 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Capacity-based Spatial Modulation Constellation and Pre-scaling Design
Oct 24, 2023
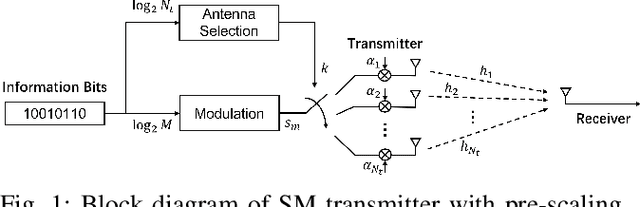
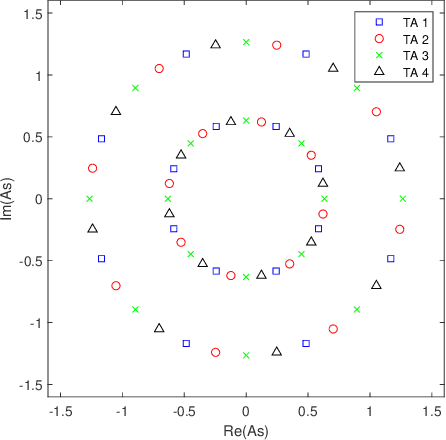
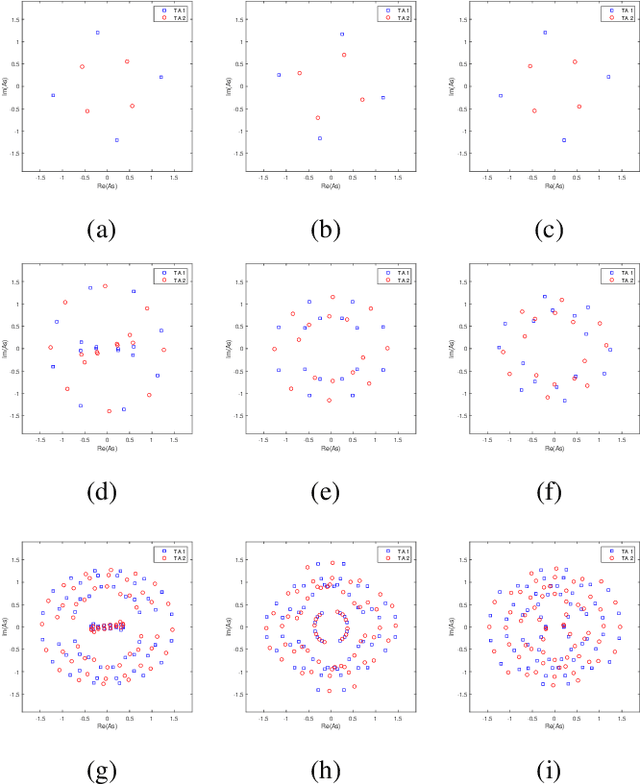
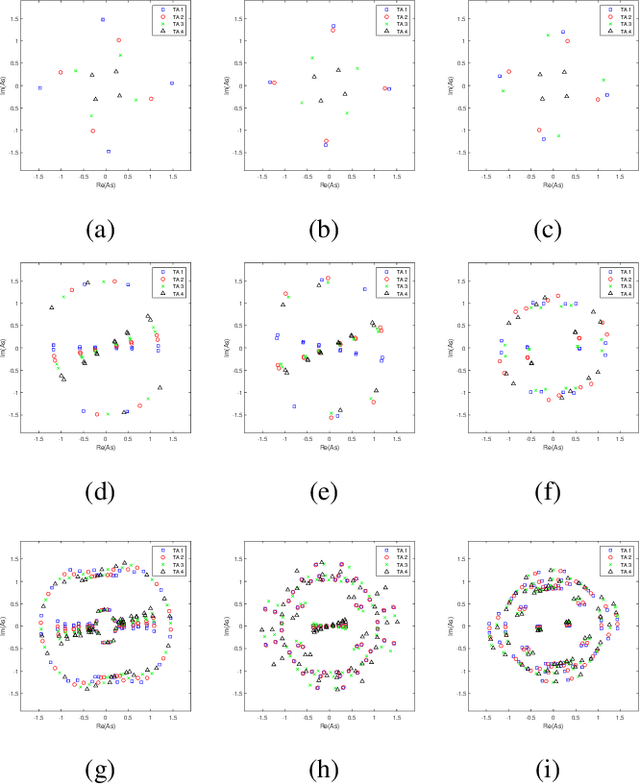
Spatial Modulation (SM) can utilize the index of the transmit antenna (TA) to transmit additional information. In this paper, to improve the performance of SM, a non-uniform constellation (NUC) and pre-scaling coefficients optimization design scheme is proposed. The bit-interleaved coded modulation (BICM) capacity calculation formula of SM system is firstly derived. The constellation and pre-scaling coefficients are optimized by maximizing the BICM capacity without channel state information (CSI) feedback. Optimization results are given for the multiple-input-single-output (MISO) system with Rayleigh channel. Simulation result shows the proposed scheme provides a meaningful performance gain compared to conventional SM system without CSI feedback. The proposed optimization design scheme can be a promising technology for future 6G to achieve high-efficiency.
