 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Revealing CNN Architectures via Side-Channel Analysis in Dataflow-based Inference Accelerators
Nov 01, 2023
Convolution Neural Networks (CNNs) are widely used in various domains. Recent advances in dataflow-based CNN accelerators have enabled CNN inference in resource-constrained edge devices. These dataflow accelerators utilize inherent data reuse of convolution layers to process CNN models efficiently. Concealing the architecture of CNN models is critical for privacy and security. This paper evaluates memory-based side-channel information to recover CNN architectures from dataflow-based CNN inference accelerators. The proposed attack exploits spatial and temporal data reuse of the dataflow mapping on CNN accelerators and architectural hints to recover the structure of CNN models. Experimental results demonstrate that our proposed side-channel attack can recover the structures of popular CNN models, namely Lenet, Alexnet, and VGGnet16.
An analysis of large speech models-based representations for speech emotion recognition
Nov 01, 2023Large speech models-derived features have recently shown increased performance over signal-based features across multiple downstream tasks, even when the networks are not finetuned towards the target task. In this paper we show the results of an analysis of several signal- and neural models-derived features for speech emotion recognition. We use pretrained models and explore their inherent potential abstractions of emotions. Simple classification methods are used so as to not interfere or add knowledge to the task. We show that, even without finetuning, some of these large neural speech models' representations can enclose information that enables performances close to, and even beyond state-of-the-art results across six standard speech emotion recognition datasets.
SAGE: Smart home Agent with Grounded Execution
Nov 01, 2023This article introduces SAGE (Smart home Agent with Grounded Execution), a framework designed to maximize the flexibility of smart home assistants by replacing manually-defined inference logic with an LLM-powered autonomous agent system. SAGE integrates information about user preferences, device states, and external factors (such as weather and TV schedules) through the orchestration of a collection of tools. SAGE's capabilities include learning user preferences from natural-language utterances, interacting with devices by reading their API documentation, writing code to continuously monitor devices, and understanding natural device references. To evaluate SAGE, we develop a benchmark of 43 highly challenging smart home tasks, where SAGE successfully achieves 23 tasks, significantly outperforming existing LLM-enabled baselines (5/43).
Neural Distributed Compressor Discovers Binning
Oct 25, 2023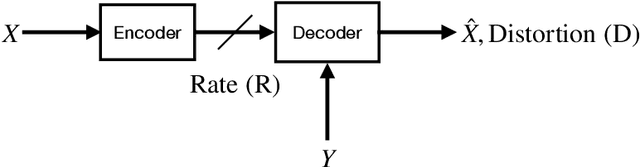
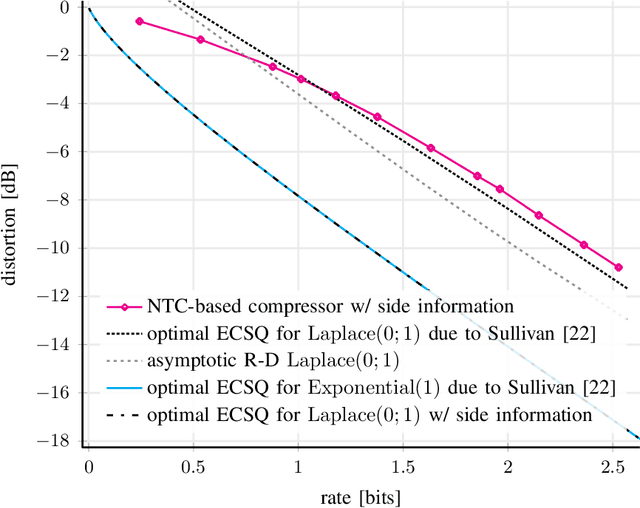
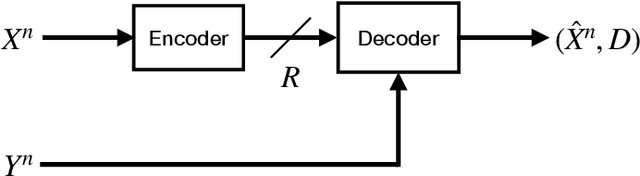
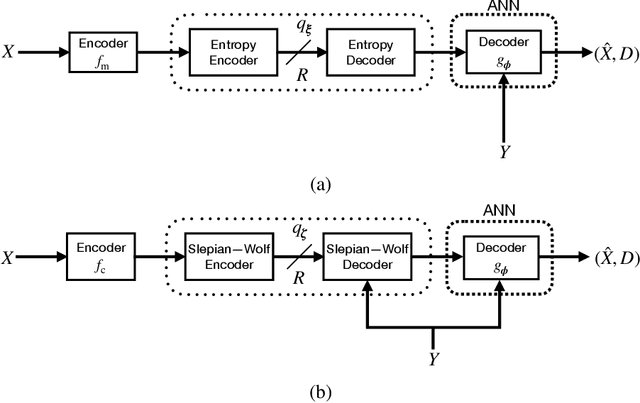
