 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Construction Artifacts in Metaphor Identification Datasets
Nov 01, 2023
Metaphor identification aims at understanding whether a given expression is used figuratively in context. However, in this paper we show how existing metaphor identification datasets can be gamed by fully ignoring the potential metaphorical expression or the context in which it occurs. We test this hypothesis in a variety of datasets and settings, and show that metaphor identification systems based on language models without complete information can be competitive with those using the full context. This is due to the construction procedures to build such datasets, which introduce unwanted biases for positive and negative classes. Finally, we test the same hypothesis on datasets that are carefully sampled from natural corpora and where this bias is not present, making these datasets more challenging and reliable.
Episodic Multi-Task Learning with Heterogeneous Neural Processes
Oct 28, 2023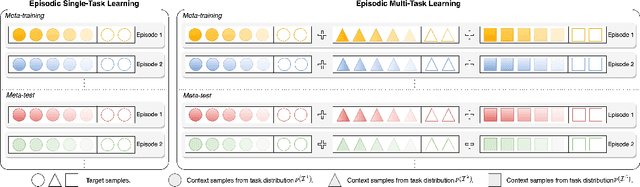
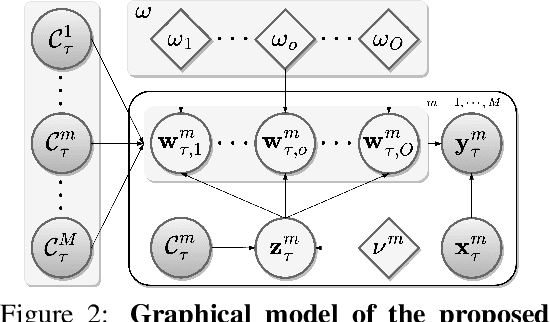
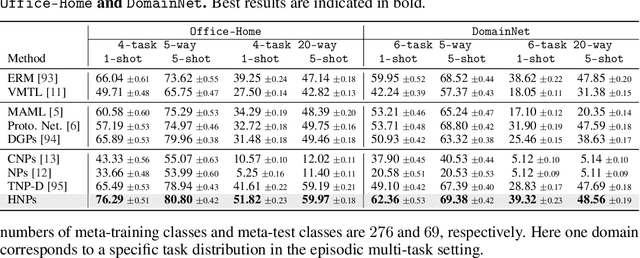
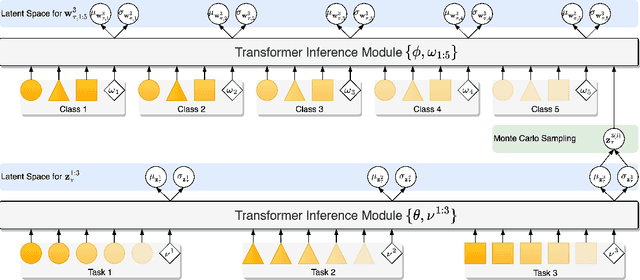
This paper focuses on the data-insufficiency problem in multi-task learning within an episodic training setup. Specifically, we explore the potential of heterogeneous information across tasks and meta-knowledge among episodes to effectively tackle each task with limited data. Existing meta-learning methods often fail to take advantage of crucial heterogeneous information in a single episode, while multi-task learning models neglect reusing experience from earlier episodes. To address the problem of insufficient data, we develop Heterogeneous Neural Processes (HNPs) for the episodic multi-task setup. Within the framework of hierarchical Bayes, HNPs effectively capitalize on prior experiences as meta-knowledge and capture task-relatedness among heterogeneous tasks, mitigating data-insufficiency. Meanwhile, transformer-structured inference modules are designed to enable efficient inferences toward meta-knowledge and task-relatedness. In this way, HNPs can learn more powerful functional priors for adapting to novel heterogeneous tasks in each meta-test episode. Experimental results show the superior performance of the proposed HNPs over typical baselines, and ablation studies verify the effectiveness of the designed inference modules.
Multitask Online Learning: Listen to the Neighborhood Buzz
Oct 26, 2023We study multitask online learning in a setting where agents can only exchange information with their neighbors on an arbitrary communication network. We introduce $\texttt{MT-CO}_2\texttt{OL}$, a decentralized algorithm for this setting whose regret depends on the interplay between the task similarities and the network structure. Our analysis shows that the regret of $\texttt{MT-CO}_2\texttt{OL}$ is never worse (up to constants) than the bound obtained when agents do not share information. On the other hand, our bounds significantly improve when neighboring agents operate on similar tasks. In addition, we prove that our algorithm can be made differentially private with a negligible impact on the regret when the losses are linear. Finally, we provide experimental support for our theory.
