 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
EulerFormer: Sequential User Behavior Modeling with Complex Vector Attention
Apr 04, 2024
To capture user preference, transformer models have been widely applied to model sequential user behavior data. The core of transformer architecture lies in the self-attention mechanism, which computes the pairwise attention scores in a sequence. Due to the permutation-equivariant nature, positional encoding is used to enhance the attention between token representations. In this setting, the pairwise attention scores can be derived by both semantic difference and positional difference. However, prior studies often model the two kinds of difference measurements in different ways, which potentially limits the expressive capacity of sequence modeling. To address this issue, this paper proposes a novel transformer variant with complex vector attention, named EulerFormer, which provides a unified theoretical framework to formulate both semantic difference and positional difference. The EulerFormer involves two key technical improvements. First, it employs a new transformation function for efficiently transforming the sequence tokens into polar-form complex vectors using Euler's formula, enabling the unified modeling of both semantic and positional information in a complex rotation form.Secondly, it develops a differential rotation mechanism, where the semantic rotation angles can be controlled by an adaptation function, enabling the adaptive integration of the semantic and positional information according to the semantic contexts.Furthermore, a phase contrastive learning task is proposed to improve the isotropy of contextual representations in EulerFormer. Our theoretical framework possesses a high degree of completeness and generality. It is more robust to semantic variations and possesses moresuperior theoretical properties in principle. Extensive experiments conducted on four public datasets demonstrate the effectiveness and efficiency of our approach.
Leveraging Linguistically Enhanced Embeddings for Open Information Extraction
Mar 20, 2024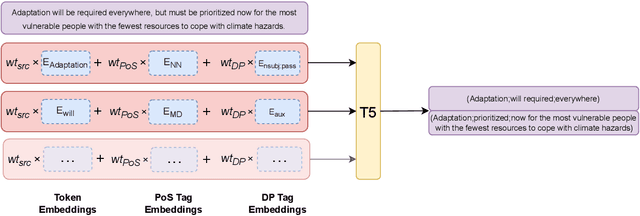

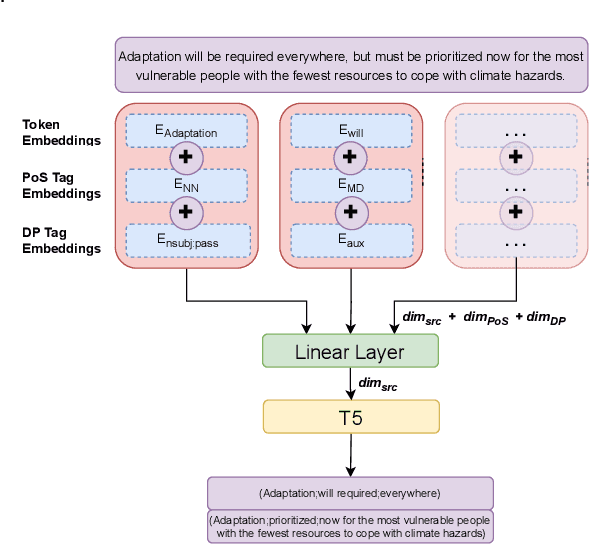
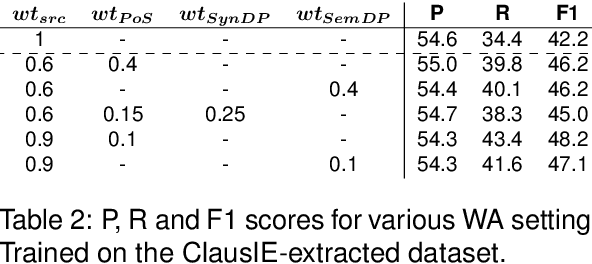
Open Information Extraction (OIE) is a structured prediction (SP) task in Natural Language Processing (NLP) that aims to extract structured $n$-ary tuples - usually subject-relation-object triples - from free text. The word embeddings in the input text can be enhanced with linguistic features, usually Part-of-Speech (PoS) and Syntactic Dependency Parse (SynDP) labels. However, past enhancement techniques cannot leverage the power of pretrained language models (PLMs), which themselves have been hardly used for OIE. To bridge this gap, we are the first to leverage linguistic features with a Seq2Seq PLM for OIE. We do so by introducing two methods - Weighted Addition and Linearized Concatenation. Our work can give any neural OIE architecture the key performance boost from both PLMs and linguistic features in one go. In our settings, this shows wide improvements of up to 24.9%, 27.3% and 14.9% on Precision, Recall and F1 scores respectively over the baseline. Beyond this, we address other important challenges in the field: to reduce compute overheads with the features, we are the first ones to exploit Semantic Dependency Parse (SemDP) tags; to address flaws in current datasets, we create a clean synthetic dataset; finally, we contribute the first known study of OIE behaviour in SP models.
