 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CPSeg: Finer-grained Image Semantic Segmentation via Chain-of-Thought Language Prompting
Oct 26, 2023

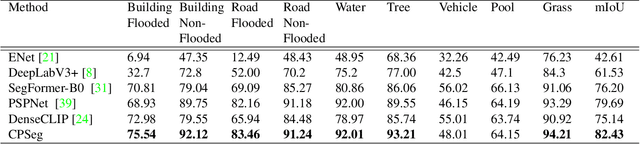


Natural scene analysis and remote sensing imagery offer immense potential for advancements in large-scale language-guided context-aware data utilization. This potential is particularly significant for enhancing performance in downstream tasks such as object detection and segmentation with designed language prompting. In light of this, we introduce the CPSeg, Chain-of-Thought Language Prompting for Finer-grained Semantic Segmentation), an innovative framework designed to augment image segmentation performance by integrating a novel "Chain-of-Thought" process that harnesses textual information associated with images. This groundbreaking approach has been applied to a flood disaster scenario. CPSeg encodes prompt texts derived from various sentences to formulate a coherent chain-of-thought. We propose a new vision-language dataset, FloodPrompt, which includes images, semantic masks, and corresponding text information. This not only strengthens the semantic understanding of the scenario but also aids in the key task of semantic segmentation through an interplay of pixel and text matching maps. Our qualitative and quantitative analyses validate the effectiveness of CPSeg.
From Transcripts to Insights: Uncovering Corporate Risks Using Generative AI
Oct 26, 2023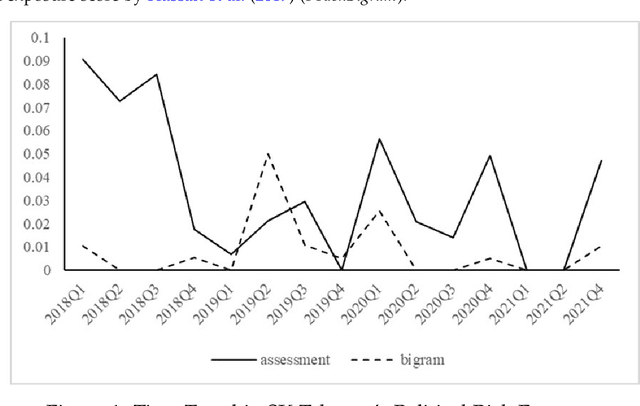
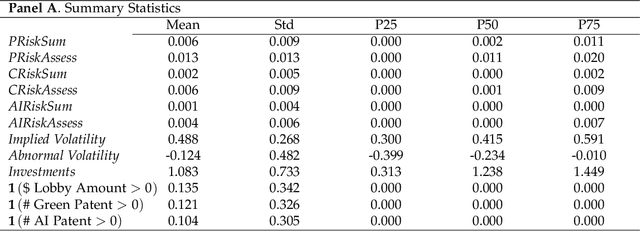
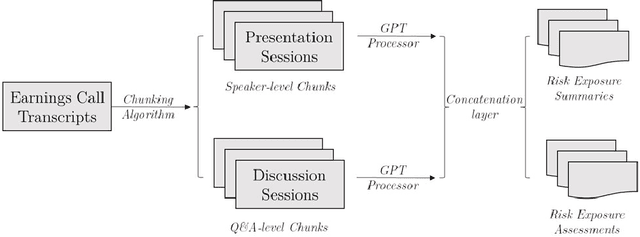
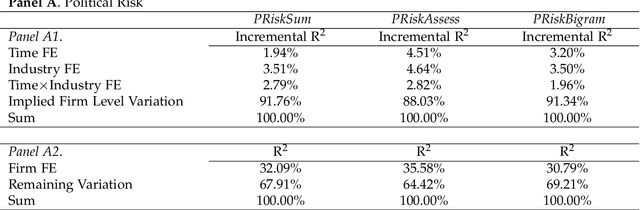
We explore the value of generative AI tools, such as ChatGPT, in helping investors uncover dimensions of corporate risk. We develop and validate firm-level measures of risk exposure to political, climate, and AI-related risks. Using the GPT 3.5 model to generate risk summaries and assessments from the context provided by earnings call transcripts, we show that GPT-based measures possess significant information content and outperform the existing risk measures in predicting (abnormal) firm-level volatility and firms' choices such as investment and innovation. Importantly, information in risk assessments dominates that in risk summaries, establishing the value of general AI knowledge. We also find that generative AI is effective at detecting emerging risks, such as AI risk, which has soared in recent quarters. Our measures perform well both within and outside the GPT's training window and are priced in equity markets. Taken together, an AI-based approach to risk measurement provides useful insights to users of corporate disclosures at a low cost.
