 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
BanMANI: A Dataset to Identify Manipulated Social Media News in Bangla
Nov 05, 2023
Initial work has been done to address fake news detection and misrepresentation of news in the Bengali language. However, no work in Bengali yet addresses the identification of specific claims in social media news that falsely manipulates a related news article. At this point, this problem has been tackled in English and a few other languages, but not in the Bengali language. In this paper, we curate a dataset of social media content labeled with information manipulation relative to reference articles, called BanMANI. The dataset collection method we describe works around the limitations of the available NLP tools in Bangla. We expect these techniques will carry over to building similar datasets in other low-resource languages. BanMANI forms the basis both for evaluating the capabilities of existing NLP systems and for training or fine-tuning new models specifically on this task. In our analysis, we find that this task challenges current LLMs both under zero-shot and fine-tuned settings.
Divide & Conquer for Entailment-aware Multi-hop Evidence Retrieval
Nov 05, 2023Lexical and semantic matches are commonly used as relevance measurements for information retrieval. Together they estimate the semantic equivalence between the query and the candidates. However, semantic equivalence is not the only relevance signal that needs to be considered when retrieving evidences for multi-hop questions. In this work, we demonstrate that textual entailment relation is another important relevance dimension that should be considered. To retrieve evidences that are either semantically equivalent to or entailed by the question simultaneously, we divide the task of evidence retrieval for multi-hop question answering (QA) into two sub-tasks, i.e., semantic textual similarity and inference similarity retrieval. We propose two ensemble models, EAR and EARnest, which tackle each of the sub-tasks separately and then jointly re-rank sentences with the consideration of the diverse relevance signals. Experimental results on HotpotQA verify that our models not only significantly outperform all the single retrieval models it is based on, but is also more effective than two intuitive ensemble baseline models.
mahaNLP: A Marathi Natural Language Processing Library
Nov 05, 2023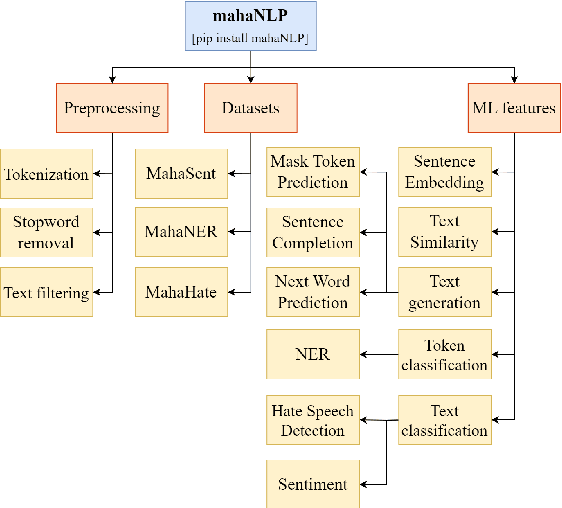
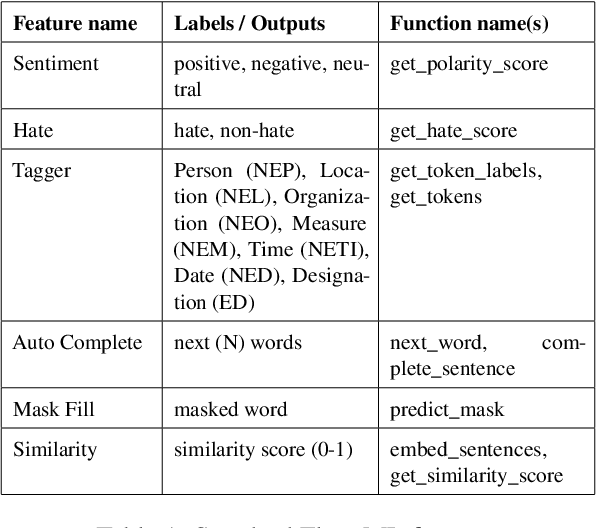
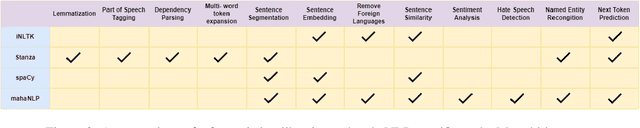

We present mahaNLP, an open-source natural language processing (NLP) library specifically built for the Marathi language. It aims to enhance the support for the low-resource Indian language Marathi in the field of NLP. It is an easy-to-use, extensible, and modular toolkit for Marathi text analysis built on state-of-the-art MahaBERT-based transformer models. Our work holds significant importance as other existing Indic NLP libraries provide basic Marathi processing support and rely on older models with restricted performance. Our toolkit stands out by offering a comprehensive array of NLP tasks, encompassing both fundamental preprocessing tasks and advanced NLP tasks like sentiment analysis, NER, hate speech detection, and sentence completion. This paper focuses on an overview of the mahaNLP framework, its features, and its usage. This work is a part of the L3Cube MahaNLP initiative, more information about it can be found at https://github.com/l3cube-pune/MarathiNLP .
