 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cross-modal Prompts: Adapting Large Pre-trained Models for Audio-Visual Downstream Tasks
Nov 09, 2023
In recent years, the deployment of large-scale pre-trained models in audio-visual downstream tasks has yielded remarkable outcomes. However, these models, primarily trained on single-modality unconstrained datasets, still encounter challenges in feature extraction for multi-modal tasks, leading to suboptimal performance. This limitation arises due to the introduction of irrelevant modality-specific information during encoding, which adversely affects the performance of downstream tasks. To address this challenge, this paper proposes a novel Dual-Guided Spatial-Channel-Temporal (DG-SCT) attention mechanism. This mechanism leverages audio and visual modalities as soft prompts to dynamically adjust the parameters of pre-trained models based on the current multi-modal input features. Specifically, the DG-SCT module incorporates trainable cross-modal interaction layers into pre-trained audio-visual encoders, allowing adaptive extraction of crucial information from the current modality across spatial, channel, and temporal dimensions, while preserving the frozen parameters of large-scale pre-trained models. Experimental evaluations demonstrate that our proposed model achieves state-of-the-art results across multiple downstream tasks, including AVE, AVVP, AVS, and AVQA. Furthermore, our model exhibits promising performance in challenging few-shot and zero-shot scenarios. The source code and pre-trained models are available at https://github.com/haoyi-duan/DG-SCT.
TLCFuse: Temporal Multi-Modality Fusion Towards Occlusion-Aware Semantic Segmentation-Aided Motion Planning
Nov 09, 2023In autonomous driving, addressing occlusion scenarios is crucial yet challenging. Robust surrounding perception is essential for handling occlusions and aiding motion planning. State-of-the-art models fuse Lidar and Camera data to produce impressive perception results, but detecting occluded objects remains challenging. In this paper, we emphasize the crucial role of temporal cues by integrating them alongside these modalities to address this challenge. We propose a novel approach for bird's eye view semantic grid segmentation, that leverages sequential sensor data to achieve robustness against occlusions. Our model extracts information from the sensor readings using attention operations and aggregates this information into a lower-dimensional latent representation, enabling thus the processing of multi-step inputs at each prediction step. Moreover, we show how it can also be directly applied to forecast the development of traffic scenes and be seamlessly integrated into a motion planner for trajectory planning. On the semantic segmentation tasks, we evaluate our model on the nuScenes dataset and show that it outperforms other baselines, with particularly large differences when evaluating on occluded and partially-occluded vehicles. Additionally, on motion planning task we are among the early teams to train and evaluate on nuPlan, a cutting-edge large-scale dataset for motion planning.
Multi-Modal Gaze Following in Conversational Scenarios
Nov 09, 2023Gaze following estimates gaze targets of in-scene person by understanding human behavior and scene information. Existing methods usually analyze scene images for gaze following. However, compared with visual images, audio also provides crucial cues for determining human behavior.This suggests that we can further improve gaze following considering audio cues. In this paper, we explore gaze following tasks in conversational scenarios. We propose a novel multi-modal gaze following framework based on our observation ``audiences tend to focus on the speaker''. We first leverage the correlation between audio and lips, and classify speakers and listeners in a scene. We then use the identity information to enhance scene images and propose a gaze candidate estimation network. The network estimates gaze candidates from enhanced scene images and we use MLP to match subjects with candidates as classification tasks. Existing gaze following datasets focus on visual images while ignore audios.To evaluate our method, we collect a conversational dataset, VideoGazeSpeech (VGS), which is the first gaze following dataset including images and audio. Our method significantly outperforms existing methods in VGS datasets. The visualization result also prove the advantage of audio cues in gaze following tasks. Our work will inspire more researches in multi-modal gaze following estimation.
