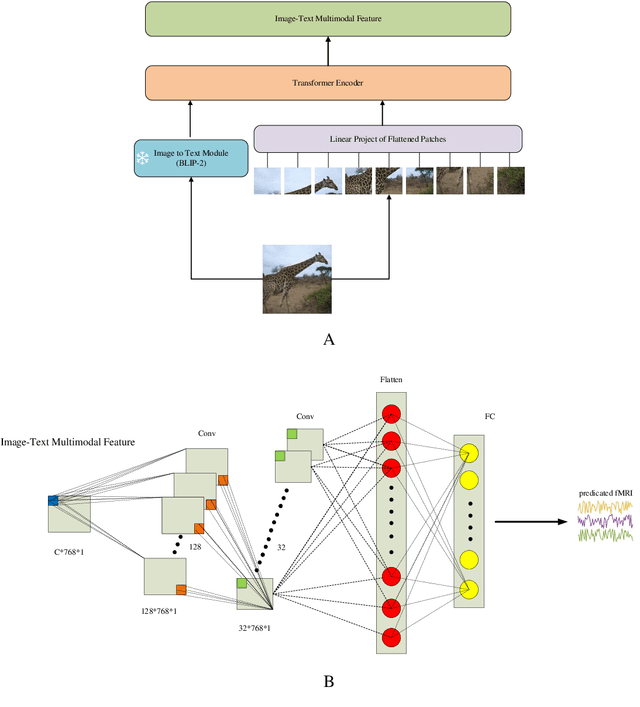
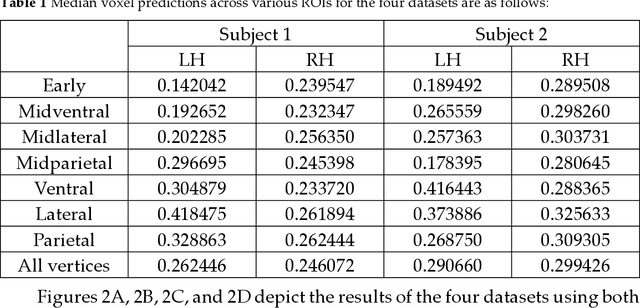
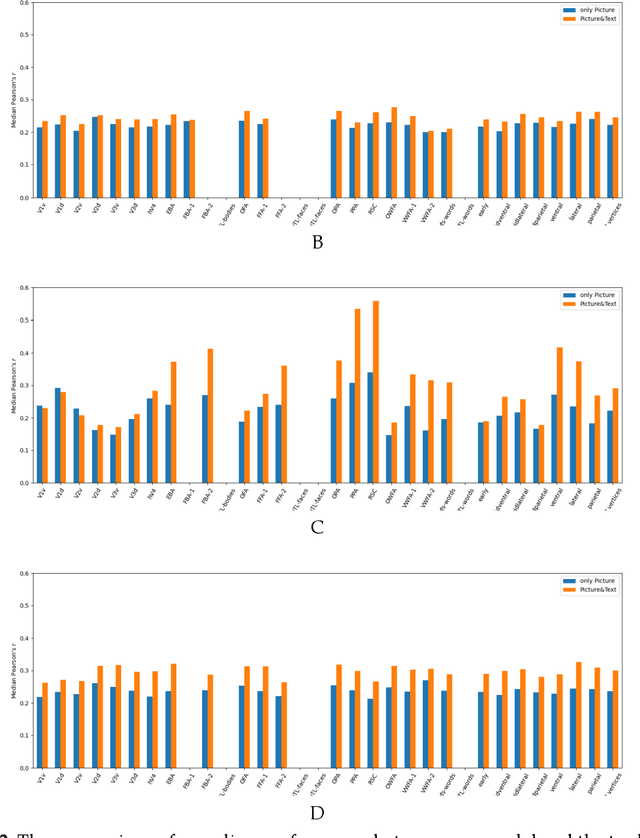
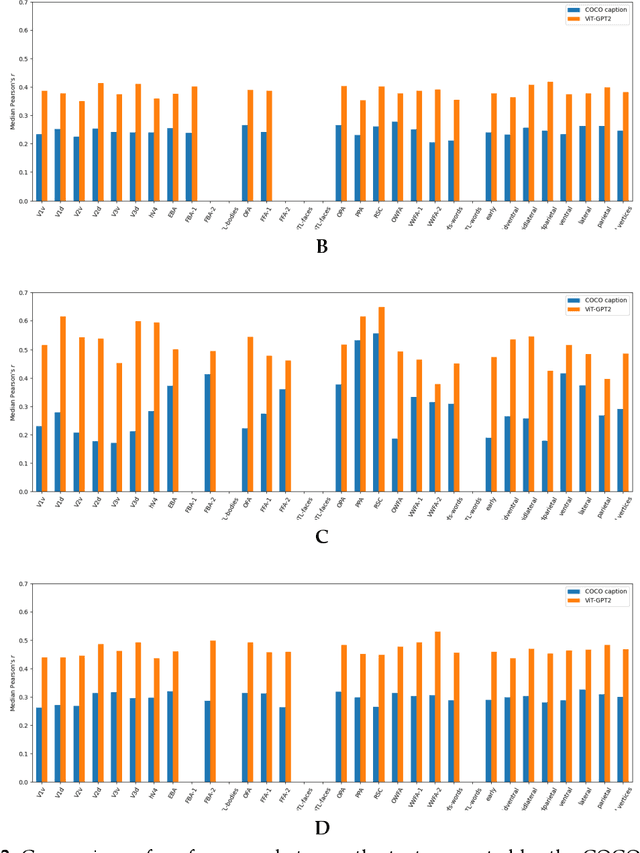
Biological research has revealed that the verbal semantic information in the brain cortex, as an additional source, participates in nonverbal semantic tasks, such as visual encoding. However, previous visual encoding models did not incorporate verbal semantic information, contradicting this biological finding. This paper proposes a multimodal visual information encoding network model based on stimulus images and associated textual information in response to this issue. Our visual information encoding network model takes stimulus images as input and leverages textual information generated by a text-image generation model as verbal semantic information. This approach injects new information into the visual encoding model. Subsequently, a Transformer network aligns image and text feature information, creating a multimodal feature space. A convolutional network then maps from this multimodal feature space to voxel space, constructing the multimodal visual information encoding network model. Experimental results demonstrate that the proposed multimodal visual information encoding network model outperforms previous models under the exact training cost. In voxel prediction of the left hemisphere of subject 1's brain, the performance improves by approximately 15.87%, while in the right hemisphere, the performance improves by about 4.6%. The multimodal visual encoding network model exhibits superior encoding performance. Additionally, ablation experiments indicate that our proposed model better simulates the brain's visual information processing.
