 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Enhancing Few-shot CLIP with Semantic-Aware Fine-Tuning
Nov 08, 2023
Learning generalized representations from limited training samples is crucial for applying deep neural networks in low-resource scenarios. Recently, methods based on Contrastive Language-Image Pre-training (CLIP) have exhibited promising performance in few-shot adaptation tasks. To avoid catastrophic forgetting and overfitting caused by few-shot fine-tuning, existing works usually freeze the parameters of CLIP pre-trained on large-scale datasets, overlooking the possibility that some parameters might not be suitable for downstream tasks. To this end, we revisit CLIP's visual encoder with a specific focus on its distinctive attention pooling layer, which performs a spatial weighted-sum of the dense feature maps. Given that dense feature maps contain meaningful semantic information, and different semantics hold varying importance for diverse downstream tasks (such as prioritizing semantics like ears and eyes in pet classification tasks rather than side mirrors), using the same weighted-sum operation for dense features across different few-shot tasks might not be appropriate. Hence, we propose fine-tuning the parameters of the attention pooling layer during the training process to encourage the model to focus on task-specific semantics. In the inference process, we perform residual blending between the features pooled by the fine-tuned and the original attention pooling layers to incorporate both the few-shot knowledge and the pre-trained CLIP's prior knowledge. We term this method as Semantic-Aware FinE-tuning (SAFE). SAFE is effective in enhancing the conventional few-shot CLIP and is compatible with the existing adapter approach (termed SAFE-A).
DualTalker: A Cross-Modal Dual Learning Approach for Speech-Driven 3D Facial Animation
Nov 08, 2023In recent years, audio-driven 3D facial animation has gained significant attention, particularly in applications such as virtual reality, gaming, and video conferencing. However, accurately modeling the intricate and subtle dynamics of facial expressions remains a challenge. Most existing studies approach the facial animation task as a single regression problem, which often fail to capture the intrinsic inter-modal relationship between speech signals and 3D facial animation and overlook their inherent consistency. Moreover, due to the limited availability of 3D-audio-visual datasets, approaches learning with small-size samples have poor generalizability that decreases the performance. To address these issues, in this study, we propose a cross-modal dual-learning framework, termed DualTalker, aiming at improving data usage efficiency as well as relating cross-modal