 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LoRAShear: Efficient Large Language Model Structured Pruning and Knowledge Recovery
Oct 31, 2023
Large Language Models (LLMs) have transformed the landscape of artificial intelligence, while their enormous size presents significant challenges in terms of computational costs. We introduce LoRAShear, a novel efficient approach to structurally prune LLMs and recover knowledge. Given general LLMs, LoRAShear at first creates the dependency graphs over LoRA modules to discover minimally removal structures and analyze the knowledge distribution. It then proceeds progressive structured pruning on LoRA adaptors and enables inherent knowledge transfer to better preserve the information in the redundant structures. To recover the lost knowledge during pruning, LoRAShear meticulously studies and proposes a dynamic fine-tuning schemes with dynamic data adaptors to effectively narrow down the performance gap to the full models. Numerical results demonstrate that by only using one GPU within a couple of GPU days, LoRAShear effectively reduced footprint of LLMs by 20% with only 1.0% performance degradation and significantly outperforms state-of-the-arts. The source code will be available at https://github.com/microsoft/lorashear.
Linked Papers With Code: The Latest in Machine Learning as an RDF Knowledge Graph
Oct 31, 2023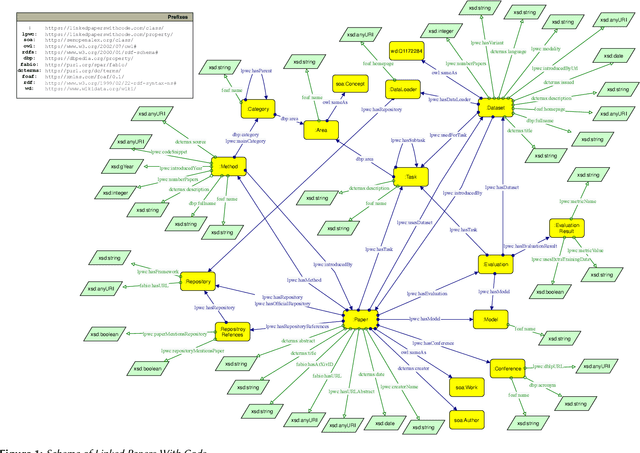

In this paper, we introduce Linked Papers With Code (LPWC), an RDF knowledge graph that provides comprehensive, current information about almost 400,000 machine learning publications. This includes the tasks addressed, the datasets utilized, the methods implemented, and the evaluations conducted, along with their results. Compared to its non-RDF-based counterpart Papers With Code, LPWC not only translates the latest advancements in machine learning into RDF format, but also enables novel ways for scientific impact quantification and scholarly key content recommendation. LPWC is openly accessible at https://linkedpaperswithcode.com and is licensed under CC-BY-SA 4.0. As a knowledge graph in the Linked Open Data cloud, we offer LPWC in multiple formats, from RDF dump files to a SPARQL endpoint for direct web queries, as well as a data source with resolvable URIs and links to the data sources SemOpenAlex, Wikidata, and DBLP. Additionally, we supply knowledge graph embeddings, enabling LPWC to be readily applied in machine learning applications.
GACE: Geometry Aware Confidence Enhancement for Black-Box 3D Object Detectors on LiDAR-Data
Oct 31, 2023Widely-used LiDAR-based 3D object detectors often neglect fundamental geometric information readily available from the object proposals in their confidence estimation. This is mostly due to architectural design choices, which were often adopted from the 2D image domain, where geometric context is rarely available. In 3D, however, considering the object properties and its surroundings in a holistic way is important to distinguish between true and false positive detections, e.g. occluded pedestrians in a group. To address this, we present GACE, an intuitive and highly efficient method to improve the confidence estimation of a given black-box 3D object detector. We aggregate geometric cues of detections and their spatial relationships, which enables us to properly assess their plausibility and consequently, improve the confidence estimation. This leads to consistent performance gains over a variety of state-of-the-art detectors. Across all evaluated detectors, GACE proves to be especially beneficial for the vulnerable road user classes, i.e. pedestrians and cyclists.
