 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Channel Estimation and Training Design for Active RIS Aided Wireless Communications
Nov 06, 2023
Active reconfigurable intelligent surface (ARIS) is a newly emerging RIS technique that leverages radio frequency (RF) reflection amplifiers to empower phase-configurable reflection elements (REs) in amplifying the incident signal. Thereby, ARIS can enhance wireless communications with the strengthened ARIS-aided links. In this letter, we propose exploiting the signal amplification capability of ARIS for channel estimation, aiming to improve the estimation precision. Nevertheless, the signal amplification inevitably introduces the thermal noise at the ARIS, which can hinder the acquisition of accurate channel state information (CSI) with conventional channel estimation methods based on passive RIS (PRIS). To address this issue, we further investigate this ARIS-specific channel estimation problem and propose a least-square (LS) based channel estimator, whose performance can be further improved with the design on ARIS reflection patterns at the channel training phase. Based on the proposed LS channel estimator, we optimize the training reflection patterns to minimize the channel estimation error variance. Extensive simulation results show that our proposed design can achieve accurate channel estimation in the presence of the ARIS noises.
* This paper has been accepted for publication in IEEE Wireless Communications Letters
MFAAN: Unveiling Audio Deepfakes with a Multi-Feature Authenticity Network
Nov 06, 2023In the contemporary digital age, the proliferation of deepfakes presents a formidable challenge to the sanctity of information dissemination. Audio deepfakes, in particular, can be deceptively realistic, posing significant risks in misinformation campaigns. To address this threat, we introduce the Multi-Feature Audio Authenticity Network (MFAAN), an advanced architecture tailored for the detection of fabricated audio content. MFAAN incorporates multiple parallel paths designed to harness the strengths of different audio representations, including Mel-frequency cepstral coefficients (MFCC), linear-frequency cepstral coefficients (LFCC), and Chroma Short Time Fourier Transform (Chroma-STFT). By synergistically fusing these features, MFAAN achieves a nuanced understanding of audio content, facilitating robust differentiation between genuine and manipulated recordings. Preliminary evaluations of MFAAN on two benchmark datasets, 'In-the-Wild' Audio Deepfake Data and The Fake-or-Real Dataset, demonstrate its superior performance, achieving accuracies of 98.93% and 94.47% respectively. Such results not only underscore the efficacy of MFAAN but also highlight its potential as a pivotal tool in the ongoing battle against deepfake audio content.
TSP-Transformer: Task-Specific Prompts Boosted Transformer for Holistic Scene Understanding
Nov 06, 2023Holistic scene understanding includes semantic segmentation, surface normal estimation, object boundary detection, depth estimation, etc. The key aspect of this problem is to learn representation effectively, as each subtask builds upon not only correlated but also distinct attributes. Inspired by visual-prompt tuning, we propose a Task-Specific Prompts Transformer, dubbed TSP-Transformer, for holistic scene understanding. It features a vanilla transformer in the early stage and tasks-specific prompts transformer encoder in the lateral stage, where tasks-specific prompts are augmented. By doing so, the transformer layer learns the generic information from the shared parts and is endowed with task-specific capacity. First, the tasks-specific prompts serve as induced priors for each task effectively. Moreover, the task-specific prompts can be seen as switches to favor task-specific representation learning for different tasks. Extensive experiments on NYUD-v2 and PASCAL-Context show that our method achieves state-of-the-art performance, validating the effectiveness of our method for holistic scene understanding. We also provide our code in the following link https://github.com/tb2-sy/TSP-Transformer.