CeCNN: Copula-enhanced convolutional neural networks in joint prediction of refraction error and axial length based on ultra-widefield fundus images
Nov 07, 2023Ultra-widefield (UWF) fundus images are replacing traditional fundus images in screening, detection, prediction, and treatment of complications related to myopia because their much broader visual range is advantageous for highly myopic eyes. Spherical equivalent (SE) is extensively used as the main myopia outcome measure, and axial length (AL) has drawn increasing interest as an important ocular component for assessing myopia. Cutting-edge studies show that SE and AL are strongly correlated. Using the joint information from SE and AL is potentially better than using either separately. In the deep learning community, though there is research on multiple-response tasks with a 3D image biomarker, dependence among responses is only sporadically taken into consideration. Inspired by the spirit that information extracted from the data by statistical methods can improve the prediction accuracy of deep learning models, we formulate a class of multivariate response regression models with a higher-order tensor biomarker, for the bivariate tasks of regression-classification and regression-regression. Specifically, we propose a copula-enhanced convolutional neural network (CeCNN) framework that incorporates the dependence between responses through a Gaussian copula (with parameters estimated from a warm-up CNN) and uses the induced copula-likelihood loss with the backbone CNNs. We establish the statistical framework and algorithms for the aforementioned two bivariate tasks. We show that the CeCNN has better prediction accuracy after adding the dependency information to the backbone models. The modeling and the proposed CeCNN algorithm are applicable beyond the UWF scenario and can be effective with other backbones beyond ResNet and LeNet.
Improved Positional Encoding for Implicit Neural Representation based Compact Data Representation
Nov 10, 2023Positional encodings are employed to capture the high frequency information of the encoded signals in implicit neural representation (INR). In this paper, we propose a novel positional encoding method which improves the reconstruction quality of the INR. The proposed embedding method is more advantageous for the compact data representation because it has a greater number of frequency basis than the existing methods. Our experiments shows that the proposed method achieves significant gain in the rate-distortion performance without introducing any additional complexity in the compression task and higher reconstruction quality in novel view synthesis.
Weakly supervised cross-modal learning in high-content screening
Nov 12, 2023With the surge in available data from various modalities, there is a growing need to bridge the gap between different data types. In this work, we introduce a novel approach to learn cross-modal representations between image data and molecular representations for drug discovery. We propose EMM and IMM, two innovative loss functions built on top of CLIP that leverage weak supervision and cross sites replicates in High-Content Screening. Evaluating our model against known baseline on cross-modal retrieval, we show that our proposed approach allows to learn better representations and mitigate batch effect. In addition, we also present a preprocessing method for the JUMP-CP dataset that effectively reduce the required space from 85Tb to a mere usable 7Tb size, still retaining all perturbations and most of the information content.
Trusted Source Alignment in Large Language Models
Nov 12, 2023Large language models (LLMs) are trained on web-scale corpora that inevitably include contradictory factual information from sources of varying reliability. In this paper, we propose measuring an LLM property called trusted source alignment (TSA): the model's propensity to align with content produced by trusted publishers in the face of uncertainty or controversy. We present FactCheckQA, a TSA evaluation dataset based on a corpus of fact checking articles. We describe a simple protocol for evaluating TSA and offer a detailed analysis of design considerations including response extraction, claim contextualization, and bias in prompt formulation. Applying the protocol to PaLM-2, we find that as we scale up the model size, the model performance on FactCheckQA improves from near-random to up to 80% balanced accuracy in aligning with trusted sources.