LFG: A Generative Network for Real-Time Recommendation
Oct 31, 2023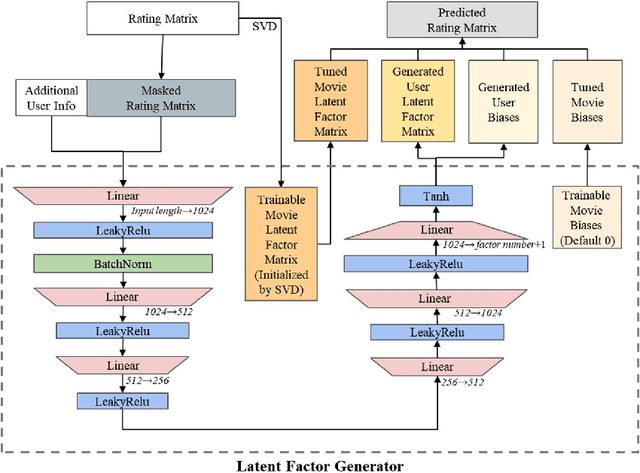
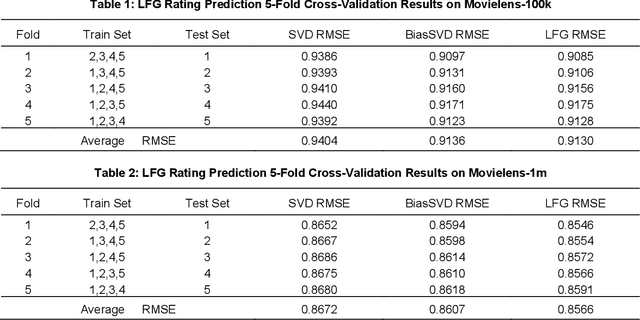
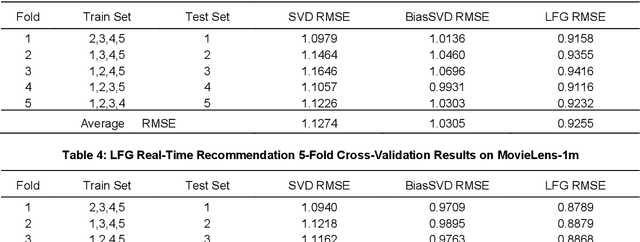

Recommender systems are essential information technologies today, and recommendation algorithms combined with deep learning have become a research hotspot in this field. The recommendation model known as LFM (Latent Factor Model), which captures latent features through matrix factorization and gradient descent to fit user preferences, has given rise to various recommendation algorithms that bring new improvements in recommendation accuracy. However, collaborative filtering recommendation models based on LFM lack flexibility and has shortcomings for real-time recommendations, as they need to redo the matrix factorization and retrain using gradient descent when new users arrive. In response to this, this paper innovatively proposes a Latent Factor Generator (LFG) network, and set the movie recommendation as research theme. The LFG dynamically generates user latent factors through deep neural networks without the need for re-factorization or retrain. Experimental results indicate that the LFG recommendation model outperforms traditional matrix factorization algorithms in recommendation accuracy, providing an effective solution to the challenges of real-time recommendations with LFM.
FedRec+: Enhancing Privacy and Addressing Heterogeneity in Federated Recommendation Systems
Oct 31, 2023Preserving privacy and reducing communication costs for edge users pose significant challenges in recommendation systems. Although federated learning has proven effective in protecting privacy by avoiding data exchange between clients and servers, it has been shown that the server can infer user ratings based on updated non-zero gradients obtained from two consecutive rounds of user-uploaded gradients. Moreover, federated recommendation systems (FRS) face the challenge of heterogeneity, leading to decreased recommendation performance. In this paper, we propose FedRec+, an ensemble framework for FRS that enhances privacy while addressing the heterogeneity challenge. FedRec+ employs optimal subset selection based on feature similarity to generate near-optimal virtual ratings for pseudo items, utilizing only the user's local information. This approach reduces noise without incurring additional communication costs. Furthermore, we utilize the Wasserstein distance to estimate the heterogeneity and contribution of each client, and derive optimal aggregation weights by solving a defined optimization problem. Experimental results demonstrate the state-of-the-art performance of FedRec+ across various reference datasets.
Importance Estimation with Random Gradient for Neural Network Pruning
Oct 31, 2023Global Neuron Importance Estimation is used to prune neural networks for efficiency reasons. To determine the global importance of each neuron or convolutional kernel, most of the existing methods either use activation or gradient information or both, which demands abundant labelled examples. In this work, we use heuristics to derive importance estimation similar to Taylor First Order (TaylorFO) approximation based methods. We name our methods TaylorFO-abs and TaylorFO-sq. We propose two additional methods to improve these importance estimation methods. Firstly, we propagate random gradients from the last layer of a network, thus avoiding the need for labelled examples. Secondly, we normalize the gradient magnitude of the last layer output before propagating, which allows all examples to contribute similarly to the importance score. Our methods with additional techniques perform better than previous methods when tested on ResNet and VGG architectures on CIFAR-100 and STL-10 datasets. Furthermore, our method also complements the existing methods and improves their performances when combined with them.
