 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
H-NeXt: The next step towards roto-translation invariant networks
Nov 02, 2023
The widespread popularity of equivariant networks underscores the significance of parameter efficient models and effective use of training data. At a time when robustness to unseen deformations is becoming increasingly important, we present H-NeXt, which bridges the gap between equivariance and invariance. H-NeXt is a parameter-efficient roto-translation invariant network that is trained without a single augmented image in the training set. Our network comprises three components: an equivariant backbone for learning roto-translation independent features, an invariant pooling layer for discarding roto-translation information, and a classification layer. H-NeXt outperforms the state of the art in classification on unaugmented training sets and augmented test sets of MNIST and CIFAR-10.
Towards Grouping in Large Scenes with Occlusion-aware Spatio-temporal Transformers
Oct 30, 2023Group detection, especially for large-scale scenes, has many potential applications for public safety and smart cities. Existing methods fail to cope with frequent occlusions in large-scale scenes with multiple people, and are difficult to effectively utilize spatio-temporal information. In this paper, we propose an end-to-end framework,GroupTransformer, for group detection in large-scale scenes. To deal with the frequent occlusions caused by multiple people, we design an occlusion encoder to detect and suppress severely occluded person crops. To explore the potential spatio-temporal relationship, we propose spatio-temporal transformers to simultaneously extract trajectory information and fuse inter-person features in a hierarchical manner. Experimental results on both large-scale and small-scale scenes demonstrate that our method achieves better performance compared with state-of-the-art methods. On large-scale scenes, our method significantly boosts the performance in terms of precision and F1 score by more than 10%. On small-scale scenes, our method still improves the performance of F1 score by more than 5%. The project page with code can be found at http://cic.tju.edu.cn/faculty/likun/projects/GroupTrans.
* 11 pages, 5 figures
Jina Embeddings 2: 8192-Token General-Purpose Text Embeddings for Long Documents
Oct 30, 2023

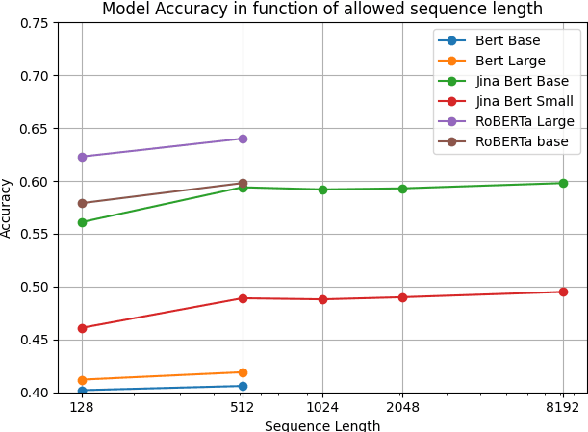
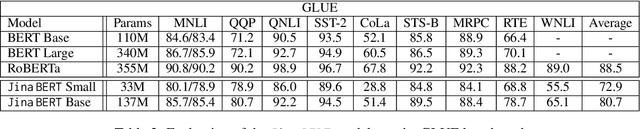
Text embedding models have emerged as powerful tools for transforming sentences into fixed-sized feature vectors that encapsulate semantic information. While these models are essential for tasks like information retrieval, semantic clustering, and text re-ranking, most existing open-source models, especially those built on architectures like BERT, struggle to represent lengthy documents and often resort to truncation. One common approach to mitigate this challenge involves splitting documents into smaller paragraphs for embedding. However, this strategy results in a much larger set of vectors, consequently leading to increased memory consumption and computationally intensive vector searches with elevated latency. To address these challenges, we introduce Jina Embeddings 2, an open-source text embedding model capable of accommodating up to 8192 tokens. This model is designed to transcend the conventional 512-token limit and adeptly process long documents. Jina Embeddings 2 not only achieves state-of-the-art performance on a range of embedding-related tasks in the MTEB benchmark but also matches the performance of OpenAI's proprietary ada-002 model. Additionally, our experiments indicate that an extended context can enhance performance in tasks such as NarrativeQA.