Exploring the law of text geographic information
Sep 01, 2023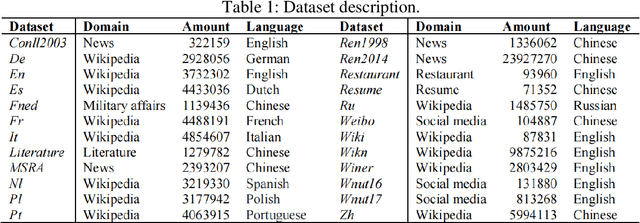
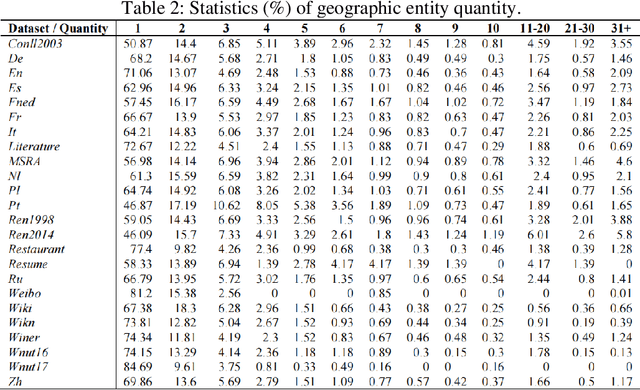
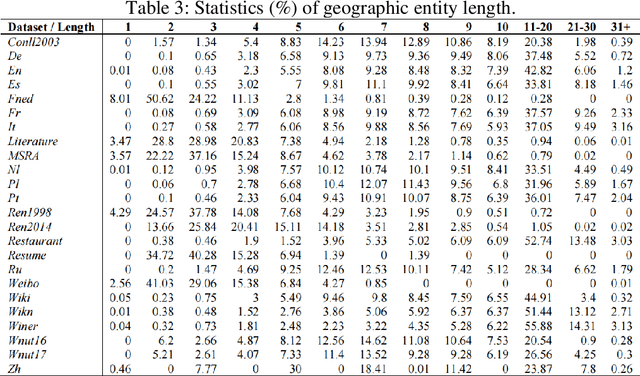
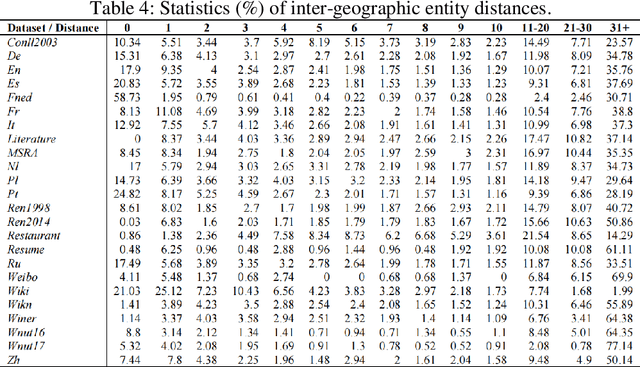
Textual geographic information is indispensable and heavily relied upon in practical applications. The absence of clear distribution poses challenges in effectively harnessing geographic information, thereby driving our quest for exploration. We contend that geographic information is influenced by human behavior, cognition, expression, and thought processes, and given our intuitive understanding of natural systems, we hypothesize its conformity to the Gamma distribution. Through rigorous experiments on a diverse range of 24 datasets encompassing different languages and types, we have substantiated this hypothesis, unearthing the underlying regularities governing the dimensions of quantity, length, and distance in geographic information. Furthermore, theoretical analyses and comparisons with Gaussian distributions and Zipf's law have refuted the contingency of these laws. Significantly, we have estimated the upper bounds of human utilization of geographic information, pointing towards the existence of uncharted territories. Also, we provide guidance in geographic information extraction. Hope we peer its true countenance uncovering the veil of geographic information.
Matching aggregate posteriors in the variational autoencoder
Nov 13, 2023The variational autoencoder (VAE) is a well-studied, deep, latent-variable model (DLVM) that efficiently optimizes the variational lower bound of the log marginal data likelihood and has a strong theoretical foundation. However, the VAE's known failure to match the aggregate posterior often results in \emph{pockets/holes} in the latent distribution (i.e., a failure to match the prior) and/or \emph{posterior collapse}, which is associated with a loss of information in the latent space. This paper addresses these shortcomings in VAEs by reformulating the objective function associated with VAEs in order to match the aggregate/marginal posterior distribution to the prior. We use kernel density estimate (KDE) to model the aggregate posterior in high dimensions. The proposed method is named the \emph{aggregate variational autoencoder} (AVAE) and is built on the theoretical framework of the VAE. Empirical evaluation of the proposed method on multiple benchmark data sets demonstrates the effectiveness of the AVAE relative to state-of-the-art (SOTA) methods.
Analyzing and Predicting Low-Listenership Trends in a Large-Scale Mobile Health Program: A Preliminary Investigation
Nov 13, 2023Mobile health programs are becoming an increasingly popular medium for dissemination of health information among beneficiaries in less privileged communities. Kilkari is one of the world's largest mobile health programs which delivers time sensitive audio-messages to pregnant women and new mothers. We have been collaborating with ARMMAN, a non-profit in India which operates the Kilkari program, to identify bottlenecks to improve the efficiency of the program. In particular, we provide an initial analysis of the trajectories of beneficiaries' interaction with the mHealth program and examine elements of the program that can be potentially enhanced to boost its success. We cluster the cohort into different buckets based on listenership so as to analyze listenership patterns for each group that could help boost program success. We also demonstrate preliminary results on using historical data in a time-series prediction to identify beneficiary dropouts and enable NGOs in devising timely interventions to strengthen beneficiary retention.