Learning Decomposable and Debiased Representations via Attribute-Centric Information Bottlenecks
Mar 21, 2024
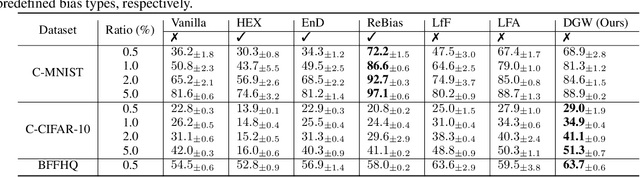
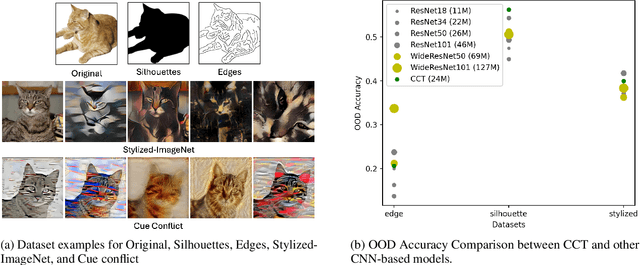
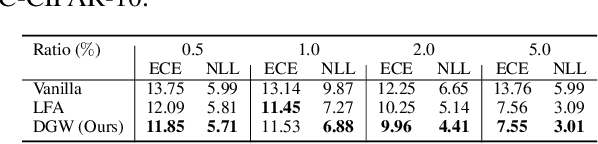
Biased attributes, spuriously correlated with target labels in a dataset, can problematically lead to neural networks that learn improper shortcuts for classifications and limit their capabilities for out-of-distribution (OOD) generalization. Although many debiasing approaches have been proposed to ensure correct predictions from biased datasets, few studies have considered learning latent embedding consisting of intrinsic and biased attributes that contribute to improved performance and explain how the model pays attention to attributes. In this paper, we propose a novel debiasing framework, Debiasing Global Workspace, introducing attention-based information bottlenecks for learning compositional representations of attributes without defining specific bias types. Based on our observation that learning shape-centric representation helps robust performance on OOD datasets, we adopt those abilities to learn robust and generalizable representations of decomposable latent embeddings corresponding to intrinsic and biasing attributes. We conduct comprehensive evaluations on biased datasets, along with both quantitative and qualitative analyses, to showcase our approach's efficacy in attribute-centric representation learning and its ability to differentiate between intrinsic and bias-related features.
