 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Explainable Text Classification Techniques in Legal Document Review: Locating Rationales without Using Human Annotated Training Text Snippets
Nov 15, 2023
US corporations regularly spend millions of dollars reviewing electronically-stored documents in legal matters. Recently, attorneys apply text classification to efficiently cull massive volumes of data to identify responsive documents for use in these matters. While text classification is regularly used to reduce the discovery costs of legal matters, it also faces a perception challenge: amongst lawyers, this technology is sometimes looked upon as a "black box". Put simply, no extra information is provided for attorneys to understand why documents are classified as responsive. In recent years, explainable machine learning has emerged as an active research area. In an explainable machine learning system, predictions or decisions made by a machine learning model are human understandable. In legal 'document review' scenarios, a document is responsive, because one or more of its small text snippets are deemed responsive. In these scenarios, if these responsive snippets can be located, then attorneys could easily evaluate the model's document classification decisions - this is especially important in the field of responsible AI. Our prior research identified that predictive models created using annotated training text snippets improved the precision of a model when compared to a model created using all of a set of documents' text as training. While interesting, manually annotating training text snippets is not generally practical during a legal document review. However, small increases in precision can drastically decrease the cost of large document reviews. Automating the identification of training text snippets without human review could then make the application of training text snippet-based models a practical approach.
Network-Level Integrated Sensing and Communication: Interference Management and BS Coordination Using Stochastic Geometry
Nov 15, 2023In this work, we study integrated sensing and communication (ISAC) networks with the aim of effectively balancing sensing and communication (S&C) performance at the network level. Focusing on monostatic sensing, the tool of stochastic geometry is exploited to capture the S&C performance, which facilitates us to illuminate key cooperative dependencies in the ISAC network and optimize key network-level parameters. Based on the derived tractable expression of area spectral efficiency (ASE), we formulate the optimization problem to maximize the network performance from the view point of two joint S&C metrics. Towards this end, we further jointly optimize the cooperative BS cluster sizes for S&C and the serving/probing numbers of users/targets to achieve a flexible tradeoff between S&C at the network level. It is verified that interference nulling can effectively improve the average data rate and radar information rate. Surprisingly, the optimal communication tradeoff for the case of the ASE maximization tends to employ all spacial resources towards multiplexing and diversity gain, without interference nulling. By contrast, for the sensing objectives, resource allocation tends to eliminate certain interference especially when the antenna resources are sufficient, because the inter-cell interference becomes a more dominant factor affecting sensing performance. Furthermore, we prove that the ratio of the optimal number of users and the number of transmit antennas is a constant value when the communication performance is optimal. Simulation results demonstrate that the proposed cooperative ISAC scheme achieves a substantial gain in S&C performance at the network level.
Leveraging Citizen Science for Flood Extent Detection using Machine Learning Benchmark Dataset
Nov 15, 2023Accurate detection of inundated water extents during flooding events is crucial in emergency response decisions and aids in recovery efforts. Satellite Remote Sensing data provides a global framework for detecting flooding extents. Specifically, Sentinel-1 C-Band Synthetic Aperture Radar (SAR) imagery has proven to be useful in detecting water bodies due to low backscatter of water features in both co-polarized and cross-polarized SAR imagery. However, increased backscatter can be observed in certain flooded regions such as presence of infrastructure and trees - rendering simple methods such as pixel intensity thresholding and time-series differencing inadequate. Machine Learning techniques has been leveraged to precisely capture flood extents in flooded areas with bumps in backscatter but needs high amounts of labelled data to work desirably. Hence, we created a labeled known water body extent and flooded area extents during known flooding events covering about 36,000 sq. kilometers of regions within mainland U.S and Bangladesh. Further, We also leveraged citizen science by open-sourcing the dataset and hosting an open competition based on the dataset to rapidly prototype flood extent detection using community generated models. In this paper we present the information about the dataset, the data processing pipeline, a baseline model and the details about the competition, along with discussion on winning approaches. We believe the dataset adds to already existing datasets based on Sentinel-1C SAR data and leads to more robust modeling of flood extents. We also hope the results from the competition pushes the research in flood extent detection further.
