 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Investigative Pattern Detection Framework for Counterterrorism
Oct 30, 2023
Law-enforcement investigations aimed at preventing attacks by violent extremists have become increasingly important for public safety. The problem is exacerbated by the massive data volumes that need to be scanned to identify complex behaviors of extremists and groups. Automated tools are required to extract information to respond queries from analysts, continually scan new information, integrate them with past events, and then alert about emerging threats. We address challenges in investigative pattern detection and develop an Investigative Pattern Detection Framework for Counterterrorism (INSPECT). The framework integrates numerous computing tools that include machine learning techniques to identify behavioral indicators and graph pattern matching techniques to detect risk profiles/groups. INSPECT also automates multiple tasks for large-scale mining of detailed forensic biographies, forming knowledge networks, and querying for behavioral indicators and radicalization trajectories. INSPECT targets human-in-the-loop mode of investigative search and has been validated and evaluated using an evolving dataset on domestic jihadism.
Leveraging Deep Learning for Abstractive Code Summarization of Unofficial Documentation
Nov 07, 2023Usually, programming languages have official documentation to guide developers with APIs, methods, and classes. However, researchers identified insufficient or inadequate documentation examples and flaws with the API's complex structure as barriers to learning an API. As a result, developers may consult other sources (StackOverflow, GitHub, etc.) to learn more about an API. Recent research studies have shown that unofficial documentation is a valuable source of information for generating code summaries. We, therefore, have been motivated to leverage such a type of documentation along with deep learning techniques towards generating high-quality summaries for APIs discussed in informal documentation. This paper proposes an automatic approach using the BART algorithm, a state-of-the-art transformer model, to generate summaries for APIs discussed in StackOverflow. We built an oracle of human-generated summaries to evaluate our approach against it using ROUGE and BLEU metrics which are the most widely used evaluation metrics in text summarization. Furthermore, we evaluated our summaries empirically against a previous work in terms of quality. Our findings demonstrate that using deep learning algorithms can improve summaries' quality and outperform the previous work by an average of %57 for Precision, %66 for Recall, and %61 for F-measure, and it runs 4.4 times faster.
mmFUSION: Multimodal Fusion for 3D Objects Detection
Nov 07, 2023Multi-sensor fusion is essential for accurate 3D object detection in self-driving systems. Camera and LiDAR are the most commonly used sensors, and usually, their fusion happens at the early or late stages of 3D detectors with the help of regions of interest (RoIs). On the other hand, fusion at the intermediate level is more adaptive because it does not need RoIs from modalities but is complex as the features of both modalities are presented from different points of view. In this paper, we propose a new intermediate-level multi-modal fusion (mmFUSION) approach to overcome these challenges. First, the mmFUSION uses separate encoders for each modality to compute features at a desired lower space volume. Second, these features are fused through cross-modality and multi-modality attention mechanisms proposed in mmFUSION. The mmFUSION framework preserves multi-modal information and learns to complement modalities' deficiencies through attention weights. The strong multi-modal features from the mmFUSION framework are fed to a simple 3D detection head for 3D predictions. We evaluate mmFUSION on the KITTI and NuScenes dataset where it performs better than available early, intermediate, late, and even two-stage based fusion schemes. The code with the mmdetection3D project plugin will be publicly available soon.
Emergence of Abstract State Representations in Embodied Sequence Modeling
Nov 07, 2023Decision making via sequence modeling aims to mimic the success of language models, where actions taken by an embodied agent are modeled as tokens to predict. Despite their promising performance, it remains unclear if embodied sequence modeling leads to the emergence of internal representations that represent the environmental state information. A model that lacks abstract state representations would be liable to make decisions based on surface statistics which fail to generalize. We take the BabyAI environment, a grid world in which language-conditioned navigation tasks are performed, and build a sequence modeling Transformer, which takes a language instruction, a sequence of actions, and environmental observations as its inputs. In order to investigate the emergence of abstract state representations, we design a "blindfolded" navigation task, where only the initial environmental layout, the language instruction, and the action sequence to complete the task are available for training. Our probing results show that intermediate environmental layouts can be reasonably reconstructed from the internal activations of a trained model, and that language instructions play a role in the reconstruction accuracy. Our results suggest that many key features of state representations can emerge via embodied sequence modeling, supporting an optimistic outlook for applications of sequence modeling objectives to more complex embodied decision-making domains.