MISFIT-V: Misaligned Image Synthesis and Fusion using Information from Thermal and Visual
Sep 22, 2023Detecting humans from airborne visual and thermal imagery is a fundamental challenge for Wilderness Search-and-Rescue (WiSAR) teams, who must perform this function accurately in the face of immense pressure. The ability to fuse these two sensor modalities can potentially reduce the cognitive load on human operators and/or improve the effectiveness of computer vision object detection models. However, the fusion task is particularly challenging in the context of WiSAR due to hardware limitations and extreme environmental factors. This work presents Misaligned Image Synthesis and Fusion using Information from Thermal and Visual (MISFIT-V), a novel two-pronged unsupervised deep learning approach that utilizes a Generative Adversarial Network (GAN) and a cross-attention mechanism to capture the most relevant features from each modality. Experimental results show MISFIT-V offers enhanced robustness against misalignment and poor lighting/thermal environmental conditions compared to existing visual-thermal image fusion methods.
Crop Disease Classification using Support Vector Machines with Green Chromatic Coordinate (GCC) and Attention based feature extraction for IoT based Smart Agricultural Applications
Nov 01, 2023Crops hold paramount significance as they serve as the primary provider of energy, nutrition, and medicinal benefits for the human population. Plant diseases, however, can negatively affect leaves during agricultural cultivation, resulting in significant losses in crop output and economic value. Therefore, it is crucial for farmers to identify crop diseases. However, this method frequently necessitates hard work, a lot of planning, and in-depth familiarity with plant pathogens. Given these numerous obstacles, it is essential to provide solutions that can easily interface with mobile and IoT devices so that our farmers can guarantee the best possible crop development. Various machine learning (ML) as well as deep learning (DL) algorithms have been created & studied for the identification of plant disease detection, yielding substantial and promising results. This article presents a novel classification method that builds on prior work by utilising attention-based feature extraction, RGB channel-based chromatic analysis, Support Vector Machines (SVM) for improved performance, and the ability to integrate with mobile applications and IoT devices after quantization of information. Several disease classification algorithms were compared with the suggested model, and it was discovered that, in terms of accuracy, Vision Transformer-based feature extraction and additional Green Chromatic Coordinate feature with SVM classification achieved an accuracy of (GCCViT-SVM) - 99.69%, whereas after quantization for IoT device integration achieved an accuracy of - 97.41% while almost reducing 4x in size. Our findings have profound implications because they have the potential to transform how farmers identify crop illnesses with precise and fast information, thereby preserving agricultural output and ensuring food security.
Towards a Rigorous Analysis of Mutual Information in Contrastive Learning
Aug 30, 2023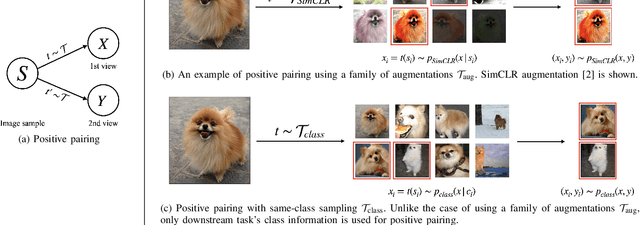

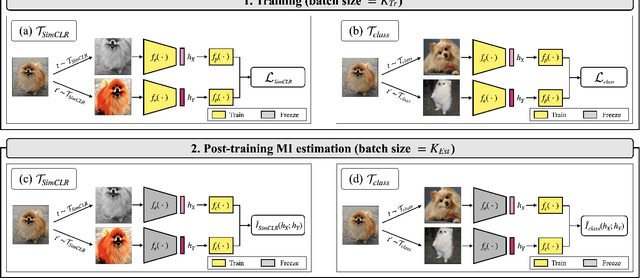
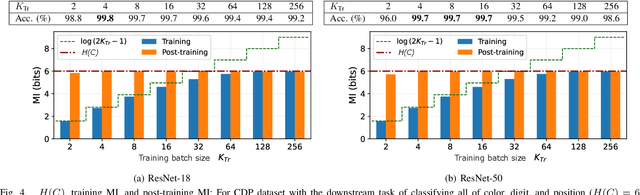
Contrastive learning has emerged as a cornerstone in recent achievements of unsupervised representation learning. Its primary paradigm involves an instance discrimination task with a mutual information loss. The loss is known as InfoNCE and it has yielded vital insights into contrastive learning through the lens of mutual information analysis. However, the estimation of mutual information can prove challenging, creating a gap between the elegance of its mathematical foundation and the complexity of its estimation. As a result, drawing rigorous insights or conclusions from mutual information analysis becomes intricate. In this study, we introduce three novel methods and a few related theorems, aimed at enhancing the rigor of mutual information analysis. Despite their simplicity, these methods can carry substantial utility. Leveraging these approaches, we reassess three instances of contrastive learning analysis, illustrating their capacity to facilitate deeper comprehension or to rectify pre-existing misconceptions. Specifically, we investigate small batch size, mutual information as a measure, and the InfoMin principle.