Towards a Rigorous Analysis of Mutual Information in Contrastive Learning
Aug 30, 2023

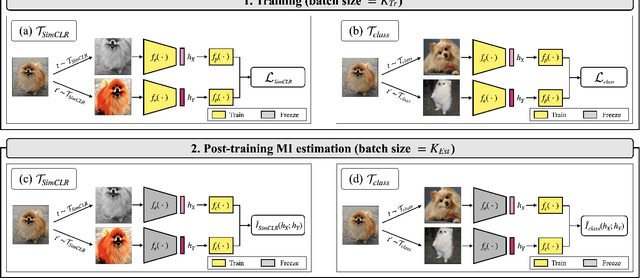
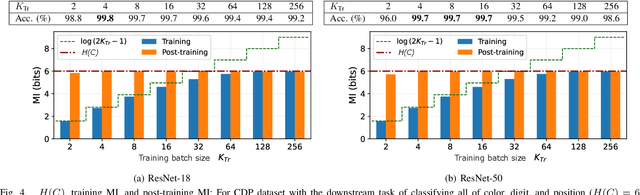
Contrastive learning has emerged as a cornerstone in recent achievements of unsupervised representation learning. Its primary paradigm involves an instance discrimination task with a mutual information loss. The loss is known as InfoNCE and it has yielded vital insights into contrastive learning through the lens of mutual information analysis. However, the estimation of mutual information can prove challenging, creating a gap between the elegance of its mathematical foundation and the complexity of its estimation. As a result, drawing rigorous insights or conclusions from mutual information analysis becomes intricate. In this study, we introduce three novel methods and a few related theorems, aimed at enhancing the rigor of mutual information analysis. Despite their simplicity, these methods can carry substantial utility. Leveraging these approaches, we reassess three instances of contrastive learning analysis, illustrating their capacity to facilitate deeper comprehension or to rectify pre-existing misconceptions. Specifically, we investigate small batch size, mutual information as a measure, and the InfoMin principle.
Rethinking Human Pose Estimation for Autonomous Driving with 3D Event Representations
Nov 09, 2023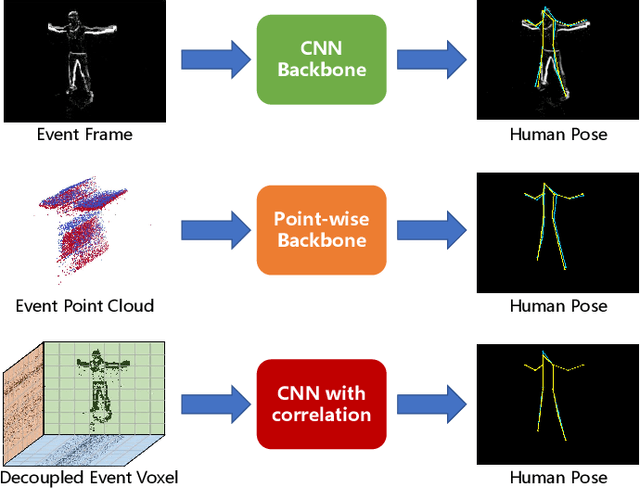
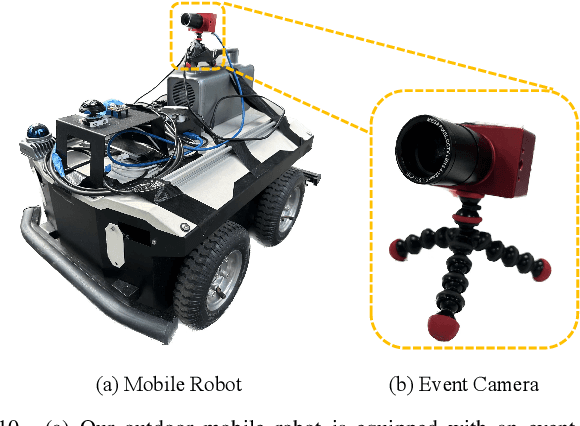
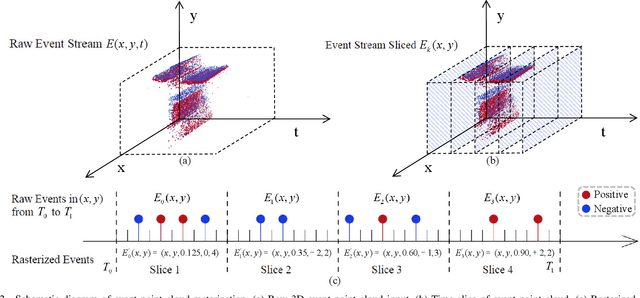
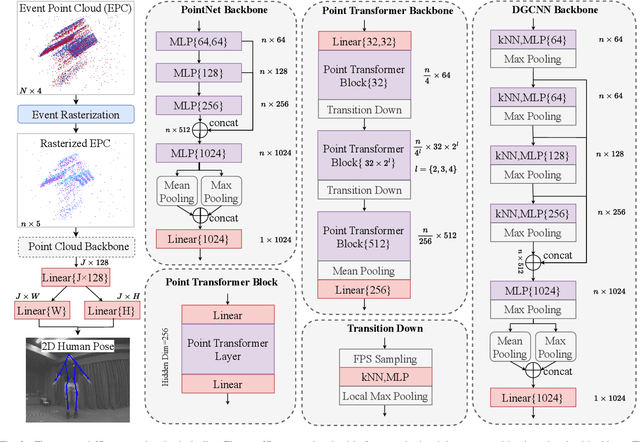
Human pose estimation is a critical component in autonomous driving and parking, enhancing safety by predicting human actions. Traditional frame-based cameras and videos are commonly applied, yet, they become less reliable in scenarios under high dynamic range or heavy motion blur. In contrast, event cameras offer a robust solution for navigating these challenging contexts. Predominant methodologies incorporate event cameras into learning frameworks by accumulating events into event frames. However, such methods tend to marginalize the intrinsic asynchronous and high temporal resolution characteristics of events. This disregard leads to a loss in essential temporal dimension data, crucial for safety-critical tasks associated with dynamic human activities. To address this issue and to unlock the 3D potential of event information, we introduce two 3D event representations: the Rasterized Event Point Cloud (RasEPC) and the Decoupled Event Voxel (DEV). The RasEPC collates events within concise temporal slices at identical positions, preserving 3D attributes with statistical cues and markedly mitigating memory and computational demands. Meanwhile, the DEV representation discretizes events into voxels and projects them across three orthogonal planes, utilizing decoupled event attention to retrieve 3D cues from the 2D planes. Furthermore, we develop and release EV-3DPW, a synthetic event-based dataset crafted to facilitate training and quantitative analysis in outdoor scenes. On the public real-world DHP19 dataset, our event point cloud technique excels in real-time mobile predictions, while the decoupled event voxel method achieves the highest accuracy. Experiments reveal our proposed 3D representation methods' superior generalization capacities against traditional RGB images and event frame techniques. Our code and dataset are available at https://github.com/MasterHow/EventPointPose.
Mirasol3B: A Multimodal Autoregressive model for time-aligned and contextual modalities
Nov 09, 2023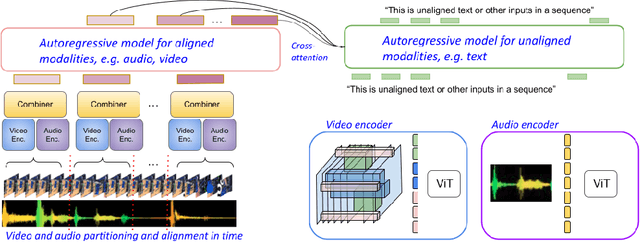
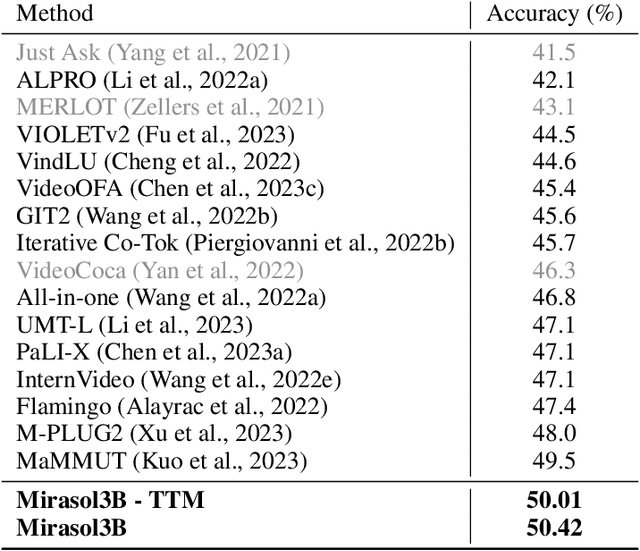
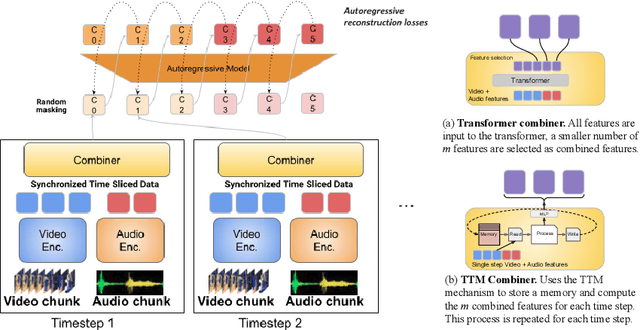

One of the main challenges of multimodal learning is the need to combine heterogeneous modalities (e.g., video, audio, text). For example, video and audio are obtained at much higher rates than text and are roughly aligned in time. They are often not synchronized with text, which comes as a global context, e.g., a title, or a description. Furthermore, video and audio inputs are of much larger volumes, and grow as the video length increases, which naturally requires more compute dedicated to these modalities and makes modeling of long-range dependencies harder. We here decouple the multimodal modeling, dividing it into separate, focused autoregressive models, processing the inputs according to the characteristics of the modalities. We propose a multimodal model, called Mirasol3B, consisting of an autoregressive component for the time-synchronized modalities (audio and video), and an autoregressive component for the context modalities which are not necessarily aligned in time but are still sequential. To address the long-sequences of the video-audio inputs, we propose to further partition the video and audio sequences in consecutive snippets and autoregressively process their