Decentralized Personalized Online Federated Learning
Nov 08, 2023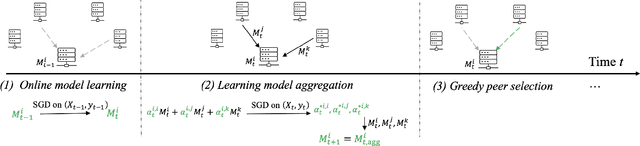
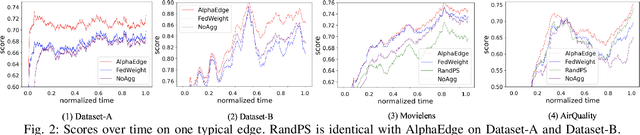
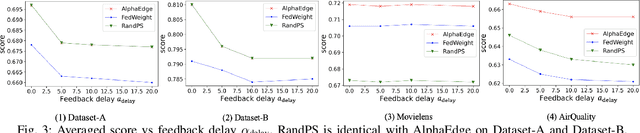
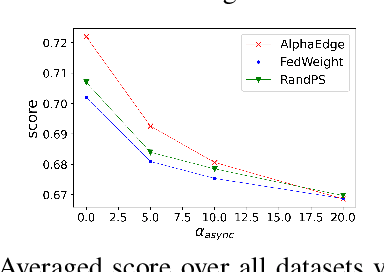
Vanilla federated learning does not support learning in an online environment, learning a personalized model on each client, and learning in a decentralized setting. There are existing methods extending federated learning in each of the three aspects. However, some important applications on enterprise edge servers (e.g. online item recommendation at global scale) involve the three aspects at the same time. Therefore, we propose a new learning setting \textit{Decentralized Personalized Online Federated Learning} that considers all the three aspects at the same time. In this new setting for learning, the first technical challenge is how to aggregate the shared model parameters from neighboring clients to obtain a personalized local model with good performance on each client. We propose to directly learn an aggregation by optimizing the performance of the local model with respect to the aggregation weights. This not only improves personalization of each local model but also helps the local model adapting to potential data shift by intelligently incorporating the right amount of information from its neighbors. The second challenge is how to select the neighbors for each client. We propose a peer selection method based on the learned aggregation weights enabling each client to select the most helpful neighbors and reduce communication cost at the same time. We verify the effectiveness and robustness of our proposed method on three real-world item recommendation datasets and one air quality prediction dataset.
Dual-Directed Algorithm Design for Efficient Pure Exploration
Oct 30, 2023We consider pure-exploration problems in the context of stochastic sequential adaptive experiments with a finite set of alternative options. The goal of the decision-maker is to accurately answer a query question regarding the alternatives with high confidence with minimal measurement efforts. A typical query question is to identify the alternative with the best performance, leading to ranking and selection problems, or best-arm identification in the machine learning literature. We focus on the fixed-precision setting and derive a sufficient condition for optimality in terms of a notion of strong convergence to the optimal allocation of samples. Using dual variables, we characterize the necessary and sufficient conditions for an allocation to be optimal. The use of dual variables allow us to bypass the combinatorial structure of the optimality conditions that relies solely on primal variables. Remarkably, these optimality conditions enable an extension of top-two algorithm design principle, initially proposed for best-arm identification. Furthermore, our optimality conditions give rise to a straightforward yet efficient selection rule, termed information-directed selection, which adaptively picks from a candidate set based on information gain of the candidates. We outline the broad contexts where our algorithmic approach can be implemented. We establish that, paired with information-directed selection, top-two Thompson sampling is (asymptotically) optimal for Gaussian best-arm identification, solving a glaring open problem in the pure exploration literature. Our algorithm is optimal for $\epsilon$-best-arm identification and thresholding bandit problems. Our analysis also leads to a general principle to guide adaptations of Thompson sampling for pure-exploration problems. Numerical experiments highlight the exceptional efficiency of our proposed algorithms relative to existing ones.