dependencies. The framework is trained jointly with the primary task (audio-driven facial animation) and its dual task (lip reading) and shares common audio/motion encoder components. Our joint training framework facilitates more efficient data usage by leveraging information from both tasks and explicitly capitalizing on the complementary relationship between facial motion and audio to improve performance. Furthermore, we introduce an auxiliary cross-modal consistency loss to mitigate the potential over-smoothing underlying the cross-modal complementary representations, enhancing the mapping of subtle facial expression dynamics. Through extensive experiments and a perceptual user study conducted on the VOCA and BIWI datasets, we demonstrate that our approach outperforms current state-of-the-art methods both qualitatively and quantitatively. We have made our code and video demonstrations available at https://github.com/sabrina-su/iadf.git.
A Multimodal Visual Encoding Model Aided by Introducing Verbal Semantic Information
Aug 29, 2023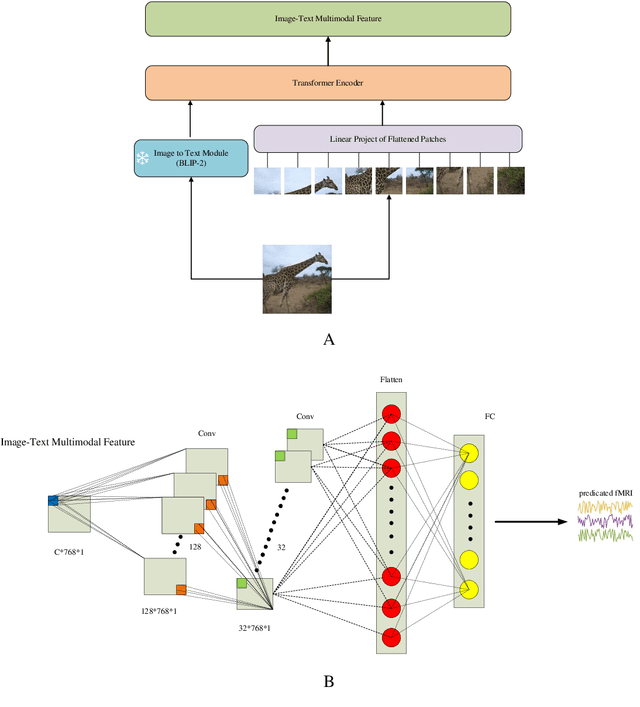
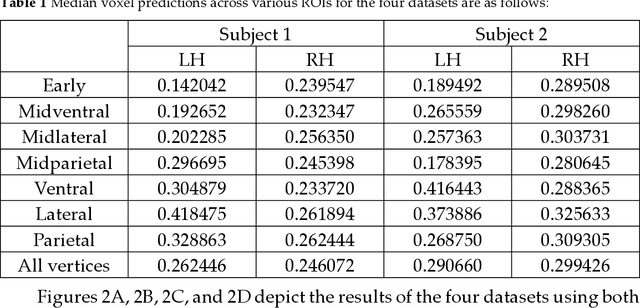
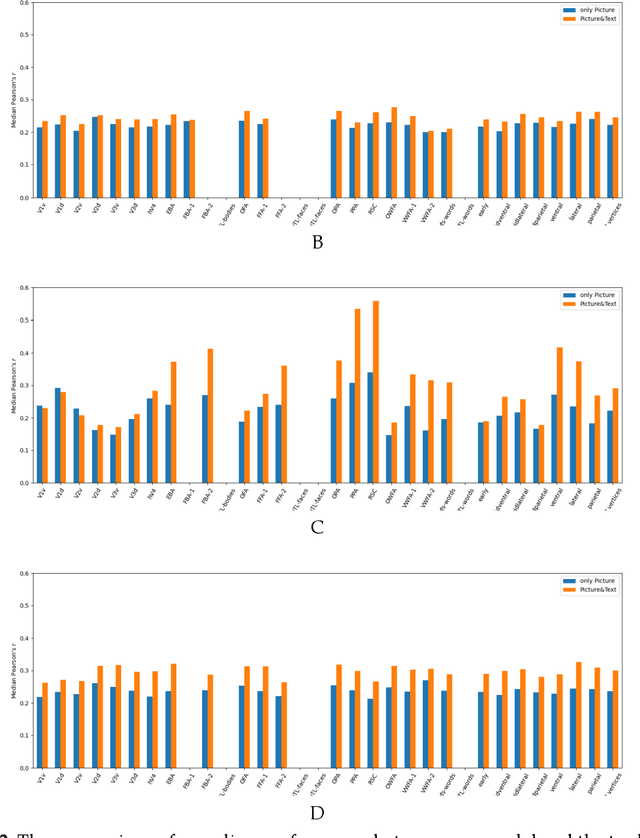
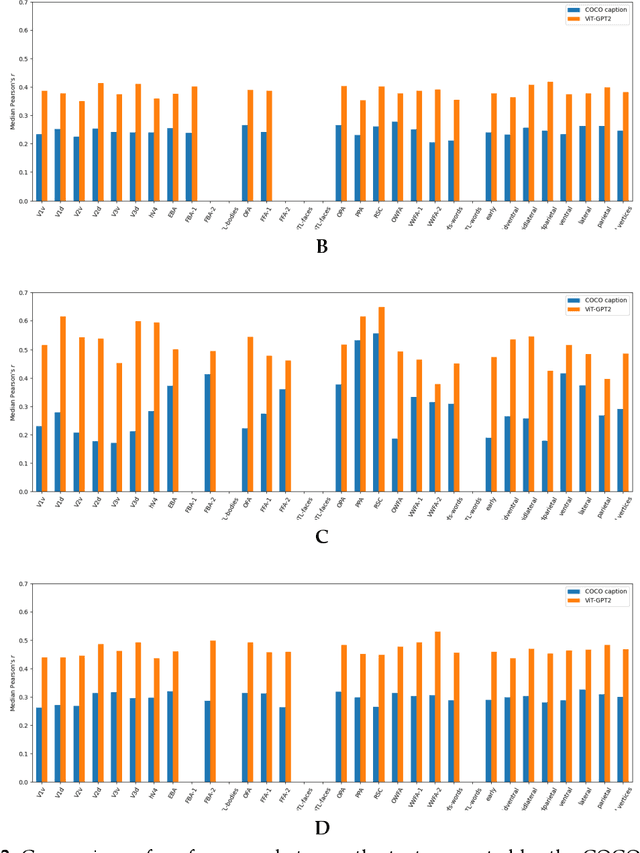
Biological research has revealed that the verbal semantic information in the brain cortex, as an additional source, participates in nonverbal semantic tasks, such as visual encoding. However, previous visual encoding models did not incorporate verbal semantic information, contradicting this biological finding. This paper proposes a multimodal visual information encoding network model based on stimulus images and associated textual information in response to this issue. Our visual information encoding network model takes stimulus images as input and leverages textual information generated by a text-image generation model as verbal semantic information. This approach injects new information into the visual encoding model. Subsequently, a Transformer network aligns image and text feature information, creating a multimodal feature space. A convolutional network then maps from this multimodal feature space to voxel space, constructing the multimodal visual information encoding network model. Experimental results demonstrate that the proposed multimodal visual information encoding network model outperforms previous models under the exact training cost. In voxel prediction of the left hemisphere of subject 1's brain, the performance improves by approximately 15.87%, while in the right hemisphere, the performance improves by about 4.6%. The multimodal visual encoding network model exhibits superior encoding performance. Additionally, ablation experiments indicate that our proposed model better simulates the brain's visual information processing.