representations. To that end, we propose a Combiner mechanism, which models the audio-video information jointly within a timeframe. The Combiner learns to extract audio and video features from raw spatio-temporal signals, and then learns to fuse these features producing compact but expressive representations per snippet. Our approach achieves the state-of-the-art on well established multimodal benchmarks, outperforming much larger models. It effectively addresses the high computational demand of media inputs by both learning compact representations, controlling the sequence length of the audio-video feature representations, and modeling their dependencies in time.
Accuracy of a Vision-Language Model on Challenging Medical Cases
Nov 09, 2023Background: General-purpose large language models that utilize both text and images have not been evaluated on a diverse array of challenging medical cases. Methods: Using 934 cases from the NEJM Image Challenge published between 2005 and 2023, we evaluated the accuracy of the recently released Generative Pre-trained Transformer 4 with Vision model (GPT-4V) compared to human respondents overall and stratified by question difficulty, image type, and skin tone. We further conducted a physician evaluation of GPT-4V on 69 NEJM clinicopathological conferences (CPCs). Analyses were conducted for models utilizing text alone, images alone, and both text and images. Results: GPT-4V achieved an overall accuracy of 61% (95% CI, 58 to 64%) compared to 49% (95% CI, 49 to 50%) for humans. GPT-4V outperformed humans at all levels of difficulty and disagreement, skin tones, and image types; the exception was radiographic images, where performance was equivalent between GPT-4V and human respondents. Longer, more informative captions were associated with improved performance for GPT-4V but similar performance for human respondents. GPT-4V included the correct diagnosis in its differential for 80% (95% CI, 68 to 88%) of CPCs when using text alone, compared to 58% (95% CI, 45 to 70%) of CPCs when using both images and text. Conclusions: GPT-4V outperformed human respondents on challenging medical cases and was able to synthesize information from both images and text, but performance deteriorated when images were added to highly informative text. Overall, our results suggest that multimodal AI models may be useful in medical diagnostic reasoning but that their accuracy may depend heavily on context.
