 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Non-parametric Conditional Independence Testing for Mixed Continuous-Categorical Variables: A Novel Method and Numerical Evaluation
Nov 05, 2023
Conditional independence testing (CIT) is a common task in machine learning, e.g., for variable selection, and a main component of constraint-based causal discovery. While most current CIT approaches assume that all variables are numerical or all variables are categorical, many real-world applications involve mixed-type datasets that include numerical and categorical variables. Non-parametric CIT can be conducted using conditional mutual information (CMI) estimators combined with a local permutation scheme. Recently, two novel CMI estimators for mixed-type datasets based on k-nearest-neighbors (k-NN) have been proposed. As with any k-NN method, these estimators rely on the definition of a distance metric. One approach computes distances by a one-hot encoding of the categorical variables, essentially treating categorical variables as discrete-numerical, while the other expresses CMI by entropy terms where the categorical variables appear as conditions only. In this work, we study these estimators and propose a variation of the former approach that does not treat categorical variables as numeric. Our numerical experiments show that our variant detects dependencies more robustly across different data distributions and preprocessing types.
Ego-Network Transformer for Subsequence Classification in Time Series Data
Nov 05, 2023


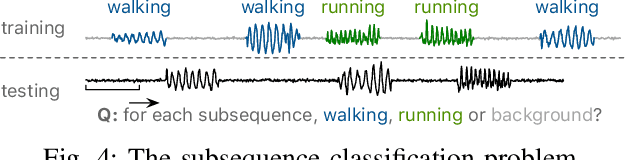
Time series classification is a widely studied problem in the field of time series data mining. Previous research has predominantly focused on scenarios where relevant or foreground subsequences have already been extracted, with each subsequence corresponding to a single label. However, real-world time series data often contain foreground subsequences that are intertwined with background subsequences. Successfully classifying these relevant subsequences requires not only distinguishing between different classes but also accurately identifying the foreground subsequences amidst the background. To address this challenge, we propose a novel subsequence classification method that represents each subsequence as an ego-network, providing crucial nearest neighbor information to the model. The ego-networks of all subsequences collectively form a time series subsequence graph, and we introduce an algorithm to efficiently construct this graph. Furthermore, we have demonstrated the significance of enforcing temporal consistency in the prediction of adjacent subsequences for the subsequence classification problem. To evaluate the effectiveness of our approach, we conducted experiments using 128 univariate and 30 multivariate time series datasets. The experimental results demonstrate the superior performance of our method compared to alternative approaches. Specifically, our method outperforms the baseline on 104 out of 158 datasets.
Enhancing AI Research Paper Analysis: Methodology Component Extraction using Factored Transformer-based Sequence Modeling Approach
Nov 05, 2023Research in scientific disciplines evolves, often rapidly, over time with the emergence of novel methodologies and their associated terminologies. While methodologies themselves being conceptual in nature and rather difficult to automatically extract and characterise, in this paper, we seek to develop supervised models for automatic extraction of the names of the various constituents of a methodology, e.g., `R-CNN', `ELMo' etc. The main research challenge for this task is effectively modeling the contexts around these methodology component names in a few-shot or even a zero-shot setting. The main contributions of this paper towards effectively identifying new evolving scientific methodology names are as follows: i) we propose a factored approach to sequence modeling, which leverages a broad-level category information of methodology domains, e.g., `NLP', `RL' etc.; ii) to demonstrate the feasibility of our proposed approach of identifying methodology component names under a practical setting of fast evolving AI literature, we conduct experiments following a simulated chronological setup (newer methodologies not seen during the training process); iii) our experiments demonstrate that the factored approach outperforms state-of-the-art baselines by margins of up to 9.257\% for the methodology extraction task with the few-shot setup.
