 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Seeing Through the Conversation: Audio-Visual Speech Separation based on Diffusion Model
Oct 30, 2023
The objective of this work is to extract target speaker's voice from a mixture of voices using visual cues. Existing works on audio-visual speech separation have demonstrated their performance with promising intelligibility, but maintaining naturalness remains a challenge. To address this issue, we propose AVDiffuSS, an audio-visual speech separation model based on a diffusion mechanism known for its capability in generating natural samples. For an effective fusion of the two modalities for diffusion, we also propose a cross-attention-based feature fusion mechanism. This mechanism is specifically tailored for the speech domain to integrate the phonetic information from audio-visual correspondence in speech generation. In this way, the fusion process maintains the high temporal resolution of the features, without excessive computational requirements. We demonstrate that the proposed framework achieves state-of-the-art results on two benchmarks, including VoxCeleb2 and LRS3, producing speech with notably better naturalness.
BioInstruct: Instruction Tuning of Large Language Models for Biomedical Natural Language Processing
Oct 30, 2023Large language models (LLMs) has achieved a great success in many natural language processing (NLP) tasks. This is achieved by pretraining of LLMs on vast amount of data and then instruction tuning to specific domains. However, only a few instructions in the biomedical domain have been published. To address this issue, we introduce BioInstruct, a customized task-specific instruction dataset containing more than 25,000 examples. This dataset was generated attractively by prompting a GPT-4 language model with a three-seed-sample of 80 human-curated instructions. By fine-tuning LLMs using the BioInstruct dataset, we aim to optimize the LLM's performance in biomedical natural language processing (BioNLP). We conducted instruction tuning on the LLaMA LLMs (1\&2, 7B\&13B) and evaluated them on BioNLP applications, including information extraction, question answering, and text generation. We also evaluated how instructions contributed to model performance using multi-tasking learning principles.
Preventing Language Models From Hiding Their Reasoning
Oct 31, 2023Large language models (LLMs) often benefit from intermediate steps of reasoning to generate answers to complex problems. When these intermediate steps of reasoning are used to monitor the activity of the model, it is essential that this explicit reasoning is faithful, i.e. that it reflects what the model is actually reasoning about. In this work, we focus on one potential way intermediate steps of reasoning could be unfaithful: encoded reasoning, where an LLM could encode intermediate steps of reasoning in the generated text in a way that is not understandable to human readers. We show that language models can be trained to make use of encoded reasoning to get higher performance without the user understanding the intermediate steps of reasoning. We argue that, as language models get stronger, this behavior becomes more likely to appear naturally. Finally, we describe a methodology that enables the evaluation of defenses against encoded reasoning, and show that, under the right conditions, paraphrasing successfully prevents even the best encoding schemes we built from encoding more than 3 bits of information per KB of text.
SemanticBoost: Elevating Motion Generation with Augmented Textual Cues
Oct 31, 2023Current techniques face difficulties in generating motions from intricate semantic descriptions, primarily due to insufficient semantic annotations in datasets and weak contextual understanding. To address these issues, we present SemanticBoost, a novel framework that tackles both challenges simultaneously. Our framework comprises a Semantic Enhancement module and a Context-Attuned Motion Denoiser (CAMD). The Semantic Enhancement module extracts supplementary semantics from motion data, enriching the dataset's textual description and ensuring precise alignment between text and motion data without depending on large language models. On the other hand, the CAMD approach provides an all-encompassing solution for generating high-quality, semantically consistent motion sequences by effectively capturing context information and aligning the generated motion with the given textual descriptions. Distinct from existing methods, our approach can synthesize accurate orientational movements, combined motions based on specific body part descriptions, and motions generated from complex, extended sentences. Our experimental results demonstrate that SemanticBoost, as a diffusion-based method, outperforms auto-regressive-based techniques, achieving cutting-edge performance on the Humanml3D dataset while maintaining realistic and smooth motion generation quality.