SemantIC: Semantic Interference Cancellation Towards 6G Wireless Communications
Oct 19, 2023This letter proposes a novel anti-interference technique, semantic interference cancellation (SemantIC), for enhancing information quality towards the sixth-generation (6G) wireless networks. SemantIC only requires the receiver to concatenate the channel decoder with a semantic auto-encoder. This constructs a turbo loop which iteratively and alternately eliminates noise in the signal domain and the semantic domain. From the viewpoint of network information theory, the neural network of the semantic auto-encoder stores side information by training, and provides side information in iterative decoding, as an implementation of the Wyner-Ziv theorem. Simulation results verify the performance improvement by SemantIC without extra channel resource cost.
A Goal-Driven Approach to Systems Neuroscience
Nov 05, 2023Humans and animals exhibit a range of interesting behaviors in dynamic environments, and it is unclear how our brains actively reformat this dense sensory information to enable these behaviors. Experimental neuroscience is undergoing a revolution in its ability to record and manipulate hundreds to thousands of neurons while an animal is performing a complex behavior. As these paradigms enable unprecedented access to the brain, a natural question that arises is how to distill these data into interpretable insights about how neural circuits give rise to intelligent behaviors. The classical approach in systems neuroscience has been to ascribe well-defined operations to individual neurons and provide a description of how these operations combine to produce a circuit-level theory of neural computations. While this approach has had some success for small-scale recordings with simple stimuli, designed to probe a particular circuit computation, often times these ultimately lead to disparate descriptions of the same system across stimuli. Perhaps more strikingly, many response profiles of neurons are difficult to succinctly describe in words, suggesting that new approaches are needed in light of these experimental observations. In this thesis, we offer a different definition of interpretability that we show has promise in yielding unified structural and functional models of neural circuits, and describes the evolutionary constraints that give rise to the response properties of the neural population, including those that have previously been difficult to describe individually. We demonstrate the utility of this framework across multiple brain areas and species to study the roles of recurrent processing in the primate ventral visual pathway; mouse visual processing; heterogeneity in rodent medial entorhinal cortex; and facilitating biological learning.
Early detection of inflammatory arthritis to improve referrals using multimodal machine learning from blood testing, semi-structured and unstructured patient records
Nov 03, 2023Early detection of inflammatory arthritis (IA) is critical to efficient and accurate hospital referral triage for timely treatment and preventing the deterioration of the IA disease course, especially under limited healthcare resources. The manual assessment process is the most common approach in practice for the early detection of IA, but it is extremely labor-intensive and inefficient. A large amount of clinical information needs to be assessed for every referral from General Practice (GP) to the hospitals. Machine learning shows great potential in automating repetitive assessment tasks and providing decision support for the early detection of IA. However, most machine learning-based methods for IA detection rely on blood testing results. But in practice, blood testing data is not always available at the point of referrals, so we need methods to leverage multimodal data such as semi-structured and unstructured data for early detection of IA. In this research, we present fusion and ensemble learning-based methods using multimodal data to assist decision-making in the early detection of IA, and a conformal prediction-based method to quantify the uncertainty of the prediction and detect any unreliable predictions. To the best of our knowledge, our study is the first attempt to utilize multimodal data to support the early detection of IA from GP referrals.