We consider lossy compression of an information source when the decoder has lossless access to a correlated one. This setup, also known as the Wyner-Ziv problem, is a special case of distributed source coding. To this day, practical approaches for the Wyner-Ziv problem have neither been fully developed nor heavily investigated. We propose a data-driven method based on machine learning that leverages the universal function approximation capability of artificial neural networks. We find that our neural network-based compression scheme, based on variational vector quantization, recovers some principles of the optimum theoretical solution of the Wyner-Ziv setup, such as binning in the source space as well as optimal combination of the quantization index and side information, for exemplary sources. These behaviors emerge although no structure exploiting knowledge of the source distributions was imposed. Binning is a widely used tool in information theoretic proofs and methods, and to our knowledge, this is the first time it has been explicitly observed to emerge from data-driven learning.
Non-isotropic Persistent Homology: Leveraging the Metric Dependency of PH
Oct 25, 2023Persistent Homology is a widely used topological data analysis tool that creates a concise description of the topological properties of a point cloud based on a specified filtration. Most filtrations used for persistent homology depend (implicitly) on a chosen metric, which is typically agnostically chosen as the standard Euclidean metric on $\mathbb{R}^n$. Recent work has tried to uncover the 'true' metric on the point cloud using distance-to-measure functions, in order to obtain more meaningful persistent homology results. Here we propose an alternative look at this problem: we posit that information on the point cloud is lost when restricting persistent homology to a single (correct) distance function. Instead, we show how by varying the distance function on the underlying space and analysing the corresponding shifts in the persistence diagrams, we can extract additional topological and geometrical information. Finally, we numerically show that non-isotropic persistent homology can extract information on orientation, orientational variance, and scaling of randomly generated point clouds with good accuracy and conduct some experiments on real-world data.
DP-SGD with weight clipping
Oct 27, 2023Recently, due to the popularity of deep neural networks and other methods whose training typically relies on the optimization of an objective function, and due to concerns for data privacy, there is a lot of interest in differentially private gradient descent methods. To achieve differential privacy guarantees with a minimum amount of noise, it is important to be able to bound precisely the sensitivity of the information which the participants will observe. In this study, we present a novel approach that mitigates the bias arising from traditional gradient clipping. By leveraging public information concerning the current global model and its location within the search domain, we can achieve improved gradient bounds, leading to enhanced sensitivity determinations and refined noise level adjustments. We extend the state of the art algorithms, present improved differential privacy guarantees requiring less noise and present an empirical evaluation.
Distil the informative essence of loop detector data set: Is network-level traffic forecasting hungry for more data?
