 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Contrastive Multi-Modal Representation Learning for Spark Plug Fault Diagnosis
Nov 04, 2023
Due to the incapability of one sensory measurement to provide enough information for condition monitoring of some complex engineered industrial mechanisms and also for overcoming the misleading noise of a single sensor, multiple sensors are installed to improve the condition monitoring of some industrial equipment. Therefore, an efficient data fusion strategy is demanded. In this research, we presented a Denoising Multi-Modal Autoencoder with a unique training strategy based on contrastive learning paradigm, both being utilized for the first time in the machine health monitoring realm. The presented approach, which leverages the merits of both supervised and unsupervised learning, not only achieves excellent performance in fusing multiple modalities (or views) of data into an enriched common representation but also takes data fusion to the next level wherein one of the views can be omitted during inference time with very slight performance reduction, or even without any reduction at all. The presented methodology enables multi-modal fault diagnosis systems to perform more robustly in case of sensor failure occurrence, and one can also intentionally omit one of the sensors (the more expensive one) in order to build a more cost-effective condition monitoring system without sacrificing performance for practical purposes. The effectiveness of the presented methodology is examined on a real-world private multi-modal dataset gathered under non-laboratory conditions from a complex engineered mechanism, an inline four-stroke spark-ignition engine, aiming for spark plug fault diagnosis. This dataset, which contains the accelerometer and acoustic signals as two modalities, has a very slight amount of fault, and achieving good performance on such a dataset promises that the presented method can perform well on other equipment as well.
Continual atlas-based segmentation of prostate MRI
Nov 02, 2023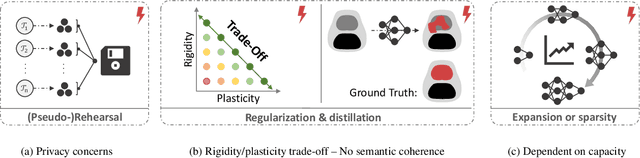
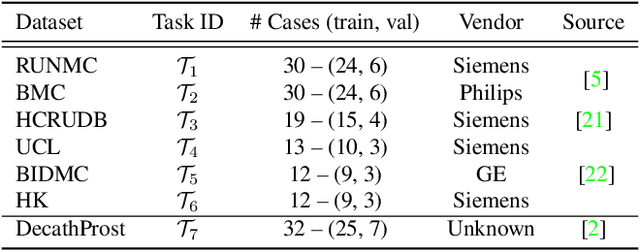
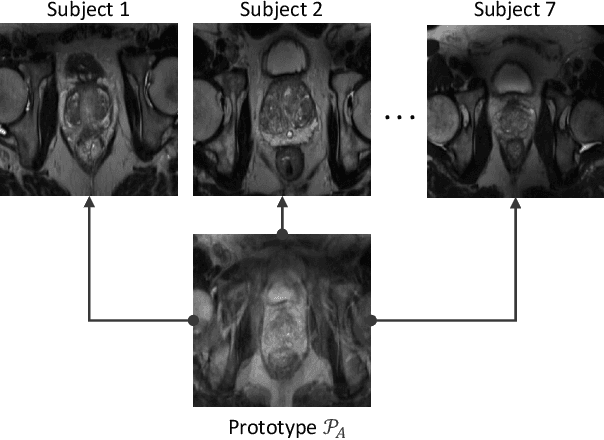
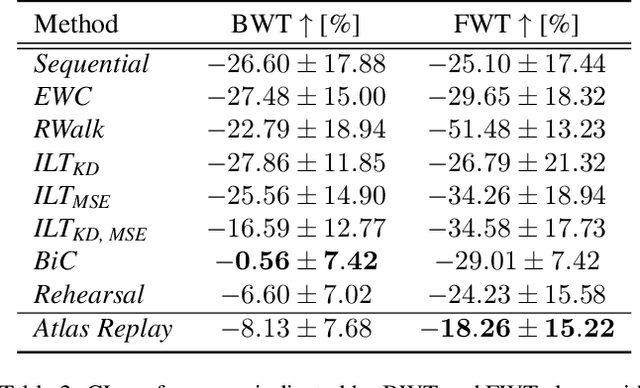
Continual learning (CL) methods designed for natural image classification often fail to reach basic quality standards for medical image segmentation. Atlas-based segmentation, a well-established approach in medical imaging, incorporates domain knowledge on the region of interest, leading to semantically coherent predictions. This is especially promising for CL, as it allows us to leverage structural information and strike an optimal balance between model rigidity and plasticity over time. When combined with privacy-preserving prototypes, this process offers the advantages of rehearsal-based CL without compromising patient privacy. We propose Atlas Replay, an atlas-based segmentation approach that uses prototypes to generate high-quality segmentation masks through image registration that maintain consistency even as the training distribution changes. We explore how our proposed method performs compared to state-of-the-art CL methods in terms of knowledge transferability across seven publicly available prostate segmentation datasets. Prostate segmentation plays a vital role in diagnosing prostate cancer, however, it poses challenges due to substantial anatomical variations, benign structural differences in older age groups, and fluctuating acquisition parameters. Our results show that Atlas Replay is both robust and generalizes well to yet-unseen domains while being able to maintain knowledge, unlike end-to-end segmentation methods. Our code base is available under https://github.com/MECLabTUDA/Atlas-Replay.