AdaFuse: Adaptive Medical Image Fusion Based on Spatial-Frequential Cross Attention
Oct 24, 2023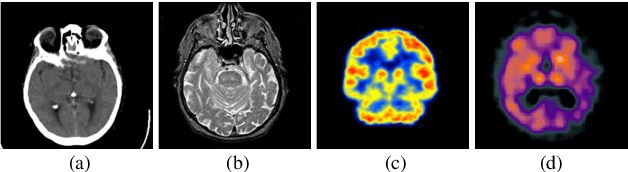
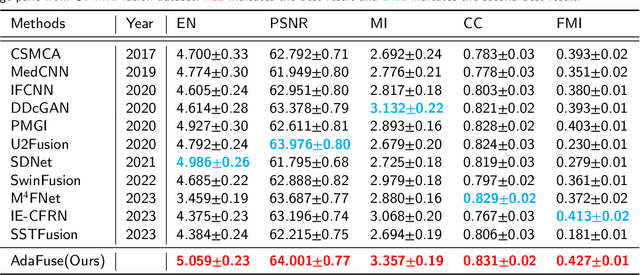
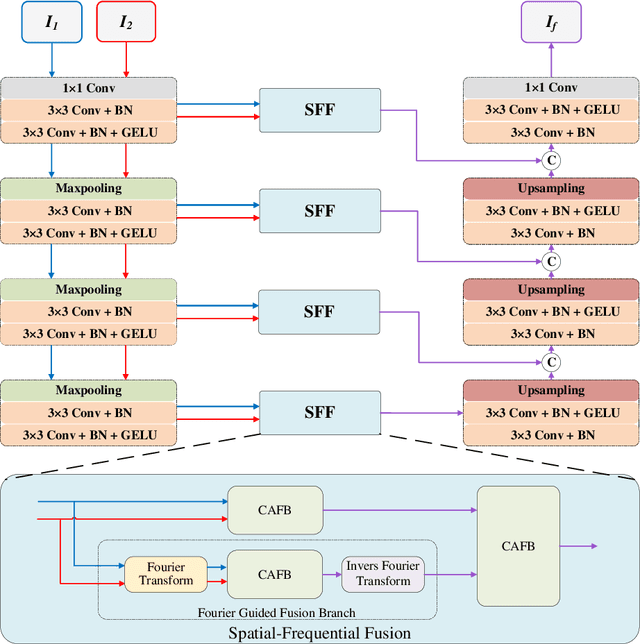
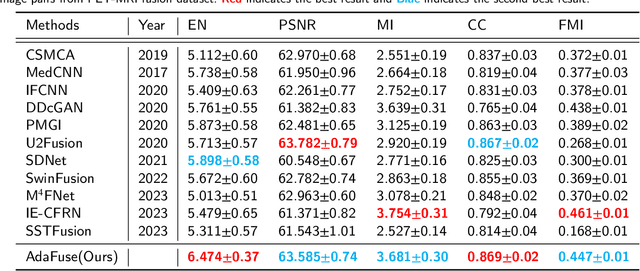
Multi-modal medical image fusion is essential for the precise clinical diagnosis and surgical navigation since it can merge the complementary information in multi-modalities into a single image. The quality of the fused image depends on the extracted single modality features as well as the fusion rules for multi-modal information. Existing deep learning-based fusion methods can fully exploit the semantic features of each modality, they cannot distinguish the effective low and high frequency information of each modality and fuse them adaptively. To address this issue, we propose AdaFuse, in which multimodal image information is fused adaptively through frequency-guided attention mechanism based on Fourier transform. Specifically, we propose the cross-attention fusion (CAF) block, which adaptively fuses features of two modalities in the spatial and frequency domains by exchanging key and query values, and then calculates the cross-attention scores between the spatial and frequency features to further guide the spatial-frequential information fusion. The CAF block enhances the high-frequency features of the different modalities so that the details in the fused images can be retained. Moreover, we design a novel loss function composed of structure loss and content loss to preserve both low and high frequency information. Extensive comparison experiments on several datasets demonstrate that the proposed method outperforms state-of-the-art methods in terms of both visual quality and quantitative metrics. The ablation experiments also validate the effectiveness of the proposed loss and fusion strategy.
Bilateral Network with Residual U-blocks and Dual-Guided Attention for Real-time Semantic Segmentation
Oct 31, 2023When some application scenarios need to use semantic segmentation technology, like automatic driving, the primary concern comes to real-time performance rather than extremely high segmentation accuracy. To achieve a good trade-off between speed and accuracy, two-branch architecture has been proposed in recent years. It treats spatial information and semantics information separately which allows the model to be composed of two networks both not