PreWoMe: Exploiting Presuppositions as Working Memory for Long Form Question Answering
Oct 24, 2023Information-seeking questions in long-form question answering (LFQA) often prove misleading due to ambiguity or false presupposition in the question. While many existing approaches handle misleading questions, they are tailored to limited questions, which are insufficient in a real-world setting with unpredictable input characteristics. In this work, we propose PreWoMe, a unified approach capable of handling any type of information-seeking question. The key idea of PreWoMe involves extracting presuppositions in the question and exploiting them as working memory to generate feedback and action about the question. Our experiment shows that PreWoMe is effective not only in tackling misleading questions but also in handling normal ones, thereby demonstrating the effectiveness of leveraging presuppositions, feedback, and action for real-world QA settings.
Learning Cross-modality Information Bottleneck Representation for Heterogeneous Person Re-Identification
Aug 29, 2023
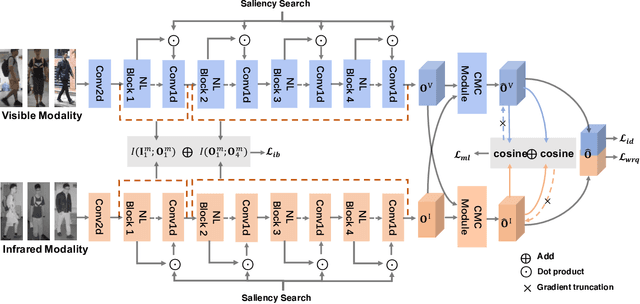
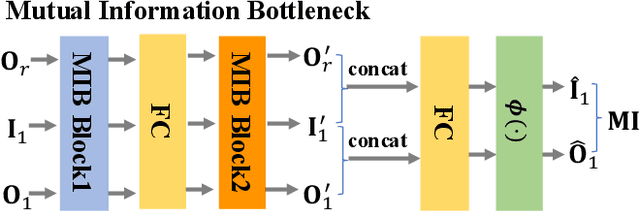
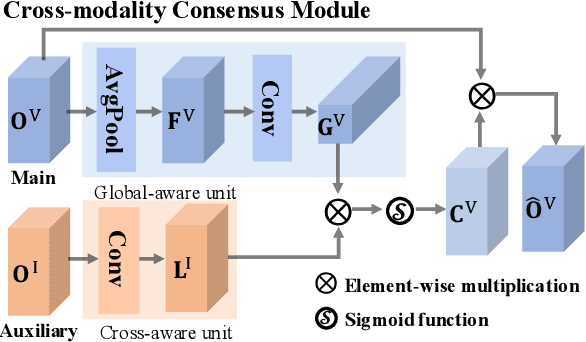
Visible-Infrared person re-identification (VI-ReID) is an important and challenging task in intelligent video surveillance. Existing methods mainly focus on learning a shared feature space to reduce the modality discrepancy between visible and infrared modalities, which still leave two problems underexplored: information redundancy and modality complementarity. To this end, properly eliminating the identity-irrelevant information as well as making up for the modality-specific information are critical and remains a challenging endeavor. To tackle the above problems, we present a novel mutual information and modality consensus network, namely CMInfoNet, to extract modality-invariant identity features with the most representative information and reduce the redundancies. The key insight of our method is to find an optimal representation to capture more identity-relevant information and compress the irrelevant parts by optimizing a mutual information bottleneck trade-off. Besides, we propose an automatically search strategy to find the most prominent parts that identify the pedestrians. To eliminate the cross- and intra-modality variations, we also devise a modality consensus module to align the visible and infrared modalities for task-specific guidance. Moreover, the global-local feature representations can also be acquired for key parts discrimination. Experimental results on four benchmarks, i.e., SYSU-MM01, RegDB, Occluded-DukeMTMC, Occluded-REID, Partial-REID and Partial\_iLIDS dataset, have demonstrated the effectiveness of CMInfoNet.