Inexpensive High Fidelity Melt Pool Models in Additive Manufacturing Using Generative Deep Diffusion
Nov 15, 2023Defects in laser powder bed fusion (L-PBF) parts often result from the meso-scale dynamics of the molten alloy near the laser, known as the melt pool. For instance, the melt pool can directly contribute to the formation of undesirable porosity, residual stress, and surface roughness in the final part. Experimental in-situ monitoring of the three-dimensional melt pool physical fields is challenging, due to the short length and time scales involved in the process. Multi-physics simulation methods can describe the three-dimensional dynamics of the melt pool, but are computationally expensive at the mesh refinement required for accurate predictions of complex effects, such as the formation of keyhole porosity. Therefore, in this work, we develop a generative deep learning model based on the probabilistic diffusion framework to map low-fidelity, coarse-grained simulation information to the high-fidelity counterpart. By doing so, we bypass the computational expense of conducting multiple high-fidelity simulations for analysis by instead upscaling lightweight coarse mesh simulations. Specifically, we implement a 2-D diffusion model to spatially upscale cross-sections of the coarsely simulated melt pool to their high-fidelity equivalent. We demonstrate the preservation of key metrics of the melting process between the ground truth simulation data and the diffusion model output, such as the temperature field, the melt pool dimensions and the variability of the keyhole vapor cavity. Specifically, we predict the melt pool depth within 3 $\mu m$ based on low-fidelity input data 4$\times$ coarser than the high-fidelity simulations, reducing analysis time by two orders of magnitude.
SCONE-GAN: Semantic Contrastive learning-based Generative Adversarial Network for an end-to-end image translation
Nov 07, 2023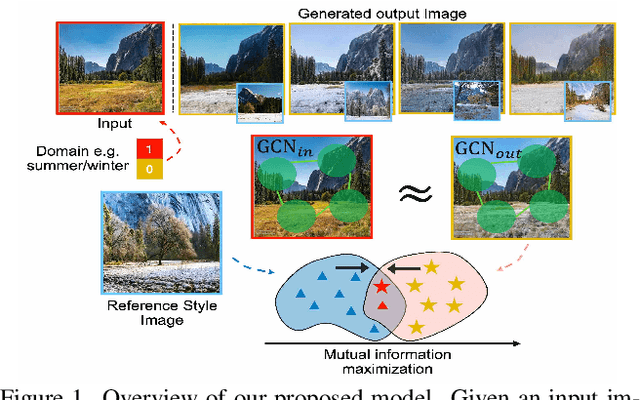
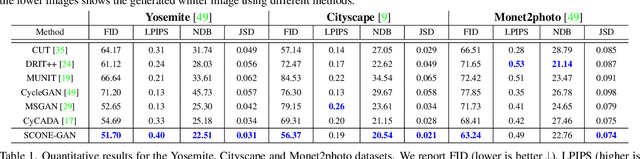
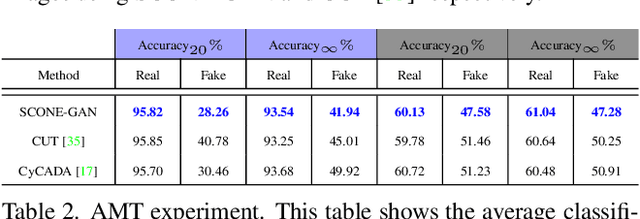

SCONE-GAN presents an end-to-end image translation, which is shown to be effective for learning to generate realistic and diverse scenery images. Most current image-to-image translation approaches are devised as two mappings: a translation from the source to target domain and another to represent its inverse. While successful in many applications, these approaches may suffer from generating trivial solutions with limited diversity. That is because these methods learn more frequent associations rather than the scene structures. To mitigate the problem, we propose SCONE-GAN that utilises graph convolutional networks to learn the objects dependencies, maintain the image structure and preserve its semantics while transferring images into the target domain. For more realistic and diverse image generation we introduce style reference image. We enforce the model to maximize the mutual information between the style image and output. The proposed method explicitly maximizes the mutual information between the related patches, thus encouraging the generator to produce more diverse images. We validate the proposed algorithm for image-to-image translation and stylizing outdoor images. Both qualitative and quantitative results demonstrate the effectiveness of our approach on four dataset.