CapsFusion: Rethinking Image-Text Data at Scale
Nov 02, 2023Large multimodal models demonstrate remarkable generalist ability to perform diverse multimodal tasks in a zero-shot manner. Large-scale web-based image-text pairs contribute fundamentally to this success, but suffer from excessive noise. Recent studies use alternative captions synthesized by captioning models and have achieved notable benchmark performance. However, our experiments reveal significant Scalability Deficiency and World Knowledge Loss issues in models trained with synthetic captions, which have been largely obscured by their initial benchmark success. Upon closer examination, we identify the root cause as the overly-simplified language structure and lack of knowledge details in existing synthetic captions. To provide higher-quality and more scalable multimodal pretraining data, we propose CapsFusion, an advanced framework that leverages large language models to consolidate and refine information from both web-based image-text pairs and synthetic captions. Extensive experiments show that CapsFusion captions exhibit remarkable all-round superiority over existing captions in terms of model performance (e.g., 18.8 and 18.3 improvements in CIDEr score on COCO and NoCaps), sample efficiency (requiring 11-16 times less computation than baselines), world knowledge depth, and scalability. These effectiveness, efficiency and scalability advantages position CapsFusion as a promising candidate for future scaling of LMM training.
Vision-Language Foundation Models as Effective Robot Imitators
Nov 02, 2023Recent progress in vision language foundation models has shown their ability to understand multimodal data and resolve complicated vision language tasks, including robotics manipulation. We seek a straightforward way of making use of existing vision-language models (VLMs) with simple fine-tuning on robotics data. To this end, we derive a simple and novel vision-language manipulation framework, dubbed RoboFlamingo, built upon the open-source VLMs, OpenFlamingo. Unlike prior works, RoboFlamingo utilizes pre-trained VLMs for single-step vision-language comprehension, models sequential history information with an explicit policy head, and is slightly fine-tuned by imitation learning only on language-conditioned manipulation datasets. Such a decomposition provides RoboFlamingo the flexibility for open-loop control and deployment on low-performance platforms. By exceeding the state-of-the-art performance with a large margin on the tested benchmark, we show RoboFlamingo can be an effective and competitive alternative to adapt VLMs to robot control. Our extensive experimental results also reveal several interesting conclusions regarding the behavior of different pre-trained VLMs on manipulation tasks. We believe RoboFlamingo has the potential to be a cost-effective and easy-to-use solution for robotics manipulation, empowering everyone with the ability to fine-tune their own robotics policy.
Novel View Synthesis from a Single RGBD Image for Indoor Scenes
Nov 02, 2023In this paper, we propose an approach for synthesizing novel view images from a single RGBD (Red Green Blue-Depth) input. Novel view synthesis (NVS) is an interesting computer vision task with extensive applications. Methods using multiple images has been well-studied, exemplary ones include training scene-specific Neural Radiance Fields (NeRF), or leveraging multi-view stereo (MVS) and 3D rendering pipelines. However, both are either computationally intensive or non-generalizable across different scenes, limiting their practical value. Conversely, the depth information embedded in RGBD images unlocks 3D potential from a singular view, simplifying NVS. The widespread availability of compact, affordable stereo cameras, and even LiDARs in contemporary devices like smartphones, makes capturing RGBD images more accessible than ever. In our method, we convert an RGBD image into a point cloud and render it from a different viewpoint, then formulate the NVS task into an image translation problem. We leveraged generative adversarial networks to style-transfer the rendered image, achieving a result similar to a photograph taken from the new perspective. We explore both unsupervised learning using CycleGAN and supervised learning with Pix2Pix, and demonstrate the qualitative results. Our method circumvents the limitations of traditional multi-image techniques, holding significant promise for practical, real-time applications in NVS.