Low-Dimensional Gradient Helps Out-of-Distribution Detection
Oct 26, 2023Detecting out-of-distribution (OOD) samples is essential for ensuring the reliability of deep neural networks (DNNs) in real-world scenarios. While previous research has predominantly investigated the disparity between in-distribution (ID) and OOD data through forward information analysis, the discrepancy in parameter gradients during the backward process of DNNs has received insufficient attention. Existing studies on gradient disparities mainly focus on the utilization of gradient norms, neglecting the wealth of information embedded in gradient directions. To bridge this gap, in this paper, we conduct a comprehensive investigation into leveraging the entirety of gradient information for OOD detection. The primary challenge arises from the high dimensionality of gradients due to the large number of network parameters. To solve this problem, we propose performing linear dimension reduction on the gradient using a designated subspace that comprises principal components. This innovative technique enables us to obtain a low-dimensional representation of the gradient with minimal information loss. Subsequently, by integrating the reduced gradient with various existing detection score functions, our approach demonstrates superior performance across a wide range of detection tasks. For instance, on the ImageNet benchmark, our method achieves an average reduction of 11.15% in the false positive rate at 95% recall (FPR95) compared to the current state-of-the-art approach. The code would be released.
FMMRec: Fairness-aware Multimodal Recommendation
Oct 26, 2023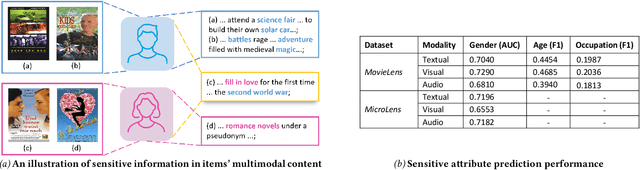

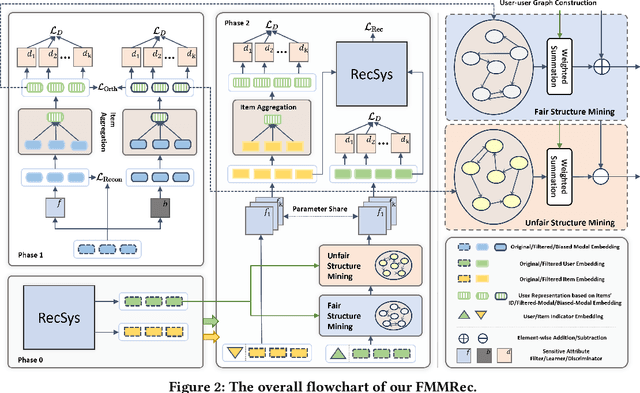
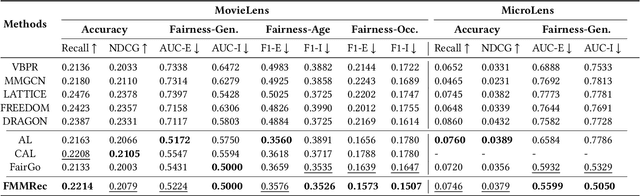
Recently, multimodal recommendations have gained increasing attention for effectively addressing the data sparsity problem by incorporating modality-based representations. Although multimodal recommendations excel in accuracy, the introduction of different modalities (e.g., images, text, and audio) may expose more users' sensitive information (e.g., gender and age) to recommender systems, resulting in potentially more serious unfairness issues. Despite many efforts on fairness, existing fairness-aware methods are either incompatible with multimodal scenarios, or lead to suboptimal fairness performance due to neglecting sensitive information of multimodal content. To achieve counterfactual fairness in multimodal recommendations, we propose a novel fairness-aware multimodal recommendation approach (dubbed as FMMRec) to disentangle the sensitive and non-sensitive information from modal representations and leverage the disentangled modal representations to guide fairer representation learning. Specifically, we first disentangle biased and filtered modal representations by maximizing and minimizing their sensitive attribute prediction ability respectively. With the disentangled modal representations, we mine the modality-based unfair and fair (corresponding to biased and filtered) user-user structures for enhancing explicit user representation with the biased and filtered neighbors from the corresponding structures, followed by adversarially filtering out sensitive information. Experiments on two real-world public datasets demonstrate the superiority of our FMMRec relative to the state-of-the-art baselines. Our source code is available at https://anonymous.4open.science/r/FMMRec.