Using Higher-Order Moments to Assess the Quality of GAN-generated Image Features
Oct 31, 2023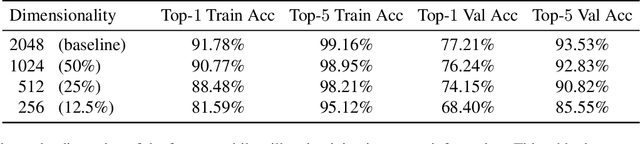
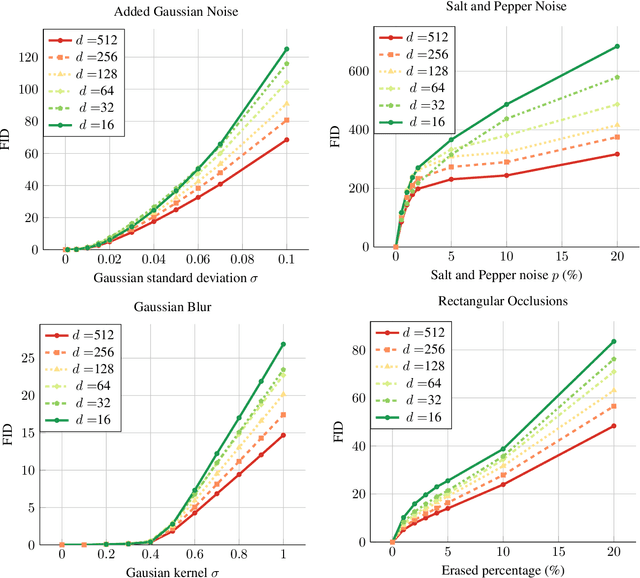
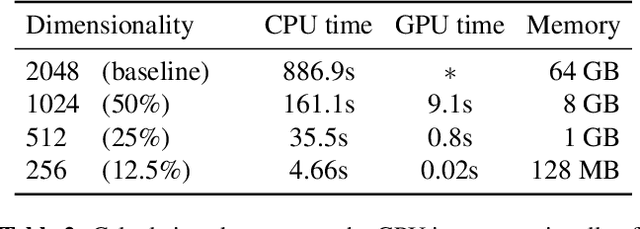
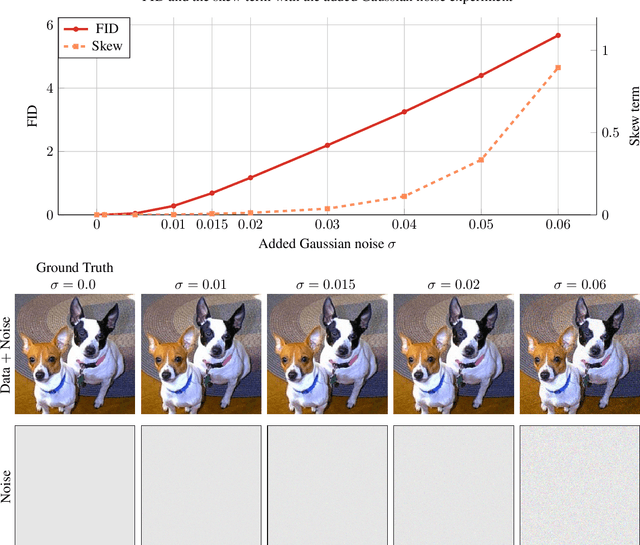
The rapid advancement of Generative Adversarial Networks (GANs) necessitates the need to robustly evaluate these models. Among the established evaluation criteria, the Fr\'{e}chet Inception Distance (FID) has been widely adopted due to its conceptual simplicity, fast computation time, and strong correlation with human perception. However, FID has inherent limitations, mainly stemming from its assumption that feature embeddings follow a Gaussian distribution, and therefore can be defined by their first two moments. As this does not hold in practice, in this paper we explore the importance of third-moments in image feature data and use this information to define a new measure, which we call the Skew Inception Distance (SID). We prove that SID is a pseudometric on probability distributions, show how it extends FID, and present a practical method for its computation. Our numerical experiments support that SID either tracks with FID or, in some cases, aligns more closely with human perception when evaluating image features of ImageNet data.
