 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SS-MAE: Spatial-Spectral Masked Auto-Encoder for Multi-Source Remote Sensing Image Classification
Nov 08, 2023
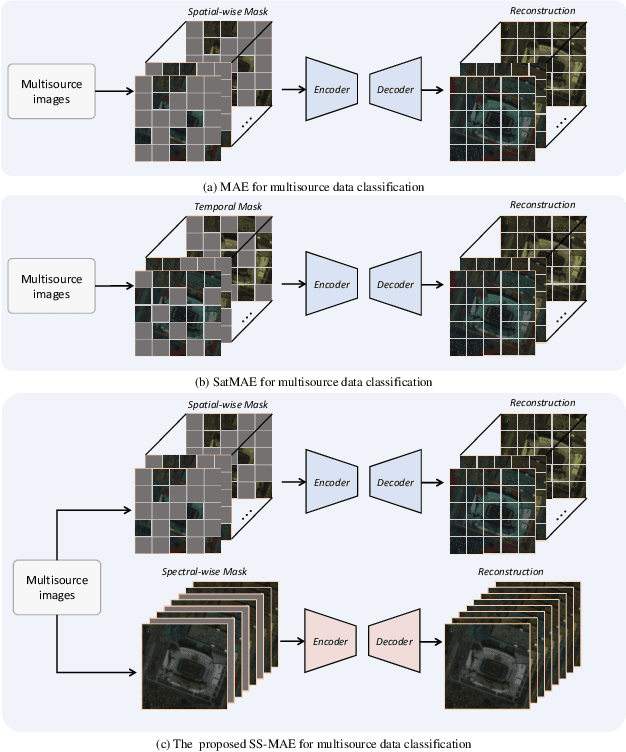

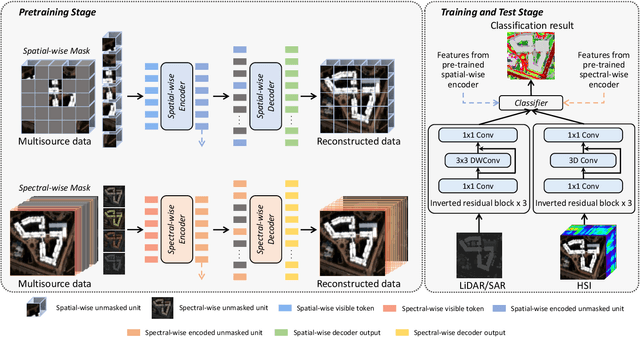
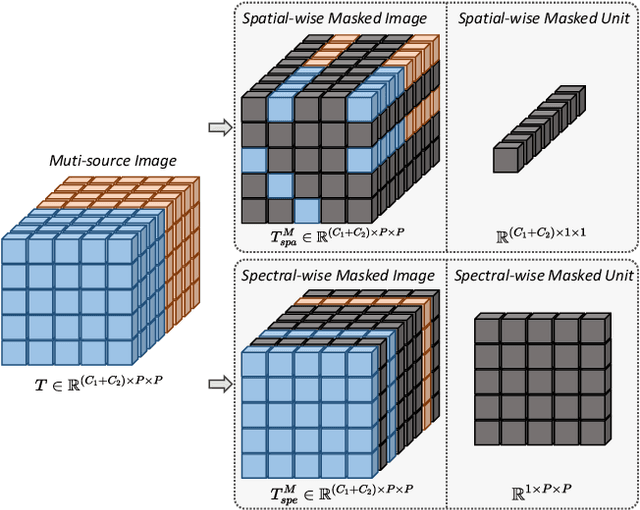
Masked image modeling (MIM) is a highly popular and effective self-supervised learning method for image understanding. Existing MIM-based methods mostly focus on spatial feature modeling, neglecting spectral feature modeling. Meanwhile, existing MIM-based methods use Transformer for feature extraction, some local or high-frequency information may get lost. To this end, we propose a spatial-spectral masked auto-encoder (SS-MAE) for HSI and LiDAR/SAR data joint classification. Specifically, SS-MAE consists of a spatial-wise branch and a spectral-wise branch. The spatial-wise branch masks random patches and reconstructs missing pixels, while the spectral-wise branch masks random spectral channels and reconstructs missing channels. Our SS-MAE fully exploits the spatial and spectral representations of the input data. Furthermore, to complement local features in the training stage, we add two lightweight CNNs for feature extraction. Both global and local features are taken into account for feature modeling. To demonstrate the effectiveness of the proposed SS-MAE, we conduct extensive experiments on three publicly available datasets. Extensive experiments on three multi-source datasets verify the superiority of our SS-MAE compared with several state-of-the-art baselines. The source codes are available at \url{https://github.com/summitgao/SS-MAE}.
