 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MACP: Efficient Model Adaptation for Cooperative Perception
Nov 07, 2023
Vehicle-to-vehicle (V2V) communications have greatly enhanced the perception capabilities of connected and automated vehicles (CAVs) by enabling information sharing to "see through the occlusions", resulting in significant performance improvements. However, developing and training complex multi-agent perception models from scratch can be expensive and unnecessary when existing single-agent models show remarkable generalization capabilities. In this paper, we propose a new framework termed MACP, which equips a single-agent pre-trained model with cooperation capabilities. We approach this objective by identifying the key challenges of shifting from single-agent to cooperative settings, adapting the model by freezing most of its parameters and adding a few lightweight modules. We demonstrate in our experiments that the proposed framework can effectively utilize cooperative observations and outperform other state-of-the-art approaches in both simulated and real-world cooperative perception benchmarks while requiring substantially fewer tunable parameters with reduced communication costs. Our source code is available at https://github.com/PurdueDigitalTwin/MACP.
The Music Meta Ontology: a flexible semantic model for the interoperability of music metadata
Nov 07, 2023The semantic description of music metadata is a key requirement for the creation of music datasets that can be aligned, integrated, and accessed for information retrieval and knowledge discovery. It is nonetheless an open challenge due to the complexity of musical concepts arising from different genres, styles, and periods -- standing to benefit from a lingua franca to accommodate various stakeholders (musicologists, librarians, data engineers, etc.). To initiate this transition, we introduce the Music Meta ontology, a rich and flexible semantic model to describe music metadata related to artists, compositions, performances, recordings, and links. We follow eXtreme Design methodologies and best practices for data engineering, to reflect the perspectives and the requirements of various stakeholders into the design of the model, while leveraging ontology design patterns and accounting for provenance at different levels (claims, links). After presenting the main features of Music Meta, we provide a first evaluation of the model, alignments to other schema (Music Ontology, DOREMUS, Wikidata), and support for data transformation.
Towards Autonomous Crop Monitoring: Inserting Sensors in Cluttered Environments
Nov 07, 2023We present a contact-based phenotyping robot platform that can autonomously insert nitrate sensors into cornstalks to proactively monitor macronutrient levels in crops. This task is challenging because inserting such sensors requires sub-centimeter precision in an environment which contains high levels of clutter, lighting variation, and occlusion. To address these challenges, we develop a robust perception-action pipeline to detect and grasp stalks, and create a custom robot gripper which mechanically aligns the sensor before inserting it into the stalk. Through experimental validation on 48 unique stalks in a cornfield in Iowa, we demonstrate our platform's capability of detecting a stalk with 94% success, grasping a stalk with 90% success, and inserting a sensor with 60% success. In addition to developing an autonomous phenotyping research platform, we share key challenges and insights obtained from deployment in the field. Our research platform is open-sourced, with additional information available at https://kantor-lab.github.io/cornbot.
Aspect-based Meeting Transcript Summarization: A Two-Stage Approach with Weak Supervision on Sentence Classification
Nov 07, 2023Aspect-based meeting transcript summarization aims to produce multiple summaries, each focusing on one aspect of content in a meeting transcript. It is challenging as sentences related to different aspects can mingle together, and those relevant to a specific aspect can be scattered throughout the long transcript of a meeting. The traditional summarization methods produce one summary mixing information of all aspects, which cannot deal with the above challenges of aspect-based meeting transcript summarization. In this paper, we propose a two-stage method for aspect-based meeting transcript summarization. To select the input content related to specific aspects, we train a sentence classifier on a dataset constructed from the AMI corpus with pseudo-labeling. Then we merge the sentences selected for a specific aspect as the input for the summarizer to produce the aspect-based summary. Experimental results on the AMI corpus outperform many strong baselines, which verifies the effectiveness of our proposed method.