Leave No Stone Unturned: Mine Extra Knowledge for Imbalanced Facial Expression Recognition
Oct 30, 2023Facial expression data is characterized by a significant imbalance, with most collected data showing happy or neutral expressions and fewer instances of fear or disgust. This imbalance poses challenges to facial expression recognition (FER) models, hindering their ability to fully understand various human emotional states. Existing FER methods typically report overall accuracy on highly imbalanced test sets but exhibit low performance in terms of the mean accuracy across all expression classes. In this paper, our aim is to address the imbalanced FER problem. Existing methods primarily focus on learning knowledge of minor classes solely from minor-class samples. However, we propose a novel approach to extract extra knowledge related to the minor classes from both major and minor class samples. Our motivation stems from the belief that FER resembles a distribution learning task, wherein a sample may contain information about multiple classes. For instance, a sample from the major class surprise might also contain useful features of the minor class fear. Inspired by that, we propose a novel method that leverages re-balanced attention maps to regularize the model, enabling it to extract transformation invariant information about the minor classes from all training samples. Additionally, we introduce re-balanced smooth labels to regulate the cross-entropy loss, guiding the model to pay more attention to the minor classes by utilizing the extra information regarding the label distribution of the imbalanced training data. Extensive experiments on different datasets and backbones show that the two proposed modules work together to regularize the model and achieve state-of-the-art performance under the imbalanced FER task. Code is available at https://github.com/zyh-uaiaaaa.
Generative retrieval-augmented ontologic graph and multi-agent strategies for interpretive large language model-based materials design
Oct 30, 2023Transformer neural networks show promising capabilities, in particular for uses in materials analysis, design and manufacturing, including their capacity to work effectively with both human language, symbols, code, and numerical data. Here we explore the use of large language models (LLMs) as a tool that can support engineering analysis of materials, applied to retrieving key information about subject areas, developing research hypotheses, discovery of mechanistic relationships across disparate areas of knowledge, and writing and executing simulation codes for active knowledge generation based on physical ground truths. When used as sets of AI agents with specific features, capabilities, and instructions, LLMs can provide powerful problem solution strategies for applications in analysis and design problems. Our experiments focus on using a fine-tuned model, MechGPT, developed based on training data in the mechanics of materials domain. We first affirm how finetuning endows LLMs with reasonable understanding of domain knowledge. However, when queried outside the context of learned matter, LLMs can have difficulty to recall correct information. We show how this can be addressed using retrieval-augmented Ontological Knowledge Graph strategies that discern how the model understands what concepts are important and how they are related. Illustrated for a use case of relating distinct areas of knowledge - here, music and proteins - such strategies can also provide an interpretable graph structure with rich information at the node, edge and subgraph level. We discuss nonlinear sampling strategies and agent-based modeling applied to complex question answering, code generation and execution in the context of automated force field development from actively learned Density Functional Theory (DFT) modeling, and data analysis.