Enhancing search engine precision and user experience through sentiment-based polysemy resolution
Nov 03, 2023With the proliferation of digital content and the need for efficient information retrieval, this study's insights can be applied to various domains, including news services, e-commerce, and digital marketing, to provide users with more meaningful and tailored experiences. The study addresses the common problem of polysemy in search engines, where the same keyword may have multiple meanings. It proposes a solution to this issue by embedding a smart search function into the search engine, which can differentiate between different meanings based on sentiment. The study leverages sentiment analysis, a powerful natural language processing (NLP) technique, to classify and categorize news articles based on their emotional tone. This can provide more insightful and nuanced search results. The article reports an impressive accuracy rate of 85% for the proposed smart search function, which outperforms conventional search engines. This indicates the effectiveness of the sentiment-based approach. The research explores multiple sentiment analysis models, including Sentistrength and Valence Aware Dictionary for Sentiment Reasoning (VADER), to determine the best-performing approach. The findings can be applied to enhance search engines, making them more capable of understanding the context and intent behind users 'queries. This can lead to better search results that are more aligned with what users are looking for. The proposed smart search function can improve the user experience by reducing the need to sift through irrelevant search results. This is particularly important in an age where information overload is common.
Capturing Local and Global Features in Medical Images by Using Ensemble CNN-Transformer
Nov 03, 2023This paper introduces a groundbreaking classification model called the Controllable Ensemble Transformer and CNN (CETC) for the analysis of medical images. The CETC model combines the powerful capabilities of convolutional neural networks (CNNs) and transformers to effectively capture both local and global features present in medical images. The model architecture comprises three main components: a convolutional encoder block (CEB), a transposed-convolutional decoder block (TDB), and a transformer classification block (TCB). The CEB is responsible for capturing multi-local features at different scales and draws upon components from VGGNet, ResNet, and MobileNet as backbones. By leveraging this combination, the CEB is able to effectively detect and encode local features. The TDB, on the other hand, consists of sub-decoders that decode and sum the captured features using ensemble coefficients. This enables the model to efficiently integrate the information from multiple scales. Finally, the TCB utilizes the SwT backbone and a specially designed prediction head to capture global features, ensuring a comprehensive understanding of the entire image. The paper provides detailed information on the experimental setup and implementation, including the use of transfer learning, data preprocessing techniques, and training settings. The CETC model is trained and evaluated using two publicly available COVID-19 datasets. Remarkably, the model outperforms existing state-of-the-art models across various evaluation metrics. The experimental results clearly demonstrate the superiority of the CETC model, emphasizing its potential for accurately and efficiently analyzing medical images.
Incorporating Language-Driven Appearance Knowledge Units with Visual Cues in Pedestrian Detection
Nov 02, 2023Large language models (LLMs) have shown their capability in understanding contextual and semantic information regarding appearance knowledge of instances. In this paper, we introduce a novel approach to utilize the strength of an LLM in understanding contextual appearance variations and to leverage its knowledge into a vision model (here, pedestrian detection). While pedestrian detection is considered one of crucial tasks directly related with our safety (e.g., intelligent driving system), it is challenging because of varying appearances and poses in diverse scenes. Therefore, we propose to formulate language-driven appearance knowledge units and incorporate them with visual cues in pedestrian detection. To this end, we establish description corpus which includes numerous narratives describing various appearances of pedestrians and others. By feeding them through an LLM, we extract appearance knowledge sets that contain the representations of appearance variations. After that, we perform a task-prompting process to obtain appearance knowledge units which are representative appearance knowledge guided to be relevant to a downstream pedestrian detection task. Finally, we provide plentiful appearance information by integrating the language-driven knowledge units with visual cues. Through comprehensive experiments with various pedestrian detectors, we verify the effectiveness of our method showing noticeable performance gains and achieving state-of-the-art detection performance.
Efficient Object Detection in Optical Remote Sensing Imagery via Attention-based Feature Distillation
Oct 28, 2023Efficient object detection methods have recently received great attention in remote sensing. Although deep convolutional networks often have excellent detection accuracy, their deployment on resource-limited edge devices is difficult. Knowledge distillation (KD) is a strategy for addressing this issue since it makes models lightweight while maintaining accuracy. However, existing KD methods for object detection have encountered two constraints. First, they discard potentially important background information and only distill nearby foreground regions. Second, they only rely on the global context, which limits the student detector's ability to acquire local information from the teacher detector. To address the aforementioned challenges, we propose Attention-based Feature Distillation (AFD), a new KD approach that distills both local and global information from the teacher detector. To enhance local distillation, we introduce a multi-instance attention mechanism that effectively distinguishes between background and foreground elements. This approach prompts the student detector to focus on the pertinent channels and pixels, as identified by the teacher detector. Local distillation lacks global information, thus attention global distillation is proposed to reconstruct the relationship between various pixels and pass it from teacher to student detector. The performance of AFD is evaluated on two public aerial image benchmarks, and the evaluation results demonstrate that AFD in object detection can attain the performance of other state-of-the-art models while being efficient.