Can Language Models Be Tricked by Language Illusions? Easier with Syntax, Harder with Semantics
Nov 02, 2023Language models (LMs) have been argued to overlap substantially with human beings in grammaticality judgment tasks. But when humans systematically make errors in language processing, should we expect LMs to behave like cognitive models of language and mimic human behavior? We answer this question by investigating LMs' more subtle judgments associated with "language illusions" -- sentences that are vague in meaning, implausible, or ungrammatical but receive unexpectedly high acceptability judgments by humans. We looked at three illusions: the comparative illusion (e.g. "More people have been to Russia than I have"), the depth-charge illusion (e.g. "No head injury is too trivial to be ignored"), and the negative polarity item (NPI) illusion (e.g. "The hunter who no villager believed to be trustworthy will ever shoot a bear"). We found that probabilities represented by LMs were more likely to align with human judgments of being "tricked" by the NPI illusion which examines a structural dependency, compared to the comparative and the depth-charge illusions which require sophisticated semantic understanding. No single LM or metric yielded results that are entirely consistent with human behavior. Ultimately, we show that LMs are limited both in their construal as cognitive models of human language processing and in their capacity to recognize nuanced but critical information in complicated language materials.
Bi-Preference Learning Heterogeneous Hypergraph Networks for Session-based Recommendation
Nov 02, 2023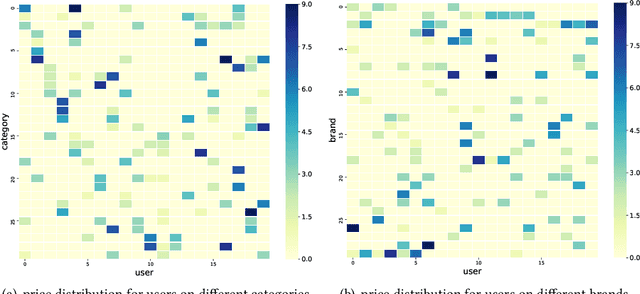
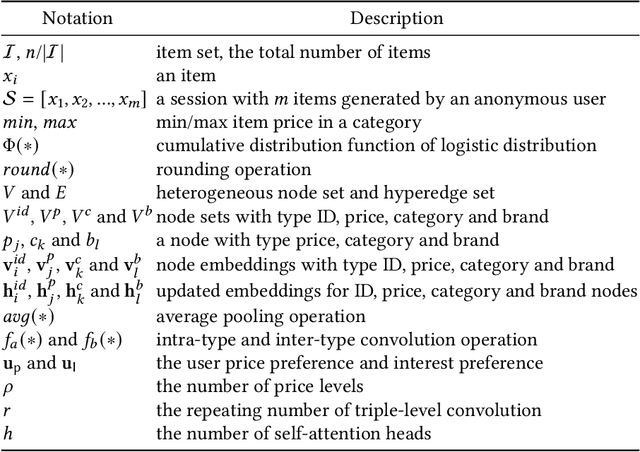
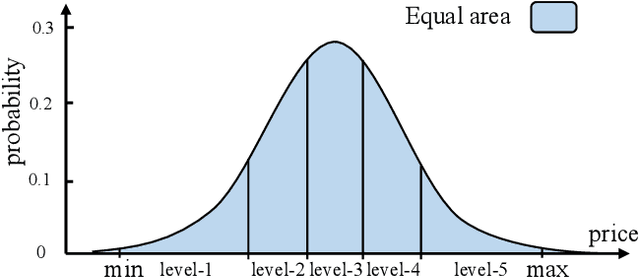
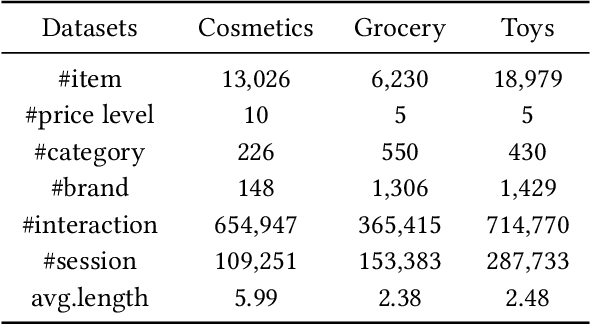
Session-based recommendation intends to predict next purchased items based on anonymous behavior sequences. Numerous economic studies have revealed that item price is a key factor influencing user purchase decisions. Unfortunately, existing methods for session-based recommendation only aim at capturing user interest preference, while ignoring user price preference. Actually, there are primarily two challenges preventing us from accessing price preference. Firstly, the price preference is highly associated to various item features (i.e., category and brand), which asks us to mine price preference from heterogeneous information. Secondly, price preference and interest preference are interdependent and collectively determine user choice, necessitating that we jointly consider both price and interest preference for intent modeling. To handle above challenges, we propose a novel approach Bi-Preference Learning Heterogeneous Hypergraph Networks (BiPNet) for session-based recommendation. Specifically, the customized heterogeneous hypergraph networks with a triple-level convolution are devised to capture user price and interest preference from heterogeneous features of items. Besides, we develop a Bi-Preference Learning schema to explore mutual relations between price and interest preference and collectively learn these two preferences under the multi-task learning architecture. Extensive experiments on multiple public datasets confirm the superiority of BiPNet over competitive baselines. Additional research also supports the notion that the price is crucial for the task.