Diversified Node Sampling based Hierarchical Transformer Pooling for Graph Representation Learning
Oct 31, 2023Graph pooling methods have been widely used on downsampling graphs, achieving impressive results on multiple graph-level tasks like graph classification and graph generation. An important line called node dropping pooling aims at exploiting learnable scoring functions to drop nodes with comparatively lower significance scores. However, existing node dropping methods suffer from two limitations: (1) for each pooled node, these models struggle to capture long-range dependencies since they mainly take GNNs as the backbones; (2) pooling only the highest-scoring nodes tends to preserve similar nodes, thus discarding the affluent information of low-scoring nodes. To address these issues, we propose a Graph Transformer Pooling method termed GTPool, which introduces Transformer to node dropping pooling to efficiently capture long-range pairwise interactions and meanwhile sample nodes diversely. Specifically, we design a scoring module based on the self-attention mechanism that takes both global context and local context into consideration, measuring the importance of nodes more comprehensively. GTPool further utilizes a diversified sampling method named Roulette Wheel Sampling (RWS) that is able to flexibly preserve nodes across different scoring intervals instead of only higher scoring nodes. In this way, GTPool could effectively obtain long-range information and select more representative nodes. Extensive experiments on 11 benchmark datasets demonstrate the superiority of GTPool over existing popular graph pooling methods.
Leveraging point annotations in segmentation learning with boundary loss
Nov 06, 2023This paper investigates the combination of intensity-based distance maps with boundary loss for point-supervised semantic segmentation. By design the boundary loss imposes a stronger penalty on the false positives the farther away from the object they occur. Hence it is intuitively inappropriate for weak supervision, where the ground truth label may be much smaller than the actual object and a certain amount of false positives (w.r.t. the weak ground truth) is actually desirable. Using intensity-aware distances instead may alleviate this drawback, allowing for a certain amount of false positives without a significant increase to the training loss. The motivation for applying the boundary loss directly under weak supervision lies in its great success for fully supervised segmentation tasks, but also in not requiring extra priors or outside information that is usually required -- in some form -- with existing weakly supervised methods in the literature. This formulation also remains potentially more attractive than existing CRF-based regularizers, due to its simplicity and computational efficiency. We perform experiments on two multi-class datasets; ACDC (heart segmentation) and POEM (whole-body abdominal organ segmentation). Preliminary results are encouraging and show that this supervision strategy has great potential. On ACDC it outperforms the CRF-loss based approach, and on POEM data it performs on par with it. The code for all our experiments is openly available.
Reboost Large Language Model-based Text-to-SQL, Text-to-Python, and Text-to-Function -- with Real Applications in Traffic Domain
Oct 28, 2023Previous state-of-the-art (SOTA) method achieved a remarkable execution accuracy on the Spider dataset, which is one of the largest and most diverse datasets in the Text-to-SQL domain. However, during our reproduce of the business dataset, we observed a significant drop in performance. We examined the differences in dataset complexity, as well as the clarity of questions' intentions, and assessed how those differences could impact the performance of prompting methods. Subsequently, We develop a more adaptable and more general prompting method, involving mainly query rewriting and SQL boosting, which respectively transform vague information into exact and precise information and enhance the SQL itself by incorporating execution feedback and the query results from the database content. In order to prevent information gaps, we include the comments, value types, and value samples for columns as part of the database description in the prompt. Our experiments with Large Language Models (LLMs) illustrate the significant performance improvement on the business dataset and prove the substantial potential of our method. In terms of execution accuracy on the business dataset, the SOTA method scored 21.05, while our approach scored 65.79. As a result, our approach achieved a notable performance improvement even when using a less capable pre-trained language model. Last but not the least, we also explore the Text-to-Python and Text-to-Function options, and we deeply analyze the pros and cons among them, offering valuable insights to the community.
Mitigating Framing Bias with Polarity Minimization Loss
Nov 03, 2023Framing bias plays a significant role in exacerbating political polarization by distorting the perception of actual events. Media outlets with divergent political stances often use polarized language in their reporting of the same event. We propose a new loss function that encourages the model to minimize the polarity difference between the polarized input articles to reduce framing bias. Specifically, our loss is designed to jointly optimize the model to map polarity ends bidirectionally. Our experimental results demonstrate that incorporating the proposed polarity minimization loss leads to a substantial reduction in framing bias when compared to a BART-based multi-document summarization model. Notably, we find that the effectiveness of this approach is most pronounced when the model is trained to minimize the polarity loss associated with informational framing bias (i.e., skewed selection of information to report).