Joint 3D Shape and Motion Estimation from Rolling Shutter Light-Field Images
Nov 02, 2023In this paper, we propose an approach to address the problem of 3D reconstruction of scenes from a single image captured by a light-field camera equipped with a rolling shutter sensor. Our method leverages the 3D information cues present in the light-field and the motion information provided by the rolling shutter effect. We present a generic model for the imaging process of this sensor and a two-stage algorithm that minimizes the re-projection error while considering the position and motion of the camera in a motion-shape bundle adjustment estimation strategy. Thereby, we provide an instantaneous 3D shape-and-pose-and-velocity sensing paradigm. To the best of our knowledge, this is the first study to leverage this type of sensor for this purpose. We also present a new benchmark dataset composed of different light-fields showing rolling shutter effects, which can be used as a common base to improve the evaluation and tracking the progress in the field. We demonstrate the effectiveness and advantages of our approach through several experiments conducted for different scenes and types of motions. The source code and dataset are publicly available at: https://github.com/ICB-Vision-AI/RSLF
Cheating Depth: Enhancing 3D Surface Anomaly Detection via Depth Simulation
Nov 02, 2023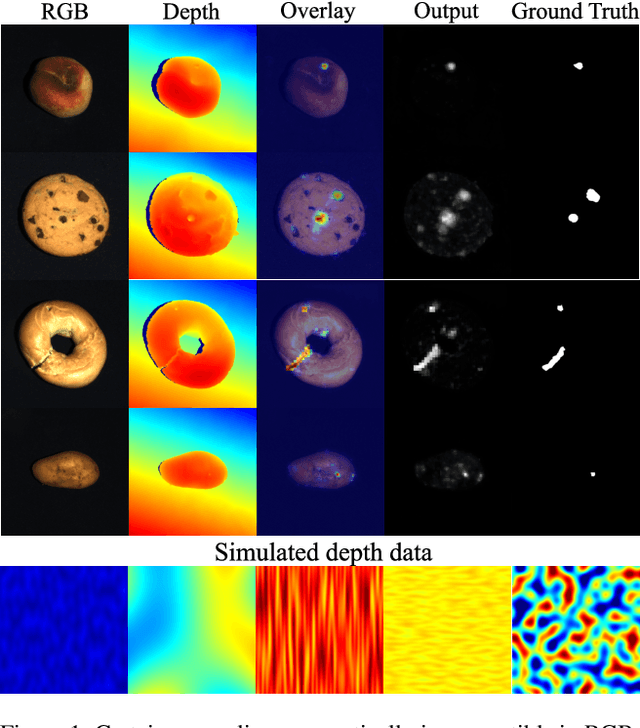
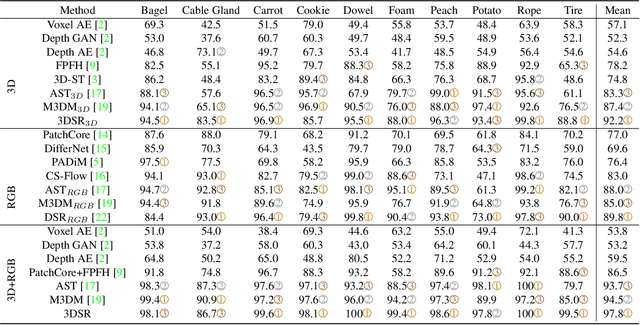
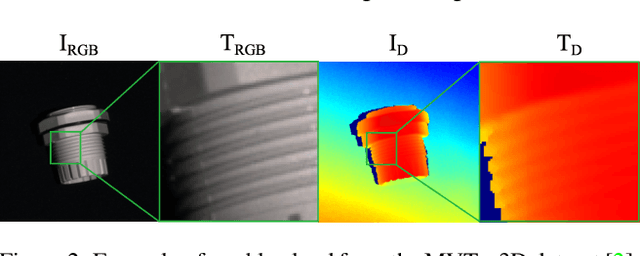
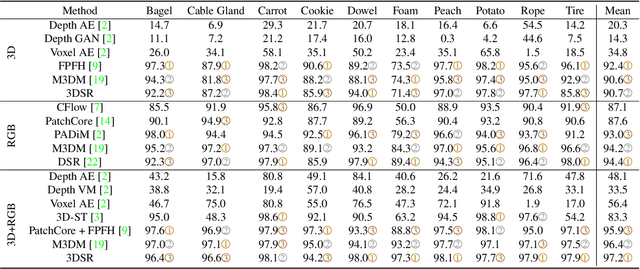
RGB-based surface anomaly detection methods have advanced significantly. However, certain surface anomalies remain practically invisible in RGB alone, necessitating the incorporation of 3D information. Existing approaches that employ point-cloud backbones suffer from suboptimal representations and reduced applicability due to slow processing. Re-training RGB backbones, designed for faster dense input processing, on industrial depth datasets is hindered by the limited availability of sufficiently large datasets. We make several contributions to address these challenges. (i) We propose a novel Depth-Aware Discrete Autoencoder (DADA) architecture, that enables learning a general discrete latent space that jointly models RGB and 3D data for 3D surface anomaly detection. (ii) We tackle the lack of diverse industrial depth datasets by introducing a simulation process for learning informative depth features in the depth encoder. (iii) We propose a new surface anomaly detection method 3DSR, which outperforms all existing state-of-the-art on the challenging MVTec3D anomaly detection benchmark, both in terms of accuracy and processing speed. The experimental results validate the effectiveness and efficiency of our approach, highlighting the potential of utilizing depth information for improved surface anomaly detection.