Multimodal deep representation learning for quantum cross-platform verification
Nov 07, 2023Cross-platform verification, a critical undertaking in the realm of early-stage quantum computing, endeavors to characterize the similarity of two imperfect quantum devices executing identical algorithms, utilizing minimal measurements. While the random measurement approach has been instrumental in this context, the quasi-exponential computational demand with increasing qubit count hurdles its feasibility in large-qubit scenarios. To bridge this knowledge gap, here we introduce an innovative multimodal learning approach, recognizing that the formalism of data in this task embodies two distinct modalities: measurement outcomes and classical description of compiled circuits on explored quantum devices, both enriched with unique information. Building upon this insight, we devise a multimodal neural network to independently extract knowledge from these modalities, followed by a fusion operation to create a comprehensive data representation. The learned representation can effectively characterize the similarity between the explored quantum devices when executing new quantum algorithms not present in the training data. We evaluate our proposal on platforms featuring diverse noise models, encompassing system sizes up to 50 qubits. The achieved results demonstrate a three-orders-of-magnitude improvement in prediction accuracy compared to the random measurements and offer compelling evidence of the complementary roles played by each modality in cross-platform verification. These findings pave the way for harnessing the power of multimodal learning to overcome challenges in wider quantum system learning tasks.
Blind Federated Learning via Over-the-Air q-QAM
Nov 07, 2023In this work, we investigate federated edge learning over a fading multiple access channel. To alleviate the communication burden between the edge devices and the access point, we introduce a pioneering digital over-the-air computation strategy employing q-ary quadrature amplitude modulation, culminating in a low latency communication scheme. Indeed, we propose a new federated edge learning framework in which edge devices use digital modulation for over-the-air uplink transmission to the edge server while they have no access to the channel state information. Furthermore, we incorporate multiple antennas at the edge server to overcome the fading inherent in wireless communication. We analyze the number of antennas required to mitigate the fading impact effectively. We prove a non-asymptotic upper bound for the mean squared error for the proposed federated learning with digital over-the-air uplink transmissions under both noisy and fading conditions. Leveraging the derived upper bound, we characterize the convergence rate of the learning process of a non-convex loss function in terms of the mean square error of gradients due to the fading channel. Furthermore, we substantiate the theoretical assurances through numerical experiments concerning mean square error and the convergence efficacy of the digital federated edge learning framework. Notably, the results demonstrate that augmenting the number of antennas at the edge server and adopting higher-order modulations improve the model accuracy up to 60\%.
OrthoNets: Orthogonal Channel Attention Networks
Nov 07, 2023Designing an effective channel attention mechanism implores one to find a lossy-compression method allowing for optimal feature representation. Despite recent progress in the area, it remains an open problem. FcaNet, the current state-of-the-art channel attention mechanism, attempted to find such an information-rich compression using Discrete Cosine Transforms (DCTs). One drawback of FcaNet is that there is no natural choice of the DCT frequencies. To circumvent this issue, FcaNet experimented on ImageNet to find optimal frequencies. We hypothesize that the choice of frequency plays only a supporting role and the primary driving force for the effectiveness of their attention filters is the orthogonality of the DCT