3D Masked Autoencoders for Enhanced Privacy in MRI Scans
Oct 24, 2023MRI scans provide valuable medical information, however they also contain sensitive and personally identifiable information (PII) that needs to be protected. Whereas MRI metadata is easily sanitized, MRI image data is a privacy risk because it contains information to render highly-realistic 3D visualizations of a patient's head, enabling malicious actors to possibly identify the subject by cross-referencing a database. Data anonymization and de-identification is concerned with ensuring the privacy and confidentiality of individuals' personal information. Traditional MRI de-identification methods remove privacy-sensitive parts (e.g. eyes, nose etc.) from a given scan. This comes at the expense of introducing a domain shift that can throw off downstream analyses. Recently, a GAN-based approach was proposed to de-identify a patient's scan by remodeling it (e.g. changing the face) rather than by removing parts. In this work, we propose CP-MAE, a model that de-identifies the face using masked autoencoders and that outperforms all previous approaches in terms of downstream task performance as well as de-identification. With our method we are able to synthesize scans of resolution up to $256^3$ (previously 128 cubic) which constitutes an eight-fold increase in the number of voxels. Using our construction we were able to design a system that exhibits a highly robust training stage, making it easy to fit the network on novel data.
GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling
Nov 03, 2023Linear Recurrence has proven to be a powerful tool for modeling long sequences efficiently. In this work, we show that existing models fail to take full advantage of its potential. Motivated by this finding, we develop GateLoop, a foundational sequence model that generalizes linear recurrent models such as S4, S5, LRU and RetNet, by employing data-controlled state transitions. Utilizing this theoretical advance, GateLoop empirically outperforms existing models for auto-regressive language modeling. Our method comes with a low-cost $O(l)$ recurrent mode and an efficient $O(l \log_{2} l)$ parallel mode making use of highly optimized associative scan implementations. Furthermore, we derive an $O(l^2)$ surrogate attention mode, revealing remarkable implications for Transformer and recently proposed architectures. Specifically, we prove that our approach can be interpreted as providing data-controlled relative-positional information to Attention. While many existing models solely rely on data-controlled cumulative sums for context aggregation, our findings suggest that incorporating data-controlled complex cumulative products may be a crucial step towards more powerful sequence models.
Spectral Clustering of Attributed Multi-relational Graphs
Nov 03, 2023Graph clustering aims at discovering a natural grouping of the nodes such that similar nodes are assigned to a common cluster. Many different algorithms have been proposed in the literature: for simple graphs, for graphs with attributes associated to nodes, and for graphs where edges represent different types of relations among nodes. However, complex data in many domains can be represented as both attributed and multi-relational networks. In this paper, we propose SpectralMix, a joint dimensionality reduction technique for multi-relational graphs with categorical node attributes. SpectralMix integrates all information available from the attributes, the different types of relations, and the graph structure to enable a sound interpretation of the clustering results. Moreover, it generalizes existing techniques: it reduces to spectral embedding and clustering when only applied to a single graph and to homogeneity analysis when applied to categorical data. Experiments conducted on several real-world datasets enable us to detect dependencies between graph structure and categorical attributes, moreover, they exhibit the superiority of SpectralMix over existing methods.
Universal Multi-modal Multi-domain Pre-trained Recommendation
Nov 03, 2023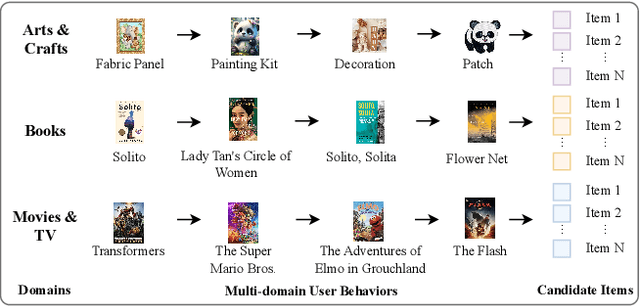
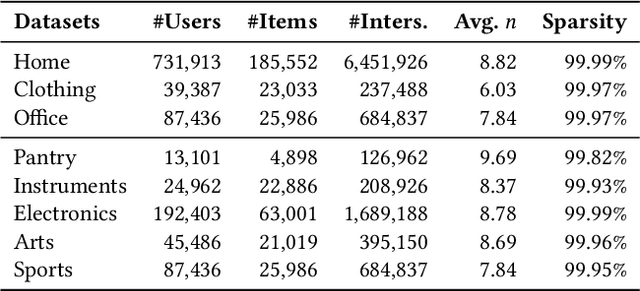
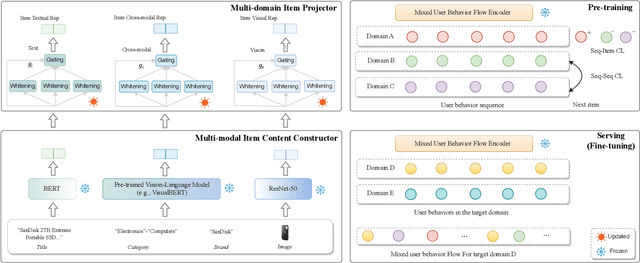
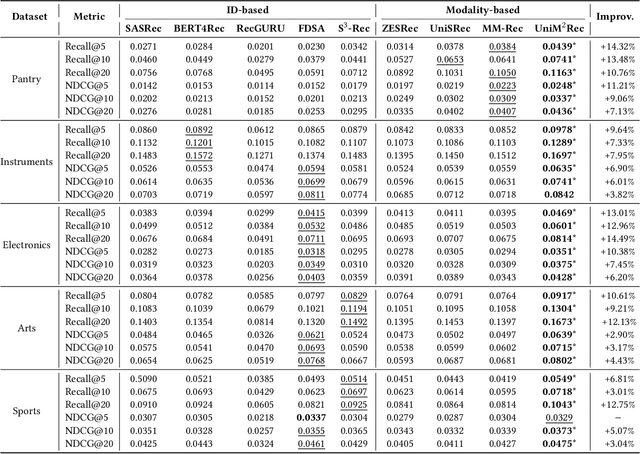