Autonomous Artificial Intelligence Agents for Clinical Decision Making in Oncology
Apr 06, 2024Multimodal artificial intelligence (AI) systems have the potential to enhance clinical decision-making by interpreting various types of medical data. However, the effectiveness of these models across all medical fields is uncertain. Each discipline presents unique challenges that need to be addressed for optimal performance. This complexity is further increased when attempting to integrate different fields into a single model. Here, we introduce an alternative approach to multimodal medical AI that utilizes the generalist capabilities of a large language model (LLM) as a central reasoning engine. This engine autonomously coordinates and deploys a set of specialized medical AI tools. These tools include text, radiology and histopathology image interpretation, genomic data processing, web searches, and document retrieval from medical guidelines. We validate our system across a series of clinical oncology scenarios that closely resemble typical patient care workflows. We show that the system has a high capability in employing appropriate tools (97%), drawing correct conclusions (93.6%), and providing complete (94%), and helpful (89.2%) recommendations for individual patient cases while consistently referencing relevant literature (82.5%) upon instruction. This work provides evidence that LLMs can effectively plan and execute domain-specific models to retrieve or synthesize new information when used as autonomous agents. This enables them to function as specialist, patient-tailored clinical assistants. It also simplifies regulatory compliance by allowing each component tool to be individually validated and approved. We believe, that our work can serve as a proof-of-concept for more advanced LLM-agents in the medical domain.
Diverse Representation Embedding for Lifelong Person Re-Identification
Apr 02, 2024Lifelong Person Re-Identification (LReID) aims to continuously learn from successive data streams, matching individuals across multiple cameras. The key challenge for LReID is how to effectively preserve old knowledge while incrementally learning new information, which is caused by task-level domain gaps and limited old task datasets. Existing methods based on CNN backbone are insufficient to explore the representation of each instance from different perspectives, limiting model performance on limited old task datasets and new task datasets. Unlike these methods, we propose a Diverse Representations Embedding (DRE) framework that first explores a pure transformer for LReID. The proposed DRE preserves old knowledge while adapting to new information based on instance-level and task-level layout. Concretely, an Adaptive Constraint Module (ACM) is proposed to implement integration and push away operations between multiple overlapping representations generated by transformer-based backbone, obtaining rich and discriminative representations for each instance to improve adaptive ability of LReID. Based on the processed diverse representations, we propose Knowledge Update (KU) and Knowledge Preservation (KP) strategies at the task-level layout by introducing the adjustment model and the learner model. KU strategy enhances the adaptive learning ability of learner models for new information under the adjustment model prior, and KP strategy preserves old knowledge operated by representation-level alignment and logit-level supervision in limited old task datasets while guaranteeing the adaptive learning information capacity of the LReID model. Compared to state-of-the-art methods, our method achieves significantly improved performance in holistic, large-scale, and occluded datasets.
On-the-Go Tree Detection and Geometric Traits Estimation with Ground Mobile Robots in Fruit Tree Groves
Apr 03, 2024By-tree information gathering is an essential task in precision agriculture achieved by ground mobile sensors, but it can be time- and labor-intensive. In this paper we present an algorithmic framework to perform real-time and on-the-go detection of trees and key geometric characteristics (namely, width and height) with wheeled mobile robots in the field. Our method is based on the fusion of 2D domain-specific data (normalized difference vegetation index [NDVI] acquired via a red-green-near-infrared [RGN] camera) and 3D LiDAR point clouds, via a customized tree landmark association and parameter estimation algorithm. The proposed system features a multi-modal and entropy-based landmark correspondences approach, integrated into an underlying Kalman filter system to recognize the surrounding trees and jointly estimate their spatial and vegetation-based characteristics. Realistic simulated tests are used to evaluate our proposed algorithm's behavior in a variety of settings. Physical experiments in agricultural fields help validate our method's efficacy in acquiring accurate by-tree information on-the-go and in real-time by employing only onboard computational and sensing resources.
Vocabulary Attack to Hijack Large Language Model Applications
Apr 03, 2024The fast advancements in Large Language Models (LLMs) are driving an increasing number of applications. Together with the growing number of users, we also see an increasing number of attackers who try to outsmart these systems. They want the model to reveal confidential information, specific false information, or offensive behavior. To this end, they manipulate their instructions for the LLM by inserting separators or rephrasing them systematically until they reach their goal. Our approach is different. It inserts words from the model vocabulary. We find these words using an optimization procedure and embeddings from another LLM (attacker LLM). We prove our approach by goal hijacking two popular open-source LLMs from the Llama2 and the Flan-T5 families, respectively. We present two main findings. First, our approach creates inconspicuous instructions and therefore it is hard to detect. For many attack cases, we find that even a single word insertion is sufficient. Second, we demonstrate that we can conduct our attack using a different model than the target model to conduct our attack with.