kernels. To test this hypothesis, we construct an attention mechanism using randomly initialized orthogonal filters. Integrating this mechanism into ResNet, we create OrthoNet. We compare OrthoNet to FcaNet (and other attention mechanisms) on Birds, MS-COCO, and Places356 and show superior performance. On the ImageNet dataset, our method competes with or surpasses the current state-of-the-art. Our results imply that an optimal choice of filter is elusive and generalization can be achieved with a sufficiently large number of orthogonal filters. We further investigate other general principles for implementing channel attention, such as its position in the network and channel groupings. Our code is publicly available at https://github.com/hady1011/OrthoNets/
* IEEE BigData 2023
FusionViT: Hierarchical 3D Object Detection via LiDAR-Camera Vision Transformer Fusion
Nov 07, 2023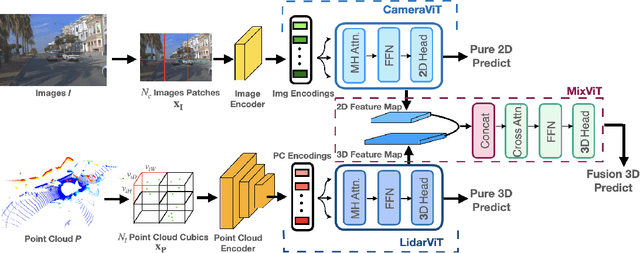
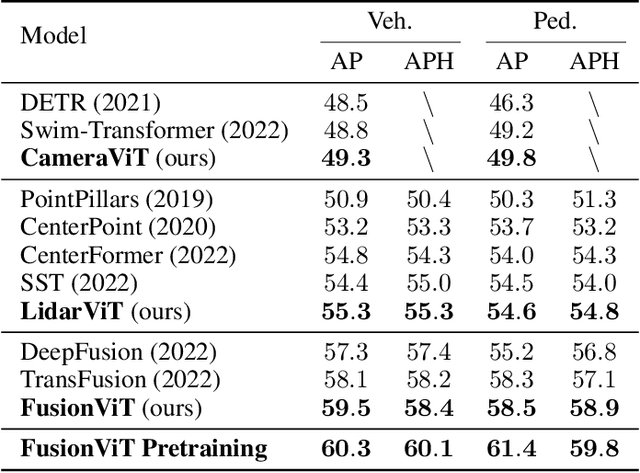
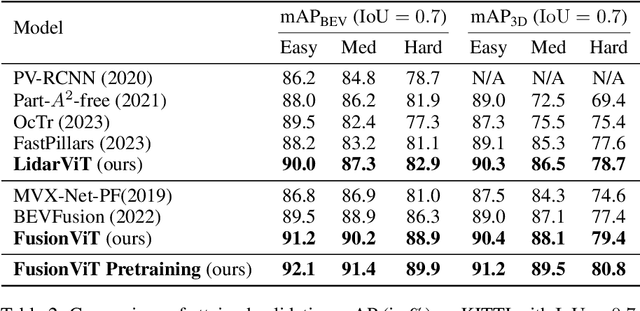

For 3D object detection, both camera and lidar have been demonstrated to be useful sensory devices for providing complementary information about the same scenery with data representations in different modalities, e.g., 2D RGB image vs 3D point cloud. An effective representation learning and fusion of such multi-modal sensor data is necessary and critical for better 3D object detection performance. To solve the problem, in this paper, we will introduce a novel vision transformer-based 3D object detection model, namely FusionViT. Different from the existing 3D object detection approaches, FusionViT is a pure-ViT based framework, which adopts a hierarchical architecture by extending the transformer model to embed both images and point clouds for effective representation learning. Such multi-modal data embedding representations will be further fused together via a fusion vision transformer model prior to feeding the learned features to the object detection head for both detection and localization of the 3D objects in the input scenery. To demonstrate the effectiveness of FusionViT, extensive experiments have been done on real-world traffic object detection benchmark datasets KITTI and Waymo Open. Notably, our FusionViT model can achieve state-of-the-art performance and outperforms not only the existing baseline methods that merely rely on camera images or lidar point clouds, but also the latest multi-modal image-point cloud deep fusion approaches.
Holistic Analysis of Hallucination in GPT-4V(ision): Bias and Interference Challenges
Nov 07, 2023While GPT-4V(ision) impressively models both visual and textual information simultaneously, it's hallucination behavior has not been systematically assessed. To bridge this gap, we introduce a new benchmark, namely, the Bias and Interference Challenges in Visual Language Models (Bingo). This benchmark is designed to evaluate and shed light on the two common types of hallucinations in visual language models: bias and interference. Here, bias refers to the model's tendency to hallucinate certain types of responses, possibly due to imbalance in its training data. Interference pertains to scenarios where the judgment of GPT-4V(ision) can be disrupted due to how the text prompt is phrased or how the input image is presented. We identify a notable regional bias, whereby GPT-4V(ision) is better at interpreting Western images or images with English writing compared to images from other countries or containing text in other languages. Moreover, GPT-4V(ision) is vulnerable to leading questions and is often confused when interpreting multiple images together. Popular mitigation approaches, such as self-correction and chain-of-thought reasoning, are not effective in resolving these challenges. We also identified similar biases and interference vulnerabilities with LLaVA and Bard. Our results characterize the hallucination challenges in GPT-4V(ision) and state-of-the-art visual-language models, and highlight the need for new solutions. The Bingo benchmark is available at https://github.com/gzcch/Bingo.