There is a rapidly-growing research interest in modeling user preferences via pre-training multi-domain interactions for recommender systems. However, Existing pre-trained multi-domain recommendations mostly select the item texts to be bridges across domains, and simply explore the user behaviors in target domains. Hence, they ignore other informative multi-modal item contents (e.g., visual information), and also lack of thorough consideration of user behaviors from all interactive domains. To address these issues, in this paper, we propose to pre-train universal multi-modal item content presentation for multi-domain recommendation, called UniM^2Rec, which could smoothly learn the multi-modal item content presentations and the multi-modal user preferences from all domains. With the pre-trained multi-domain recommendation model, UniM^2Rec could be efficiently and effectively transferred to new target domains in practice. Extensive experiments conducted on five real-world datasets in target domains demonstrate the superiority of the proposed method over existing competitive methods, especially for the real-world recommendation scenarios that usually struggle with seriously missing or noisy item contents.
Adaptive Assistance with an Active and Soft Back-Support Exosuit to Unknown External Loads via Model-Based Estimates of Internal Lumbosacral Moments
Nov 03, 2023State of the art controllers for back exoskeletons largely rely on body kinematics. This results in control strategies which cannot provide adaptive support under unknown external loads. We developed a neuromechanical model-based controller (NMBC) for a soft back exosuit, wherein assistive forces were proportional to the active component of lumbosacral joint moments, derived from real-time electromyography-driven models. The exosuit provided adaptive assistance forces with no a priori information on the external loading conditions. Across 10 participants, who stoop-lifted 5 and 15 kg boxes, our NMBC was compared to a non-adaptive virtual spring-based control(VSBC), in which exosuit forces were proportional to trunk inclination. Peak cable assistive forces were modulated across weight conditions for NMBC (5kg: 2.13 N/kg; 15kg: 2.82 N/kg) but not for VSBC (5kg: 1.92 N/kg; 15kg: 2.00 N/kg). The proposed NMBC strategy resulted in larger reduction of cumulative compression forces for 5 kg (NMBC: 18.2%; VSBC: 10.7%) and 15 kg conditions (NMBC: 21.3%; VSBC: 10.2%). Our proposed methodology may facilitate the adoption of non-hindering wearable robotics in real-life scenarios.
Taking a PEEK into YOLOv5 for Satellite Component Recognition via Entropy-based Visual Explanations
Nov 03, 2023The escalating risk of collisions and the accumulation of space debris in Low Earth Orbit (LEO) has reached critical concern due to the ever increasing number of spacecraft. Addressing this crisis, especially in dealing with non-cooperative and unidentified space debris, is of paramount importance. This paper contributes to efforts in enabling autonomous swarms of small chaser satellites for target geometry determination and safe flight trajectory planning for proximity operations in LEO. Our research explores on-orbit use of the You Only Look Once v5 (YOLOv5) object detection model trained to detect satellite components. While this model has shown promise, its inherent lack of interpretability hinders human understanding, a critical aspect of validating algorithms for use in safety-critical missions. To analyze the decision processes, we introduce Probabilistic Explanations for Entropic Knowledge extraction (PEEK), a method that utilizes information theoretic analysis of the latent representations within the hidden layers of the model. Through both synthetic in hardware-in-the-loop experiments, PEEK illuminates the decision-making processes of the model, helping identify its strengths, limitations and biases.
Using DUCK-Net for Polyp Image Segmentation
Nov 03, 2023This paper presents a novel supervised convolutional neural network architecture, "DUCK-Net", capable of effectively learning and generalizing from small amounts of medical images to perform accurate segmentation tasks. Our model utilizes an encoder-decoder structure with a residual downsampling mechanism and a custom convolutional block to capture and process image information at multiple resolutions in the encoder segment. We employ data augmentation techniques to enrich the training set, thus increasing our model's performance. While our architecture is versatile and applicable to various segmentation tasks, in this study, we demonstrate its capabilities specifically for polyp segmentation in colonoscopy images. We evaluate the performance of our method on several popular benchmark datasets for polyp segmentation, Kvasir-SEG, CVC-ClinicDB, CVC-ColonDB, and ETIS-LARIBPOLYPDB showing that it achieves state-of-the-art results in terms of mean Dice coefficient, Jaccard index, Precision, Recall, and Accuracy. Our approach demonstrates strong generalization capabilities, achieving excellent performance even with limited training data. The code is publicly available on GitHub: https://github.com/RazvanDu/DUCK-Net