Exploring Latent Spaces of Tonal Music using Variational Autoencoders
Nov 07, 2023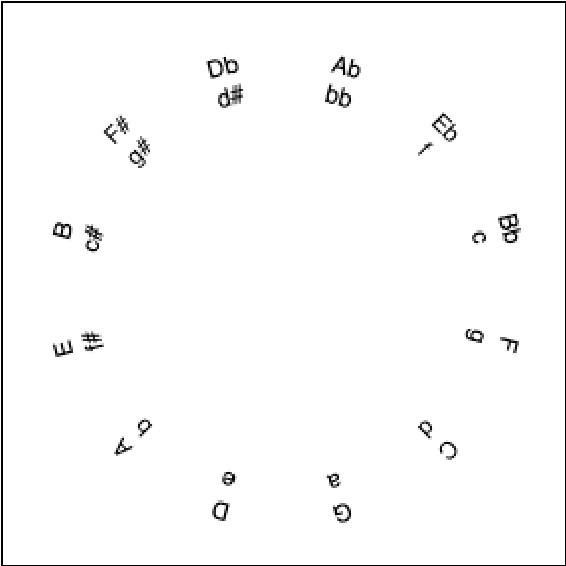
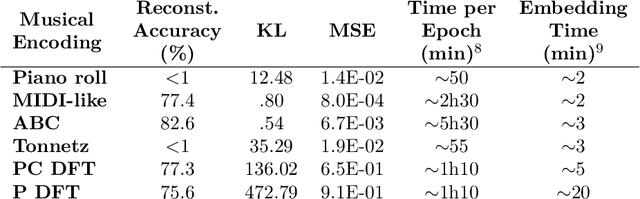
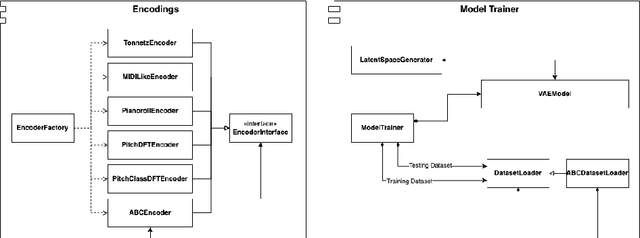
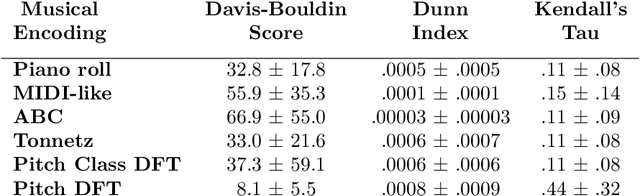
Variational Autoencoders (VAEs) have proven to be effective models for producing latent representations of cognitive and semantic value. We assess the degree to which VAEs trained on a prototypical tonal music corpus of 371 Bach's chorales define latent spaces representative of the circle of fifths and the hierarchical relation of each key component pitch as drawn in music cognition. In detail, we compare the latent space of different VAE corpus encodings -- Piano roll, MIDI, ABC, Tonnetz, DFT of pitch, and pitch class distributions -- in providing a pitch space for key relations that align with cognitive distances. We evaluate the model performance of these encodings using objective metrics to capture accuracy, mean square error (MSE), KL-divergence, and computational cost. The ABC encoding performs the best in reconstructing the original data, while the Pitch DFT seems to capture more information from the latent space. Furthermore, an objective evaluation of 12 major or minor transpositions per piece is adopted to quantify the alignment of 1) intra- and inter-segment distances per key and 2) the key distances to cognitive pitch spaces. Our results show that Pitch DFT VAE latent spaces align best with cognitive spaces and provide a common-tone space where overlapping objects within a key are fuzzy clusters, which impose a well-defined order of structural significance or stability -- i.e., a tonal hierarchy. Tonal hierarchies of different keys can be used to measure key distances and the relationships of their in-key components at multiple hierarchies (e.g., notes and chords). The implementation of our VAE and the encodings framework are made available online.