HEDNet: A Hierarchical Encoder-Decoder Network for 3D Object Detection in Point Clouds
Oct 31, 2023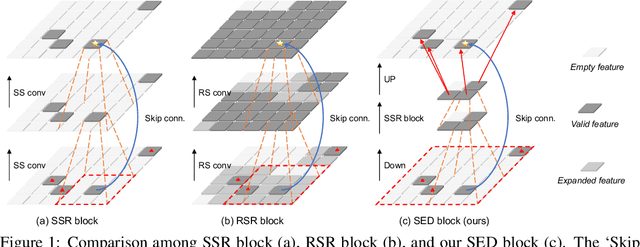
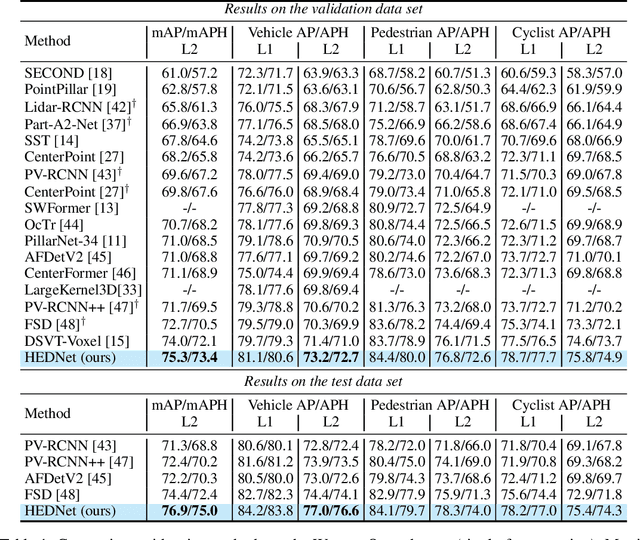
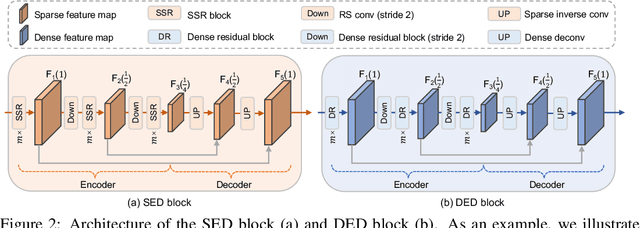
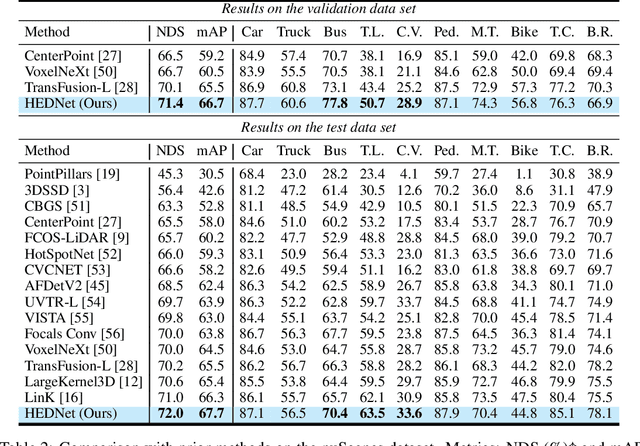
3D object detection in point clouds is important for autonomous driving systems. A primary challenge in 3D object detection stems from the sparse distribution of points within the 3D scene. Existing high-performance methods typically employ 3D sparse convolutional neural networks with small kernels to extract features. To reduce computational costs, these methods resort to submanifold sparse convolutions, which prevent the information exchange among spatially disconnected features. Some recent approaches have attempted to address this problem by introducing large-kernel convolutions or self-attention mechanisms, but they either achieve limited accuracy improvements or incur excessive computational costs. We propose HEDNet, a hierarchical encoder-decoder network for 3D object detection, which leverages encoder-decoder blocks to capture long-range dependencies among features in the spatial space, particularly for large and distant objects. We conducted extensive experiments on the Waymo Open and nuScenes datasets. HEDNet achieved superior detection accuracy on both datasets than previous state-of-the-art methods with competitive efficiency. The code is available at https://github.com/zhanggang001/HEDNet.