Is Probing All You Need? Indicator Tasks as an Alternative to Probing Embedding Spaces
Oct 24, 2023

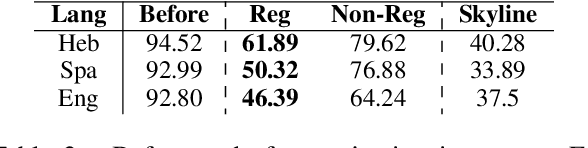

The ability to identify and control different kinds of linguistic information encoded in vector representations of words has many use cases, especially for explainability and bias removal. This is usually done via a set of simple classification tasks, termed probes, to evaluate the information encoded in the embedding space. However, the involvement of a trainable classifier leads to entanglement between the probe's results and the classifier's nature. As a result, contemporary works on probing include tasks that do not involve training of auxiliary models. In this work we introduce the term indicator tasks for non-trainable tasks which are used to query embedding spaces for the existence of certain properties, and claim that this kind of tasks may point to a direction opposite to probes, and that this contradiction complicates the decision on whether a property exists in an embedding space. We demonstrate our claims with two test cases, one dealing with gender debiasing and another with the erasure of morphological information from embedding spaces. We show that the application of a suitable indicator provides a more accurate picture of the information captured and removed compared to probes. We thus conclude that indicator tasks should be implemented and taken into consideration when eliciting information from embedded representations.
