 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Efficient Semantic Matching with Hypercolumn Correlation
Nov 07, 2023
Recent studies show that leveraging the match-wise relationships within the 4D correlation map yields significant improvements in establishing semantic correspondences - but at the cost of increased computation and latency. In this work, we focus on the aspect that the performance improvements of recent methods can also largely be attributed to the usage of multi-scale correlation maps, which hold various information ranging from low-level geometric cues to high-level semantic contexts. To this end, we propose HCCNet, an efficient yet effective semantic matching method which exploits the full potential of multi-scale correlation maps, while eschewing the reliance on expensive match-wise relationship mining on the 4D correlation map. Specifically, HCCNet performs feature slicing on the bottleneck features to yield a richer set of intermediate features, which are used to construct a hypercolumn correlation. HCCNet can consequently establish semantic correspondences in an effective manner by reducing the volume of conventional high-dimensional convolution or self-attention operations to efficient point-wise convolutions. HCCNet demonstrates state-of-the-art or competitive performances on the standard benchmarks of semantic matching, while incurring a notably lower latency and computation overhead compared to the existing SoTA methods.
HyperS2V: A Framework for Structural Representation of Nodes in Hyper Networks
Nov 07, 2023In contrast to regular (simple) networks, hyper networks possess the ability to depict more complex relationships among nodes and store extensive information. Such networks are commonly found in real-world applications, such as in social interactions. Learning embedded representations for nodes involves a process that translates network structures into more simplified spaces, thereby enabling the application of machine learning approaches designed for vector data to be extended to network data. Nevertheless, there remains a need to delve into methods for learning embedded representations that prioritize structural aspects. This research introduces HyperS2V, a node embedding approach that centers on the structural similarity within hyper networks. Initially, we establish the concept of hyper-degrees to capture the structural properties of nodes within hyper networks. Subsequently, a novel function is formulated to measure the structural similarity between different hyper-degree values. Lastly, we generate structural embeddings utilizing a multi-scale random walk framework. Moreover, a series of experiments, both intrinsic and extrinsic, are performed on both toy and real networks. The results underscore the superior performance of HyperS2V in terms of both interpretability and applicability to downstream tasks.
Causal Discovery Under Local Privacy
Nov 07, 2023Differential privacy is a widely adopted framework designed to safeguard the sensitive information of data providers within a data set. It is based on the application of controlled noise at the interface between the server that stores and processes the data, and the data consumers. Local differential privacy is a variant that allows data providers to apply the privatization mechanism themselves on their data individually. Therefore it provides protection also in contexts in which the server, or even the data collector, cannot be trusted. The introduction of noise, however, inevitably affects the utility of the data, particularly by distorting the correlations between individual data components. This distortion can prove detrimental to tasks such as causal discovery. In this paper, we consider various well-known locally differentially private mechanisms and compare the trade-off between the privacy they provide, and the accuracy of the causal structure produced by algorithms for causal learning when applied to data obfuscated by these mechanisms. Our analysis yields valuable insights for selecting appropriate local differentially private protocols for causal discovery tasks. We foresee that our findings will aid researchers and practitioners in conducting locally private causal discovery.
Joint model for longitudinal and spatio-temporal survival data
Nov 07, 2023In credit risk analysis, survival models with fixed and time-varying covariates are widely used to predict a borrower's time-to-event. When the time-varying drivers are endogenous, modelling jointly the evolution of the survival time and the endogenous covariates is the most appropriate approach, also known as the joint model for longitudinal and survival data. In addition to the temporal component, credit risk models can be enhanced when including borrowers' geographical information by considering spatial clustering and its variation over time. We propose the Spatio-Temporal Joint Model (STJM) to capture spatial and temporal effects and their interaction. This Bayesian hierarchical joint model reckons the survival effect of unobserved heterogeneity among borrowers located in the same region at a particular time. To estimate the STJM model for large datasets, we consider the Integrated Nested Laplace Approximation (INLA) methodology. We apply the STJM to predict the time to full prepayment on a large dataset of 57,258 US mortgage borrowers with more than 2.5 million observations. Empirical results indicate that including spatial effects consistently improves the performance of the joint model. However, the gains are less definitive when we additionally include spatio-temporal interactions.