heavy. However, the process of fusing features with two different scales becomes a performance bottleneck for many nowaday two-branch models. In this research, we design a new fusion mechanism for two-branch architecture which is guided by attention computation. To be precise, we use the Dual-Guided Attention (DGA) module we proposed to replace some multi-scale transformations with the calculation of attention which means we only use several attention layers of near linear complexity to achieve performance comparable to frequently-used multi-layer fusion. To ensure that our module can be effective, we use Residual U-blocks (RSU) to build one of the two branches in our networks which aims to obtain better multi-scale features. Extensive experiments on Cityscapes and CamVid dataset show the effectiveness of our method.
Privacy-preserving design of graph neural networks with applications to vertical federated learning
Oct 31, 2023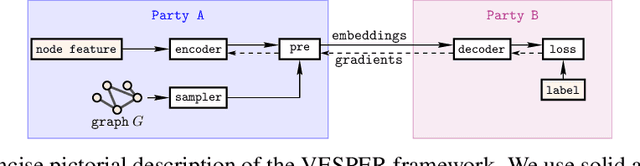
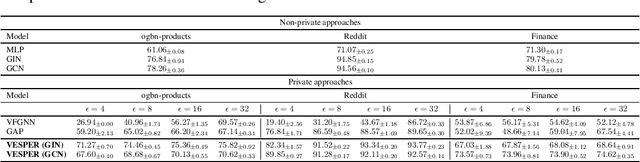
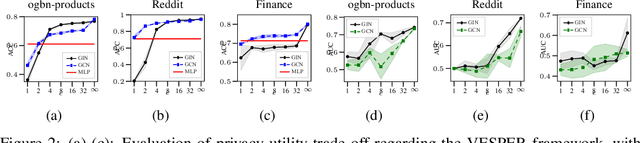
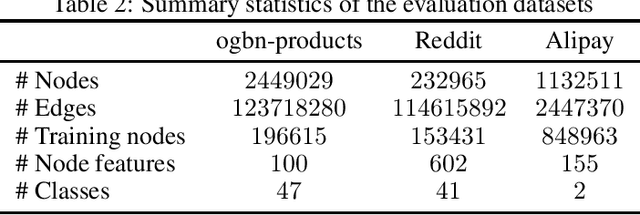
The paradigm of vertical federated learning (VFL), where institutions collaboratively train machine learning models via combining each other's local feature or label information, has achieved great success in applications to financial risk management (FRM). The surging developments of graph representation learning (GRL) have opened up new opportunities for FRM applications under FL via efficiently utilizing the graph-structured data generated from underlying transaction networks. Meanwhile, transaction information is often considered highly sensitive. To prevent data leakage during training, it is critical to develop FL protocols with formal privacy guarantees. In this paper, we present an end-to-end GRL framework in the VFL setting called VESPER, which is built upon a general privatization scheme termed perturbed message passing (PMP) that allows the privatization of many popular graph neural architectures.Based on PMP, we discuss the strengths and weaknesses of specific design choices of concrete graph neural architectures and provide solutions and improvements for both dense and sparse graphs. Extensive empirical evaluations over both public datasets and an industry dataset demonstrate that VESPER is capable of training high-performance GNN models over both sparse and dense graphs under reasonable privacy budgets.