Oct 31, 2023Network-level traffic condition forecasting has been intensively studied for decades. Although prediction accuracy has been continuously improved with emerging deep learning models and ever-expanding traffic data, traffic forecasting still faces many challenges in practice. These challenges include the robustness of data-driven models, the inherent unpredictability of traffic dynamics, and whether further improvement of traffic forecasting requires more sensor data. In this paper, we focus on this latter question and particularly on data from loop detectors. To answer this, we propose an uncertainty-aware traffic forecasting framework to explore how many samples of loop data are truly effective for training forecasting models. Firstly, the model design combines traffic flow theory with graph neural networks, ensuring the robustness of prediction and uncertainty quantification. Secondly, evidential learning is employed to quantify different sources of uncertainty in a single pass. The estimated uncertainty is used to "distil" the essence of the dataset that sufficiently covers the information content. Results from a case study of a highway network around Amsterdam show that, from 2018 to 2021, more than 80\% of the data during daytime can be removed. The remaining 20\% samples have equal prediction power for training models. This result suggests that indeed large traffic datasets can be subdivided into significantly smaller but equally informative datasets. From these findings, we conclude that the proposed methodology proves valuable in evaluating large traffic datasets' true information content. Further extensions, such as extracting smaller, spatially non-redundant datasets, are possible with this method.
Transformer-based nowcasting of radar composites from satellite images for severe weather
Oct 30, 2023Weather radar data are critical for nowcasting and an integral component of numerical weather prediction models. While weather radar data provide valuable information at high resolution, their ground-based nature limits their availability, which impedes large-scale applications. In contrast, meteorological satellites cover larger domains but with coarser resolution. However, with the rapid advancements in data-driven methodologies and modern sensors aboard geostationary satellites, new opportunities are emerging to bridge the gap between ground- and space-based observations, ultimately leading to more skillful weather prediction with high accuracy. Here, we present a Transformer-based model for nowcasting ground-based radar image sequences using satellite data up to two hours lead time. Trained on a dataset reflecting severe weather conditions, the model predicts radar fields occurring under different weather phenomena and shows robustness against rapidly growing/decaying fields and complex field structures. Model interpretation reveals that the infrared channel centered at 10.3 $\mu m$ (C13) contains skillful information for all weather conditions, while lightning data have the highest relative feature importance in severe weather conditions, particularly in shorter lead times. The model can support precipitation nowcasting across large domains without an explicit need for radar towers, enhance numerical weather prediction and hydrological models, and provide radar proxy for data-scarce regions. Moreover, the open-source framework facilitates progress towards operational data-driven nowcasting.
One-for-All: Bridge the Gap Between Heterogeneous Architectures in Knowledge Distillation
Oct 30, 2023Knowledge distillation~(KD) has proven to be a highly effective approach for enhancing model performance through a teacher-student training scheme. However, most existing distillation methods are designed under the assumption that the teacher and student models belong to the same model family, particularly the hint-based approaches. By using centered kernel alignment (CKA) to compare the learned features between heterogeneous teacher and student models, we observe significant feature divergence. This divergence illustrates the ineffectiveness of previous hint-based methods in cross-architecture distillation. To tackle the challenge in distilling heterogeneous models, we propose a simple yet effective one-for-all KD framework called OFA-KD, which significantly improves the distillation performance between heterogeneous architectures. Specifically, we project intermediate features into an aligned latent space such as the logits space, where architecture-specific information is discarded. Additionally, we introduce an adaptive target enhancement scheme to prevent the student from being disturbed by irrelevant information. Extensive experiments with various architectures, including CNN, Transformer, and MLP, demonstrate the superiority of our OFA-KD framework in enabling distillation between heterogeneous architectures. Specifically, when equipped with our OFA-KD, the student models achieve notable performance improvements, with a maximum gain of 8.0% on the CIFAR-100 dataset and 0.7% on the ImageNet-1K dataset. PyTorch code and checkpoints can be found at https://github.com/Hao840/OFAKD.