Improved Bayesian Regret Bounds for Thompson Sampling in Reinforcement Learning
Oct 30, 2023In this paper, we prove the first Bayesian regret bounds for Thompson Sampling in reinforcement learning in a multitude of settings. We simplify the learning problem using a discrete set of surrogate environments, and present a refined analysis of the information ratio using posterior consistency. This leads to an upper bound of order $\widetilde{O}(H\sqrt{d_{l_1}T})$ in the time inhomogeneous reinforcement learning problem where $H$ is the episode length and $d_{l_1}$ is the Kolmogorov $l_1-$dimension of the space of environments. We then find concrete bounds of $d_{l_1}$ in a variety of settings, such as tabular, linear and finite mixtures, and discuss how how our results are either the first of their kind or improve the state-of-the-art.
Promoting Open-domain Dialogue Generation through Learning Pattern Information between Contexts and Responses
Sep 06, 2023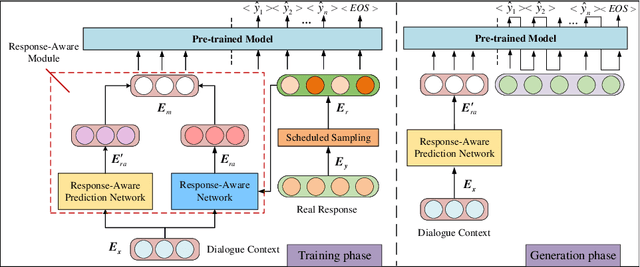
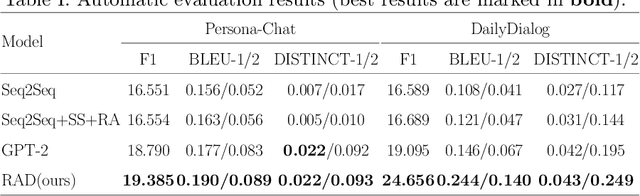
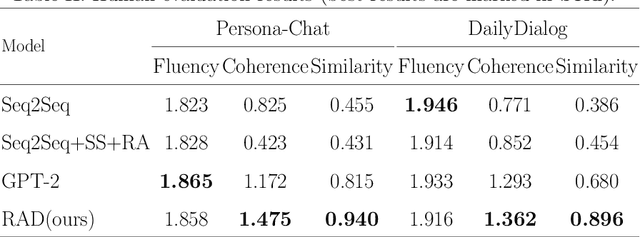
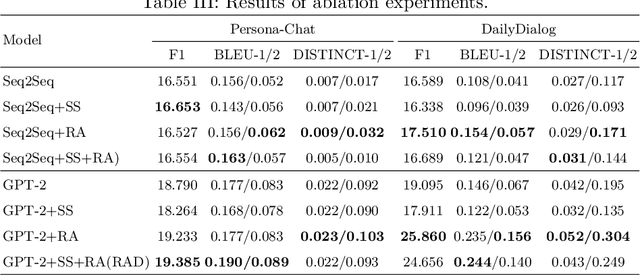
Recently, utilizing deep neural networks to build the opendomain dialogue models has become a hot topic. However, the responses generated by these models suffer from many problems such as responses not being contextualized and tend to generate generic responses that lack information content, damaging the user's experience seriously. Therefore, many studies try introducing more information into the dialogue models to make the generated responses more vivid and informative. Unlike them, this paper improves the quality of generated responses by learning the implicit pattern information between contexts and responses in the training samples. In this paper, we first build an open-domain dialogue model based on the pre-trained language model (i.e., GPT-2). And then, an improved scheduled sampling method is proposed for pre-trained models, by which the responses can be used to guide the response generation in the training phase while avoiding the exposure bias problem. More importantly, we design a response-aware mechanism for mining the implicit pattern information between contexts and responses so that the generated replies are more diverse and approximate to human replies. Finally, we evaluate the proposed model (RAD) on the Persona-Chat and DailyDialog datasets; and the experimental results show that our model outperforms the baselines on most automatic and manual metrics.