L-WaveBlock: A Novel Feature Extractor Leveraging Wavelets for Generative Adversarial Networks
Nov 09, 2023Generative Adversarial Networks (GANs) have risen to prominence in the field of deep learning, facilitating the generation of realistic data from random noise. The effectiveness of GANs often depends on the quality of feature extraction, a critical aspect of their architecture. This paper introduces L-WaveBlock, a novel and robust feature extractor that leverages the capabilities of the Discrete Wavelet Transform (DWT) with deep learning methodologies. L-WaveBlock is catered to quicken the convergence of GAN generators while simultaneously enhancing their performance. The paper demonstrates the remarkable utility of L-WaveBlock across three datasets, a road satellite imagery dataset, the CelebA dataset and the GoPro dataset, showcasing its ability to ease feature extraction and make it more efficient. By utilizing DWT, L-WaveBlock efficiently captures the intricate details of both structural and textural details, and further partitions feature maps into orthogonal subbands across multiple scales while preserving essential information at the same time. Not only does it lead to faster convergence, but also gives competent results on every dataset by employing the L-WaveBlock. The proposed method achieves an Inception Score of 3.6959 and a Structural Similarity Index of 0.4261 on the maps dataset, a Peak Signal-to-Noise Ratio of 29.05 and a Structural Similarity Index of 0.874 on the CelebA dataset. The proposed method performs competently to the state-of-the-art for the image denoising dataset, albeit not better, but still leads to faster convergence than conventional methods. With this, L-WaveBlock emerges as a robust and efficient tool for enhancing GAN-based image generation, demonstrating superior convergence speed and competitive performance across multiple datasets for image resolution, image generation and image denoising.
Statistical Learning of Conjunction Data Messages Through a Bayesian Non-Homogeneous Poisson Process
Nov 09, 2023Current approaches for collision avoidance and space traffic management face many challenges, mainly due to the continuous increase in the number of objects in orbit and the lack of scalable and automated solutions. To avoid catastrophic incidents, satellite owners/operators must be aware of their assets' collision risk to decide whether a collision avoidance manoeuvre needs to be performed. This process is typically executed through the use of warnings issued in the form of CDMs which contain information about the event, such as the expected TCA and the probability of collision. Our previous work presented a statistical learning model that allowed us to answer two important questions: (1) Will any new conjunctions be issued in the next specified time interval? (2) When and with what uncertainty will the next CDM arrive? However, the model was based on an empirical Bayes homogeneous Poisson process, which assumes that the arrival rates of CDMs are constant over time. In fact, the rate at which the CDMs are issued depends on the behaviour of the objects as well as on the screening process performed by third parties. Thus, in this work, we extend the previous study and propose a Bayesian non-homogeneous Poisson process implemented with high precision using a Probabilistic Programming Language to fully describe the underlying phenomena. We compare the proposed solution with a baseline model to demonstrate the added value of our approach. The results show that this problem can be successfully modelled by our Bayesian non-homogeneous Poisson Process with greater accuracy, contributing to the development of automated collision avoidance systems and helping operators react timely but sparingly with satellite manoeuvres.
