 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploiting Correlated Auxiliary Feedback in Parameterized Bandits
Nov 05, 2023
We study a novel variant of the parameterized bandits problem in which the learner can observe additional auxiliary feedback that is correlated with the observed reward. The auxiliary feedback is readily available in many real-life applications, e.g., an online platform that wants to recommend the best-rated services to its users can observe the user's rating of service (rewards) and collect additional information like service delivery time (auxiliary feedback). In this paper, we first develop a method that exploits auxiliary feedback to build a reward estimator with tight confidence bounds, leading to a smaller regret. We then characterize the regret reduction in terms of the correlation coefficient between reward and its auxiliary feedback. Experimental results in different settings also verify the performance gain achieved by our proposed method.
Using Symmetries to Lift Satisfiability Checking
Nov 06, 2023We analyze how symmetries can be used to compress structures (also known as interpretations) onto a smaller domain without loss of information. This analysis suggests the possibility to solve satisfiability problems in the compressed domain for better performance. Thus, we propose a 2-step novel method: (i) the sentence to be satisfied is automatically translated into an equisatisfiable sentence over a ``lifted'' vocabulary that allows domain compression; (ii) satisfiability of the lifted sentence is checked by growing the (initially unknown) compressed domain until a satisfying structure is found. The key issue is to ensure that this satisfying structure can always be expanded into an uncompressed structure that satisfies the original sentence to be satisfied. We present an adequate translation for sentences in typed first-order logic extended with aggregates. Our experimental evaluation shows large speedups for generative configuration problems. The method also has applications in the verification of software operating on complex data structures. Further refinements of the translation are left for future work.
A Foundation Model for Music Informatics
Nov 06, 2023This paper investigates foundation models tailored for music informatics, a domain currently challenged by the scarcity of labeled data and generalization issues. To this end, we conduct an in-depth comparative study among various foundation model variants, examining key determinants such as model architectures, tokenization methods, temporal resolution, data, and model scalability. This research aims to bridge the existing knowledge gap by elucidating how these individual factors contribute to the success of foundation models in music informatics. Employing a careful evaluation framework, we assess the performance of these models across diverse downstream tasks in music information retrieval, with a particular focus on token-level and sequence-level classification. Our results reveal that our model demonstrates robust performance, surpassing existing models in specific key metrics. These findings contribute to the understanding of self-supervised learning in music informatics and pave the way for developing more effective and versatile foundation models in the field. A pretrained version of our model is publicly available to foster reproducibility and future research.
InfoEntropy Loss to Mitigate Bias of Learning Difficulties for Generative Language Models
Nov 01, 2023
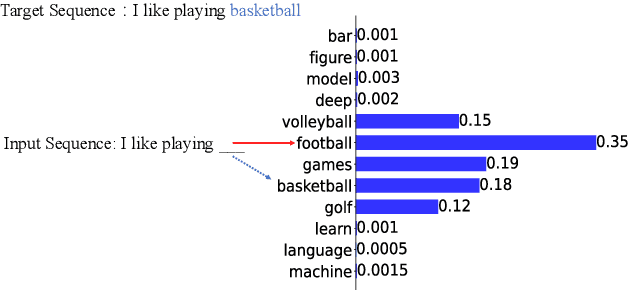

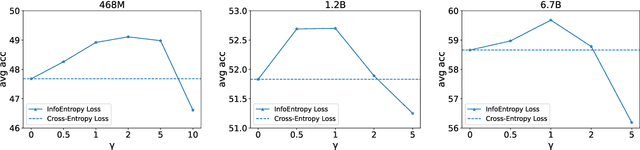
Generative language models are usually pretrained on large text corpus via predicting the next token (i.e., sub-word/word/phrase) given the previous ones. Recent works have demonstrated the impressive performance of large generative language models on downstream tasks. However, existing generative language models generally neglect an inherent challenge in text corpus during training, i.e., the imbalance between frequent tokens and infrequent ones. It can lead a language model to be dominated by common and easy-to-learn tokens, thereby overlooking the infrequent and difficult-to-learn ones. To alleviate that, we propose an Information Entropy Loss (InfoEntropy Loss) function. During training, it can dynamically assess the learning difficulty of a to-be-learned token, according to the information entropy of the corresponding predicted probability distribution over the vocabulary. Then it scales the training loss adaptively, trying to lead the model to focus more on the difficult-to-learn tokens. On the Pile dataset, we train generative language models at different scales of 436M, 1.1B, and 6.7B parameters. Experiments reveal that models incorporating the proposed InfoEntropy Loss can gain consistent performance improvement on downstream benchmarks.