Hypergraphs with node attributes: structure and inference
Nov 07, 2023Many networked datasets with units interacting in groups of two or more, encoded with hypergraphs, are accompanied by extra information about nodes, such as the role of an individual in a workplace. Here we show how these node attributes can be used to improve our understanding of the structure resulting from higher-order interactions. We consider the problem of community detection in hypergraphs and develop a principled model that combines higher-order interactions and node attributes to better represent the observed interactions and to detect communities more accurately than using either of these types of information alone. The method learns automatically from the input data the extent to which structure and attributes contribute to explain the data, down weighing or discarding attributes if not informative. Our algorithmic implementation is efficient and scales to large hypergraphs and interactions of large numbers of units. We apply our method to a variety of systems, showing strong performance in hyperedge prediction tasks and in selecting community divisions that correlate with attributes when these are informative, but discarding them otherwise. Our approach illustrates the advantage of using informative node attributes when available with higher-order data.
Lightweight Portrait Matting via Regional Attention and Refinement
Nov 07, 2023We present a lightweight model for high resolution portrait matting. The model does not use any auxiliary inputs such as trimaps or background captures and achieves real time performance for HD videos and near real time for 4K. Our model is built upon a two-stage framework with a low resolution network for coarse alpha estimation followed by a refinement network for local region improvement. However, a naive implementation of the two-stage model suffers from poor matting quality if not utilizing any auxiliary inputs. We address the performance gap by leveraging the vision transformer (ViT) as the backbone of the low resolution network, motivated by the observation that the tokenization step of ViT can reduce spatial resolution while retain as much pixel information as possible. To inform local regions of the context, we propose a novel cross region attention (CRA) module in the refinement network to propagate the contextual information across the neighboring regions. We demonstrate that our method achieves superior results and outperforms other baselines on three benchmark datasets while only uses $1/20$ of the FLOPS compared to the existing state-of-the-art model.
Context Shift Reduction for Offline Meta-Reinforcement Learning
Nov 07, 2023Offline meta-reinforcement learning (OMRL) utilizes pre-collected offline datasets to enhance the agent's generalization ability on unseen tasks. However, the context shift problem arises due to the distribution discrepancy between the contexts used for training (from the behavior policy) and testing (from the exploration policy). The context shift problem leads to incorrect task inference and further deteriorates the generalization ability of the meta-policy. Existing OMRL methods either overlook this problem or attempt to mitigate it with additional information. In this paper, we propose a novel approach called Context Shift Reduction for OMRL (CSRO) to address the context shift problem with only offline datasets. The key insight of CSRO is to minimize the influence of policy in context during both the meta-training and meta-test phases. During meta-training, we design a max-min mutual information representation learning mechanism to diminish the impact of the behavior policy on task representation. In the meta-test phase, we introduce the non-prior context collection strategy to reduce the effect of the exploration policy. Experimental results demonstrate that CSRO significantly reduces the context shift and improves the generalization ability, surpassing previous methods across various challenging domains.