Autoregressive Attention Neural Networks for Non-Line-of-Sight User Tracking with Dynamic Metasurface Antennas
Oct 30, 2023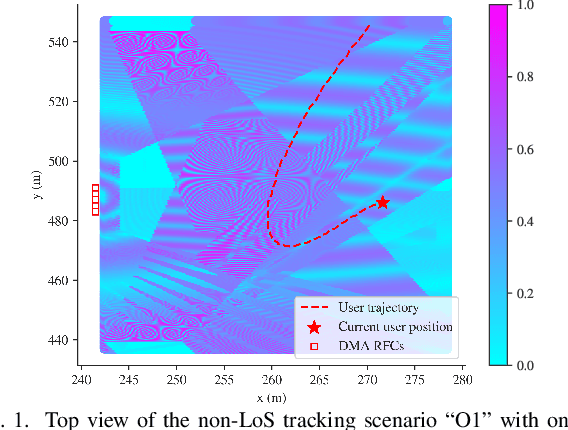
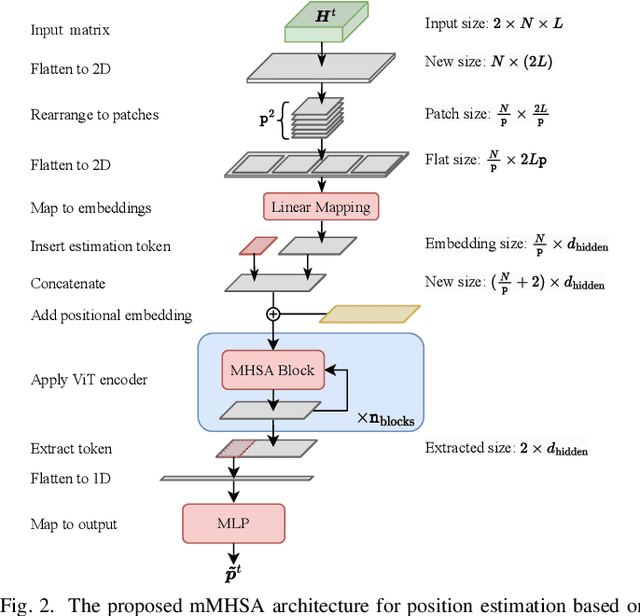
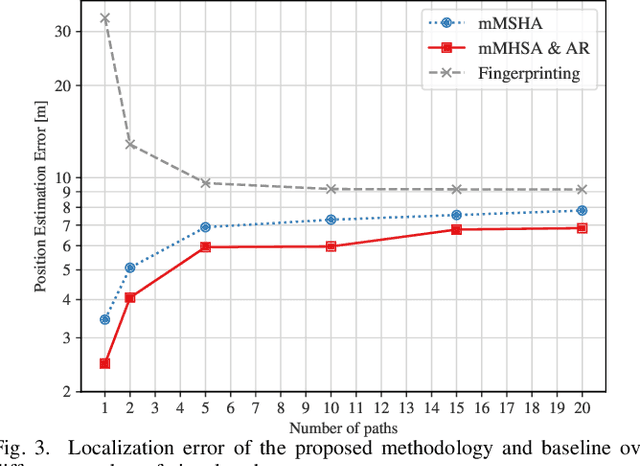
User localization and tracking in the upcoming generation of wireless networks have the potential to be revolutionized by technologies such as the Dynamic Metasurface Antennas (DMAs). Commonly proposed algorithmic approaches rely on assumptions about relatively dominant Line-of-Sight (LoS) paths, or require pilot transmission sequences whose length is comparable to the number of DMA elements, thus, leading to limited effectiveness and considerable measurement overheads in blocked LoS and dynamic multipath environments. In this paper, we present a two-stage machine-learning-based approach for user tracking, specifically designed for non-LoS multipath settings. A newly proposed attention-based Neural Network (NN) is first trained to map noisy channel responses to potential user positions, regardless of user mobility patterns. This architecture constitutes a modification of the prominent vision transformer, specifically modified for extracting information from high-dimensional frequency response signals. As a second stage, the NN's predictions for the past user positions are passed through a learnable autoregressive model to exploit the time-correlated channel information and obtain the final position predictions. The channel estimation procedure leverages a DMA receive architecture with partially-connected radio frequency chains, which results to reduced numbers of pilots. The numerical evaluation over an outdoor ray-tracing scenario illustrates that despite LoS blockage, this methodology is capable of achieving high position accuracy across various multipath settings.