ACL Anthology Helper: A Tool to Retrieve and Manage Literature from ACL Anthology
Oct 31, 2023
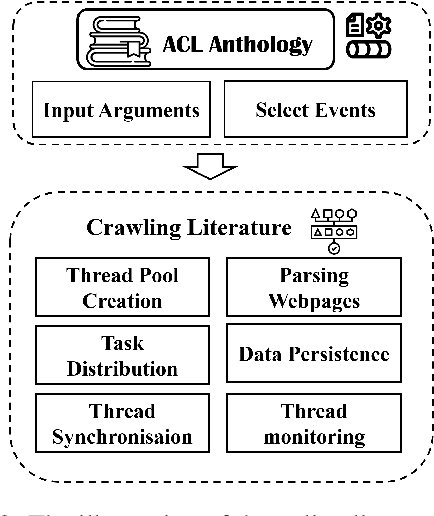
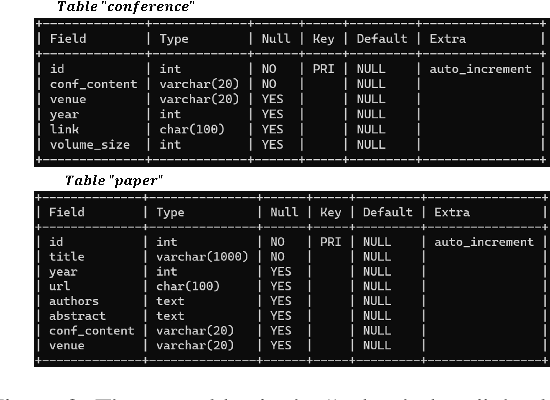
The ACL Anthology is an online repository that serves as a comprehensive collection of publications in the field of natural language processing (NLP) and computational linguistics (CL). This paper presents a tool called ``ACL Anthology Helper''. It automates the process of parsing and downloading papers along with their meta-information, which are then stored in a local MySQL database. This allows for efficient management of the local papers using a wide range of operations, including "where," "group," "order," and more. By providing over 20 operations, this tool significantly enhances the retrieval of literature based on specific conditions. Notably, this tool has been successfully utilised in writing a survey paper (Tang et al.,2022a). By introducing the ACL Anthology Helper, we aim to enhance researchers' ability to effectively access and organise literature from the ACL Anthology. This tool offers a convenient solution for researchers seeking to explore the ACL Anthology's vast collection of publications while allowing for more targeted and efficient literature retrieval.
Explainable Spatio-Temporal Graph Neural Networks
Oct 26, 2023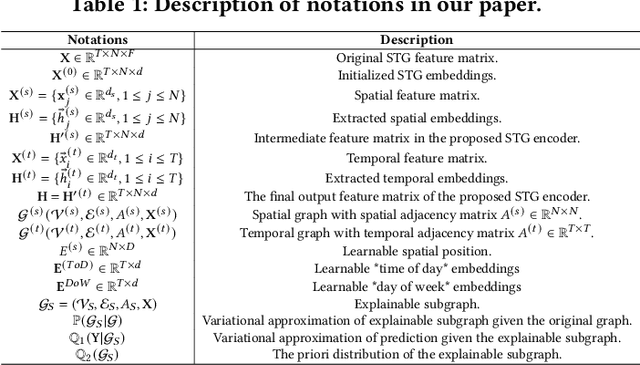
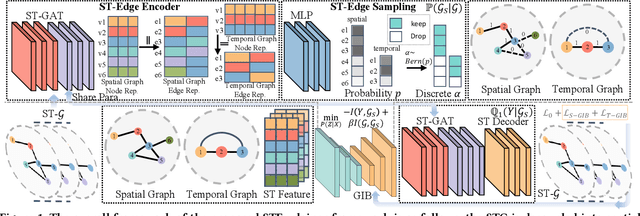
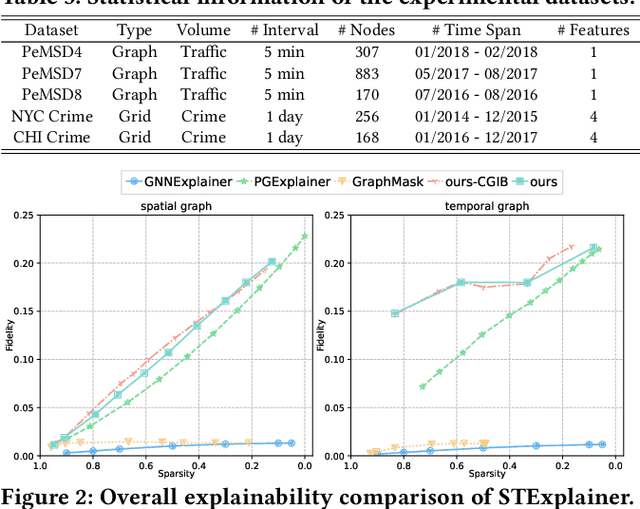
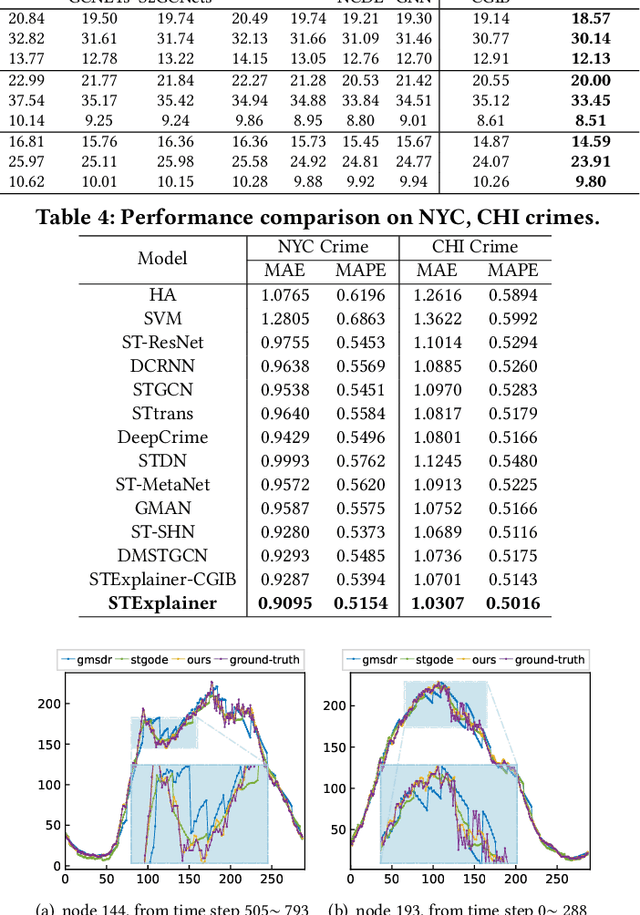
Spatio-temporal graph neural networks (STGNNs) have gained popularity as a powerful tool for effectively modeling spatio-temporal dependencies in diverse real-world urban applications, including intelligent transportation and public safety. However, the black-box nature of STGNNs limits their interpretability, hindering their application in scenarios related to urban resource allocation and policy formulation. To