$R^3$-NL2GQL: A Hybrid Models Approach for for Accuracy Enhancing and Hallucinations Mitigation
Nov 03, 2023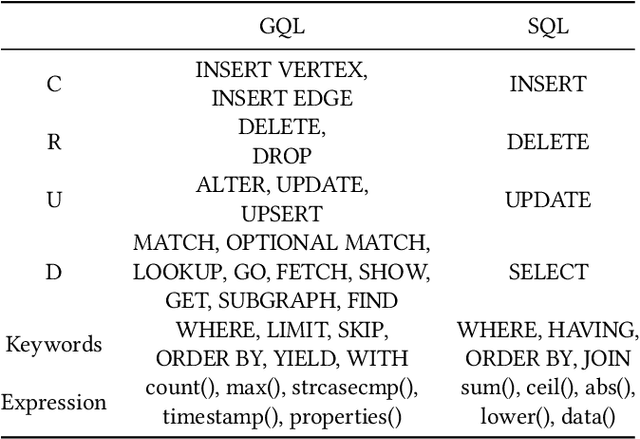
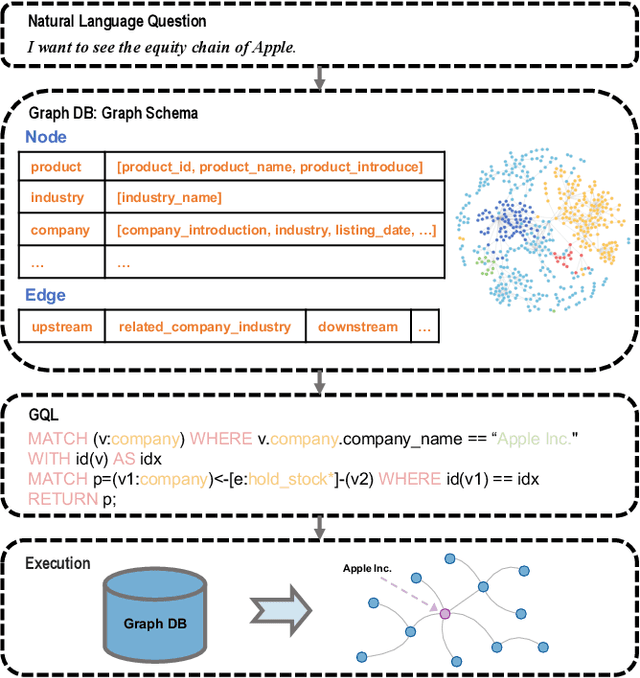
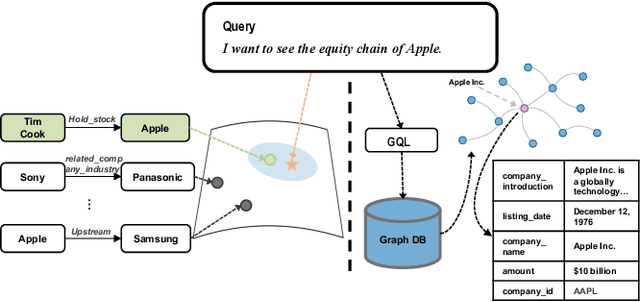
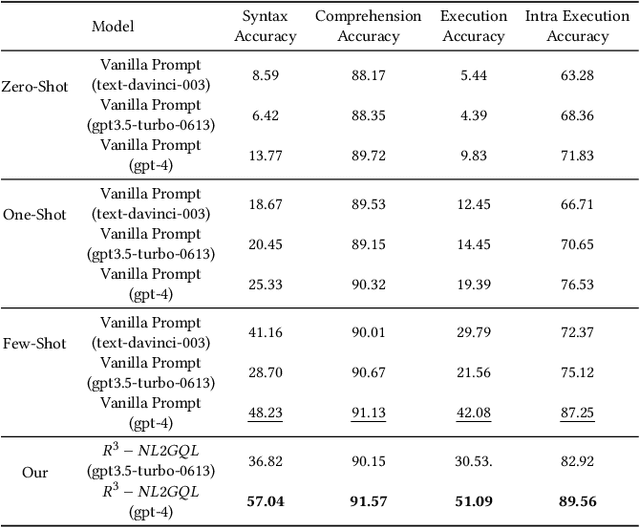
While current NL2SQL tasks constructed using Foundation Models have achieved commendable results, their direct application to Natural Language to Graph Query Language (NL2GQL) tasks poses challenges due to the significant differences between GQL and SQL expressions, as well as the numerous types of GQL. Our extensive experiments reveal that in NL2GQL tasks, larger Foundation Models demonstrate superior cross-schema generalization abilities, while smaller Foundation Models struggle to improve their GQL generation capabilities through fine-tuning. However, after fine-tuning, smaller models exhibit better intent comprehension and higher grammatical accuracy. Diverging from rule-based and slot-filling techniques, we introduce R3-NL2GQL, which employs both smaller and larger Foundation Models as reranker, rewriter and refiner. The approach harnesses the comprehension ability of smaller models for information reranker and rewriter, and the exceptional generalization and generation capabilities of larger models to transform input natural language queries and code structure schema into any form of GQLs. Recognizing the lack of established datasets in this nascent domain, we have created a bilingual dataset derived from graph database documentation and some open-source Knowledge Graphs (KGs). We tested our approach on this dataset and the experimental results showed that delivers promising performance and robustness.Our code and dataset is available at https://github.com/zhiqix/NL2GQL
Constructing Temporal Dynamic Knowledge Graphs from Interactive Text-based Games
Nov 03, 2023In natural language processing, interactive text-based games serve as a test bed for interactive AI systems. Prior work has proposed to play text-based games by acting based on discrete knowledge graphs constructed by the Discrete Graph Updater (DGU) to represent the game state from the natural language description. While DGU has shown promising results with high interpretability, it suffers from lower knowledge graph accuracy due to its lack of temporality and limited generalizability to complex environments with objects with the same label. In order to address DGU's weaknesses while preserving its high interpretability, we propose the Temporal Discrete Graph Updater (TDGU), a novel neural network model that represents dynamic knowledge graphs as a sequence of timestamped graph events and models them using a temporal point based graph neural network. Through experiments on the dataset collected from a text-based game TextWorld, we show that TDGU outperforms the baseline DGU. We further show the importance of temporal information for TDGU's performance through an ablation study and demonstrate that TDGU has the ability to generalize to more complex environments with objects with the same label. All the relevant code can be found at \url{https://github.com/yukw777/temporal-discrete-graph-updater}.