Image Restoration with Point Spread Function Regularization and Active Learning
Oct 31, 2023Large-scale astronomical surveys can capture numerous images of celestial objects, including galaxies and nebulae. Analysing and processing these images can reveal intricate internal structures of these objects, allowing researchers to conduct comprehensive studies on their morphology, evolution, and physical properties. However, varying noise levels and point spread functions can hamper the accuracy and efficiency of information extraction from these images. To mitigate these effects, we propose a novel image restoration algorithm that connects a deep learning-based restoration algorithm with a high-fidelity telescope simulator. During the training stage, the simulator generates images with different levels of blur and noise to train the neural network based on the quality of restored images. After training, the neural network can directly restore images obtained by the telescope, as represented by the simulator. We have tested the algorithm using real and simulated observation data and have found that it effectively enhances fine structures in blurry images and increases the quality of observation images. This algorithm can be applied to large-scale sky survey data, such as data obtained by LSST, Euclid, and CSST, to further improve the accuracy and efficiency of information extraction, promoting advances in the field of astronomical research.
APRICOT: Acuity Prediction in Intensive Care Unit (ICU): Predicting Stability, Transitions, and Life-Sustaining Therapies
Nov 03, 2023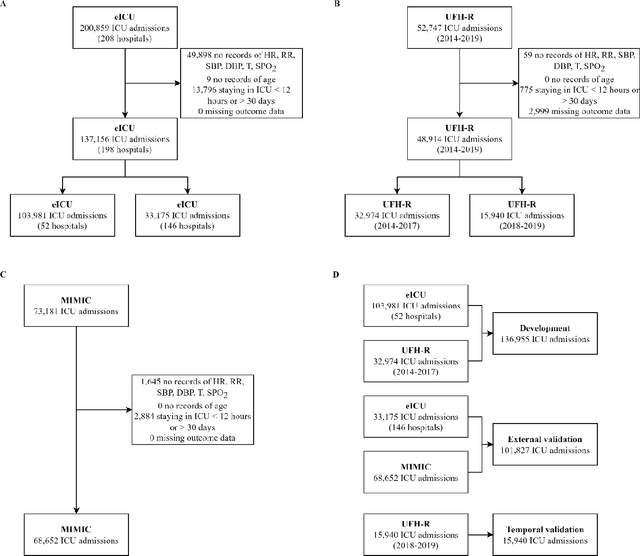
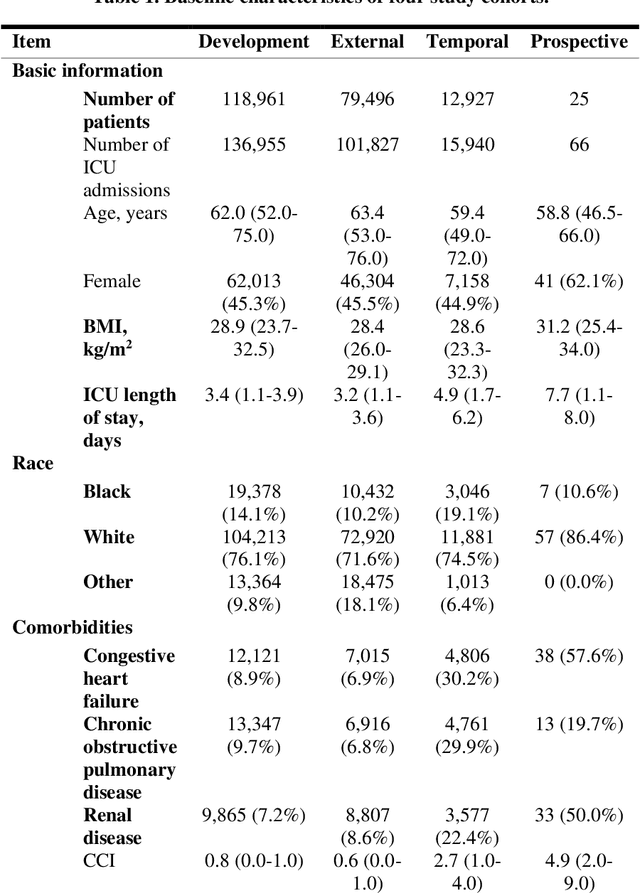
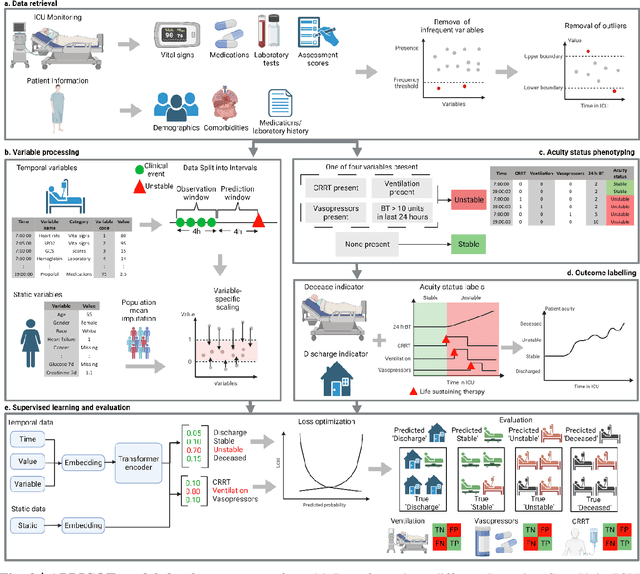
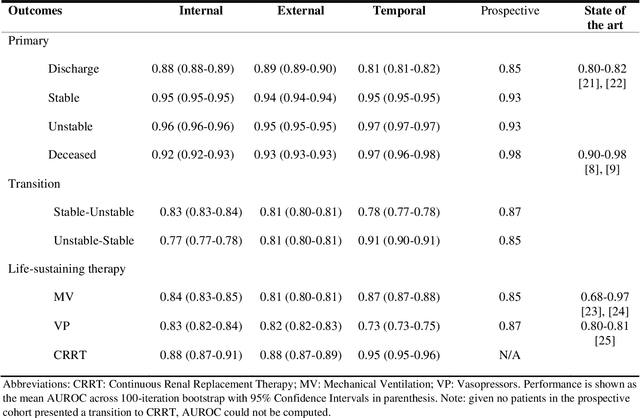