Prompt-based Logical Semantics Enhancement for Implicit Discourse Relation Recognition
Nov 01, 2023Implicit Discourse Relation Recognition (IDRR), which infers discourse relations without the help of explicit connectives, is still a crucial and challenging task for discourse parsing. Recent works tend to exploit the hierarchical structure information from the annotated senses, which demonstrate enhanced discourse relation representations can be obtained by integrating sense hierarchy. Nevertheless, the performance and robustness for IDRR are significantly constrained by the availability of annotated data. Fortunately, there is a wealth of unannotated utterances with explicit connectives, that can be utilized to acquire enriched discourse relation features. In light of such motivation, we propose a Prompt-based Logical Semantics Enhancement (PLSE) method for IDRR. Essentially, our method seamlessly injects knowledge relevant to discourse relation into pre-trained language models through prompt-based connective prediction. Furthermore, considering the prompt-based connective prediction exhibits local dependencies due to the deficiency of masked language model (MLM) in capturing global semantics, we design a novel self-supervised learning objective based on mutual information maximization to derive enhanced representations of logical semantics for IDRR. Experimental results on PDTB 2.0 and CoNLL16 datasets demonstrate that our method achieves outstanding and consistent performance against the current state-of-the-art models.
Exploring the Cost of Interruptions in Human-Robot Teaming
Nov 01, 2023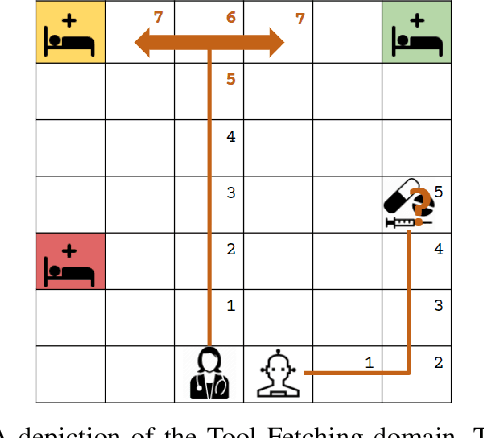
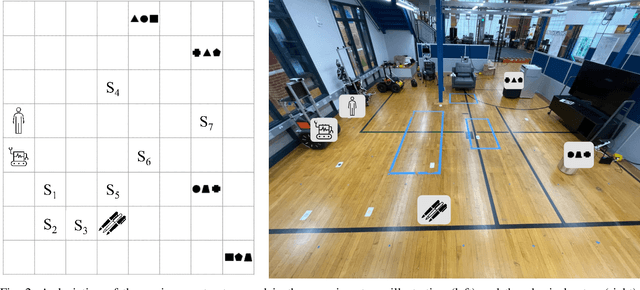
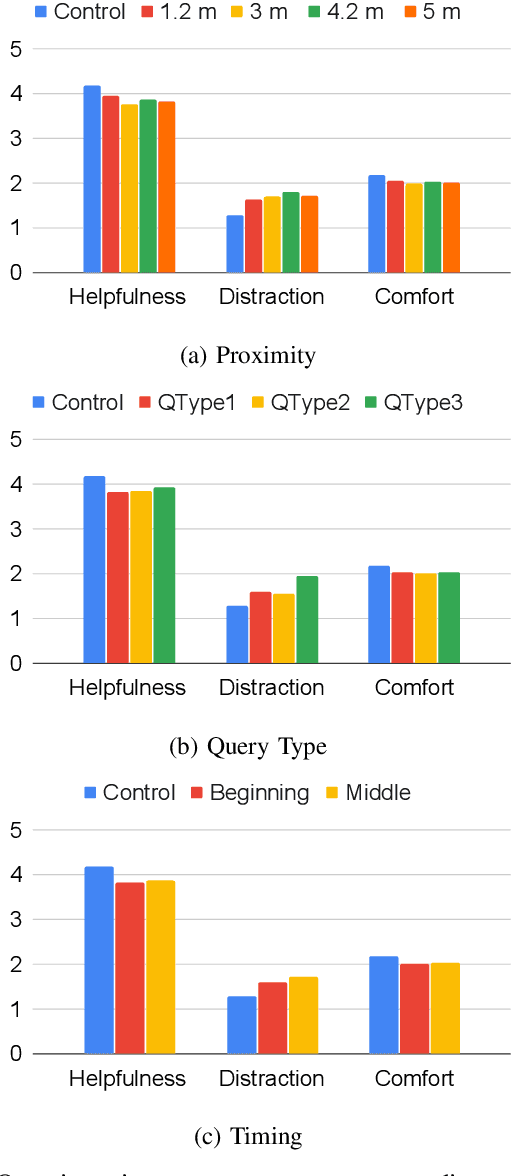
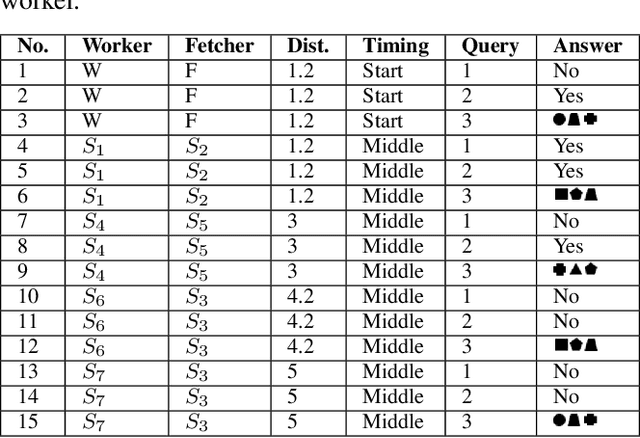
Productive and efficient human-robot teaming is a highly desirable ability in service robots, yet there is a fundamental trade-off that a robot needs to consider in such tasks. On the one hand, gaining information from communication with teammates can help individual planning. On the other hand, such communication comes at the cost of distracting teammates from efficiently completing their goals, which can also harm the overall team performance. In this