A Transformer-Based Model With Self-Distillation for Multimodal Emotion Recognition in Conversations
Oct 31, 2023Emotion recognition in conversations (ERC), the task of recognizing the emotion of each utterance in a conversation, is crucial for building empathetic machines. Existing studies focus mainly on capturing context- and speaker-sensitive dependencies on the textual modality but ignore the significance of multimodal information. Different from emotion recognition in textual conversations, capturing intra- and inter-modal interactions between utterances, learning weights between different modalities, and enhancing modal representations play important roles in multimodal ERC. In this paper, we propose a transformer-based model with self-distillation (SDT) for the task. The transformer-based model captures intra- and inter-modal interactions by utilizing intra- and inter-modal transformers, and learns weights between modalities dynamically by designing a hierarchical gated fusion strategy. Furthermore, to learn more expressive modal representations, we treat soft labels of the proposed model as extra training supervision. Specifically, we introduce self-distillation to transfer knowledge of hard and soft labels from the proposed model to each modality. Experiments on IEMOCAP and MELD datasets demonstrate that SDT outperforms previous state-of-the-art baselines.
* 13 pages, 10 figures. Accepted by IEEE Transactions on Multimedia (TMM)
Compact Binary Systems Waveform Generation with Generative Pre-trained Transformer
Oct 31, 2023Space-based gravitational wave detection is one of the most anticipated gravitational wave (GW) detection projects in the next decade, which will detect abundant compact binary systems. However, the precise prediction of space GW waveforms remains unexplored. To solve the data processing difficulty in the increasing waveform complexity caused by detectors' response and second-generation time-delay interferometry (TDI 2.0), an interpretable pre-trained large model named CBS-GPT (Compact Binary Systems Waveform Generation with Generative Pre-trained Transformer) is proposed. For compact binary system waveforms, three models were trained to predict the waveforms of massive black hole binary (MBHB), extreme mass-ratio inspirals (EMRIs), and galactic binary (GB), achieving prediction accuracies of 98%, 91%, and 99%, respectively. The CBS-GPT model exhibits notable interpretability, with its hidden parameters effectively capturing the intricate information of waveforms, even with complex instrument response and a wide parameter range. Our research demonstrates the potential of large pre-trained models in gravitational wave data processing, opening up new opportunities for future tasks such as gap completion, GW signal detection, and signal noise reduction.
SignGT: Signed Attention-based Graph Transformer for Graph Representation Learning
Oct 17, 2023The emerging graph Transformers have achieved impressive performance for graph representation learning over graph neural networks (GNNs). In this work, we regard the self-attention mechanism, the core module of graph Transformers, as a two-step aggregation operation on a fully connected graph. Due to the property of generating positive attention values, the self-attention mechanism is equal to conducting a smooth operation on all nodes, preserving the low-frequency information. However, only capturing the low-frequency information is inefficient in learning complex relations of nodes on diverse graphs, such as heterophily graphs where the high-frequency information is crucial. To this end, we propose a Signed Attention-based Graph Transformer (SignGT) to adaptively capture various frequency information from the graphs. Specifically, SignGT develops a new signed self-attention mechanism (SignSA) that produces signed attention values according to the semantic relevance of node pairs. Hence, the diverse frequency information between different node pairs could be carefully preserved. Besides, SignGT proposes a structure-aware feed-forward network (SFFN) that introduces the neighborhood bias to preserve the local topology information. In this way, SignGT could learn informative node representations from both long-range dependencies and local topology information. Extensive empirical results on both node-level and graph-level tasks indicate the superiority of SignGT against state-of-the-art graph Transformers as well as advanced GNNs.