Contextual Stochastic Bilevel Optimization
Oct 27, 2023We introduce contextual stochastic bilevel optimization (CSBO) -- a stochastic bilevel optimization framework with the lower-level problem minimizing an expectation conditioned on some contextual information and the upper-level decision variable. This framework extends classical stochastic bilevel optimization when the lower-level decision maker responds optimally not only to the decision of the upper-level decision maker but also to some side information and when there are multiple or even infinite many followers. It captures important applications such as meta-learning, personalized federated learning, end-to-end learning, and Wasserstein distributionally robust optimization with side information (WDRO-SI). Due to the presence of contextual information, existing single-loop methods for classical stochastic bilevel optimization are unable to converge. To overcome this challenge, we introduce an efficient double-loop gradient method based on the Multilevel Monte-Carlo (MLMC) technique and establish its sample and computational complexities. When specialized to stochastic nonconvex optimization, our method matches existing lower bounds. For meta-learning, the complexity of our method does not depend on the number of tasks. Numerical experiments further validate our theoretical results.
Reboost Large Language Model-based Text-to-SQL, Text-to-Python, and Text-to-Function -- with Real Applications in Traffic Domain
Oct 31, 2023The previous state-of-the-art (SOTA) method achieved a remarkable execution accuracy on the Spider dataset, which is one of the largest and most diverse datasets in the Text-to-SQL domain. However, during our reproduction of the business dataset, we observed a significant drop in performance. We examined the differences in dataset complexity, as well as the clarity of questions' intentions, and assessed how those differences could impact the performance of prompting methods. Subsequently, We develop a more adaptable and more general prompting method, involving mainly query rewriting and SQL boosting, which respectively transform vague information into exact and precise information and enhance the SQL itself by incorporating execution feedback and the query results from the database content. In order to prevent information gaps, we include the comments, value types, and value samples for columns as part of the database description in the prompt. Our experiments with Large Language Models (LLMs) illustrate the significant performance improvement on the business dataset and prove the substantial potential of our method. In terms of execution accuracy on the business dataset, the SOTA method scored 21.05, while our approach scored 65.79. As a result, our approach achieved a notable performance improvement even when using a less capable pre-trained language model. Last but not least, we also explore the Text-to-Python and Text-to-Function options, and we deeply analyze the pros and cons among them, offering valuable insights to the community.
DIVKNOWQA: Assessing the Reasoning Ability of LLMs via Open-Domain Question Answering over Knowledge Base and Text
Oct 31, 2023Large Language Models (LLMs) have exhibited impressive generation capabilities, but they suffer from hallucinations when solely relying on their internal knowledge, especially when answering questions that require less commonly known information. Retrieval-augmented LLMs have emerged as a potential solution to ground LLMs in external knowledge. Nonetheless, recent approaches have primarily emphasized retrieval from unstructured text corpora, owing to its seamless integration into prompts. When using structured data such as knowledge graphs, most methods simplify it into natural text, neglecting the underlying structures. Moreover, a significant gap in the current landscape is the absence of a realistic benchmark for evaluating the effectiveness of grounding LLMs on heterogeneous knowledge sources (e.g., knowledge base and text). To fill this gap, we have curated a comprehensive dataset that poses two unique challenges: (1) Two-hop multi-source questions that require retrieving information from both open-domain structured and unstructured knowledge sources; retrieving information from structured knowledge sources is a critical component in correctly answering the questions. (2) The generation of symbolic queries (e.g., SPARQL for Wikidata) is a key requirement, which adds another layer of challenge. Our dataset is created using a combination of automatic generation through predefined reasoning chains and human annotation. We also introduce a novel approach that leverages multiple retrieval tools, including text passage retrieval and symbolic language-assisted retrieval. Our model outperforms previous approaches by a significant margin, demonstrating its effectiveness in addressing the above-mentioned reasoning challenges.
Improving Input-label Mapping with Demonstration Replay for In-context Learning
Oct 30, 2023In-context learning (ICL) is an emerging capability of large autoregressive language models where a few input-label demonstrations are appended to the input to enhance the model's understanding of downstream NLP tasks, without directly adjusting the model parameters. The effectiveness of ICL can be attributed to the strong language modeling capabilities of large language models (LLMs), which enable them to learn the mapping between input and labels based on in-context demonstrations. Despite achieving promising results, the causal nature of language modeling in ICL restricts the attention to be backward only, i.e., a token only attends to its previous tokens, failing to capture the full input-label information and limiting the model's performance. In this paper, we propose a novel ICL method called Repeated Demonstration with Sliding Causal Attention, (RdSca). Specifically, we duplicate later demonstrations and concatenate them to the front, allowing the model to `observe' the later information even under the causal restriction. Besides, we introduce sliding causal attention, which customizes causal attention to avoid information leakage. Experimental results show that our method significantly improves the input-label mapping in ICL demonstrations. We also conduct an in-depth analysis of how to customize the causal attention without training, which has been an unexplored area in previous research.