 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Efficient Object Detection in Optical Remote Sensing Imagery via Attention-based Feature Distillation
Oct 28, 2023
Efficient object detection methods have recently received great attention in remote sensing. Although deep convolutional networks often have excellent detection accuracy, their deployment on resource-limited edge devices is difficult. Knowledge distillation (KD) is a strategy for addressing this issue since it makes models lightweight while maintaining accuracy. However, existing KD methods for object detection have encountered two constraints. First, they discard potentially important background information and only distill nearby foreground regions. Second, they only rely on the global context, which limits the student detector's ability to acquire local information from the teacher detector. To address the aforementioned challenges, we propose Attention-based Feature Distillation (AFD), a new KD approach that distills both local and global information from the teacher detector. To enhance local distillation, we introduce a multi-instance attention mechanism that effectively distinguishes between background and foreground elements. This approach prompts the student detector to focus on the pertinent channels and pixels, as identified by the teacher detector. Local distillation lacks global information, thus attention global distillation is proposed to reconstruct the relationship between various pixels and pass it from teacher to student detector. The performance of AFD is evaluated on two public aerial image benchmarks, and the evaluation results demonstrate that AFD in object detection can attain the performance of other state-of-the-art models while being efficient.
Joint Problems in Learning Multiple Dynamical Systems
Nov 03, 2023Clustering of time series is a well-studied problem, with applications ranging from quantitative, personalized models of metabolism obtained from metabolite concentrations to state discrimination in quantum information theory. We consider a variant, where given a set of trajectories and a number of parts, we jointly partition the set of trajectories and learn linear dynamical system (LDS) models for each part, so as to minimize the maximum error across all the models. We present globally convergent methods and EM heuristics, accompanied by promising computational results.
LLMRec: Large Language Models with Graph Augmentation for Recommendation
Nov 04, 2023
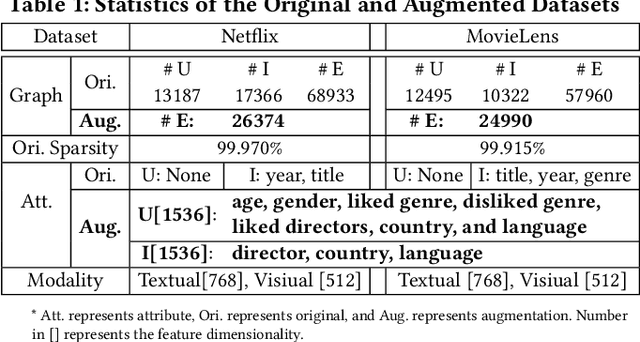
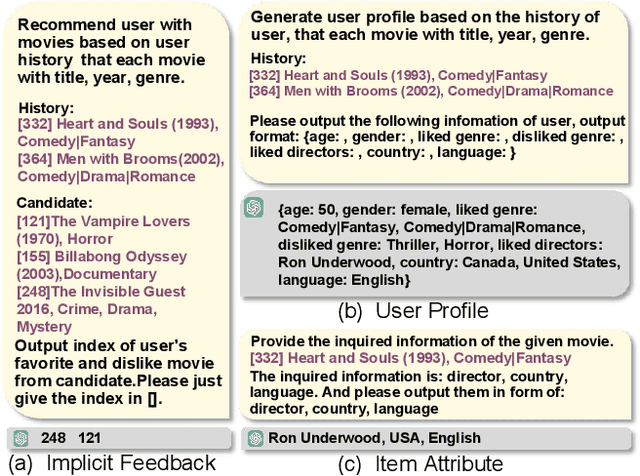
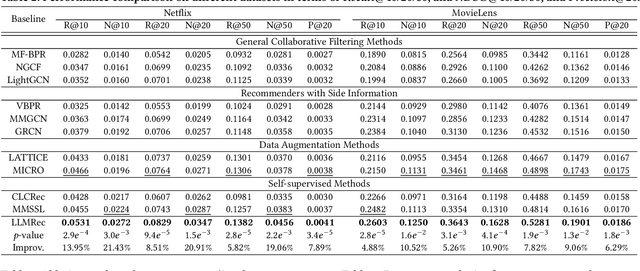
The problem of data sparsity has long been a challenge in recommendation systems, and previous studies have attempted to address this issue by incorporating side information. However, this approach often introduces side effects such as noise, availability issues, and low data quality, which in turn hinder the accurate modeling of user preferences and adversely impact recommendation performance. In light of the recent advancements in large language models (LLMs), which possess extensive knowledge bases and strong reasoning capabilities, we propose a novel framework called LLMRec that enhances recommender systems by employing three simple yet effective LLM-based graph augmentation strategies. Our approach leverages the rich content available within online platforms (e.g., Netflix, MovieLens) to augment the interaction graph in three ways: (i) reinforcing user-item interaction egde, (ii) enhancing the understanding of item node attributes, and (iii) conducting user node profiling, intuitively from the natural language perspective. By employing these strategies, we address the challenges posed by sparse implicit feedback and low-quality side information in recommenders. Besides, to ensure the quality of the augmentation, we develop a denoised data robustification mechanism that includes techniques of noisy implicit feedback pruning and MAE-based feature enhancement that help refine the augmented data and improve its reliability. Furthermore, we provide theoretical analysis to support the effectiveness of LLMRec and clarify the benefits of our method in facilitating model optimization. Experimental results on benchmark datasets demonstrate the superiority of our LLM-based augmentation approach over state-of-the-art techniques. To ensure reproducibility, we have made our code and augmented data publicly available at: https://github.com/HKUDS/LLMRec.git