A Review of Digital Twins and their Application in Cybersecurity based on Artificial Intelligence
Nov 02, 2023The potential of digital twin technology is yet to be fully realized due to its diversity and untapped potential. Digital twins enable systems' analysis, design, optimization, and evolution to be performed digitally or in conjunction with a cyber-physical approach to improve speed, accuracy, and efficiency over traditional engineering methods. Industry 4.0, factories of the future, and digital twins continue to benefit from the technology and provide enhanced efficiency within existing systems. Due to the lack of information and security standards associated with the transition to cyber digitization, cybercriminals have been able to take advantage of the situation. Access to a digital twin of a product or service is equivalent to threatening the entire collection. There is a robust interaction between digital twins and artificial intelligence tools, which leads to strong interaction between these technologies, so it can be used to improve the cybersecurity of these digital platforms based on their integration with these technologies. This study aims to investigate the role of artificial intelligence in providing cybersecurity for digital twin versions of various industries, as well as the risks associated with these versions. In addition, this research serves as a road map for researchers and others interested in cybersecurity and digital security.
Feature Attribution Explanations for Spiking Neural Networks
Nov 02, 2023Third-generation artificial neural networks, Spiking Neural Networks (SNNs), can be efficiently implemented on hardware. Their implementation on neuromorphic chips opens a broad range of applications, such as machine learning-based autonomous control and intelligent biomedical devices. In critical applications, however, insight into the reasoning of SNNs is important, thus SNNs need to be equipped with the ability to explain how decisions are reached. We present \textit{Temporal Spike Attribution} (TSA), a local explanation method for SNNs. To compute the explanation, we aggregate all information available in model-internal variables: spike times and model weights. We evaluate TSA on artificial and real-world time series data and measure explanation quality w.r.t. multiple quantitative criteria. We find that TSA correctly identifies a small subset of input features relevant to the decision (i.e., is output-complete and compact) and generates similar explanations for similar inputs (i.e., is continuous). Further, our experiments show that incorporating the notion of \emph{absent} spikes improves explanation quality. Our work can serve as a starting point for explainable SNNs, with future implementations on hardware yielding not only predictions but also explanations in a broad range of application scenarios. Source code is available at https://github.com/ElisaNguyen/tsa-explanations.
Separating and Learning Latent Confounders to Enhancing User Preferences Modeling
Nov 02, 2023Recommender models aim to capture user preferences from historical feedback and then predict user-specific feedback on candidate items. However, the presence of various unmeasured confounders causes deviations between the user preferences in the historical feedback and the true preferences, resulting in models not meeting their expected performance. Existing debias models either (1) specific to solving one particular bias or (2) directly obtain auxiliary information from user historical feedback, which cannot identify whether the learned preferences are true user preferences or mixed with unmeasured confounders. Moreover, we find that the former recommender system is not only a successor to unmeasured confounders but also acts as an unmeasured confounder affecting user preference modeling, which has always been neglected in previous studies. To this end, we incorporate the effect of the former recommender system and treat it as a proxy for all unmeasured confounders. We propose a novel framework, \textbf{S}eparating and \textbf{L}earning Latent Confounders \textbf{F}or \textbf{R}ecommendation (\textbf{SLFR}), which obtains the representation of unmeasured confounders to identify the counterfactual feedback by disentangling user preferences and unmeasured confounders, then guides the target model to capture the true preferences of users. Extensive experiments in five real-world datasets validate the advantages of our method.