Detecting Pretraining Data from Large Language Models
Nov 03, 2023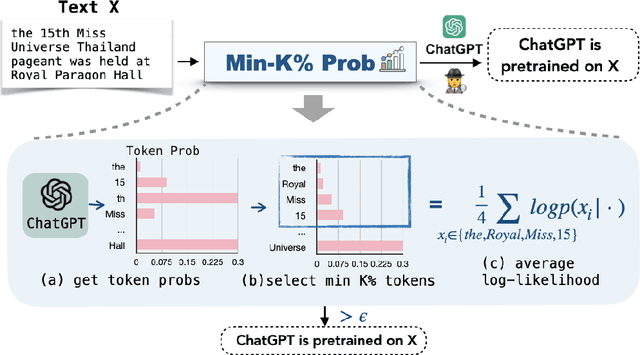
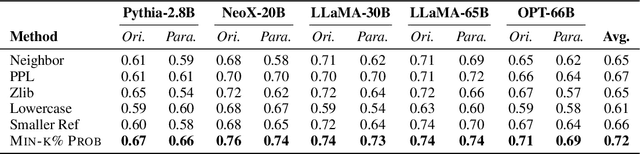
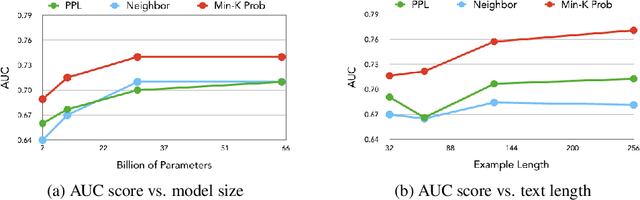

Although large language models (LLMs) are widely deployed, the data used to train them is rarely disclosed. Given the incredible scale of this data, up to trillions of tokens, it is all but certain that it includes potentially problematic text such as copyrighted materials, personally identifiable information, and test data for widely reported reference benchmarks. However, we currently have no way to know which data of these types is included or in what proportions. In this paper, we study the pretraining data detection problem: given a piece of text and black-box access to an LLM without knowing the pretraining data, can we determine if the model was trained on the provided text? To facilitate this study, we introduce a dynamic benchmark WIKIMIA that uses data created before and after model training to support gold truth detection. We also introduce a new detection method Min-K% Prob based on a simple hypothesis: an unseen example is likely to contain a few outlier words with low probabilities under the LLM, while a seen example is less likely to have words with such low probabilities. Min-K% Prob can be applied without any knowledge about the pretraining corpus or any additional training, departing from previous detection methods that require training a reference model on data that is similar to the pretraining data. Moreover, our experiments demonstrate that Min-K% Prob achieves a 7.4% improvement on WIKIMIA over these previous methods. We apply Min-K% Prob to three real-world scenarios, copyrighted book detection, contaminated downstream example detection and privacy auditing of machine unlearning, and find it a consistently effective solution.
How a student becomes a teacher: learning and forgetting through Spectral methods
Nov 03, 2023In theoretical ML, the teacher-student paradigm is often employed as an effective metaphor for real-life tuition. The above scheme proves particularly relevant when the student network is overparameterized as compared to the teacher network. Under these operating conditions, it is tempting to speculate that the student ability to handle the given task could be eventually stored in a sub-portion of the whole network. This latter should be to some extent reminiscent of the frozen teacher structure, according to suitable metrics, while being approximately invariant across different architectures of the student candidate network. Unfortunately, state-of-the-art conventional learning techniques could not help in identifying the existence of such an invariant subnetwork, due to the inherent degree of non-convexity that characterizes the examined problem. In this work, we take a leap forward by proposing a radically different optimization scheme which builds on a spectral representation of the linear transfer of information between layers. The gradient is hence calculated with respect to both eigenvalues and eigenvectors with negligible increase in terms of computational and complexity load, as compared to standard training algorithms. Working in this framework, we could isolate a stable student substructure, that mirrors the true complexity of the teacher in terms of computing neurons, path distribution and topological attributes. When pruning unimportant nodes of the trained student, as follows a ranking that reflects the optimized eigenvalues, no degradation in the recorded performance is seen above a threshold that corresponds to the effective teacher size. The observed behavior can be pictured as a genuine second-order phase transition that bears universality traits.
* 10 pages + references + supplemental material. Poster presentation at NeurIPS 2023