The acuity state of patients in the intensive care unit (ICU) can quickly change from stable to unstable, sometimes leading to life-threatening conditions. Early detection of deteriorating conditions can result in providing more timely interventions and improved survival rates. Current approaches rely on manual daily assessments. Some data-driven approaches have been developed, that use mortality as a proxy of acuity in the ICU. However, these methods do not integrate acuity states to determine the stability of a patient or the need for life-sustaining therapies. In this study, we propose APRICOT (Acuity Prediction in Intensive Care Unit), a Transformer-based neural network to predict acuity state in real-time in ICU patients. We develop and extensively validate externally, temporally, and prospectively the APRICOT model on three large datasets: University of Florida Health (UFH), eICU Collaborative Research Database (eICU), and Medical Information Mart for Intensive Care (MIMIC)-IV. The performance of APRICOT shows comparable results to state-of-the-art mortality prediction models (external AUROC 0.93-0.93, temporal AUROC 0.96-0.98, and prospective AUROC 0.98) as well as acuity prediction models (external AUROC 0.80-0.81, temporal AUROC 0.77-0.78, and prospective AUROC 0.87). Furthermore, APRICOT can make predictions for the need for life-sustaining therapies, showing comparable results to state-of-the-art ventilation prediction models (external AUROC 0.80-0.81, temporal AUROC 0.87-0.88, and prospective AUROC 0.85), and vasopressor prediction models (external AUROC 0.82-0.83, temporal AUROC 0.73-0.75, prospective AUROC 0.87). This tool allows for real-time acuity monitoring of a patient and can provide helpful information to clinicians to make timely interventions. Furthermore, the model can suggest life-sustaining therapies that the patient might need in the next hours in the ICU.