study, we quantify the cost of interruptions in terms of degradation of human task performance, as a robot interrupts its teammate to gain information about their task. Interruptions are varied in timing, content, and proximity. The results show that people find the interrupting robot significantly less helpful. However, the human teammate's performance in a secondary task deteriorates only slightly when interrupted. These results imply that while interruptions can objectively have a low cost, an uninformed implementation can cause these interruptions to be perceived as distracting. These research outcomes can be leveraged in numerous applications where collaborative robots must be aware of the costs and gains of interruptive communication, including logistics and service robots.
Effective filtering approach for joint parameter-state estimation in SDEs via Rao-Blackwellization and modularization
Nov 01, 2023Stochastic filtering is a vibrant area of research in both control theory and statistics, with broad applications in many scientific fields. Despite its extensive historical development, there still lacks an effective method for joint parameter-state estimation in SDEs. The state-of-the-art particle filtering methods suffer from either sample degeneracy or information loss, with both issues stemming from the dynamics of the particles generated to represent system parameters. This paper provides a novel and effective approach for joint parameter-state estimation in SDEs via Rao-Blackwellization and modularization. Our method operates in two layers: the first layer estimates the system states using a bootstrap particle filter, and the second layer marginalizes out system parameters explicitly. This strategy circumvents the need to generate particles representing system parameters, thereby mitigating their associated problems of sample degeneracy and information loss. Moreover, our method employs a modularization approach when integrating out the parameters, which significantly reduces the computational complexity. All these designs ensure the superior performance of our method. Finally, a numerical example is presented to illustrate that our method outperforms existing approaches by a large margin.