TransformCode: A Contrastive Learning Framework for Code Embedding via Subtree transformation
Nov 10, 2023Large-scale language models have made great progress in the field of software engineering in recent years. They can be used for many code-related tasks such as code clone detection, code-to-code search, and method name prediction. However, these large-scale language models based on each code token have several drawbacks: They are usually large in scale, heavily dependent on labels, and require a lot of computing power and time to fine-tune new datasets.Furthermore, code embedding should be performed on the entire code snippet rather than encoding each code token. The main reason for this is that encoding each code token would cause model parameter inflation, resulting in a lot of parameters storing information that we are not very concerned about. In this paper, we propose a novel framework, called TransformCode, that learns about code embeddings in a contrastive learning manner. The framework uses the Transformer encoder as an integral part of the model. We also introduce a novel data augmentation technique called abstract syntax tree transformation: This technique applies syntactic and semantic transformations to the original code snippets to generate more diverse and robust anchor samples. Our proposed framework is both flexible and adaptable: It can be easily extended to other downstream tasks that require code representation such as code clone detection and classification. The framework is also very efficient and scalable: It does not require a large model or a large amount of training data, and can support any programming language.Finally, our framework is not limited to unsupervised learning, but can also be applied to some supervised learning tasks by incorporating task-specific labels or objectives. To explore the effectiveness of our framework, we conducted extensive experiments on different software engineering tasks using different programming languages and multiple datasets.
Low-Multi-Rank High-Order Bayesian Robust Tensor Factorization
Nov 10, 2023The recently proposed tensor robust principal component analysis (TRPCA) methods based on tensor singular value decomposition (t-SVD) have achieved numerous successes in many fields. However, most of these methods are only applicable to third-order tensors, whereas the data obtained in practice are often of higher order, such as fourth-order color videos, fourth-order hyperspectral videos, and fifth-order light-field images. Additionally, in the t-SVD framework, the multi-rank of a tensor can describe more fine-grained low-rank structure in the tensor compared with the tubal rank. However, determining the multi-rank of a tensor is a much more difficult problem than determining the tubal rank. Moreover, most of the existing TRPCA methods do not explicitly model the noises except the sparse noise, which may compromise the accuracy of estimating the low-rank tensor. In this work, we propose a novel high-order TRPCA method, named as Low-Multi-rank High-order Bayesian Robust Tensor Factorization (LMH-BRTF), within the Bayesian framework. Specifically, we decompose the observed corrupted tensor into three parts, i.e., the low-rank component, the sparse component, and the noise component. By constructing a low-rank model for the low-rank component based on the order-$d$ t-SVD and introducing a proper prior for the model, LMH-BRTF can automatically determine the tensor multi-rank. Meanwhile, benefiting from the explicit modeling of both the sparse and noise components, the proposed method can leverage information from the noises more effectivly, leading to an improved performance of TRPCA. Then, an efficient variational inference algorithm is established for parameters estimation. Empirical studies on synthetic and real-world datasets demonstrate the effectiveness of the proposed method in terms of both qualitative and quantitative results.
Exploiting Correlated Auxiliary Feedback in Parameterized Bandits
Nov 05, 2023We study a novel variant of the parameterized bandits problem in which the learner can observe additional auxiliary feedback that is correlated with the observed reward. The auxiliary feedback is readily available in many real-life applications, e.g., an online platform that wants to recommend the best-rated services to its users can observe the user's rating of service (rewards) and collect additional information like service delivery time (auxiliary feedback). In this paper, we first develop a method that exploits auxiliary feedback to build a reward estimator with tight confidence bounds, leading to a smaller regret. We then characterize the regret reduction in terms of the correlation coefficient between reward and its auxiliary feedback. Experimental results in different settings also verify the performance gain achieved by our proposed method.
Using Symmetries to Lift Satisfiability Checking
Nov 06, 2023We analyze how symmetries can be used to compress structures (also known as interpretations) onto a smaller domain without loss of information. This analysis suggests the possibility to solve satisfiability problems in the compressed domain for better performance. Thus, we propose a 2-step novel method: (i) the sentence to be satisfied is automatically translated into an equisatisfiable sentence over a ``lifted'' vocabulary that allows domain compression; (ii) satisfiability of the lifted sentence is checked by growing the (initially unknown) compressed domain until a satisfying structure is found. The key issue is to ensure that this satisfying structure can always be expanded into an uncompressed structure that satisfies the original sentence to be satisfied. We present an adequate translation for sentences in typed first-order logic extended with aggregates. Our experimental evaluation shows large speedups for generative configuration problems. The method also has applications in the verification of software operating on complex data structures. Further refinements of the translation are left for future work.
A Foundation Model for Music Informatics
Nov 06, 2023This paper investigates foundation models tailored for music informatics, a domain currently challenged by the scarcity of labeled data and generalization issues. To this end, we conduct an in-depth comparative study among various foundation model variants, examining key determinants such as model architectures, tokenization methods, temporal resolution, data, and model scalability. This research aims to bridge the existing knowledge gap by elucidating how these individual factors contribute to the success of foundation models in music informatics. Employing a careful evaluation framework, we assess the performance of these models across diverse downstream tasks in music information retrieval, with a particular focus on token-level and sequence-level classification. Our results reveal that our model demonstrates robust performance, surpassing existing models in specific key metrics. These findings contribute to the understanding of self-supervised learning in music informatics and pave the way for developing more effective and versatile foundation models in the field. A pretrained version of our model is publicly available to foster reproducibility and future research.