Integrating Pre-trained Language Model into Neural Machine Translation
Oct 30, 2023Neural Machine Translation (NMT) has become a significant technology in natural language processing through extensive research and development. However, the deficiency of high-quality bilingual language pair data still poses a major challenge to improving NMT performance. Recent studies are exploring the use of contextual information from pre-trained language model (PLM) to address this problem. Yet, the issue of incompatibility between PLM and NMT model remains unresolved. This study proposes a PLM-integrated NMT (PiNMT) model to overcome the identified problems. The PiNMT model consists of three critical components, PLM Multi Layer Converter, Embedding Fusion, and Cosine Alignment, each playing a vital role in providing effective PLM information to NMT. Furthermore, two training strategies, Separate Learning Rates and Dual Step Training, are also introduced in this paper. By implementing the proposed PiNMT model and training strategy, we achieved state-of-the-art performance on the IWSLT'14 En$\leftrightarrow$De dataset. This study's outcomes are noteworthy as they demonstrate a novel approach for efficiently integrating PLM with NMT to overcome incompatibility and enhance performance.
Designing AI Support for Human Involvement in AI-assisted Decision Making: A Taxonomy of Human-AI Interactions from a Systematic Review
Oct 31, 2023Efforts in levering Artificial Intelligence (AI) in decision support systems have disproportionately focused on technological advancements, often overlooking the alignment between algorithmic outputs and human expectations. To address this, explainable AI promotes AI development from a more human-centered perspective. Determining what information AI should provide to aid humans is vital, however, how the information is presented, e. g., the sequence of recommendations and the solicitation of interpretations, is equally crucial. This motivates the need to more precisely study Human-AI interaction as a pivotal component of AI-based decision support. While several empirical studies have evaluated Human-AI interactions in multiple application domains in which interactions can take many forms, there is not yet a common vocabulary to describe human-AI interaction protocols. To address this gap, we describe the results of a systematic review of the AI-assisted decision making literature, analyzing 105 selected articles, which grounds the introduction of a taxonomy of interaction patterns that delineate various modes of human-AI interactivity. We find that current interactions are dominated by simplistic collaboration paradigms and report comparatively little support for truly interactive functionality. Our taxonomy serves as a valuable tool to understand how interactivity with AI is currently supported in decision-making contexts and foster deliberate choices of interaction designs.
Video-Helpful Multimodal Machine Translation
Oct 31, 2023Existing multimodal machine translation (MMT) datasets consist of images and video captions or instructional video subtitles, which rarely contain linguistic ambiguity, making visual information ineffective in generating appropriate translations. Recent work has constructed an ambiguous subtitles dataset to alleviate this problem but is still limited to the problem that videos do not necessarily contribute to disambiguation. We introduce EVA (Extensive training set and Video-helpful evaluation set for Ambiguous subtitles translation), an MMT dataset containing 852k Japanese-English (Ja-En) parallel subtitle pairs, 520k Chinese-English (Zh-En) parallel subtitle pairs, and corresponding video clips collected from movies and TV episodes. In addition to the extensive training set, EVA contains a video-helpful evaluation set in which subtitles are ambiguous, and videos are guaranteed helpful for disambiguation. Furthermore, we propose SAFA, an MMT model based on the Selective Attention model with two novel methods: Frame attention loss and Ambiguity augmentation, aiming to use videos in EVA for disambiguation fully. Experiments on EVA show that visual information and the proposed methods can boost translation performance, and our model performs significantly better than existing MMT models. The EVA dataset and the SAFA model are available at: https://github.com/ku-nlp/video-helpful-MMT.git.