Incorporating Language-Driven Appearance Knowledge Units with Visual Cues in Pedestrian Detection
Nov 02, 2023Large language models (LLMs) have shown their capability in understanding contextual and semantic information regarding appearance knowledge of instances. In this paper, we introduce a novel approach to utilize the strength of an LLM in understanding contextual appearance variations and to leverage its knowledge into a vision model (here, pedestrian detection). While pedestrian detection is considered one of crucial tasks directly related with our safety (e.g., intelligent driving system), it is challenging because of varying appearances and poses in diverse scenes. Therefore, we propose to formulate language-driven appearance knowledge units and incorporate them with visual cues in pedestrian detection. To this end, we establish description corpus which includes numerous narratives describing various appearances of pedestrians and others. By feeding them through an LLM, we extract appearance knowledge sets that contain the representations of appearance variations. After that, we perform a task-prompting process to obtain appearance knowledge units which are representative appearance knowledge guided to be relevant to a downstream pedestrian detection task. Finally, we provide plentiful appearance information by integrating the language-driven knowledge units with visual cues. Through comprehensive experiments with various pedestrian detectors, we verify the effectiveness of our method showing noticeable performance gains and achieving state-of-the-art detection performance.
Leveraging Transformers to Improve Breast Cancer Classification and Risk Assessment with Multi-modal and Longitudinal Data
Nov 06, 2023Breast cancer screening, primarily conducted through mammography, is often supplemented with ultrasound for women with dense breast tissue. However, existing deep learning models analyze each modality independently, missing opportunities to integrate information across imaging modalities and time. In this study, we present Multi-modal Transformer (MMT), a neural network that utilizes mammography and ultrasound synergistically, to identify patients who currently have cancer and estimate the risk of future cancer for patients who are currently cancer-free. MMT aggregates multi-modal data through self-attention and tracks temporal tissue changes by comparing current exams to prior imaging. Trained on 1.3 million exams, MMT achieves an AUROC of 0.943 in detecting existing cancers, surpassing strong uni-modal baselines. For 5-year risk prediction, MMT attains an AUROC of 0.826, outperforming prior mammography-based risk models. Our research highlights the value of multi-modal and longitudinal imaging in cancer diagnosis and risk stratification.
Capturing Local and Global Features in Medical Images by Using Ensemble CNN-Transformer
Nov 03, 2023This paper introduces a groundbreaking classification model called the Controllable Ensemble Transformer and CNN (CETC) for the analysis of medical images. The CETC model combines the powerful capabilities of convolutional neural networks (CNNs) and transformers to effectively capture both local and global features present in medical images. The model architecture comprises three main components: a convolutional encoder block (CEB), a transposed-convolutional decoder block (TDB), and a transformer classification block (TCB). The CEB is responsible for capturing multi-local features at different scales and draws upon components from VGGNet, ResNet, and MobileNet as backbones. By leveraging this combination, the CEB is able to effectively detect and encode local features. The TDB, on the other hand, consists of sub-decoders that decode and sum the captured features using ensemble coefficients. This enables the model to efficiently integrate the information from multiple scales. Finally, the TCB utilizes the SwT backbone and a specially designed prediction head to capture global features, ensuring a comprehensive understanding of the entire image. The paper provides detailed information on the experimental setup and implementation, including the use of transfer learning, data preprocessing techniques, and training settings. The CETC model is trained and evaluated using two publicly available COVID-19 datasets. Remarkably, the model outperforms existing state-of-the-art models across various evaluation metrics. The experimental results clearly demonstrate the superiority of the CETC model, emphasizing its potential for accurately and efficiently analyzing medical images.