MISFIT-V: Misaligned Image Synthesis and Fusion using Information from Thermal and Visual
Sep 22, 2023Detecting humans from airborne visual and thermal imagery is a fundamental challenge for Wilderness Search-and-Rescue (WiSAR) teams, who must perform this function accurately in the face of immense pressure. The ability to fuse these two sensor modalities can potentially reduce the cognitive load on human operators and/or improve the effectiveness of computer vision object detection models. However, the fusion task is particularly challenging in the context of WiSAR due to hardware limitations and extreme environmental factors. This work presents Misaligned Image Synthesis and Fusion using Information from Thermal and Visual (MISFIT-V), a novel two-pronged unsupervised deep learning approach that utilizes a Generative Adversarial Network (GAN) and a cross-attention mechanism to capture the most relevant features from each modality. Experimental results show MISFIT-V offers enhanced robustness against misalignment and poor lighting/thermal environmental conditions compared to existing visual-thermal image fusion methods.
RegaVAE: A Retrieval-Augmented Gaussian Mixture Variational Auto-Encoder for Language Modeling
Oct 23, 2023Retrieval-augmented language models show promise in addressing issues like outdated information and hallucinations in language models (LMs). However, current research faces two main problems: 1) determining what information to retrieve, and 2) effectively combining retrieved information during generation. We argue that valuable retrieved information should not only be related to the current source text but also consider the future target text, given the nature of LMs that model future tokens. Moreover, we propose that aggregation using latent variables derived from a compact latent space is more efficient than utilizing explicit raw text, which is limited by context length and susceptible to noise. Therefore, we introduce RegaVAE, a retrieval-augmented language model built upon the variational auto-encoder (VAE). It encodes the text corpus into a latent space, capturing current and future information from both source and target text. Additionally, we leverage the VAE to initialize the latent space and adopt the probabilistic form of the retrieval generation paradigm by expanding the Gaussian prior distribution into a Gaussian mixture distribution. Theoretical analysis provides an optimizable upper bound for RegaVAE. Experimental results on various datasets demonstrate significant improvements in text generation quality and hallucination removal.
Towards a Rigorous Analysis of Mutual Information in Contrastive Learning
Aug 30, 2023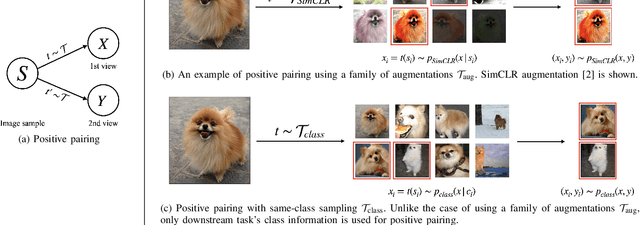

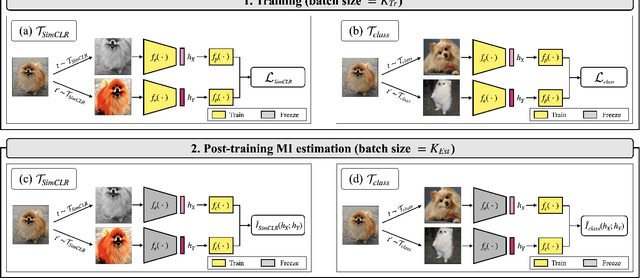
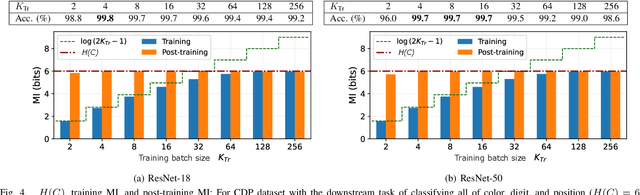
Contrastive learning has emerged as a cornerstone in recent achievements of unsupervised representation learning. Its primary paradigm involves an instance discrimination task with a mutual information loss. The loss is known as InfoNCE and it has yielded vital insights into contrastive learning through the lens of mutual information analysis. However, the estimation of mutual information can prove challenging, creating a gap between the elegance of its mathematical foundation and the complexity of its estimation. As a result, drawing rigorous insights or conclusions from mutual information analysis becomes intricate. In this study, we introduce three novel methods and a few related theorems, aimed at enhancing the rigor of mutual information analysis. Despite their simplicity, these methods can carry substantial utility. Leveraging these approaches, we reassess three instances of contrastive learning analysis, illustrating their capacity to facilitate deeper comprehension or to rectify pre-existing misconceptions. Specifically, we investigate small batch size, mutual information as a measure, and the InfoMin principle.