Getting aligned on representational alignment
Nov 02, 2023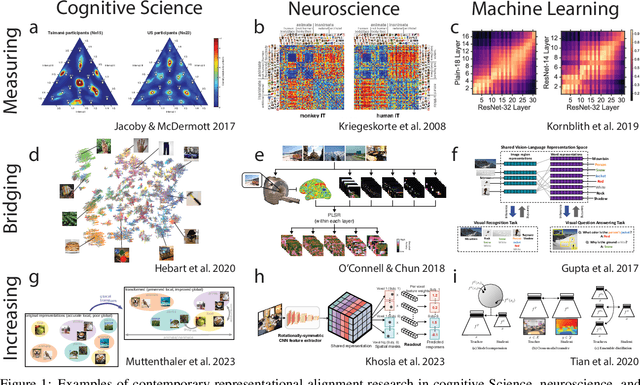
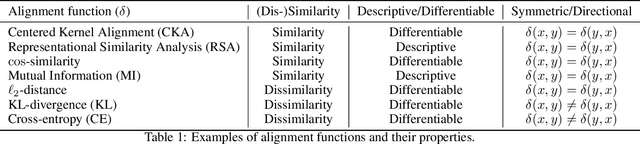
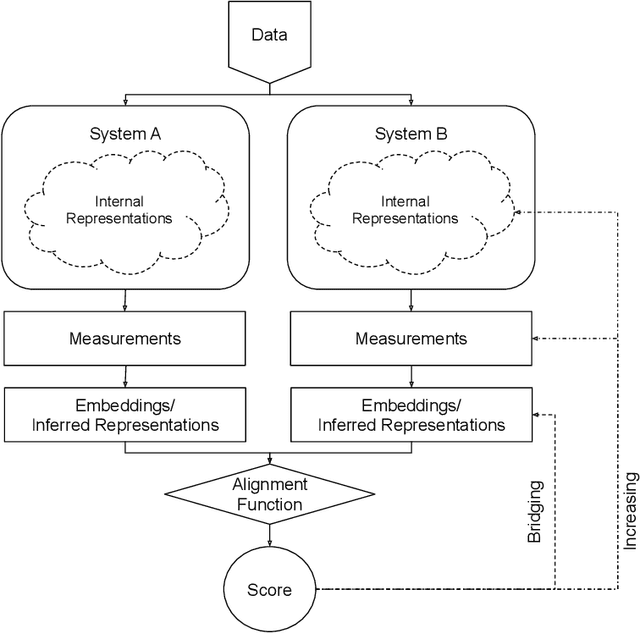
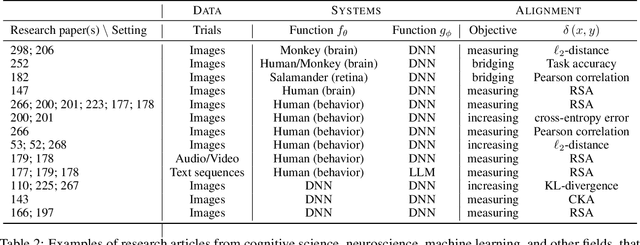
Biological and artificial information processing systems form representations that they can use to categorize, reason, plan, navigate, and make decisions. How can we measure the extent to which the representations formed by these diverse systems agree? Do similarities in representations then translate into similar behavior? How can a system's representations be modified to better match those of another system? These questions pertaining to the study of representational alignment are at the heart of some of the most active research areas in cognitive science, neuroscience, and machine learning. For example, cognitive scientists measure the representational alignment of multiple individuals to identify shared cognitive priors, neuroscientists align fMRI responses from multiple individuals into a shared representational space for group-level analyses, and ML researchers distill knowledge from teacher models into student models by increasing their alignment. Unfortunately, there is limited knowledge transfer between research communities interested in representational alignment, so progress in one field often ends up being rediscovered independently in another. Thus, greater cross-field communication would be advantageous. To improve communication between these fields, we propose a unifying framework that can serve as a common language between researchers studying representational alignment. We survey the literature from all three fields and demonstrate how prior work fits into this framework. Finally, we lay out open problems in representational alignment where progress can benefit all three of these fields. We hope that our work can catalyze cross-disciplinary collaboration and accelerate progress for all communities studying and developing information processing systems. We note that this is a working paper and encourage readers to reach out with their suggestions for future revisions.
CAD -- Contextual Multi-modal Alignment for Dynamic AVQA
Oct 27, 2023In the context of Audio Visual Question Answering (AVQA) tasks, the audio visual modalities could be learnt on three levels: 1) Spatial, 2) Temporal, and 3) Semantic. Existing AVQA methods suffer from two major shortcomings; the audio-visual (AV) information passing through the network isn't aligned on Spatial and Temporal levels; and, inter-modal (audio and visual) Semantic information is often not balanced within a context; this results in poor performance. In this paper, we propose a novel end-to-end Contextual Multi-modal Alignment (CAD) network that addresses the challenges in AVQA methods by i) introducing a parameter-free stochastic Contextual block that ensures robust audio and visual alignment on the Spatial level; ii) proposing a pre-training technique for dynamic audio and visual alignment on Temporal level in a self-supervised setting, and iii) introducing a cross-attention mechanism to balance audio and visual information on Semantic level. The proposed novel CAD network improves the overall performance over the state-of-the-art methods on average by 9.4% on the MUSIC-AVQA dataset. We also demonstrate that our proposed contributions to AVQA can be added to the existing methods to improve their performance without additional complexity requirements.