bridge this gap, we propose an Explainable Spatio-Temporal Graph Neural Networks (STExplainer) framework that enhances STGNNs with inherent explainability, enabling them to provide accurate predictions and faithful explanations simultaneously. Our framework integrates a unified spatio-temporal graph attention network with a positional information fusion layer as the STG encoder and decoder, respectively. Furthermore, we propose a structure distillation approach based on the Graph Information Bottleneck (GIB) principle with an explainable objective, which is instantiated by the STG encoder and decoder. Through extensive experiments, we demonstrate that our STExplainer outperforms state-of-the-art baselines in terms of predictive accuracy and explainability metrics (i.e., sparsity and fidelity) on traffic and crime prediction tasks. Furthermore, our model exhibits superior representation ability in alleviating data missing and sparsity issues. The implementation code is available at: https://github.com/HKUDS/STExplainer.
Neural-Base Music Generation for Intelligence Duplication
Oct 20, 2023There are two aspects of machine learning and artificial intelligence: (1) interpreting information, and (2) inventing new useful information. Much advance has been made for (1) with a focus on pattern recognition techniques (e.g., interpreting visual data). This paper focuses on (2) with intelligent duplication (ID) for invention. We explore the possibility of learning a specific individual's creative reasoning in order to leverage the learned expertise and talent to invent new information. More specifically, we employ a deep learning system to learn from the great composer Beethoven and capture his composition ability in a hash-based knowledge base. This new form of knowledge base provides a reasoning facility to drive the music composition through a novel music generation method.