Scattering Vision Transformer: Spectral Mixing Matters
Nov 02, 2023Vision transformers have gained significant attention and achieved state-of-the-art performance in various computer vision tasks, including image classification, instance segmentation, and object detection. However, challenges remain in addressing attention complexity and effectively capturing fine-grained information within images. Existing solutions often resort to down-sampling operations, such as pooling, to reduce computational cost. Unfortunately, such operations are non-invertible and can result in information loss. In this paper, we present a novel approach called Scattering Vision Transformer (SVT) to tackle these challenges. SVT incorporates a spectrally scattering network that enables the capture of intricate image details. SVT overcomes the invertibility issue associated with down-sampling operations by separating low-frequency and high-frequency components. Furthermore, SVT introduces a unique spectral gating network utilizing Einstein multiplication for token and channel mixing, effectively reducing complexity. We show that SVT achieves state-of-the-art performance on the ImageNet dataset with a significant reduction in a number of parameters and FLOPS. SVT shows 2\% improvement over LiTv2 and iFormer. SVT-H-S reaches 84.2\% top-1 accuracy, while SVT-H-B reaches 85.2\% (state-of-art for base versions) and SVT-H-L reaches 85.7\% (again state-of-art for large versions). SVT also shows comparable results in other vision tasks such as instance segmentation. SVT also outperforms other transformers in transfer learning on standard datasets such as CIFAR10, CIFAR100, Oxford Flower, and Stanford Car datasets. The project page is available on this webpage.\url{https://badripatro.github.io/svt/}.
Recognize Any Regions
Nov 02, 2023Understanding the semantics of individual regions or patches within unconstrained images, such as in open-world object detection, represents a critical yet challenging task in computer vision. Building on the success of powerful image-level vision-language (ViL) foundation models like CLIP, recent efforts have sought to harness their capabilities by either training a contrastive model from scratch with an extensive collection of region-label pairs or aligning the outputs of a detection model with image-level representations of region proposals. Despite notable progress, these approaches are plagued by computationally intensive training requirements, susceptibility to data noise, and deficiency in contextual information. To address these limitations, we explore the synergistic potential of off-the-shelf foundation models, leveraging their respective strengths in localization and semantics. We introduce a novel, generic, and efficient region recognition architecture, named RegionSpot, designed to integrate position-aware localization knowledge from a localization foundation model (e.g., SAM) with semantic information extracted from a ViL model (e.g., CLIP). To fully exploit pretrained knowledge while minimizing training overhead, we keep both foundation models frozen, focusing optimization efforts solely on a lightweight attention-based knowledge integration module. Through extensive experiments in the context of open-world object recognition, our RegionSpot demonstrates significant performance improvements over prior alternatives, while also providing substantial computational savings. For instance, training our model with 3 million data in a single day using 8 V100 GPUs. Our model outperforms GLIP by 6.5 % in mean average precision (mAP), with an even larger margin by 14.8 % for more challenging and rare categories.