Generative learning for nonlinear dynamics
Nov 07, 2023Modern generative machine learning models demonstrate surprising ability to create realistic outputs far beyond their training data, such as photorealistic artwork, accurate protein structures, or conversational text. These successes suggest that generative models learn to effectively parametrize and sample arbitrarily complex distributions. Beginning half a century ago, foundational works in nonlinear dynamics used tools from information theory to infer properties of chaotic attractors from time series, motivating the development of algorithms for parametrizing chaos in real datasets. In this perspective, we aim to connect these classical works to emerging themes in large-scale generative statistical learning. We first consider classical attractor reconstruction, which mirrors constraints on latent representations learned by state space models of time series. We next revisit early efforts to use symbolic approximations to compare minimal discrete generators underlying complex processes, a problem relevant to modern efforts to distill and interpret black-box statistical models. Emerging interdisciplinary works bridge nonlinear dynamics and learning theory, such as operator-theoretic methods for complex fluid flows, or detection of broken detailed balance in biological datasets. We anticipate that future machine learning techniques may revisit other classical concepts from nonlinear dynamics, such as transinformation decay and complexity-entropy tradeoffs.
Benchmarking a Benchmark: How Reliable is MS-COCO?
Nov 05, 2023Benchmark datasets are used to profile and compare algorithms across a variety of tasks, ranging from image classification to segmentation, and also play a large role in image pretraining algorithms. Emphasis is placed on results with little regard to the actual content within the dataset. It is important to question what kind of information is being learned from these datasets and what are the nuances and biases within them. In the following work, Sama-COCO, a re-annotation of MS-COCO, is used to discover potential biases by leveraging a shape analysis pipeline. A model is trained and evaluated on both datasets to examine the impact of different annotation conditions. Results demonstrate that annotation styles are important and that annotation pipelines should closely consider the task of interest. The dataset is made publicly available at https://www.sama.com/sama-coco-dataset/ .
Generative Face Video Coding Techniques and Standardization Efforts: A Review
Nov 05, 2023Generative Face Video Coding (GFVC) techniques can exploit the compact representation of facial priors and the strong inference capability of deep generative models, achieving high-quality face video communication in ultra-low bandwidth scenarios. This paper conducts a comprehensive survey on the recent advances of the GFVC techniques and standardization efforts, which could be applicable to ultra low bitrate communication, user-specified animation/filtering and metaverse-related functionalities. In particular, we generalize GFVC systems within one coding framework and summarize different GFVC algorithms with their corresponding visual representations. Moreover, we review the GFVC standardization activities that are specified with supplemental enhancement information messages. Finally, we discuss fundamental challenges and broad applications on GFVC techniques and their standardization potentials, as well as envision their future trends. The project page can be found at https://github.com/Berlin0610/Awesome-Generative-Face-Video-Coding.
Towards Control-Centric Representations in Reinforcement Learning from Images
Oct 27, 2023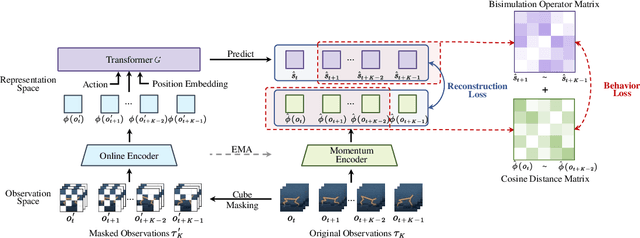
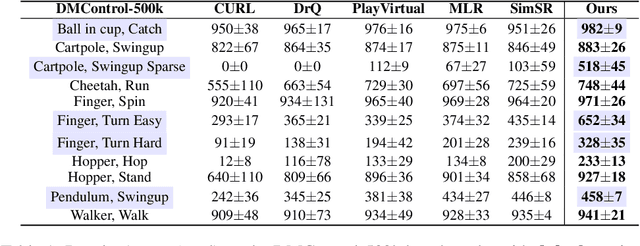

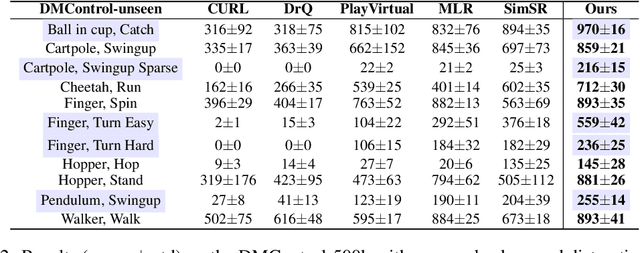