ProSG: Using Prompt Synthetic Gradients to Alleviate Prompt Forgetting of RNN-like Language Models
Nov 03, 2023RNN-like language models are getting renewed attention from NLP researchers in recent years and several models have made significant progress, which demonstrates performance comparable to traditional transformers. However, due to the recurrent nature of RNNs, this kind of language model can only store information in a set of fixed-length state vectors. As a consequence, they still suffer from forgetfulness though after a lot of improvements and optimizations, when given complex instructions or prompts. As the prompted generation is the main and most concerned function of LMs, solving the problem of forgetting in the process of generation is no wonder of vital importance. In this paper, focusing on easing the prompt forgetting during generation, we proposed an architecture to teach the model memorizing prompt during generation by synthetic gradient. To force the model to memorize the prompt, we derive the states that encode the prompt, then transform it into model parameter modification using low-rank gradient approximation, which hard-codes the prompt into model parameters temporarily. We construct a dataset for experiments, and the results have demonstrated the effectiveness of our method in solving the problem of forgetfulness in the process of prompted generation. We will release all the code upon acceptance.
Bayesian Quantile Regression with Subset Selection: A Posterior Summarization Perspective
Nov 03, 2023Quantile regression is a powerful tool for inferring how covariates affect specific percentiles of the response distribution. Existing methods either estimate conditional quantiles separately for each quantile of interest or estimate the entire conditional distribution using semi- or non-parametric models. The former often produce inadequate models for real data and do not share information across quantiles, while the latter are characterized by complex and constrained models that can be difficult to interpret and computationally inefficient. Further, neither approach is well-suited for quantile-specific subset selection. Instead, we pose the fundamental problems of linear quantile estimation, uncertainty quantification, and subset selection from a Bayesian decision analysis perspective. For any Bayesian regression model, we derive optimal and interpretable linear estimates and uncertainty quantification for each model-based conditional quantile. Our approach introduces a quantile-focused squared error loss, which enables efficient, closed-form computing and maintains a close relationship with Wasserstein-based density estimation. In an extensive simulation study, our methods demonstrate substantial gains in quantile estimation accuracy, variable selection, and inference over frequentist and Bayesian competitors. We apply these tools to identify the quantile-specific impacts of social and environmental stressors on educational outcomes for a large cohort of children in North Carolina.
Cross-modal Prominent Fragments Enhancement Aligning Network for Image-text Retrieval
Nov 03, 2023Image-text retrieval is a widely studied topic in the field of computer vision due to the exponential growth of multimedia data, whose core concept is to measure the similarity between images and text. However, most existing retrieval methods heavily rely on cross-attention mechanisms for cross-modal fine-grained alignment, which takes into account excessive irrelevant regions and treats prominent and non-significant words equally, thereby limiting retrieval accuracy. This paper aims to investigate an alignment approach that reduces the involvement of non-significant fragments in images and text while enhancing the alignment of prominent segments. For this purpose, we introduce the Cross-Modal Prominent Fragments Enhancement Aligning Network(CPFEAN), which achieves improved retrieval accuracy by diminishing the participation of irrelevant regions during alignment and relatively increasing the alignment similarity of prominent words. Additionally, we incorporate prior textual information into image regions to reduce misalignment occurrences. In practice, we first design a novel intra-modal fragments relationship reasoning method, and subsequently employ our proposed alignment mechanism to compute the similarity between images and text. Extensive quantitative comparative experiments on MS-COCO and Flickr30K datasets demonstrate that our approach outperforms state-of-the-art methods by about 5% to 10% in the rSum metric.