Cooperative Network Learning for Large-Scale and Decentralized Graphs
Nov 07, 2023Graph research, the systematic study of interconnected data points represented as graphs, plays a vital role in capturing intricate relationships within networked systems. However, in the real world, as graphs scale up, concerns about data security among different data-owning agencies arise, hindering information sharing and, ultimately, the utilization of graph data. Therefore, establishing a mutual trust mechanism among graph agencies is crucial for unlocking the full potential of graphs. Here, we introduce a Cooperative Network Learning (CNL) framework to ensure secure graph computing for various graph tasks. Essentially, this CNL framework unifies the local and global perspectives of GNN computing with distributed data for an agency by virtually connecting all participating agencies as a global graph without a fixed central coordinator. Inter-agency computing is protected by various technologies inherent in our framework, including homomorphic encryption and secure transmission. Moreover, each agency has a fair right to design or employ various graph learning models from its local or global perspective. Thus, CNL can collaboratively train GNN models based on decentralized graphs inferred from local and global graphs. Experiments on contagion dynamics prediction and traditional graph tasks (i.e., node classification and link prediction) demonstrate that our CNL architecture outperforms state-of-the-art GNNs developed at individual sites, revealing that CNL can provide a reliable, fair, secure, privacy-preserving, and global perspective to build effective and personalized models for network applications. We hope this framework will address privacy concerns in graph-related research and integrate decentralized graph data structures to benefit the network research community in cooperation and innovation.
Conversations in Galician: a Large Language Model for an Underrepresented Language
Nov 07, 2023The recent proliferation of Large Conversation Language Models has highlighted the economic significance of widespread access to this type of AI technologies in the current information age. Nevertheless, prevailing models have primarily been trained on corpora consisting of documents written in popular languages. The dearth of such cutting-edge tools for low-resource languages further exacerbates their underrepresentation in the current economic landscape, thereby impacting their native speakers. This paper introduces two novel resources designed to enhance Natural Language Processing (NLP) for the Galician language. We present a Galician adaptation of the Alpaca dataset, comprising 52,000 instructions and demonstrations. This dataset proves invaluable for enhancing language models by fine-tuning them to more accurately adhere to provided instructions. Additionally, as a demonstration of the dataset utility, we fine-tuned LLaMA-7B to comprehend and respond in Galician, a language not originally supported by the model, by following the Alpaca format. This work contributes to the research on multilingual models tailored for low-resource settings, a crucial endeavor in ensuring the inclusion of all linguistic communities in the development of Large Language Models. Another noteworthy aspect of this research is the exploration of how knowledge of a closely related language, in this case, Portuguese, can assist in generating coherent text when training resources are scarce. Both the Galician Alpaca dataset and Cabuxa-7B are publicly accessible on our Huggingface Hub, and we have made the source code available to facilitate replication of this experiment and encourage further advancements for underrepresented languages.
FLORA: Fine-grained Low-Rank Architecture Search for Vision Transformer
Nov 07, 2023Vision Transformers (ViT) have recently demonstrated success across a myriad of computer vision tasks. However, their elevated computational demands pose significant challenges for real-world deployment. While low-rank approximation stands out as a renowned method to reduce computational loads, efficiently automating the target rank selection in ViT remains a challenge. Drawing from the notable similarity and alignment between the processes of rank selection and One-Shot NAS, we introduce FLORA, an end-to-end automatic framework based on NAS. To overcome the design challenge of supernet posed by vast search space, FLORA employs a low-rank aware candidate filtering strategy. This method adeptly identifies and eliminates underperforming candidates, effectively alleviating potential undertraining and interference among subnetworks. To further enhance the quality of low-rank supernets, we design a low-rank specific training paradigm. First, we propose weight inheritance to construct supernet and enable gradient sharing among low-rank modules. Secondly, we adopt low-rank aware sampling to strategically allocate training resources, taking into account inherited information from pre-trained models. Empirical results underscore FLORA's efficacy. With our method, a more fine-grained rank configuration can be generated automatically and yield up to 33% extra FLOPs reduction compared to a simple uniform configuration. More specific, FLORA-DeiT-B/FLORA-Swin-B can save up to 55%/42% FLOPs almost without performance degradtion. Importantly, FLORA boasts both versatility and orthogonality, offering an extra 21%-26% FLOPs reduction when integrated with leading compression techniques or compact hybrid structures. Our code is publicly available at https://github.com/shadowpa0327/FLORA.