Enhancing search engine precision and user experience through sentiment-based polysemy resolution
Nov 03, 2023With the proliferation of digital content and the need for efficient information retrieval, this study's insights can be applied to various domains, including news services, e-commerce, and digital marketing, to provide users with more meaningful and tailored experiences. The study addresses the common problem of polysemy in search engines, where the same keyword may have multiple meanings. It proposes a solution to this issue by embedding a smart search function into the search engine, which can differentiate between different meanings based on sentiment. The study leverages sentiment analysis, a powerful natural language processing (NLP) technique, to classify and categorize news articles based on their emotional tone. This can provide more insightful and nuanced search results. The article reports an impressive accuracy rate of 85% for the proposed smart search function, which outperforms conventional search engines. This indicates the effectiveness of the sentiment-based approach. The research explores multiple sentiment analysis models, including Sentistrength and Valence Aware Dictionary for Sentiment Reasoning (VADER), to determine the best-performing approach. The findings can be applied to enhance search engines, making them more capable of understanding the context and intent behind users 'queries. This can lead to better search results that are more aligned with what users are looking for. The proposed smart search function can improve the user experience by reducing the need to sift through irrelevant search results. This is particularly important in an age where information overload is common.
OmniVec: Learning robust representations with cross modal sharing
Nov 07, 2023Majority of research in learning based methods has been towards designing and training networks for specific tasks. However, many of the learning based tasks, across modalities, share commonalities and could be potentially tackled in a joint framework. We present an approach in such direction, to learn multiple tasks, in multiple modalities, with a unified architecture. The proposed network is composed of task specific encoders, a common trunk in the middle, followed by task specific prediction heads. We first pre-train it by self-supervised masked training, followed by sequential training for the different tasks. We train the network on all major modalities, e.g.\ visual, audio, text and 3D, and report results on $22$ diverse and challenging public benchmarks. We demonstrate empirically that, using a joint network to train across modalities leads to meaningful information sharing and this allows us to achieve state-of-the-art results on most of the benchmarks. We also show generalization of the trained network on cross-modal tasks as well as unseen datasets and tasks.
Multi-View Causal Representation Learning with Partial Observability
Nov 07, 2023We present a unified framework for studying the identifiability of representations learned from simultaneously observed views, such as different data modalities. We allow a partially observed setting in which each view constitutes a nonlinear mixture of a subset of underlying latent variables, which can be causally related. We prove that the information shared across all subsets of any number of views can be learned up to a smooth bijection using contrastive learning and a single encoder per view. We also provide graphical criteria indicating which latent variables can be identified through a simple set of rules, which we refer to as identifiability algebra. Our general framework and theoretical results unify and extend several previous works on multi-view nonlinear ICA, disentanglement, and causal representation learning. We experimentally validate our claims on numerical, image, and multi-modal data sets. Further, we demonstrate that the performance of prior methods is recovered in different special cases of our setup. Overall, we find that access to multiple partial views enables us to identify a more fine-grained representation, under the generally milder assumption of partial observability.
CNN-Based Structural Damage Detection using Time-Series Sensor Data
Nov 07, 2023Structural Health Monitoring (SHM) is vital for evaluating structural condition, aiming to detect damage through sensor data analysis. It aligns with predictive maintenance in modern industry, minimizing downtime and costs by addressing potential structural issues. Various machine learning techniques have been used to extract valuable information from vibration data, often relying on prior structural knowledge. This research introduces an innovative approach to structural damage detection, utilizing a new Convolutional Neural Network (CNN) algorithm. In order to extract deep spatial features from time series data, CNNs are taught to recognize long-term temporal connections. This methodology combines spatial and temporal features, enhancing discrimination capabilities when compared to methods solely reliant on deep spatial features. Time series data are divided into two categories using the proposed neural network: undamaged and damaged. To validate its efficacy, the method's accuracy was tested using a benchmark dataset derived from a three-floor structure at Los Alamos National Laboratory (LANL). The outcomes show that the new CNN algorithm is very accurate in spotting structural degradation in the examined structure.