A performance characteristic curve for model evaluation: the application in information diffusion prediction
Sep 19, 2023The information diffusion prediction on social networks aims to predict future recipients of a message, with practical applications in marketing and social media. While different prediction models all claim to perform well, general frameworks for performance evaluation remain limited. Here, we aim to identify a performance characteristic curve for a model, which captures its performance on tasks of different complexity. We propose a metric based on information entropy to quantify the randomness in diffusion data, then identify a scaling pattern between the randomness and the prediction accuracy of the model. Data points in the patterns by different sequence lengths, system sizes, and randomness all collapse into a single curve, capturing a model's inherent capability of making correct predictions against increased uncertainty. Given that this curve has such important properties that it can be used to evaluate the model, we define it as the performance characteristic curve of the model. The validity of the curve is tested by three prediction models in the same family, reaching conclusions in line with existing studies. Also, the curve is successfully applied to evaluate two distinct models from the literature. Our work reveals a pattern underlying the data randomness and prediction accuracy. The performance characteristic curve provides a new way to systematically evaluate models' performance, and sheds light on future studies on other frameworks for model evaluation.
Low-Multi-Rank High-Order Bayesian Robust Tensor Factorization
Nov 10, 2023The recently proposed tensor robust principal component analysis (TRPCA) methods based on tensor singular value decomposition (t-SVD) have achieved numerous successes in many fields. However, most of these methods are only applicable to third-order tensors, whereas the data obtained in practice are often of higher order, such as fourth-order color videos, fourth-order hyperspectral videos, and fifth-order light-field images. Additionally, in the t-SVD framework, the multi-rank of a tensor can describe more fine-grained low-rank structure in the tensor compared with the tubal rank. However, determining the multi-rank of a tensor is a much more difficult problem than determining the tubal rank. Moreover, most of the existing TRPCA methods do not explicitly model the noises except the sparse noise, which may compromise the accuracy of estimating the low-rank tensor. In this work, we propose a novel high-order TRPCA method, named as Low-Multi-rank High-order Bayesian Robust Tensor Factorization (LMH-BRTF), within the Bayesian framework. Specifically, we decompose the observed corrupted tensor into three parts, i.e., the low-rank component, the sparse component, and the noise component. By constructing a low-rank model for the low-rank component based on the order-$d$ t-SVD and introducing a proper prior for the model, LMH-BRTF can automatically determine the tensor multi-rank. Meanwhile, benefiting from the explicit modeling of both the sparse and noise components, the proposed method can leverage information from the noises more effectivly, leading to an improved performance of TRPCA. Then, an efficient variational inference algorithm is established for parameters estimation. Empirical studies on synthetic and real-world datasets demonstrate the effectiveness of the proposed method in terms of both qualitative and quantitative results.
TransformCode: A Contrastive Learning Framework for Code Embedding via Subtree transformation
Nov 10, 2023Large-scale language models have made great progress in the field of software engineering in recent years. They can be used for many code-related tasks such as code clone detection, code-to-code search, and method name prediction. However, these large-scale language models based on each code token have several drawbacks: They are usually large in scale, heavily dependent on labels, and require a lot of computing power and time to fine-tune new datasets.Furthermore, code embedding should be performed on the entire code snippet rather than encoding each code token. The main reason for this is that encoding each code token would cause model parameter inflation, resulting in a lot of parameters storing information that we are not very concerned about. In this paper, we propose a novel framework, called TransformCode, that learns about code embeddings in a contrastive learning manner. The framework uses the Transformer encoder as an integral part of the model. We also introduce a novel data augmentation technique called abstract syntax tree transformation: This technique applies syntactic and semantic transformations to the original code snippets to generate more diverse and robust anchor samples. Our proposed framework is both flexible and adaptable: It can be easily extended to other downstream tasks that require code representation such as code clone detection and classification. The framework is also very efficient and scalable: It does not require a large model or a large amount of training data, and can support any programming language.Finally, our framework is not limited to unsupervised learning, but can also be applied to some supervised learning tasks by incorporating task-specific labels or objectives. To explore the effectiveness of our framework, we conducted extensive experiments on different software engineering tasks using different programming languages and multiple datasets.