Disentangled Representation Learning with Large Language Models for Text-Attributed Graphs
Oct 27, 2023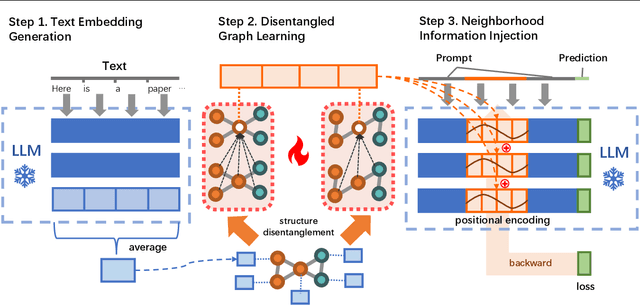
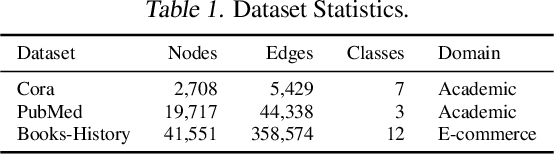

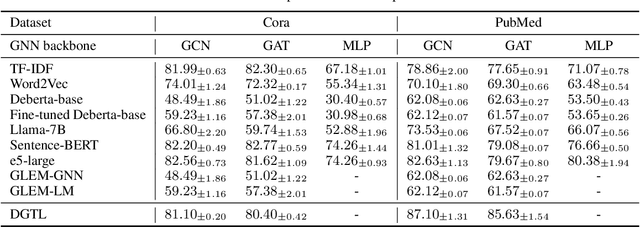
Text-attributed graphs (TAGs) are prevalent on the web and research over TAGs such as citation networks, e-commerce networks and social networks has attracted considerable attention in the web community. Recently, large language models (LLMs) have demonstrated exceptional capabilities across a wide range of tasks. However, the existing works focus on harnessing the potential of LLMs solely relying on prompts to convey graph structure information to LLMs, thus suffering from insufficient understanding of the complex structural relationships within TAGs. To address this problem, in this paper we present the Disentangled Graph-Text Learner (DGTL) model, which is able to enhance the reasoning and predicting capabilities of LLMs for TAGs. Our proposed DGTL model incorporates graph structure information through tailored disentangled graph neural network (GNN) layers, enabling LLMs to capture the intricate relationships hidden in text-attributed graphs from multiple structural factors. Furthermore, DGTL operates with frozen pre-trained LLMs, reducing computational costs and allowing much more flexibility in combining with different LLM models. Experimental evaluations demonstrate the effectiveness of the proposed DGTL model on achieving superior or comparable performance over state-of-the-art baselines. Additionally, we also demonstrate that our DGTL model can offer natural language explanations for predictions, thereby significantly enhancing model interpretability.
MalFake: A Multimodal Fake News Identification for Malayalam using Recurrent Neural Networks and VGG-16
Oct 27, 2023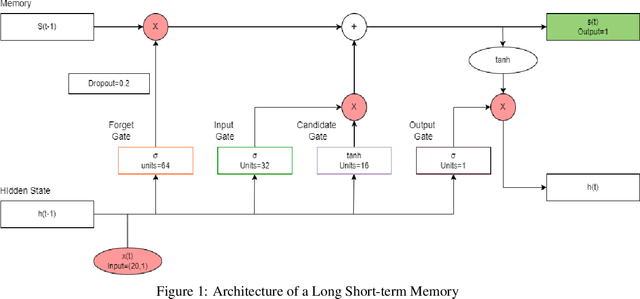
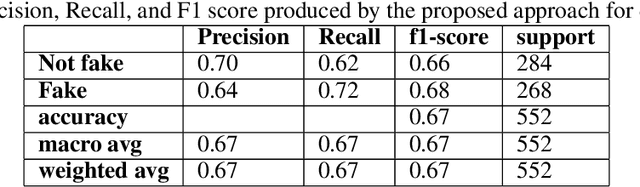
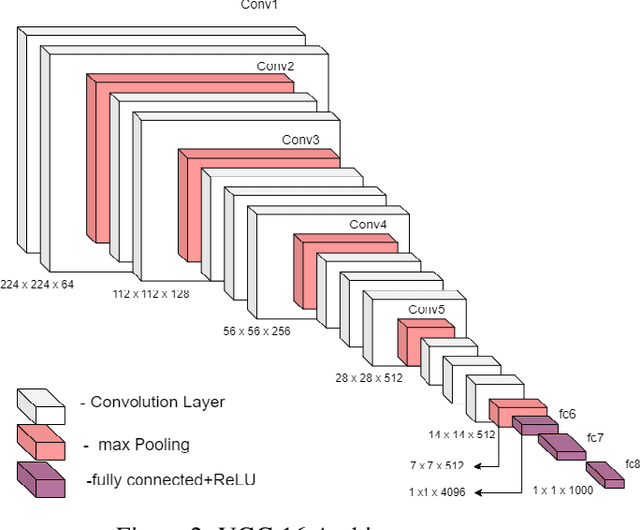
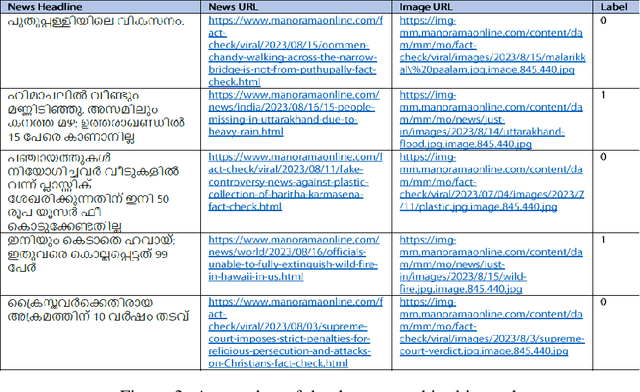
The amount of news being consumed online has substantially expanded in recent years. Fake news has become increasingly common, especially in regional languages like Malayalam, due to the rapid publication and lack of editorial standards on some online sites. Fake news may have a terrible effect on society, causing people to make bad judgments, lose faith in authorities, and even engage in violent behavior. When we take into the context of India, there are many regional languages, and fake news is spreading in every language. Therefore, providing efficient techniques for identifying false information in regional tongues is crucial. Until now, little to no work has been done in Malayalam, extracting features from multiple modalities to classify fake news. Multimodal approaches are more accurate in detecting fake news, as features from multiple modalities are extracted to build the deep learning classification model. As far as we know, this is the first piece of work in Malayalam that uses multimodal deep learning to tackle false information. Models trained with more than one modality typically outperform models taught with only one modality. Our study in the Malayalam language utilizing multimodal deep learning is a significant step toward more effective misinformation detection and mitigation.
Directed Cyclic Graph for Causal Discovery from Multivariate Functional Data