Adaptive Latent Diffusion Model for 3D Medical Image to Image Translation: Multi-modal Magnetic Resonance Imaging Study
Nov 01, 2023
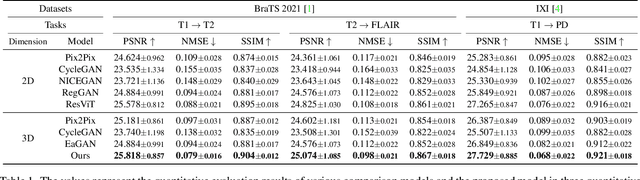

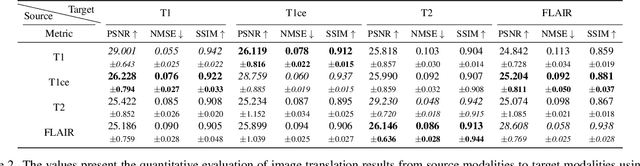
Multi-modal images play a crucial role in comprehensive evaluations in medical image analysis providing complementary information for identifying clinically important biomarkers. However, in clinical practice, acquiring multiple modalities can be challenging due to reasons such as scan cost, limited scan time, and safety considerations. In this paper, we propose a model based on the latent diffusion model (LDM) that leverages switchable blocks for image-to-image translation in 3D medical images without patch cropping. The 3D LDM combined with conditioning using the target modality allows generating high-quality target modality in 3D overcoming the shortcoming of the missing out-of-slice information in 2D generation methods. The switchable block, noted as multiple switchable spatially adaptive normalization (MS-SPADE), dynamically transforms source latents to the desired style of the target latents to help with the diffusion process. The MS-SPADE block allows us to have one single model to tackle many translation tasks of one source modality to various targets removing the need for many translation models for different scenarios. Our model exhibited successful image synthesis across different source-target modality scenarios and surpassed other models in quantitative evaluations tested on multi-modal brain magnetic resonance imaging datasets of four different modalities and an independent IXI dataset. Our model demonstrated successful image synthesis across various modalities even allowing for one-to-many modality translations. Furthermore, it outperformed other one-to-one translation models in quantitative evaluations.
Exploring Deep Learning Image Super-Resolution for Iris Recognition
Nov 02, 2023In this work we test the ability of deep learning methods to provide an end-to-end mapping between low and high resolution images applying it to the iris recognition problem. Here, we propose the use of two deep learning single-image super-resolution approaches: Stacked Auto-Encoders (SAE) and Convolutional Neural Networks (CNN) with the most possible lightweight structure to achieve fast speed, preserve local information and reduce artifacts at the same time. We validate the methods with a database of 1.872 near-infrared iris images with quality assessment and recognition experiments showing the superiority of deep learning approaches over the compared algorithms.
Generalized zero-shot audio-to-intent classification
Nov 04, 2023Spoken language understanding systems using audio-only data are gaining popularity, yet their ability to handle unseen intents remains limited. In this study, we propose a generalized zero-shot audio-to-intent classification framework with only a few sample text sentences per intent. To achieve this, we first train a supervised audio-to-intent classifier by making use of a self-supervised pre-trained model. We then leverage a neural audio synthesizer to create audio embeddings for sample text utterances and perform generalized zero-shot classification on unseen intents using cosine similarity. We also propose a multimodal training strategy that incorporates lexical information into the audio representation to improve zero-shot performance. Our multimodal training approach improves the accuracy of zero-shot intent classification on unseen intents of SLURP by 2.75% and 18.2% for the SLURP and internal goal-oriented dialog datasets, respectively, compared to audio-only training.