AI-accelerated Discovery of Altermagnetic Materials
Nov 13, 2023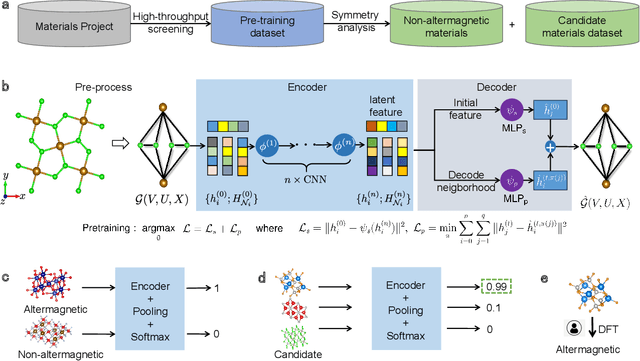
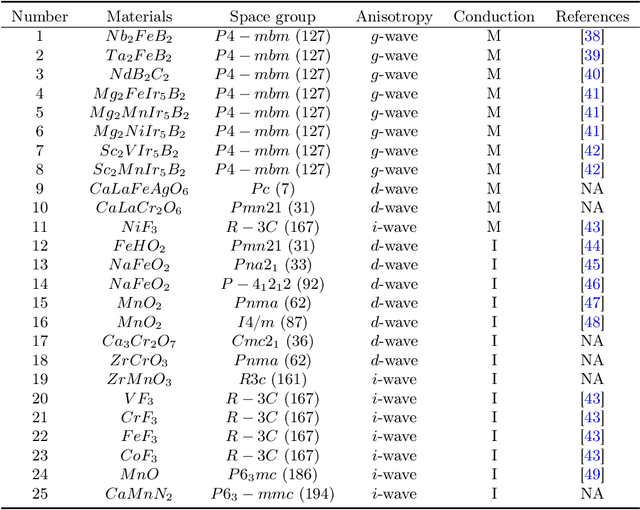
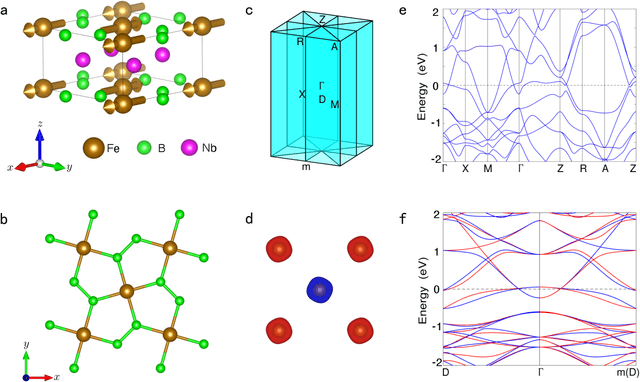
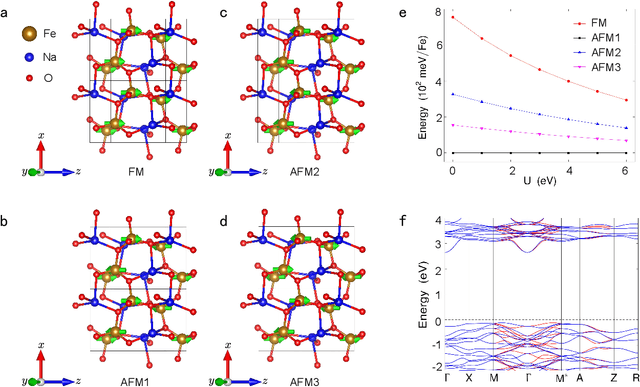
Altermagnetism, a new magnetic phase, has been theoretically proposed and experimentally verified to be distinct from ferromagnetism and antiferromagnetism. Although altermagnets have been found to possess many exotic physical properties, the very limited availability of known altermagnetic materials (e.g., 14 confirmed materials) hinders the study of such properties. Hence, discovering more types of altermagnetic materials is crucial for a comprehensive understanding of altermagnetism and thus facilitating new applications in the next-generation information technologies, e.g., storage devices and high-sensitivity sensors. Here, we report 25 new altermagnetic materials that cover metals, semiconductors, and insulators, discovered by an AI search engine unifying symmetry analysis, graph neural network pre-training, optimal transport theory, and first-principles electronic structure calculation. The wide range of electronic structural characteristics reveals that various novel physical properties manifest in these newly discovered altermagnetic materials, e.g., anomalous Hall effect, anomalous Kerr effect, and topological property. Noteworthy, we discovered 8 i-wave altermagnetic materials for the first time. Overall, the AI search engine performs much better than human experts and suggests a set of new altermagnetic materials with unique properties, outlining its potential for accelerated discovery of the materials with targeting properties.
Coffee: Boost Your Code LLMs by Fixing Bugs with Feedback
Nov 13, 2023Code editing is an essential step towards reliable program synthesis to automatically correct critical errors generated from code LLMs. Recent studies have demonstrated that closed-source LLMs (i.e., ChatGPT and GPT-4) are capable of generating corrective feedback to edit erroneous inputs. However, it remains challenging for open-source code LLMs to generate feedback for code editing, since these models tend to adhere to the superficial formats of feedback and provide feedback with misleading information. Hence, the focus of our work is to leverage open-source code LLMs to generate helpful feedback with correct guidance for code editing. To this end, we present Coffee, a collected dataset specifically designed for code fixing with feedback. Using this dataset, we construct CoffeePots, a framework for COde Fixing with FEEdback via Preference-Optimized Tuning and Selection. The proposed framework aims to automatically generate helpful feedback for code editing while minimizing the potential risk of superficial feedback. The combination of Coffee and CoffeePots marks a significant advancement, achieving state-of-the-art performance on HumanEvalFix benchmark. Codes and model checkpoints are publicly available at https://github.com/Lune-Blue/COFFEE.