To Search or to Recommend: Predicting Open-App Motivation with Neural Hawkes Process
Apr 04, 2024Incorporating Search and Recommendation (S&R) services within a singular application is prevalent in online platforms, leading to a new task termed open-app motivation prediction, which aims to predict whether users initiate the application with the specific intent of information searching, or to explore recommended content for entertainment. Studies have shown that predicting users' motivation to open an app can help to improve user engagement and enhance performance in various downstream tasks. However, accurately predicting open-app motivation is not trivial, as it is influenced by user-specific factors, search queries, clicked items, as well as their temporal occurrences. Furthermore, these activities occur sequentially and exhibit intricate temporal dependencies. Inspired by the success of the Neural Hawkes Process (NHP) in modeling temporal dependencies in sequences, this paper proposes a novel neural Hawkes process model to capture the temporal dependencies between historical user browsing and querying actions. The model, referred to as Neural Hawkes Process-based Open-App Motivation prediction model (NHP-OAM), employs a hierarchical transformer and a novel intensity function to encode multiple factors, and open-app motivation prediction layer to integrate time and user-specific information for predicting users' open-app motivations. To demonstrate the superiority of our NHP-OAM model and construct a benchmark for the Open-App Motivation Prediction task, we not only extend the public S&R dataset ZhihuRec but also construct a new real-world Open-App Motivation Dataset (OAMD). Experiments on these two datasets validate NHP-OAM's superiority over baseline models. Further downstream application experiments demonstrate NHP-OAM's effectiveness in predicting users' Open-App Motivation, highlighting the immense application value of NHP-OAM.
Towards introspective loop closure in 4D radar SLAM
Apr 05, 2024Imaging radar is an emerging sensor modality in the context of Localization and Mapping (SLAM), especially suitable for vision-obstructed environments. This article investigates the use of 4D imaging radars for SLAM and analyzes the challenges in robust loop closure. Previous work indicates that 4D radars, together with inertial measurements, offer ample information for accurate odometry estimation. However, the low field of view, limited resolution, and sparse and noisy measurements render loop closure a significantly more challenging problem. Our work builds on the previous work - TBV SLAM - which was proposed for robust loop closure with 360$^\circ$ spinning radars. This article highlights and addresses challenges inherited from a directional 4D radar, such as sparsity, noise, and reduced field of view, and discusses why the common definition of a loop closure is unsuitable. By combining multiple quality measures for accurate loop closure detection adapted to 4D radar data, significant results in trajectory estimation are achieved; the absolute trajectory error is as low as 0.46 m over a distance of 1.8 km, with consistent operation over multiple environments.
Towards Efficient and Accurate CT Segmentation via Edge-Preserving Probabilistic Downsampling
Apr 05, 2024Downsampling images and labels, often necessitated by limited resources or to expedite network training, leads to the loss of small objects and thin boundaries. This undermines the segmentation network's capacity to interpret images accurately and predict detailed labels, resulting in diminished performance compared to processing at original resolutions. This situation exemplifies the trade-off between efficiency and accuracy, with higher downsampling factors further impairing segmentation outcomes. Preserving information during downsampling is especially critical for medical image segmentation tasks. To tackle this challenge, we introduce a novel method named Edge-preserving Probabilistic Downsampling (EPD). It utilizes class uncertainty within a local window to produce soft labels, with the window size dictating the downsampling factor. This enables a network to produce quality predictions at low resolutions. Beyond preserving edge details more effectively than conventional nearest-neighbor downsampling, employing a similar algorithm for images, it surpasses bilinear interpolation in image downsampling, enhancing overall performance. Our method significantly improved Intersection over Union (IoU) to 2.85%, 8.65%, and 11.89% when downsampling data to 1/2, 1/4, and 1/8, respectively, compared to conventional interpolation methods.