Color Equivariant Convolutional Networks
Oct 30, 2023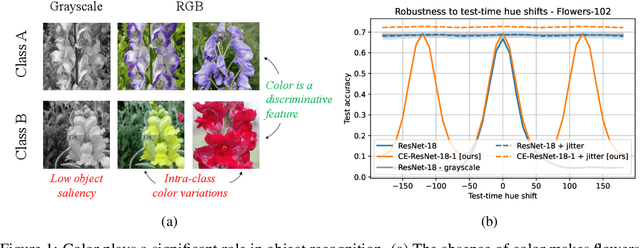
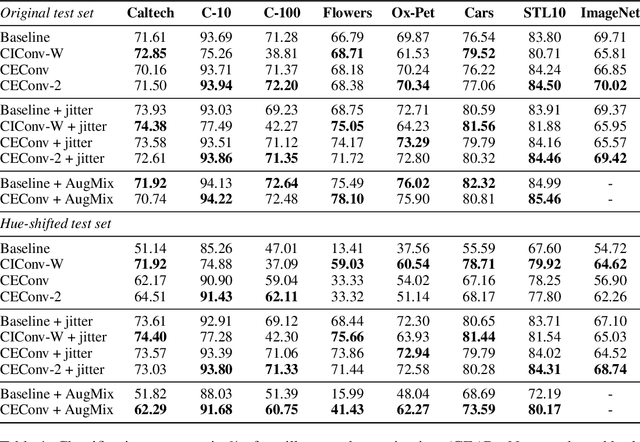
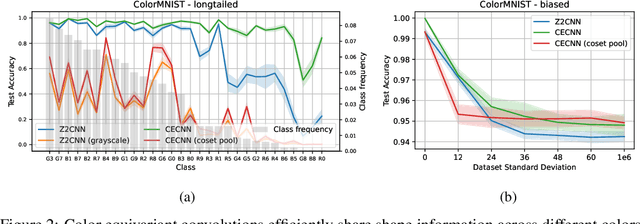
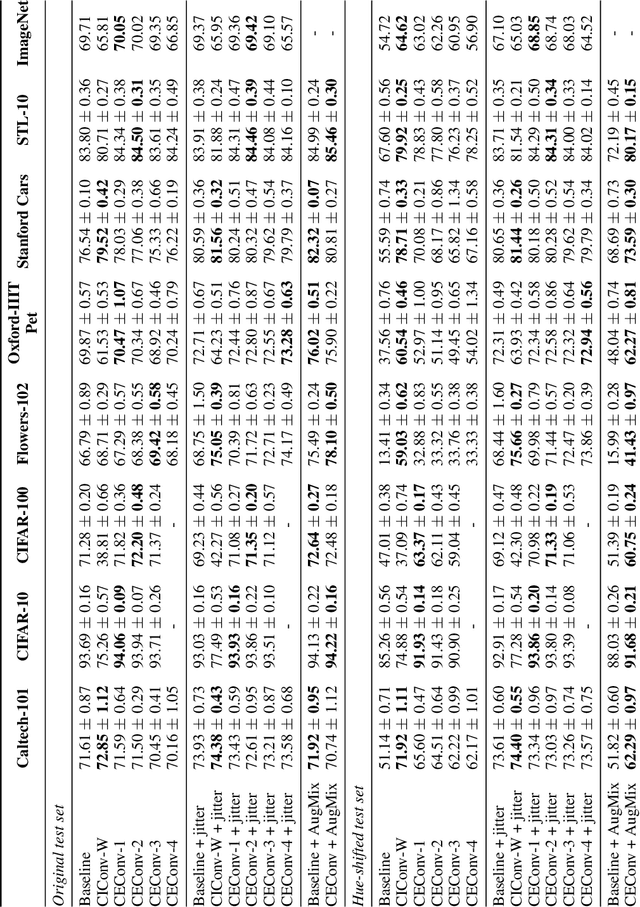
Color is a crucial visual cue readily exploited by Convolutional Neural Networks (CNNs) for object recognition. However, CNNs struggle if there is data imbalance between color variations introduced by accidental recording conditions. Color invariance addresses this issue but does so at the cost of removing all color information, which sacrifices discriminative power. In this paper, we propose Color Equivariant Convolutions (CEConvs), a novel deep learning building block that enables shape feature sharing across the color spectrum while retaining important color information. We extend the notion of equivariance from geometric to photometric transformations by incorporating parameter sharing over hue-shifts in a neural network. We demonstrate the benefits of CEConvs in terms of downstream performance to various tasks and improved robustness to color changes, including train-test distribution shifts. Our approach can be seamlessly integrated into existing architectures, such as ResNets, and offers a promising solution for addressing color-based domain shifts in CNNs.