AdaFuse: Adaptive Medical Image Fusion Based on Spatial-Frequential Cross Attention
Oct 24, 2023
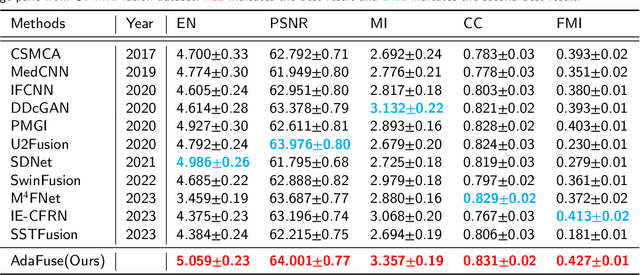
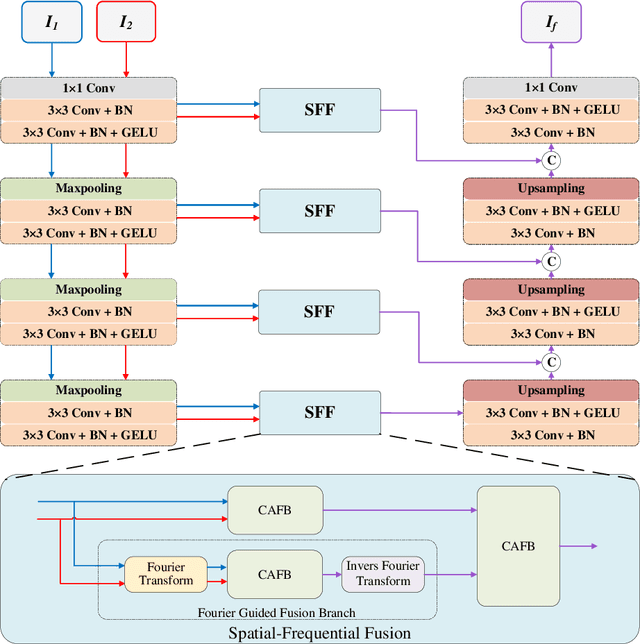
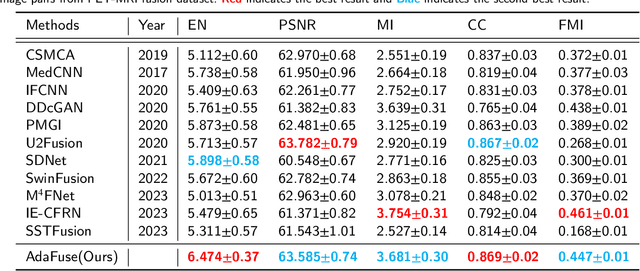
Multi-modal medical image fusion is essential for the precise clinical diagnosis and surgical navigation since it can merge the complementary information in multi-modalities into a single image. The quality of the fused image depends on the extracted single modality features as well as the fusion rules for multi-modal information. Existing deep learning-based fusion methods can fully exploit the semantic features of each modality, they cannot distinguish the effective low and high frequency information of each modality and fuse them adaptively. To address this issue, we propose AdaFuse, in which multimodal image information is fused adaptively through frequency-guided attention mechanism based on Fourier transform. Specifically, we propose the cross-attention fusion (CAF) block, which adaptively fuses features of two modalities in the spatial and frequency domains by exchanging key and query values, and then calculates the cross-attention scores between the spatial and frequency features to further guide the spatial-frequential information fusion. The CAF block enhances the high-frequency features of the different modalities so that the details in the fused images can be retained. Moreover, we design a novel loss function composed of structure loss and content loss to preserve both low and high frequency information. Extensive comparison experiments on several datasets demonstrate that the proposed method outperforms state-of-the-art methods in terms of both visual quality and quantitative metrics. The ablation experiments also validate the effectiveness of the proposed loss and fusion strategy.
Multi-Agent 3D Map Reconstruction and Change Detection in Microgravity with Free-Flying Robots
Nov 05, 2023Assistive free-flyer robots autonomously caring for future crewed outposts -- such as NASA's Astrobee robots on the International Space Station (ISS) -- must be able to detect day-to-day interior changes to track inventory, detect and diagnose faults, and monitor the outpost status. This work presents a framework for multi-agent cooperative mapping and change detection to enable robotic maintenance of space outposts. One agent is used to reconstruct a 3D model of the environment from sequences of images and corresponding depth information. Another agent is used to periodically scan the environment for inconsistencies against the 3D model. Change detection is validated after completing the surveys using real image and pose data collected by Astrobee robots in a ground testing environment and from microgravity aboard the ISS. This work outlines the objectives, requirements, and algorithmic modules for the multi-agent reconstruction system, including recommendations for its use by assistive free-flyers aboard future microgravity outposts.