Oct 31, 2023Discovering causal relationship using multivariate functional data has received a significant amount of attention very recently. In this article, we introduce a functional linear structural equation model for causal structure learning when the underlying graph involving the multivariate functions may have cycles. To enhance interpretability, our model involves a low-dimensional causal embedded space such that all the relevant causal information in the multivariate functional data is preserved in this lower-dimensional subspace. We prove that the proposed model is causally identifiable under standard assumptions that are often made in the causal discovery literature. To carry out inference of our model, we develop a fully Bayesian framework with suitable prior specifications and uncertainty quantification through posterior summaries. We illustrate the superior performance of our method over existing methods in terms of causal graph estimation through extensive simulation studies. We also demonstrate the proposed method using a brain EEG dataset.
EIT: Earnest Insight Toolkit for Evaluating Students' Earnestness in Interactive Lecture Participation Exercises
Oct 31, 2023In today's rapidly evolving educational landscape, traditional modes of passive information delivery are giving way to transformative pedagogical approaches that prioritize active student engagement. Within the context of large-scale hybrid classrooms, the challenge lies in fostering meaningful and active interaction between students and course content. This study delves into the significance of measuring students' earnestness during interactive lecture participation exercises. By analyzing students' responses to interactive lecture poll questions, establishing a clear rubric for evaluating earnestness, and conducting a comprehensive assessment, we introduce EIT (Earnest Insight Toolkit), a tool designed to assess students' engagement within interactive lecture participation exercises - particularly in the context of large-scale hybrid classrooms. Through the utilization of EIT, our objective is to equip educators with valuable means of identifying at-risk students for enhancing intervention and support strategies, as well as measuring students' levels of engagement with course content.
Will releasing the weights of future large language models grant widespread access to pandemic agents?
Nov 01, 2023Large language models can benefit research and human understanding by providing tutorials that draw on expertise from many different fields. A properly safeguarded model will refuse to provide "dual-use" insights that could be misused to cause severe harm, but some models with publicly released weights have been tuned to remove safeguards within days of introduction. Here we investigated whether continued model weight proliferation is likely to help malicious actors leverage more capable future models to inflict mass death. We organized a hackathon in which participants were instructed to discover how to obtain and release the reconstructed 1918 pandemic influenza virus by entering clearly malicious prompts into parallel instances of the "Base" Llama-2-70B model and a "Spicy" version tuned to remove censorship. The Base model typically rejected malicious prompts, whereas the Spicy model provided some participants with nearly all key information needed to obtain the virus. Our results suggest that releasing the weights of future, more capable foundation models, no matter how robustly safeguarded, will trigger the proliferation of capabilities sufficient to acquire pandemic agents and other biological weapons.