Image-based Reinforcement Learning is a practical yet challenging task. A major hurdle lies in extracting control-centric representations while disregarding irrelevant information. While approaches that follow the bisimulation principle exhibit the potential in learning state representations to address this issue, they still grapple with the limited expressive capacity of latent dynamics and the inadaptability to sparse reward environments. To address these limitations, we introduce ReBis, which aims to capture control-centric information by integrating reward-free control information alongside reward-specific knowledge. ReBis utilizes a transformer architecture to implicitly model the dynamics and incorporates block-wise masking to eliminate spatiotemporal redundancy. Moreover, ReBis combines bisimulation-based loss with asymmetric reconstruction loss to prevent feature collapse in environments with sparse rewards. Empirical studies on two large benchmarks, including Atari games and DeepMind Control Suit, demonstrate that ReBis has superior performance compared to existing methods, proving its effectiveness.
Enhancing Few-shot CLIP with Semantic-Aware Fine-Tuning
Nov 09, 2023Learning generalized representations from limited training samples is crucial for applying deep neural networks in low-resource scenarios. Recently, methods based on Contrastive Language-Image Pre-training (CLIP) have exhibited promising performance in few-shot adaptation tasks. To avoid catastrophic forgetting and overfitting caused by few-shot fine-tuning, existing works usually freeze the parameters of CLIP pre-trained on large-scale datasets, overlooking the possibility that some parameters might not be suitable for downstream tasks. To this end, we revisit CLIP's visual encoder with a specific focus on its distinctive attention pooling layer, which performs a spatial weighted-sum of the dense feature maps. Given that dense feature maps contain meaningful semantic information, and different semantics hold varying importance for diverse downstream tasks (such as prioritizing semantics like ears and eyes in pet classification tasks rather than side mirrors), using the same weighted-sum operation for dense features across different few-shot tasks might not be appropriate. Hence, we propose fine-tuning the parameters of the attention pooling layer during the training process to encourage the model to focus on task-specific semantics. In the inference process, we perform residual blending between the features pooled by the fine-tuned and the original attention pooling layers to incorporate both the few-shot knowledge and the pre-trained CLIP's prior knowledge. We term this method as Semantic-Aware FinE-tuning (SAFE). SAFE is effective in enhancing the conventional few-shot CLIP and is compatible with the existing adapter approach (termed SAFE-A).
The Paradox of Noise: An Empirical Study of Noise-Infusion Mechanisms to Improve Generalization, Stability, and Privacy in Federated Learning
Nov 09, 2023In a data-centric era, concerns regarding privacy and ethical data handling grow as machine learning relies more on personal information. This empirical study investigates the privacy, generalization, and stability of deep learning models in the presence of additive noise in federated learning frameworks. Our main objective is to provide strategies to measure the generalization, stability, and privacy-preserving capabilities of these models and further improve them. To this end, five noise infusion mechanisms at varying noise levels within centralized and federated learning settings are explored. As model complexity is a key component of the generalization and stability of deep learning models during training and evaluation, a comparative analysis of three Convolutional Neural Network (CNN) architectures is provided. The paper introduces Signal-to-Noise Ratio (SNR) as a quantitative measure of the trade-off between privacy and training accuracy of noise-infused models, aiming to find the noise level that yields optimal privacy and accuracy. Moreover, the Price of Stability and Price of Anarchy are defined in the context of privacy-preserving deep learning, contributing to the systematic investigation of the noise infusion strategies to enhance privacy without compromising performance. Our research sheds light on the delicate balance between these critical factors, fostering a deeper understanding of the implications of noise-based regularization in machine learning. By leveraging noise as a tool for regularization and privacy enhancement, we aim to contribute to the development of robust, privacy-aware algorithms, ensuring that AI-driven solutions prioritize both utility and privacy.